ViveNAS - 一个基于LSM tree的文件存储实现 (一)
1. ViveNAS (GitHub - cocalele/ViveNAS)
ViveNAS 是一个开源分布式的网络文件系统(NAS), 具有下面的特点:
- 通过不同存储介质的结合,在高性能、低成本间寻找动态的平衡
- 解决数据的长期、低成本存储问题,支持磁带,SMR HDD等低成本介质,以及EC
- 为CXL内存池、SCM等新技术的应用做好准备,并应用这些新技术产生澎湃性能,服务热点数据
- 解决小文件存储难题
- 为企业存储提供受控的分布式策略,以解决传统分布式存储在扩容、均衡、故障恢复时面临的各种难题
- 绿色存储,充分利用数据中心超配而不能充分利用的内存、CPU资源提供服务,降低能源消耗
ViveNAS目前版本提供标准NFS接口。
ViveNAS提供上述能力的核心技术依赖于下列两项:
核心1,PureFlash 分布式SAN存储
PureFlash 提供了我们这个存储系统所有跟分布式有关的特性,包括高可用机制、故障恢复机制、存储虚拟化、快照、克隆等。
PureFlash是一个分布式的ServerSAN存储系统,他的核心思想继承自NetBRIC S5,一个以全FPGA硬件实现的全闪存储系统,因此PureFlash拥有一个极度简单的IO栈,最小的IO开销。
区别与以hash算法为基础的分布式系统,PureFlash的数据分布是完全人为可控的,这提供了企业存储在运行时所需的稳定能力,因为数据分布的掌控权最终在“人”而不在“机器”。更多细节请参看github.com/cocalele/PureFlash
PureFlash支持在一个集群里管理不同的存储质,包括从NVMe SSD、HDD、磁带,以及AOF文件访问,
上述的这些为ViveNAS提供了坚实的数据存储保障。
核心2,以LSM tree为基础的ViveFS
LSM tree有两个重要特点,一是多层级,二是每个层级都是顺序写。
ViveFS将level 0 放在内存或者CXL内存池里,将其他层级放在PureFlash提供的不同存储介质里,而且每个层级都是分布式且具有高可靠性。
顺序写这个特性对磁带/smr hdd介质非常的友好,这样ViveNAS就可以将比较低层级的数据放到这些低成本介质上进行长期存储。这也是ViveNAS最重要的目标,解决冷数据的长期存储成本与访问复杂难题,
同时顺序写的AOF文件对ec也是很友好的,通过大因子EC可以进一步降低存储成本。
2. ViveNAS的 层级架构
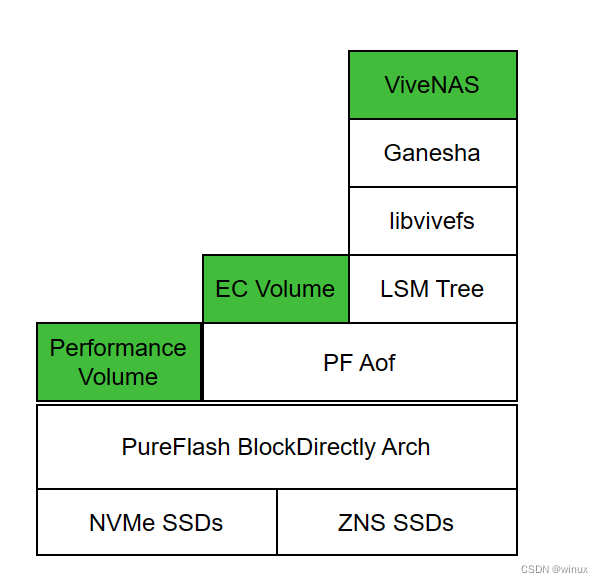
从上图可以看到,从一个最底层的SSD介质到方便使用的NAS文件服务中间需要很多层级的协作。
本文重点介绍里面的libvivefs的实现原理。正如libvivefs在图中的位置,他的下层是LSM tree, 在当前的实现里面我直接选用了rocksdb。他的上层对接到ganesha FSAL,提供标准的文件语义接口。标准文件语义,但并不是标准Posix接口,也没有对接在linux VFS之下。libvivefs提供的API包括:
inode_no_t vn_lookup_inode_no(struct ViveFsContext* ctx, inode_no_t parent_inode_no, const char* file_name, /*out*/struct ViveInode** inode);
inode_no_t vn_create_file(struct ViveFsContext* ctx, inode_no_t parent_inode_no, const char* file_name,
int16_t mode, int16_t uid, int16_t gid, /*out*/ struct ViveInode** inode_out);
struct ViveFile* vn_open_file(struct ViveFsContext* ctx, inode_no_t parent_inode_no, const char* file_name, int32_t flags, int16_t mode);
struct ViveFile* vn_open_file_by_inode(struct ViveFsContext* ctx, struct ViveInode* inode, int32_t flags, int16_t mode);
size_t vn_write(struct ViveFsContext* ctx, struct ViveFile* file, const char* in_buf, size_t len, off_t offset);
size_t vn_writev(struct ViveFsContext* ctx, struct ViveFile* file, struct iovec in_iov[], int iov_cnt, off_t offset);
size_t vn_read(struct ViveFsContext* ctx, struct ViveFile* file, char* out_buf, size_t len, off_t offset);
size_t vn_readv(struct ViveFsContext* ctx, struct ViveFile* file, struct iovec out_iov[] , int iov_cnt, off_t offset);
struct vn_inode_iterator* vn_begin_iterate_dir(struct ViveFsContext* ctx, int64_t parent_inode_no);
struct ViveInode* vn_next_inode(struct ViveFsContext* ctx, struct vn_inode_iterator* it, char* entry_name, size_t buf_len);
int /*as bool*/ vn_iterator_has_next(struct vn_inode_iterator* it);
void vn_release_iterator(struct ViveFsContext* ctx, struct vn_inode_iterator* it);
int vn_fsync(struct ViveFsContext* ctx, struct ViveFile* file);
int vn_close_file(struct ViveFsContext* ctx, struct ViveFile* file);
int vn_unlink(struct ViveFsContext* ctx, int64_t parent_ino, const char* fname);
int vn_rename_file(struct ViveFsContext* ctx, inode_no_t old_dir_ino, const char* old_name, inode_no_t new_dir_ino, const char* new_name);
struct ViveFsContext* vn_mount(const char* db_path);
int vn_umount(struct ViveFsContext* ctx);
里面的open/close, read/write类函数想必大家都不陌生,只是换了个名字,毕竟跟系统的标准API重名会自找麻烦。还有一些函数,包括lookup_inode, iterator, unlink这些函数,研究过linux内核文件系统实现的朋友也一定都见到过。
上面的这组接口就是libvivefs想要提供出来能力。他的下层rocksdb提供的接口也是相当的简洁:put/get, prefix_iterator, merge, transaction commit。
put/get已经能够实现数据的写入、读出。但是put/get是KV操作,是对目标对象整体的访问。对于文件语义必须要提供随机IO能力,也就是指定任意Offset, 操作任意长度的数据。libvivefs的作用就是弥合这二者间的差异。
3. libvivefs的数据布局
看一个文件系统的原理一定要看他的磁盘布局,磁盘布局决定了需要什么样的算法。磁盘布局跟介质密切相关,一定要按介质特点设计,因此针对机械盘,NAND flash, pmem, 磁带等有各种适配文件系统。
libvivefs在rocksdb里创建两个column family, 分别储存文件系统的元数据和数据。数据CF (column family)顾名思义就是文件的内容了,其K-V是这样的:
Value是文件内容按64KB大小切割的数据块加上extent_head,Key是extent的标识。
Key 由16Byte的binary构成,结构如下:
struct vn_extent_key{
union {
struct {
_le64 extent_index;
_le64 inode_no;
};
char keybuf[16];
}
}`vn_extent_key` 结构里的两个关键变量:
inode_no: 也就是Inode号,这和其他文件系统对inode号的定义一样,唯一标识一个文件,并且不会随着文件改名而变化。
extent_index:表示这个数据块是文件的第几个数据块。也就是说这些数据块顺次保存了文件的内容。
extent_head的构成如下:
struct vn_extent_head {
int8_t flags;
int8_t pad0;
union {
uint16_t data_bmp;
uint16_t merge_off;
};
char pad1[12];
};有了extent_head的存在就能够支持任意长度的写入,而不必等凑满整个extent才能写入。这个能力也是借助了rocksdb的merge操作实现的。
反正LSM-tree是需要对数据进行compaction,因此写入的时候没必要每次都进行RMW(Read-Modify-Write),只需要将改动的部分数据写入。在compaction或者read的时候,会触发merge操作将同一个key的不同数据分片、版本合并成一个完整的extent。extent_head里面的信息在merge操作时会被用到。
4. write操作的实现
有了上面的数据布局知识,write操作的实现就很明显了,将数据按照在文件中的位置找到对应的extent,按照写入是否写满了整个extent分别调用mege或者put操作。
size_t vn_write(struct ViveFsContext* ctx, struct ViveFile* file, const char * in_buf, size_t len, off_t offset )
{
int64_t start_ext = offset / file->inode->i_extent_size;
int64_t end_ext = (offset + len + file->inode->i_extent_size - 1) / file->inode->i_extent_size;
void* buf = malloc(file->inode->i_extent_size + PFS_EXTENT_HEAD_SIZE);
S5LOG_DEBUG("call vn_write, len:%ld off:%ld", len, offset);
DeferCall _1([buf]() {free(buf); });
struct vn_extent_head* head = (struct vn_extent_head*)buf;
Transaction* tx = ctx->db->BeginTransaction(ctx->data_opt);
DeferCall _2([tx]() {delete tx; });
Cleaner _c;
Status s;
_c.push_back([tx]() {tx->Rollback(); });
int64_t buf_offset = 0;
for (int64_t index = start_ext; index < end_ext; index++) {
//string ext_key = format_string("%ld_%ld", file->i_no, index);
vn_extent_key ext_key = { {{extent_index: (__le64)index, inode_no : (__le64)file->i_no}} };
int64_t start_off = (offset + buf_offset) % file->inode->i_extent_size; //offset in extent
size_t segment_len = std::min(len - buf_offset, (size_t)file->inode->i_extent_size - start_off);
*head = { 0 };
memcpy((char*)buf + PFS_EXTENT_HEAD_SIZE, in_buf + buf_offset, segment_len);
Slice segment_data((char*)buf, segment_len + PFS_EXTENT_HEAD_SIZE);
if(segment_len != file->inode->i_extent_size){
//不是满条带,就执行Merge操作
head->merge_off = (uint16_t)start_off;
s = tx->Merge(ctx->data_cf, Slice((const char*)&ext_key, sizeof(ext_key)), segment_data);
} else {
//满条带,就执行Put操作
head->data_bmp = (uint16_t)start_off;
s = tx->Put(ctx->data_cf, Slice((const char*)&ext_key, sizeof(ext_key)), segment_data);
}
buf_offset += segment_len;
}
file->inode->i_mtime = time(NULL);
file->dirty = 1;
if (offset + len > file->inode->i_size) {
//如果文件长度也发生了改变,就更新长度。 否则会现在lazy 模式更新元数据,也就是上面的修改时间不会每次更新。
file->inode->i_size = offset + len;
s = _vn_persist_inode(ctx, tx, file->inode);
file->dirty = 0;
}
s = tx->Commit();
_c.cancel_all();
return len;
}read操作的实现逻辑和write相似且更简单。