《通过十几轮数据进行模型训练,实现精确的无创血糖测量的演绎学习》阅读笔记
目录
0 演绎学习
1 论文摘要
2 论文十问
3 论文亮点与不足之处
4 与其他研究的比较
5 实际应用与影响
6 个人思考与启示
参考文献
0 演绎学习
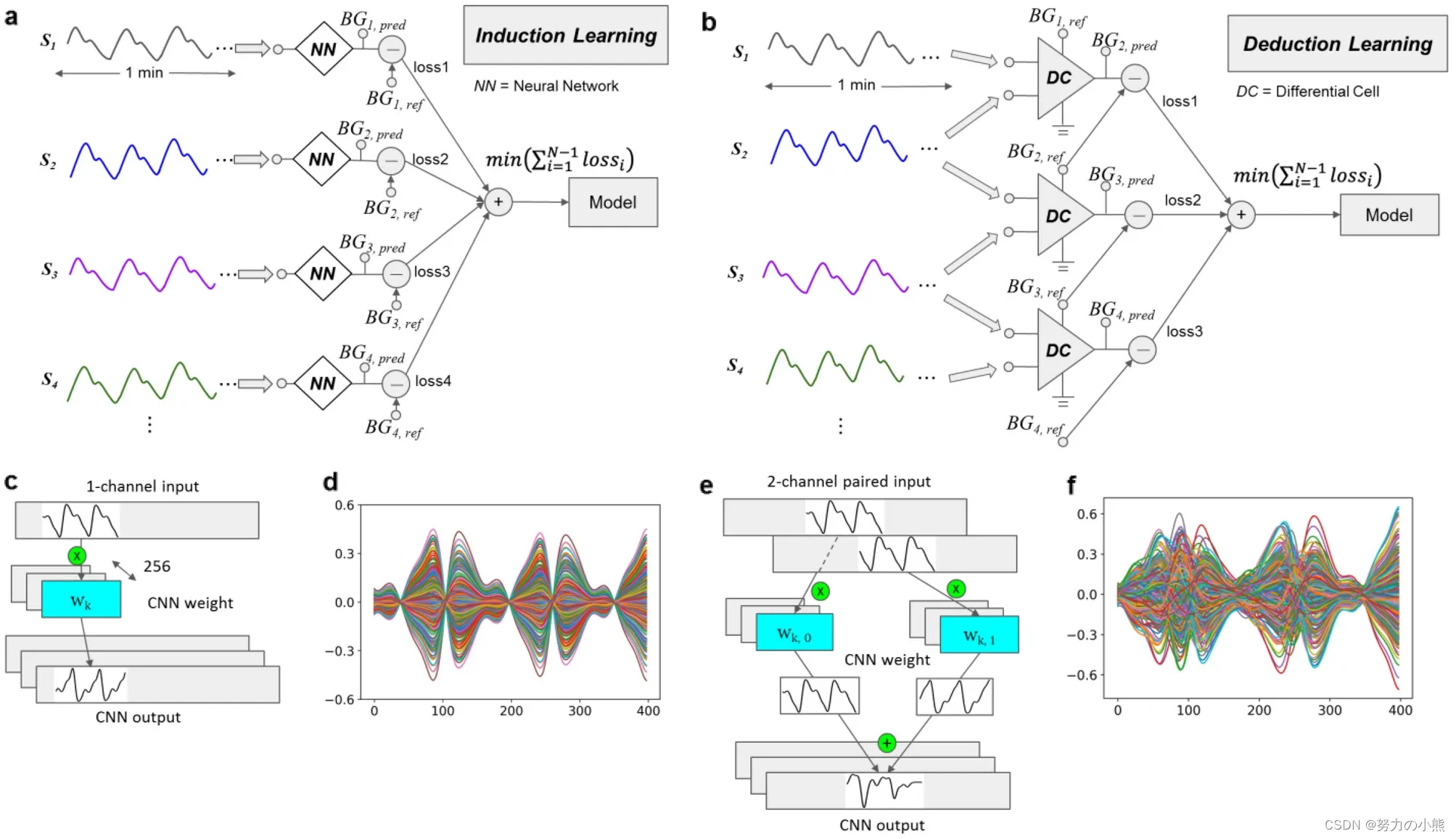
在本文中,DL指的是Deduction Learning,即演绎学习方法。该方法是一种机器学习方法,通过使用逻辑推理和归纳推理来构建模型。与传统的归纳学习方法不同,演绎学习方法可以利用领域知识和先验信息来提高模型的训练效率和泛化能力。在本文中,作者使用演绎学习方法来训练个性化模型,以实现精确无创血糖测量的目标。
1 论文摘要
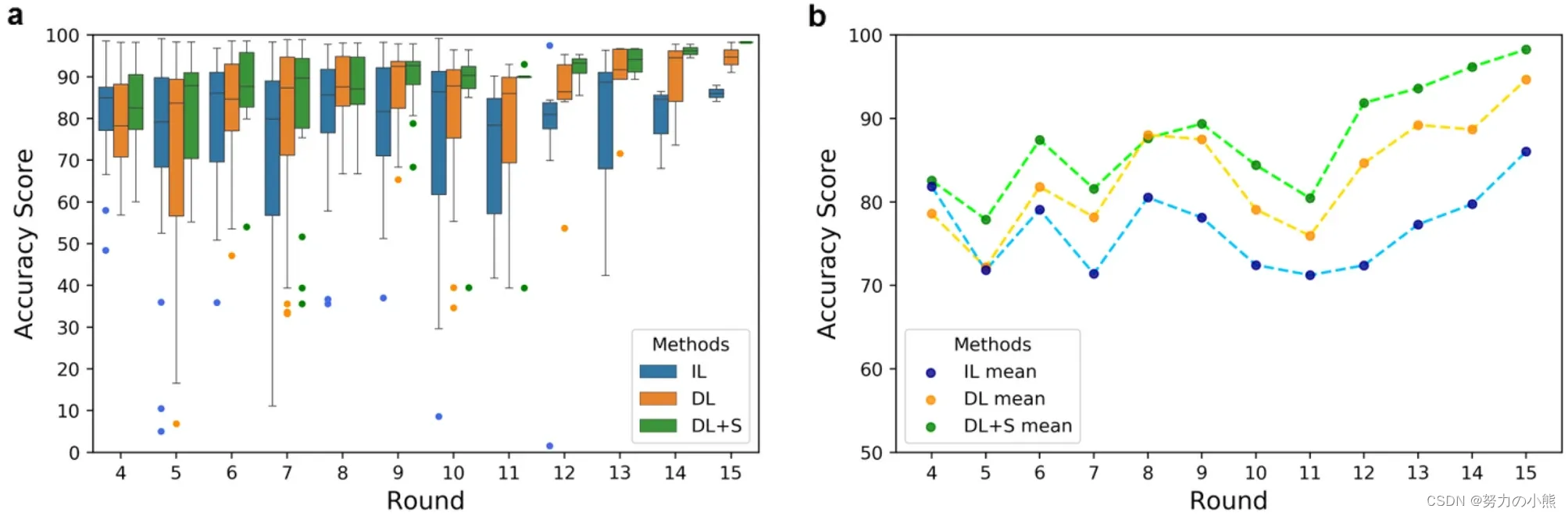
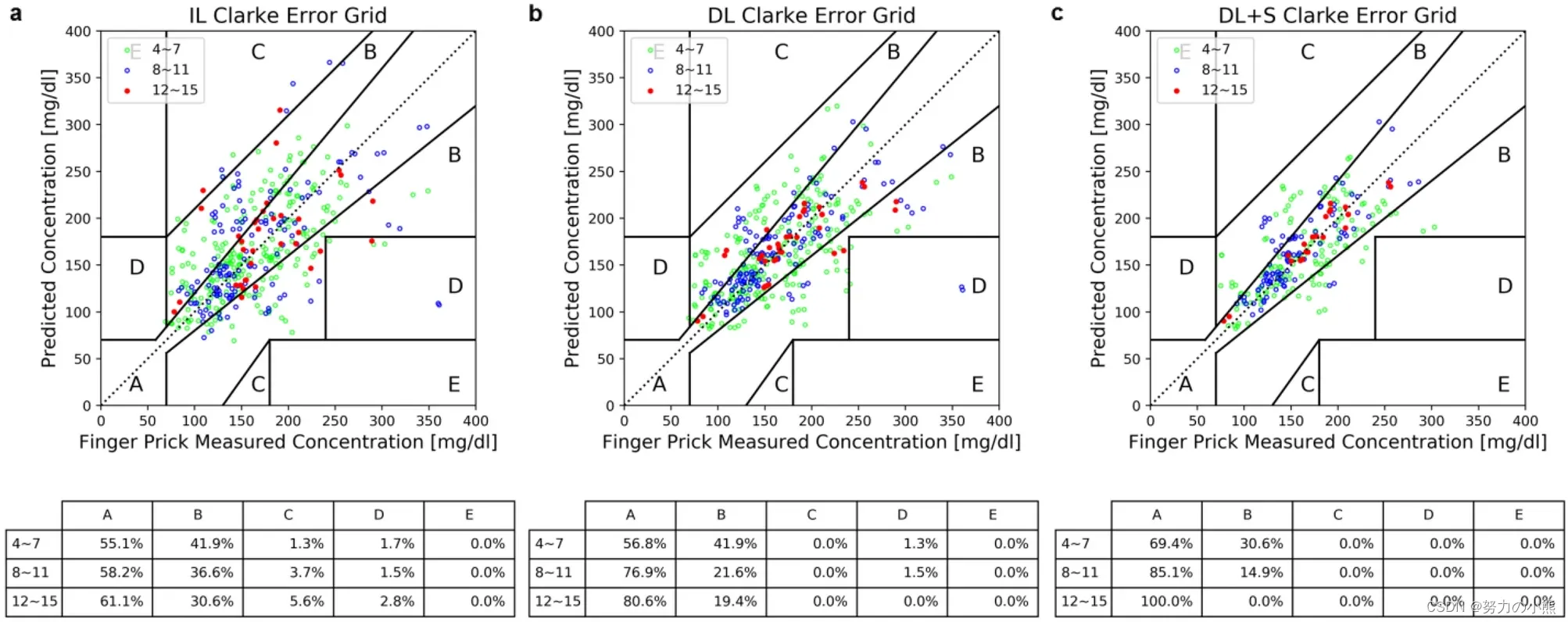
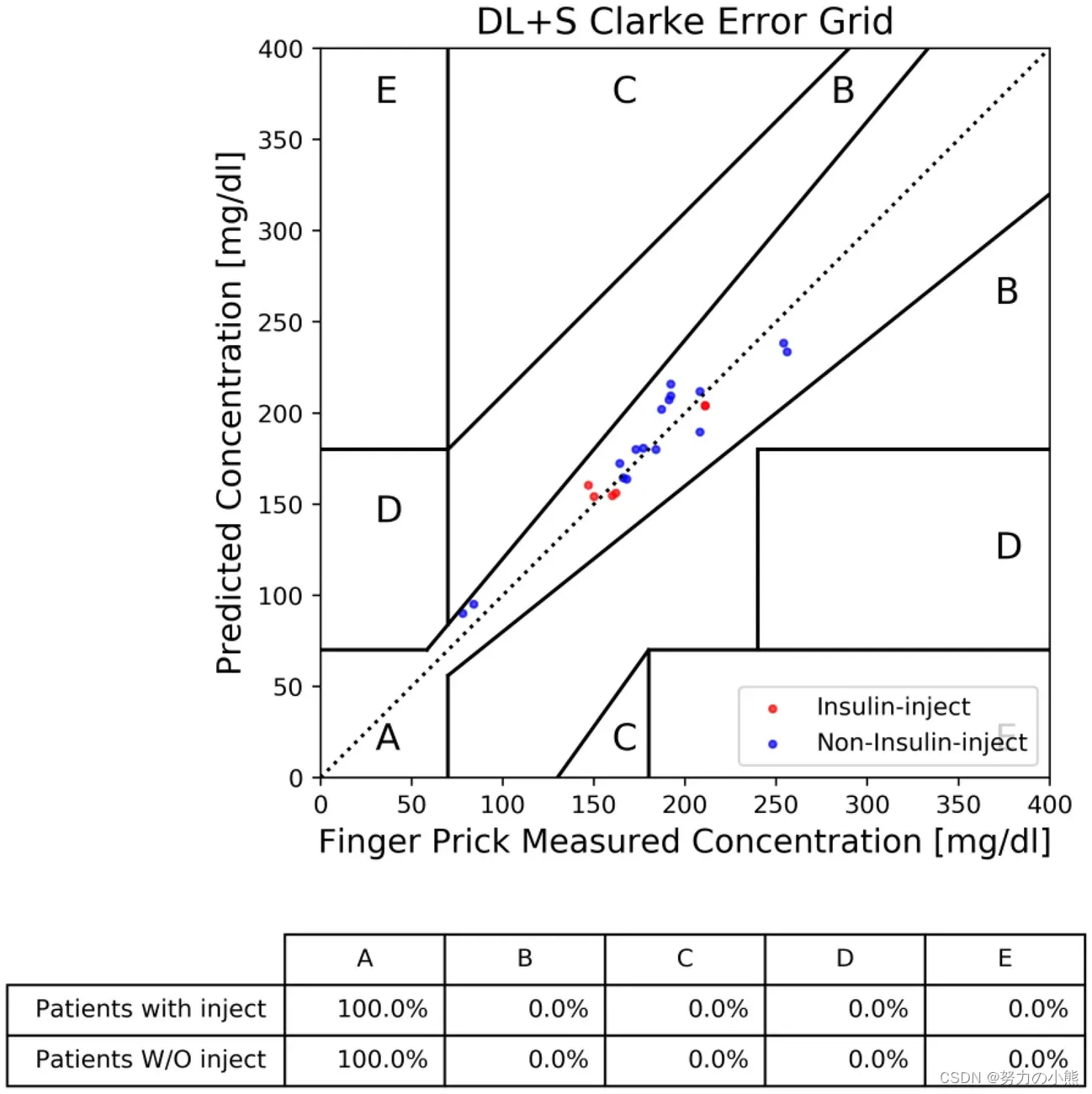
个性化建模长期以来一直被期望用于接近精确的无创血糖测量,但受限于用于训练个人模型的有限数据以及不可避免的异常预测。为了克服这些长期存在的问题,我们通过创新的演绎学习(DL),而非传统的归纳学习(IL)方法,在有限的个人数据中大大提高了训练效率。我们演绎方法(DL)的领域理论利用累积的配对输入比较来纠正之前测量的血糖,从而构建了我们的深度神经网络结构。DL方法涉及将配对相邻轮次的指尖脉动光电容积图信号记录作为输入,应用于基于卷积神经网络(CNN)的深度学习模型。我们的研究发现,与IL模型相比,DL模型的CNN滤波器产生了额外的、非均匀的特征模式,这表明在有限训练数据下,DL在学习效率方面优于IL。在我们招募的30名糖尿病患者志愿者中,使用12轮数据进行模型训练的DL模型在Clarke错误网格(CEG)的A区域达到了80%的测试预测,比IL方法提高了20%。此外,我们开发了一种自动筛选算法来删除低置信度的异常预测。仅使用十几轮训练数据,DL模型结合自动筛选实现了相关系数(RP)为0.81、准确率得分(RA)为93.5、均方根误差为13.93 mg/dl、平均绝对误差为12.07 mg/dl,以及CEG A区域内的100%预测。非参数Wilcoxon配对检验在DL与IL的RA上显示了接近显著差异,p值为0.06。这些显著的改进表明,可以实现非常简单和精确的无创血糖浓度测量。
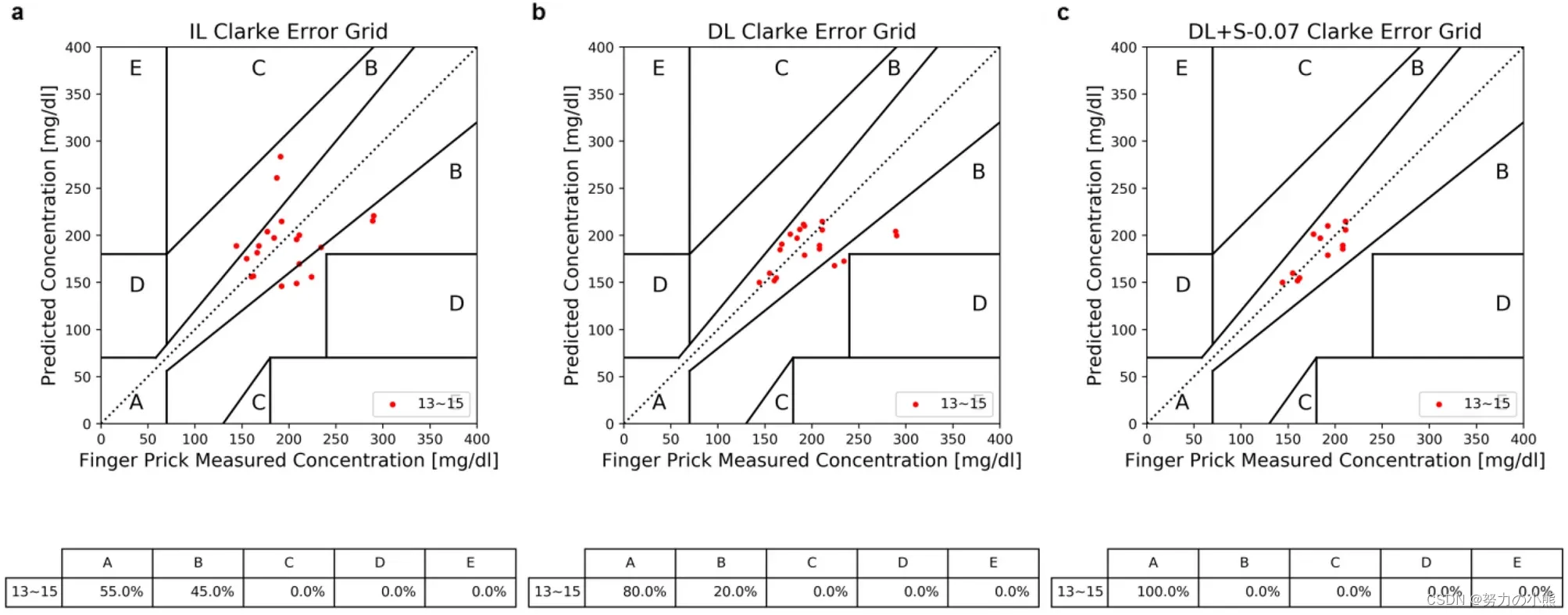
2 论文十问
Q1:论文试图解决什么问题?
A1:这篇论文试图解决精确无创血糖测量的问题。
Q2:这是否是一个新的问题?
A2:不完全是。虽然精确无创血糖测量一直是一个挑战,但已经有相关研究在这个领域进行了很多工作。
Q3:这篇文章要验证一个什么科学假设?
A3:这篇文章要验证使用归纳学习和演绎学习方法来训练个性化模型,以实现精确无创血糖测量的可行性。
Q4:有哪些相关研究?如何归类?谁是这一课题在领域内值得关注的研究员?
A4:相关研究包括使用光谱分析、光学技术、声波技术等方法进行无创血糖测量。这些方法可以归类为物理方法和计算机视觉方法。在领域内值得关注的研究员包括Wei-Ru Lu、Wen-Tse Yang等人。
Q5:论文中提到的解决方案之关键是什么?
A5:论文中提到的解决方案之关键是使用演绎学习方法来训练个性化模型,以提高训练效率和避免异常预测。
Q6:论文中的实验是如何设计的?
A6:论文中的实验设计包括使用归纳学习和演绎学习方法来训练模型,并使用数据集进行测试和评估。
Q7:用于定量评估的数据集是什么?代码有没有开源?
A7:用于定量评估的数据集是由作者自己收集的,包括了来自不同人的血糖测量数据。代码已经开源,可以在论文中找到相关链接。
Q8:论文中的实验及结果有没有很好地支持需要验证的科学假设?
A8:是的,论文中的实验和结果表明使用演绎学习方法训练个性化模型可以提高训练效率和避免异常预测,从而支持了需要验证的科学假设。
Q9:这篇论文到底有什么贡献?
A9:这篇论文提出了一种新方法——演绎学习方法,用于解决精确无创血糖测量问题,并证明了该方法在训练效率和异常预测方面优于传统归纳学习方法。
Q10:下一步呢?有什么工作可以继续深入?
A10:下一步可以进一步探索演绎学习方法在其他医疗领域中的应用,并进一步改进该方法以提高精度和可靠性。
3 论文亮点与不足之处
本文的亮点在于提出了一种新的演绎学习方法,用于解决精确无创血糖测量问题,并证明了该方法在训练效率和异常预测方面优于传统归纳学习方法。实验设计合理,结果准确可靠。
然而,本文的不足之处在于使用的数据集较小,可能存在一定的局限性。此外,模型的泛化能力还需要进一步验证。
4 与其他研究的比较
与其他相关研究相比,本文提出了一种新颖的演绎学习方法来解决精确无创血糖测量问题。相较于传统归纳学习方法,该方法在训练效率和异常预测方面表现更好。此外,本文还对CNN模型进行了深入分析,并探索了其生成非均匀特征模式的原因。
5 实际应用与影响
本文提出的演绎学习方法可以为精确无创血糖测量提供新思路和解决方案。该方法可以帮助医生更准确地监测患者的血糖水平,并及时采取措施。此外,该方法还可以应用于其他医疗领域,如心率监测、血压监测等。
6 个人思考与启示
本文的阅读让我深刻认识到演绎学习方法在机器学习领域中的重要性。同时,也让我意识到数据集的大小对模型训练和泛化能力的影响。在未来的研究中,需要更加注重数据集的质量和数量,并探索更多的机器学习方法来解决实际问题。此外,本文还启示我们要关注医疗领域中的实际问题,并探索如何将机器学习方法应用于医疗领域,为人类健康事业做出贡献。
参考文献
Lu, WR., Yang, WT., Chu, J. et al. Deduction learning for precise noninvasive measurements of blood glucose with a dozen rounds of data for model training. Sci Rep 12, 6506 (2022). https://doi.org/10.1038/s41598-022-10360-3