计算机组成原理4.2.3提高存储器访问速度的措施
提高存储器访问层次大概有三种方法
-
采用高速器件
-
采用层次结构 Cache 主存
-
调整主存结构
调整存储结构
单体多字系统

利用程序局部性原理,访问一个块 相邻的若干块都会被拿出来,缺点可能会碰到跳转类指令
多体并行系统

高位是体号,低位时地址因此,CPU给出一次存储访问总是对一块连续的存储单元进行的,在多CPU系统中,不同的CPU访问不同的存储块,达到并行工作。
 这种做法可以在不改变存取周期的前提下,提高存储器带宽,因为可以在一个访问周期下,访问多个不同的存储体。适用于单处理器系统
这种做法可以在不改变存取周期的前提下,提高存储器带宽,因为可以在一个访问周期下,访问多个不同的存储体。适用于单处理器系统简要说明高位交叉和低位交叉提高访存速度的原因
- 高位交叉各个体分别响应不同请求源的请求,实现多体并行 高位体号 低位地址
- 低位交叉不改变存取周期的情况下增加存储带宽 低位体号 高位地址
 多个存储体并行访问,所以最后的是32*8=256,8-1=7
多个存储体并行访问,所以最后的是32*8=256,8-1=7
低位交叉指令流水的工作过程

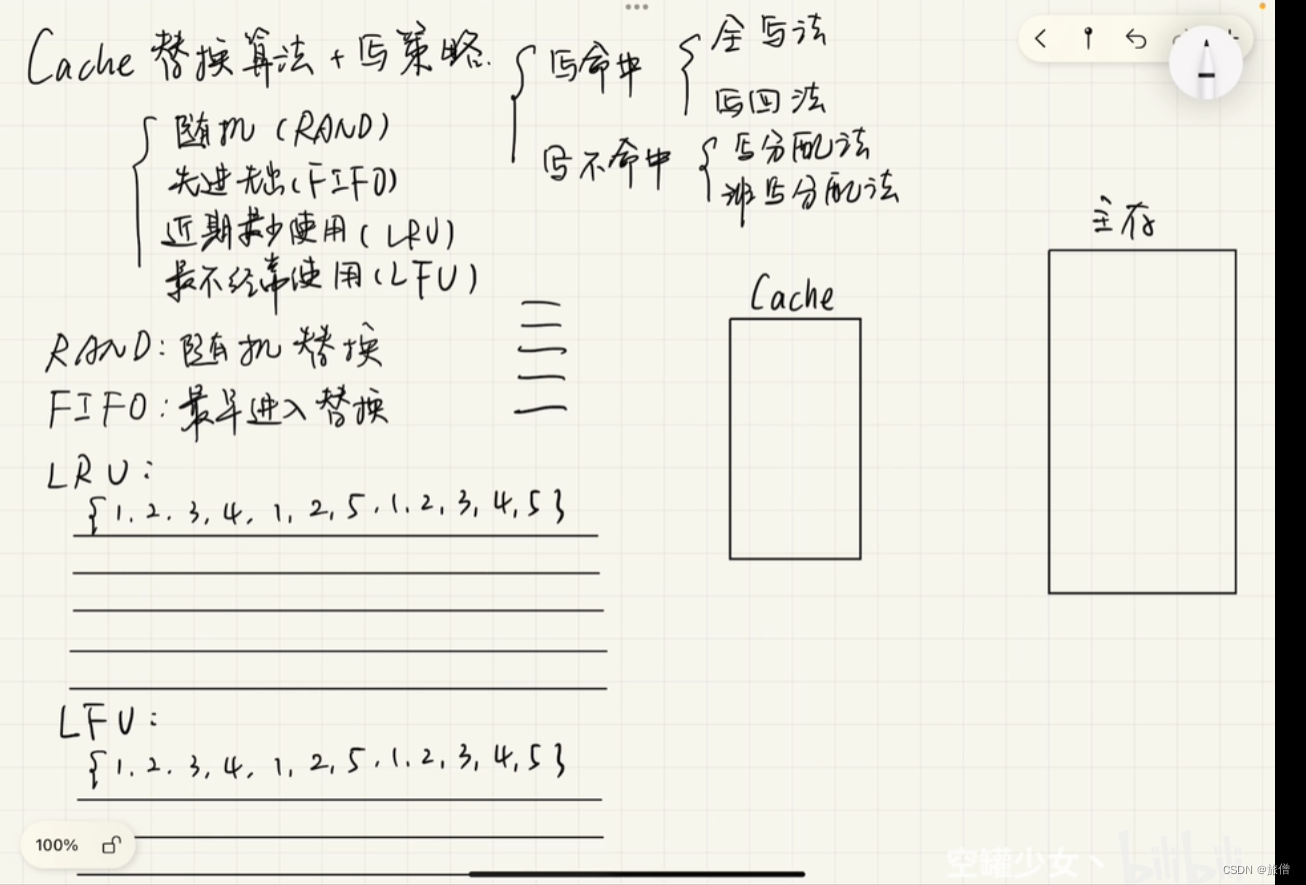
Cache的设计
为了保持cache和主存内容的一致性,采用写直达法和写回法两种策略。
为了能加快访问速度,采用映射的方法,这里需要注意算法和替换策略
使用告诉缓存器是为了解决CPU和主存速度不匹配问题,缓存的地址对用户来说是透明的。存储管理主要是通过硬件来实现没使用虚拟存储器主要是为了解决容量问题,存储管理主要由操作系统和硬件来实现,CPU不直接访问第二级存储器。
Cache的容量和命中率有关。
Cache和主存的地址映射
直接映射
指令格式

每个cache可以对应若干个主存但是每个主存只能对应一个cache
映射算法:i = j mod C

例题



全相联映射
指令格式


主存 中的 任一块 可以映射到 缓存 中的 任一块


在缓存-主存的地址映射中全相联映射的灵活性最强,全相联映射的成本最高。
组相联映射和多路组相联
指令格式



注意:几路组相联是看多少个是一组


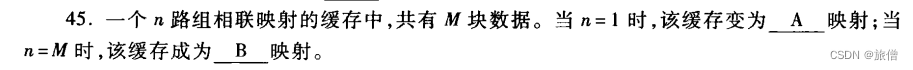 直接 全相联映射
直接 全相联映射
 注意:几路组相联是看多少个是一组
注意:几路组相联是看多少个是一组
块长是16B 四个块为一组 每一组是64B 所以一共有16KB/64B=2^8组,所以就看倒数第三位和倒数第二位就行,最后一位的A是块内偏移量 C*16+B=203

同理 26F
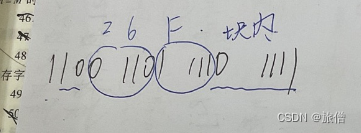



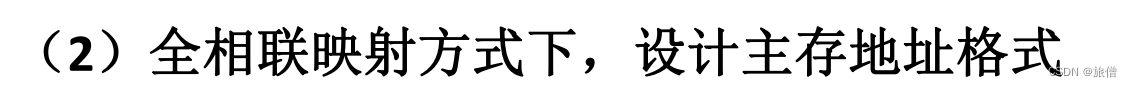



多级存储系统方法: