详解MySQL索引
目录
1.什么是索引
2.使用索引的优缺点
3.索引的数据结构
4.索引的分类
5.索引的操作
6.复合索引的数据结构
1.什么是索引
当我们想在一本书里面找到具体的章节的时候,最快的办法是去查看这本书的目录,索引就类似于数据库中存储的数据的目录,是一种用于快速查找到数据的数据结构,这个数据结构里面存储的是指向数据存储位置的指针。
使用索引之后,除了数据本身之外,还要存一份索引,用了更多的存储空间,是标准的用空间换时间的做法。
2.使用索引的优缺点
索引能提高查询效率,但是会降低增加、删除、修改的效率,因为这些更新操作不仅需要更新数据,还要更新索引。由于索引是排序好的,有序的数据结构(任何用于支持快速查询的数据结构都是有序的),更新操作还会引起索引的自调整,这也是很花时间的。
3.索引的数据结构
MySQL中不同存储引擎的索引采用的不同的数据结构,在我们常用的innodb存储引擎里使用的是B+树。
关于B树和B+树推荐博主之前写的文章,里面详细的介绍了B树和B+树:
数据结构(8)树形结构——B树、B+树(含完整建树过程)_b+树构建过程__BugMan的博客-CSDN博客
4.索引的分类
索引的分类有两个维度,一个是数据和索引是不是在一起,一个是建立索引的字段。
按照数据和索引是不是在一起,可分为:
-
聚集索引
-
非聚集索引
注意:在innodb存储引擎中,同一个表的数据和索引会存放在同一个表空间文件(.idb)中。所以在innodb体系中数据和索引是不是在一起这个概念,是指二者是不是挂在一个数据结构上。
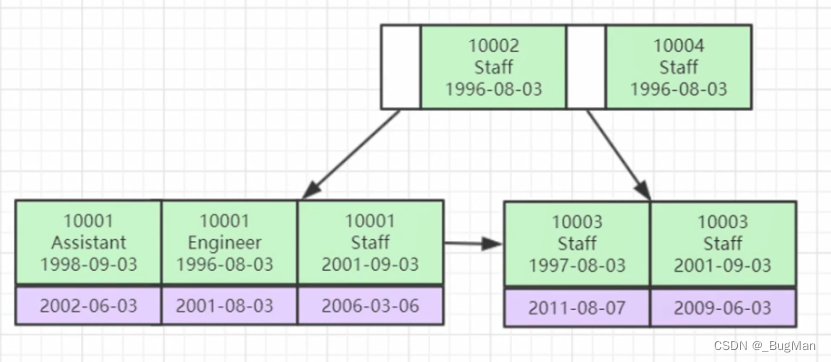
聚集索引:
聚集索引,即索引和数据聚集在一起。
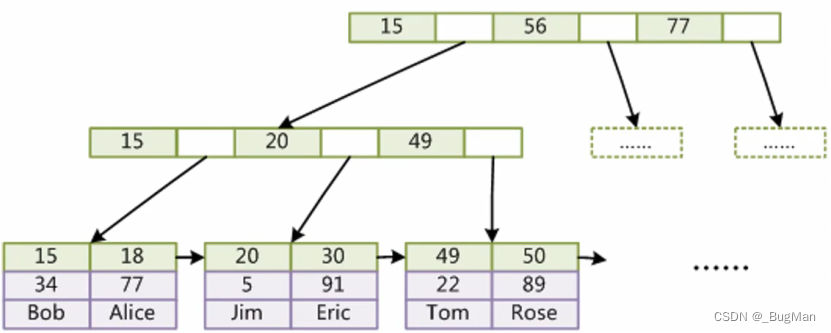
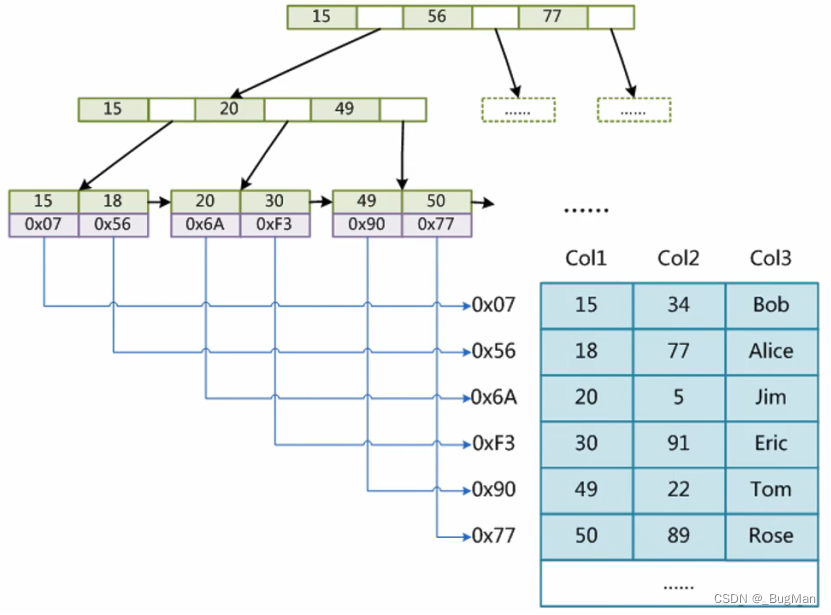
非聚集索引:
非聚集索引,即索引和数据是分开的,通过地址指针来关联。
按照建立索引的字段的不同,可以分为:
-
单值索引
-
唯一索引
-
主键索引
-
复合索引
单值索引:
即在单字段上创建索引。
CREATE INDEX idx_name ON table_name (column_name);
唯一索引:
唯一索引也是在单字段上创建索引,区别在于唯一索引要求索引列的所有值必须唯一。也就是说,如果一个列建立了唯一索引,那么不能在这个列中插入重复的值。也就是说唯一索引可以帮我们”辨重“,具有一些业务场景的价值,如果我们需要确保数据的唯一性,例如在用户表中的用户名字段或者订单表中的订单号字段等,就应该使用唯一索引。使用唯一索引可以保证数据的完整性,防止出现重复数据。
CREATE UNIQUE INDEX idx_name ON table_name (column_name);
主键索引:
主键自带的索引,属于特殊的唯一索引,是innodb引擎中唯一的聚集索引,因为是聚集索引,其拥有超高的查询效率。
ALTER TABLE table_name ADD PRIMARY KEY (column_name);
5.索引的操作
查询所有索引:
show index from 表名;
删除索引:
drop index 索引名 on 表名;
创建索引前文已经说过了,此处不赘述。
6.复合索引的数据结构
单字段的索引的结构都很好想象和理解,复合索引的结构这里要特比提一下,它是先按照第一个索引排序,第一个索引的值相同时,按照第二个索引排序,以此类推。