谷粒商城二十四Sentinel限流熔断降级
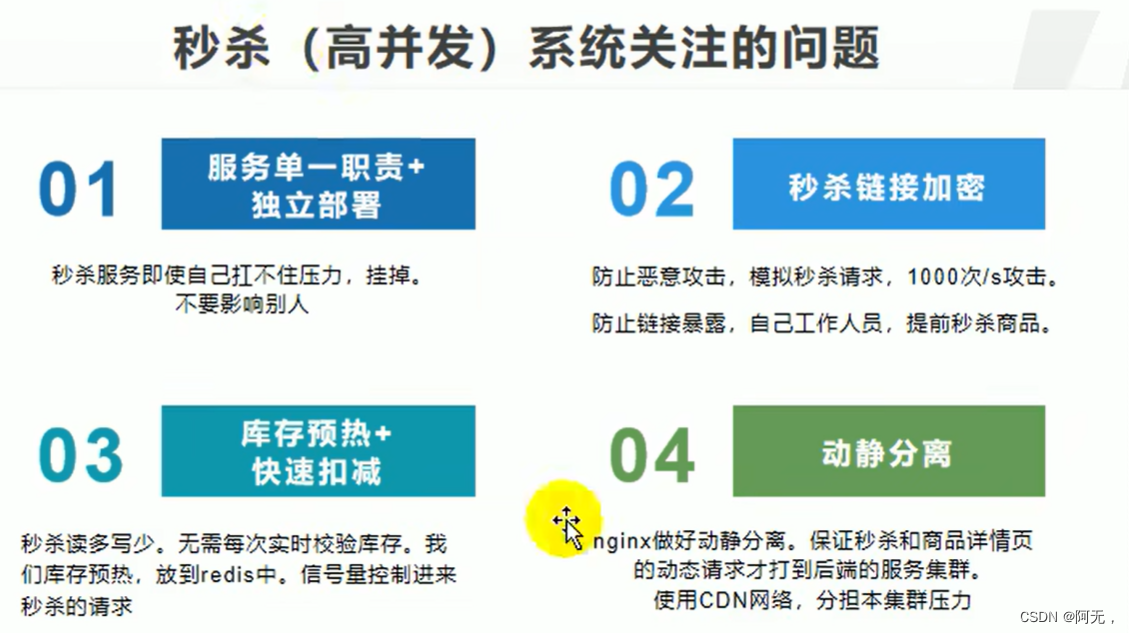

我们在秒杀服务加的以上所有手段都是为了快,除了快之外,我们还需要保证稳定。
我们即使再快也会有一个极限值,现在假设单机下每秒处理一万个单,这已经是超高的处理能力了,秒杀服务上了五台服务器,有三台掉线,但是秒杀请求网关直接放过了10w请求,全部放进来,那剩下的两台服务器就处理不过来,每台服务器的顶峰值是1w,所有的请求都得排队,排着排着就造成了请求的时间累积,时间一长,资源耗尽,服务器就要崩溃了。
所以快保证了以后,我们就需要保证稳定。
如何保证稳定,那就是在我们分布式系统中的限流&熔断&降级,我们无论哪个分布式系统,不管是不是高并发,都要考虑,因为有了这些的保护手段,我们的整个集群就可以达到稳定。
我们以前是用springCloud的hystrix,不更新了,而且支持的功能也是有限的,
在我们的系统里面,我们使用springCloud alibaba的Sentinel,来完成整个系统的限流&熔断&降级。
会把我们整个系统保护的非常稳定,即使百台服务器的大集群,有了Sentinel的保护,上线或者崩溃几台服务器,都会非常的稳定。
限流&熔断&降级
-
什么是熔断
A 服务调用 B 服务的某个功能,由于网络不稳定问题,或者 B 服务卡机,导致功能时间超长。如果这样子的次数太多。我们就可以直接将 B 断路了(A 不再请求 B 接口),凡是调用 B 的直接返回降级数据,不必等待 B 的超长执行。 这样 B 的故障问题,就不会级联影响到 A。如果没有任何保护,feign远程调用,feign有一个默认超时时间,例如是3s,3s时间如果不返回数据,就认为被调用的服务出问题了,feign接口就会报超时错误,但我们等不了这么久,因为这样就会引起整个调用链的
累积效应,
a调用b,b调用c,c方法现在要等3s,b需要等c,a需要等b,大家都需要等,就会全线卡死,资源不能得到释放,吞吐量就会下降,大量的请求又在排队,这就形成了一个死循环,能力越不行,请求累积的越多,越多的请求又需要越多的资源进行分配处理,我们的机器就会整个卡死,宕机。
所以我们需要加入熔断机制,a调用b,如果发现b不能正常返回,那以后我们直接把b进行断路,接下来a调用b不需要关注b是否成功,直接快速返回失败。
熔断可以保证我们整个服务不受级联影响,一个服务挂了不会让整个调用链长时间的卡死。 -
什么是降级
整个网站处于流量高峰期,服务器压力剧增,根据当前业务情况及流量,对一些服务和页面进行有策略的降级[停止服务,所有的调用直接返回降级数据]。以此缓解服务器资源的的压力,以保证核心业务的正常运行,同时也保持了客户和大部分客户的得到正确的相应。
假设流量处于高峰期,现在有超多的业务正在运行,一些核心的业务,购物车、订单等,还有一些非核心的业务,比如注册之类的,现在网站正在秒杀的高峰期间,大家资源不够用了。
我们可以手动的让一些非核心业务,比如注册,把服务器的注册业务停掉,该服务器上如果有其他业务,就可以把资源让给其他核心业务,这就是降级。
同时可以返回一个降级页面,提示此功能暂时不可用。
-
异同
-
相同点
- 为了保证集群大部分服务的可用性和可靠性,防止崩溃,牺牲小我
- 用户最终都是体验到某个功能不可用
-
不同点:
- 熔断是被调用方故障,触发的系统主动规则
- 降级是基于全局考虑,手动停止一些正常服务,释放资源
-
-
什么是限流
对打入服务的请求流量进行控制,使服务能够承担不超过自己能力的流量压力。
比如整个集群的处理能力就是每秒1w,那我们从网关处放回的请求就是1w,其他一些运气不好的,直接报告错误,自己重试也好,怎么做也好。
限流就是把整个入口的流量来做一个限制,保证我们的服务不会被超过它的能力的流量全部压垮。只要超过它能力的流量直接丢弃,也不用去处理了。
Sentinel
限流&熔断&降级功能都可以用Sentinel做。
Sentinel与Hystrix的区别
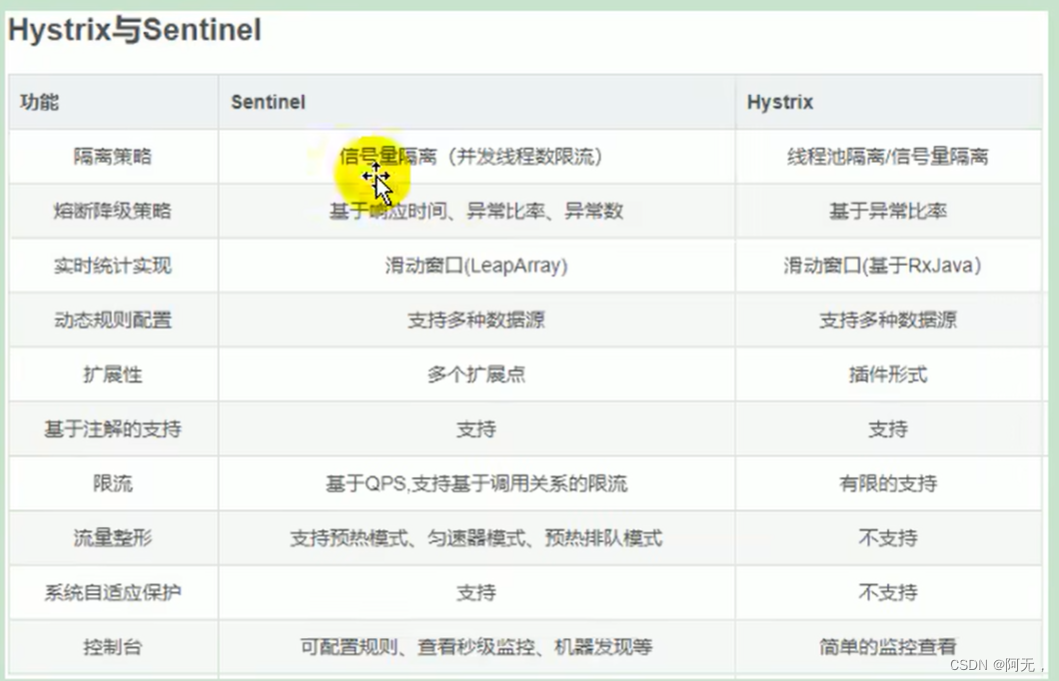
1. 隔离策略
假设我们现在有100个请求全部进来要执行, 系统能力不足只能执行50个
-
线程池隔离
如果是Hystrix,例如是hello请求,为这个请求做一个线程池,分配50个线程,线程池分配一个线程来执行,如果线程不够了就打回去。
但是如果有超多请求,每个请求就会对应一个不同的线程池,线程池也会超多,线程池之间的切换也非常浪费时间,这是对性能的一个极大影响。可能线程池用着用着资源都不够了,导致服务宕机都有可能。 -
信号量隔离
java8中也有Semaphore,和我们redis的Semaphore是一样的,只要请求一进来,如果限制是50,调用该请求的每一个请求都有对应自己的一个信号量,进来一个请求信号量-1,执行完一个请求信号量+1,如果发现该请求进来50个,下一次进来的就直接给打回。
不用为每一个请求单独创建线程池,造成资源的耗费。
线程池隔离也有它的优点,每一个请求都是用自己的线程池,自己的线程池里炸了,和别人没有任何关系。
信号量则是一旦有些人炸了,我们整个服务都会出现一些问题。
2. 熔断降级策略
-
基于响应时间
例如每个请求只要超过1s就不去执行 -
异常比率
一个请求请求一百次,百分之九十都出现了异常,以后我就不请求了。 -
异常数
一百个请求中有五个出现异常,也不请求了。
我们有很多的策略来限制要不要熔断、降级后边的调用链(服务)。
3. 动态规则配置
以上的策略都可以通过数据源来做动态配置,就是把配置持久化到数据库中,服务即使重新启动,还能用之前的配置。
4. 系统自适应保护
系统的能力它知道以后,低峰期把流量都放进来,高峰期限制一些。
简介
Sentinel 可以简单的分为 Sentinel 核心库和 Dashboard(web可视化界面,有了可视化界面,调节监控就非常方便了)。核心库不依赖 Dashboard,但是结合 Dashboard 可以取得最好的效果。
我们说的资源,可以是任何东西,服务,服务里的方法,甚至是一段代码。使用 Sentinel 来进行资源保护,主要分为几个步骤:
- 定义资源(哪些资源要进行保护)
- 定义规则(定义保护规则,比如每秒请求超过多少次就不让访问了,cpu负载超过多少就给它降级了)
- 检验规则是否生效
定义资源
以下是最常用的定义资源的三种方式
方式一:主流框架的默认适配
为了减少开发的复杂程度,我们对大部分的主流框架,例如 Web Servlet、Dubbo、Spring Cloud、gRPC、Spring WebFlux、Reactor 等都做了适配。您只需要引入对应的依赖即可方便地整合 Sentinel。
主流的web框架,所有的请求是默认全部进来适配,所有的请求都是要受保护的资源。
方式二:抛出异常的方式定义资源
SphU 包含了 try-catch 风格的 API。用这种方式,当资源发生了限流之后会抛出 BlockException。这个时候可以捕捉异常,进行限流之后的逻辑处理。示例代码如下:
// 1.5.0 版本开始可以利用 try-with-resources 特性(使用有限制)
// 资源名可使用任意有业务语义的字符串,比如方法名、接口名或其它可唯一标识的字符串。
try (Entry entry = SphU.entry("resourceName")) {
// 被保护的业务逻辑
// do something here...
} catch (BlockException ex) {
// 资源访问阻止,被限流或被降级
// 在此处进行相应的处理操作
}
方式四:注解方式定义资源
Sentinel 支持通过 @SentinelResource 注解定义资源并配置 blockHandler 和 fallback 函数来进行限流之后的处理。示例:
// 原本的业务方法.
@SentinelResource(blockHandler = "blockHandlerForGetUser")
public User getUserById(String id) {
throw new RuntimeException("getUserById command failed");
}
// blockHandler 函数,原方法调用被限流/降级/系统保护的时候调用
public User blockHandlerForGetUser(String id, BlockException ex) {
return new User("admin");
}
每次和学校谈话结束,苏迎澜就第一时间分享给小逸,“过来,我和你汇报下工作”。她省略了具体谈判的过程,以一个孩子能理解的语言把事情总结出来。
https://baijiahao.baidu.com/s?id=1760481532554271247
一个妈妈的反校园暴力“战斗”