ElasticSearch学习随笔之分词算法
ElasticSearch
1、ElasticSearch学习随笔之基础介绍
2、ElasticSearch学习随笔之简单操作
3、ElasticSearch学习随笔之java api 操作
4、ElasticSearch学习随笔之SpringBoot Starter 操作
5、ElasticSearch学习随笔之嵌套操作
6、ElasticSearch学习随笔之分词算法
ElasticSearch,创始人 Shay Banon(谢巴农)
本文主要讲解ElasticSearch 主要使用的分词算法。
文章目录
- ElasticSearch
- 前言
- 一、TF-IDF
- 二、BM25
- 三、Explain查看TF-IDF
前言
本文主要对ElasticSearch分词算法进行简单讲解,在了解算法之前,我们先要知道两点,什么是相关性和相关性算分。
站在用户的角度来看,检索是什么呢?检索是用户通过关键词查找针对这个关键词比较有相关性的结果,也就是说,用户其实主要关系的是搜索结果的相关性,主要涉及以下几个问题:
- 是否找到所有相关的内容。
- 是否得到了很多内容是不相关的。
- 排在最前面的搜索结果打分是否合理。
- 结合需求,结果排名是否平衡。
那如何衡量相关性呢?主要看三点:
- Precision(查准率),尽可能的返回较少的无相关的文档。
- Recall(查全率),尽量返回较多的相关的文档。
- Ranking(排序),能够按照相关性进行排序。
所以,相关性算分,描述了一个文档和查询语句匹配的程度。在 query 方式检索时,ES 会对每个匹配结果进行算分(_score)。打分的本质就是排序,把分值最高的放在最前面展示给用户。
在ES5之前使用的是 TF-IDF 算法,后面到现在8.x版本使用 BM25 算法。
一、TF-IDF
TF-IDF(Term frequency - inverse document frequency)是一种用户信息检索与数据挖掘的常用的加权技术,公认为是信息检索领域最重要的发明,而且在文献分类等其他相关领域应用非常广泛。
IDF 的概念,最早是剑桥大学的一个大佬(斯巴克.琼斯)提出来的,1972年——“关键词特殊性的统计解释和它在文献检索中的应用”,但是没有从理论上解释IDF应该是用log(全部文档数/检索词出现过的文档总数),而不是其他函数,也没有做进一步的研究,1970,1980年代萨尔顿和罗宾逊,进行了进一步的证明和研究,并用香农信息论做了证明http://www.staff.city.ac.uk/~sb317/papers/foundations_bm25_review.pdf,现代搜索引擎,对TF-IDF进行了大量细微的优化。
Lucene中的TF-IDF评分公式:
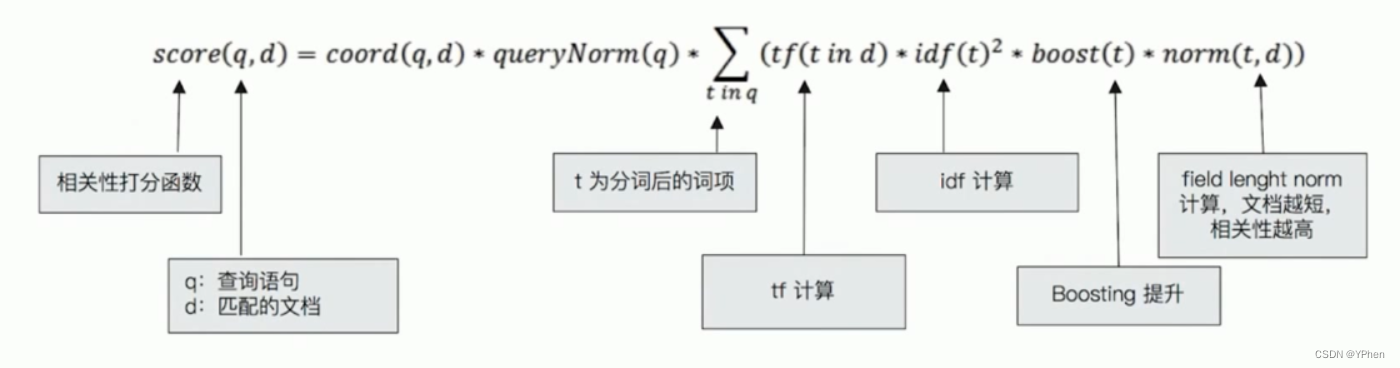
主要看这里:
- TF(Term frequency)是词频
- 检查的关键词在文档中出现的频率越高,相关性越高。
- IDF(Inverse document frequency)是逆向文本频率
- 每个检索词在索引中出现的频率,频率越高,相关性越低。
- 字段长度归一值(Field-length norm)
- 字段的长度是多少?字段越短,字段的权重越高。检索词出现在一个内容短的字段(title)要比出现在一个内容长的字段(content)权重更大。
以上三个因素 TF、IDF、Field-length norm 一起计算单个词在特定文档中的权重。
二、BM25
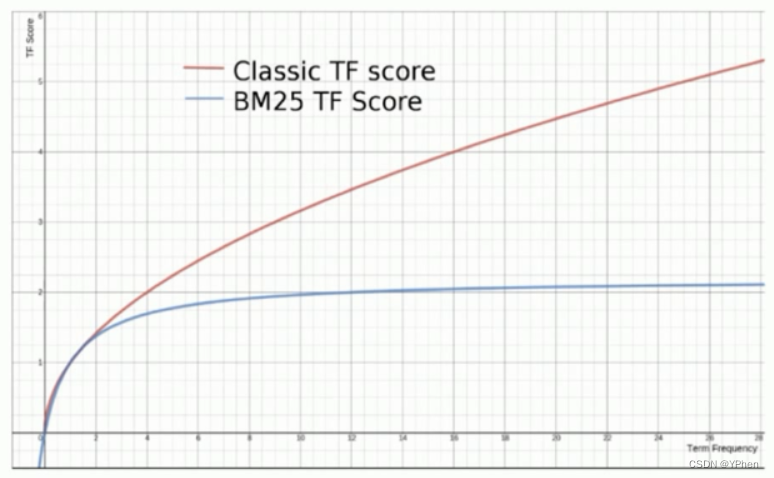
BM25 是对 TF-IDF 算法的改进,在 TD-IDF 算法中,TF 部分的值越大,整个计算公式返回的值就越大。BM25 就是针对这点进行优化的,随着 TF 部分值的逐步增大,那返回的值则会逐步趋于一个数值。
而在 ES 5开始,默认的算法就是 BM25。
当TF无限增加时,BM25算法会趋于一个数值,见下图:
BM25 公式如下:
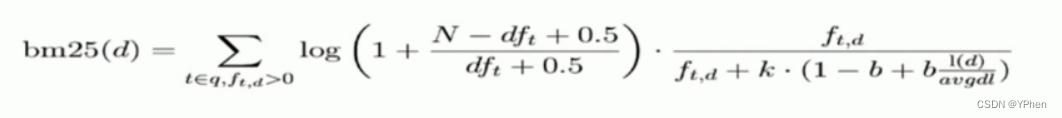
三、Explain查看TF-IDF