MySQL基础
MySQL的C/S模式
mysql #客户端程序
mysqld #服务端程序,再修改配置后需要重新启动服务端 systemctl restart mysqld
设置开机启动
#开启开机⾃启动
systemctl enable mysqld
systemctl daemon-reload
mysql文件的存放路径
默认情况下msql文件从存储路径为
/var/lib/mysql
数据库服务器,数据库,表关系
- 所谓安装数据库服务器,只是在机器上安装了一个数据库管理系统程序,这个管理程序可以管理多个数据库,一般开发人员会针对每一个应用创建一个数据库。
- 为保存应用中实体的数据,一般会在数据库中创建多个表,以保存程序中实体的数据。
数据库服务器、数据库和表的关系如下:
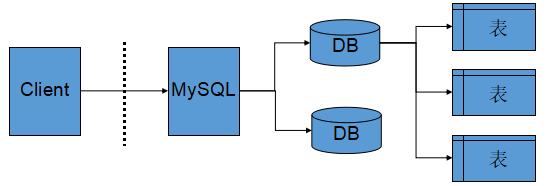
说明:
- 图中的Client对应的就是mysql命令,MySQL对应的就是mysqld服务。
- DB(database)表示的是mysqld管理的多个数据库,而每一个DB下会包含多张表。
什么是数据库
广义上的:以特定的格式保存好的文件,我们叫做数据库。
狭义上的:提供较为便携的存储服务的软件集合
创建数据库和创建表在文件系统下发生了什么?
创建数据库:在默认的存储目录下(默认是/var/lib/mysql)创建一个同名的目录。
我的数据库的路径为 :/data/mysql
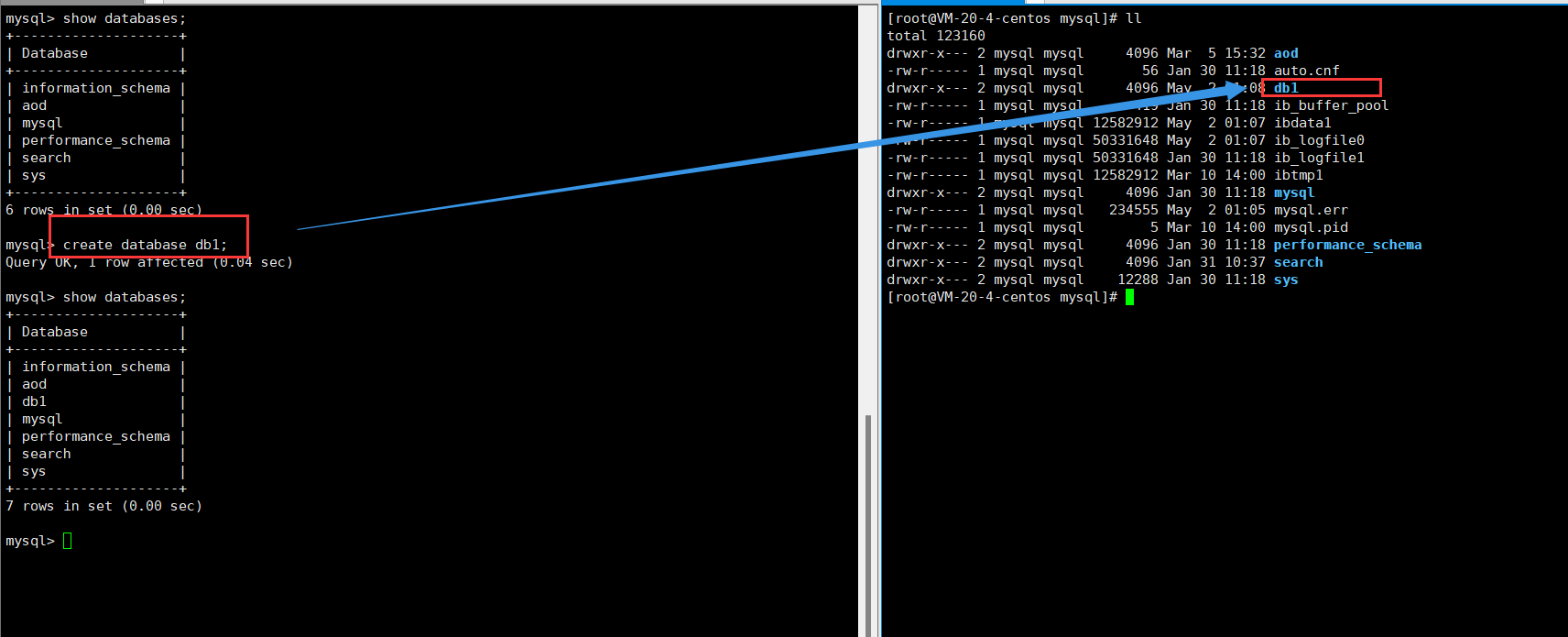
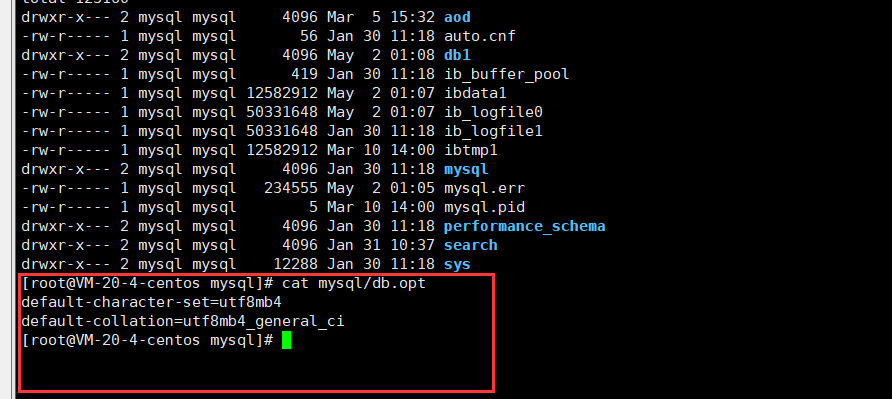
在数据库的目录下有一个名为的db.opt的文件,该文件中指明了当前数据库的默认字符编码和字符校验规则。如下:
cat online_d1/db.opt可以查看对应的字符集和校验方式。
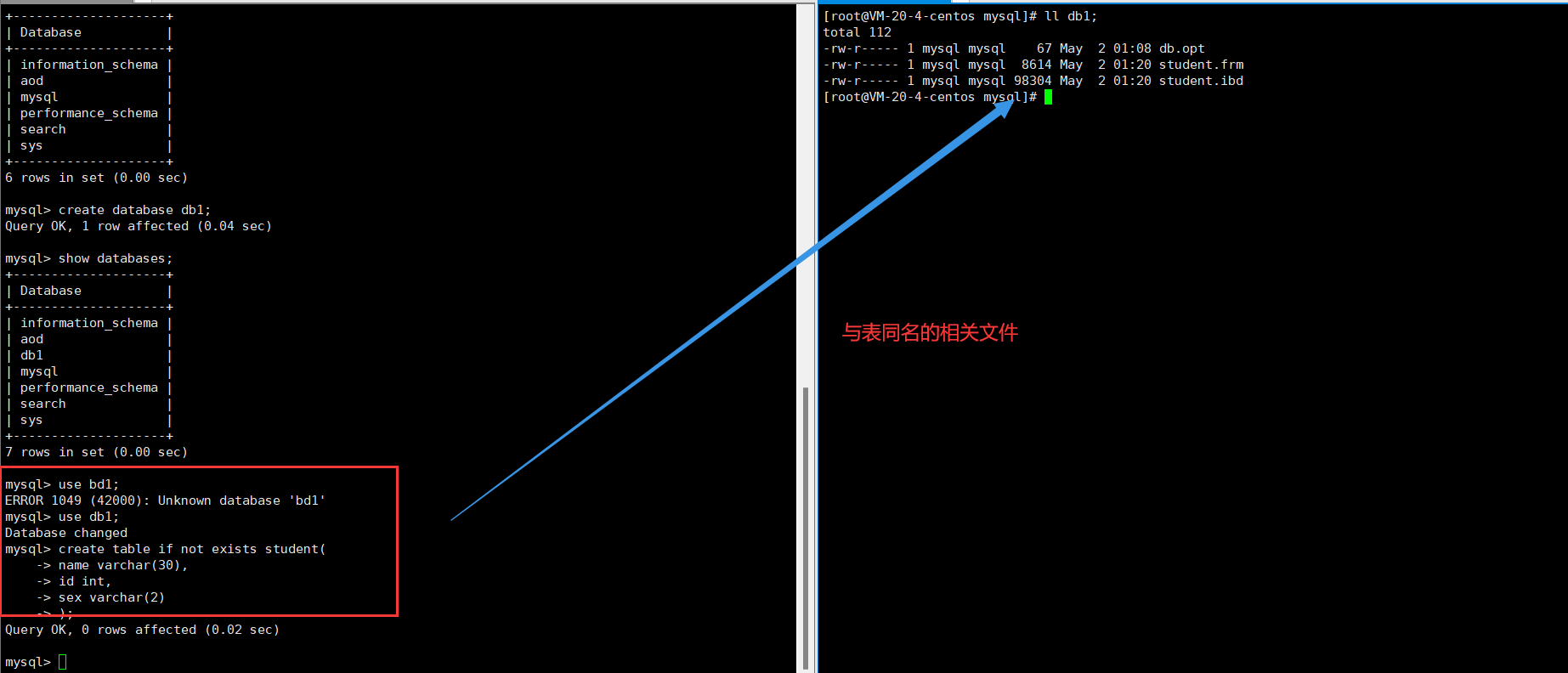
创建表:在数据库中创建一个表,本质上是在该数据库的目录下创建表对应的文件(包括索引文件,数据文件,结构文件)。
MySQL架构
MySQL 是一个可移植的数据库,几乎能在当前所有的操作系统上运行,如 Unix/Linux、Windows、Mac 和 Solaris。各种系统在底层实现方面各有不同,但是 MySQL 基本上能保证在各个平台上的物理体系结构的一致性。
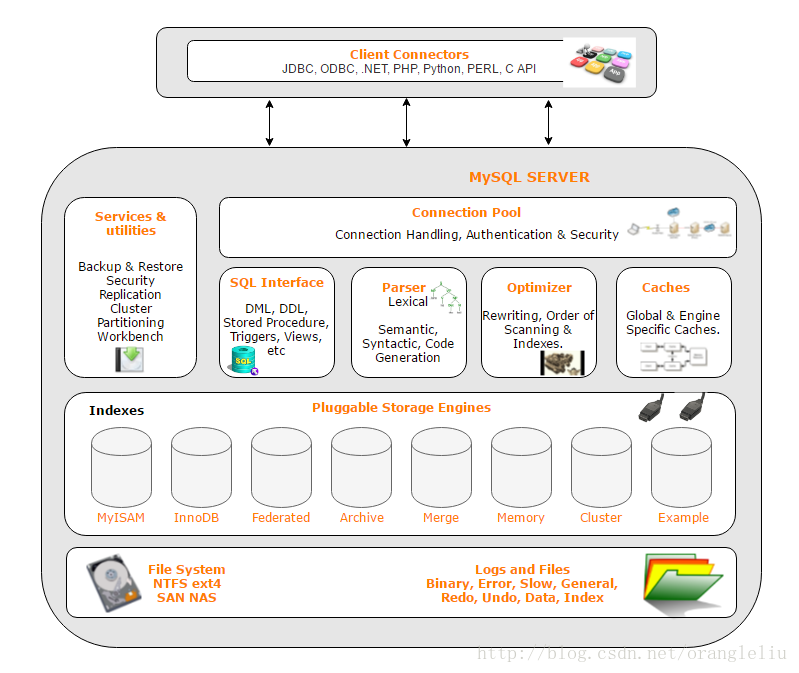
MySQL架构主要可分为如下四层:
- 连接层:主要完成一些类似连接处理,授权认证及相关的安全方案。
- 服务层:在MySQL数据库系统处理底层数据之前的所有工作都是在这一层完成的,包括权限判断、SQL接口、SQL解析、SQL分析优化、缓存查询的处理以及部分内置函数执行等。各个存储引擎提供的功能都集中在这一层,如存储过程、触发器、试图等。
- 引擎层:由多种可拔插的存储引擎共同组成,真正负责MySQL中数据的存储和提取,每个存储引擎都有自己的优点和缺陷,服务层是通过存储引擎API来与它们交互的。MySQL的核心是插件式存储引擎,支持多种存储引擎。
- 存储层:将数据存储在裸设备的文件系统之上,完成存储引擎的交互。
MySQL客户端
前面提到MySQL是基于C/S模式。用户通过MySQL客户端编写SQL语句。MySQL服务器会收到MySQL客户端发来的SQL语句,并根据SQL语句执行对应的操作。
- MySQL客户端不仅仅指的是连接MySQL时使用的mysql命令,MySQL客户端还包括语言接口客户端。
- MySQL给各种语言提供的用于访问数据库的接口,用户通过调用这些接口也可以向MySQL服务器发送SQL语句。
mysql的本质是一个可执行文件,通过ldd命令可以看到mysql依赖了很多的C库。

SQL分类
SQL (Structured Query Language) 是具有数据操纵和数据定义等多种功能的数据库语言,这种语言具有交互性特点,能为用户提供极大的便利,数据库管理系统应充分利用SQL语言提高计算机应用系统的工作质量与效率。
- DDL【data definition language】 数据定义语言,用来维护存储数据的结构。代表指令: create, drop, alter
- DML【data manipulation language】 数据操纵语言,用来对数据进行操作。代表指令: insert,delete,update
- DML中又单独分了一个DQL,数据查询语言,代表指令: select
- DCL【Data Control Language】 数据控制语言,主要负责权限管理和事务。代表指令: grant,revoke,commit
MySQL的存储引擎
存储引擎是:数据库管理系统如何存储数据、如何为存储的数据建立索引和如何更新、查询数据等技术的实现方法。
show engines;
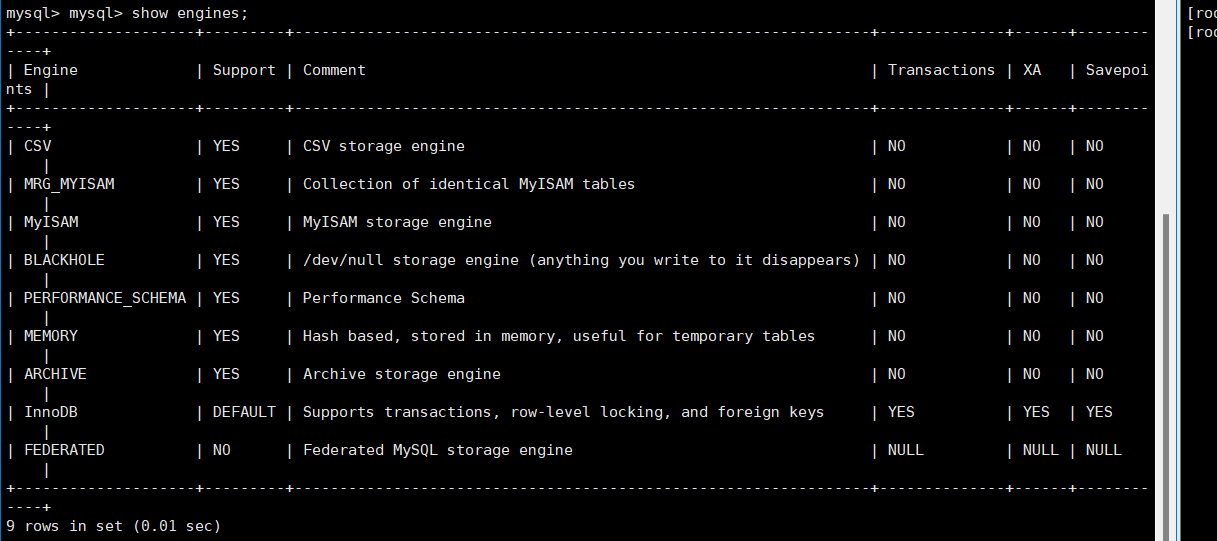
其中MySQL底层默认使用的存储引擎是InnoDB,该存储引擎支持事务、行级锁、外键等。
MyISAM和InnoDB的区别
从上面的对比我们可以看到两者的一部分区别:
- InnoDB 支持事务,MyISAM 不支持,对于 InnoDB 每一条 SQL 语句都默认封装成事务进行提交,这样就会影响速度,优化速度的方式是将多条 SQL 语句放在 begin 和 commit 之间,组成一个事务;
- InnoDB 支持外键,而 MyISAM 不支持。
- InnoDB的数据文件就是索引文件。
所以如果一个表修改要求比较高的事务处理,可以选择 InnoDB。这个数据库中可以将查询要求比较高的表选择 MyISAM 存储。如果该数据库需要一个用于查询的临时表,甚至可以考虑选择 MEMORY 存储引擎。
根据不同的引擎创建表
前面我们说过,创建表会在对应的目录下创建相应的文件:
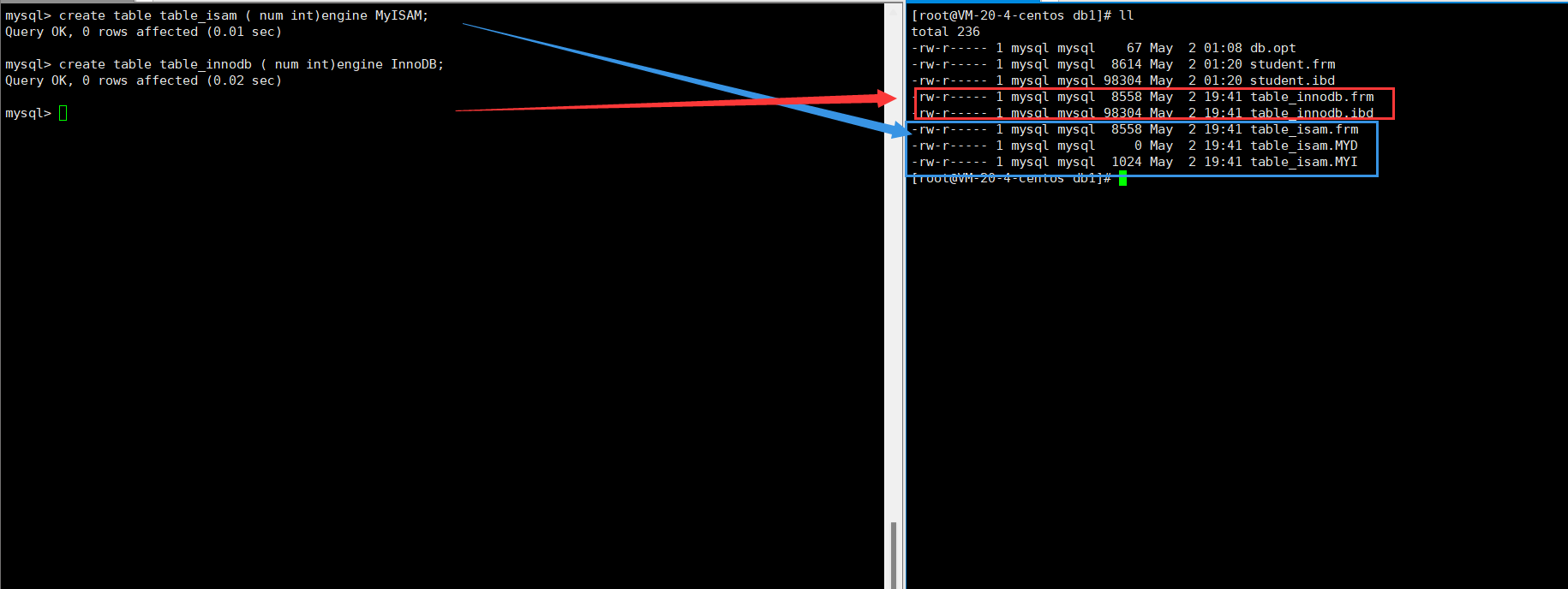
可以看到,MyISAM和InnoDB引擎创建表的存储逻辑并不相同。
存储引擎原理
MyISAM和InnoDB两种引擎所使用的索引数据结构都是B+树,区别在于:
- MyISAM 中 B+ 树的数据结构存储的内容是实际数据的地址值,它的索引和实际数据是分开的,只不过使用索引指向了实际数据。这种索引的模式被称为非聚集索引。
- InnoDB 中 B+ 树的数据结构中存储的都是实际的数据,这种索引有被称为聚集索引。
为什么是B+树?
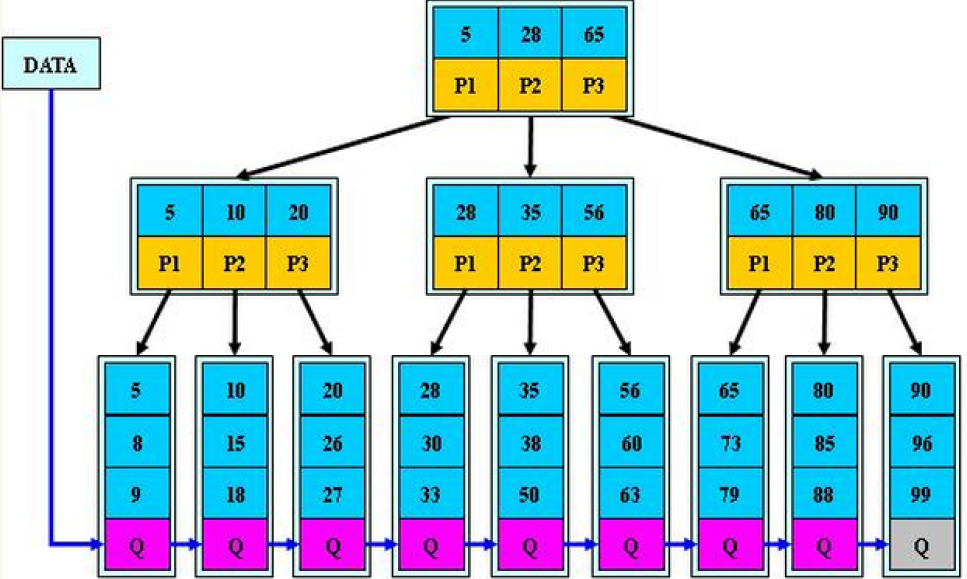
B+树的优势在于查找效率上,具体说明:
首先,B+树的查找和B树一样,类似于二叉查找树。起始于根节点,自顶向下遍历树,选择其分离值在要查找值的任意一边的子指针。在节点内部典型的使用是二分查找来确定这个位置。
(1)不同的是,B+树中间节点没有卫星数据(索引元素所指向的数据记录),只有索引,而B树每个结点中的每个关键字都有卫星数据;这就意味着同样的大小的磁盘页可以容纳更多节点元素,在相同的数据量下,B+树更加“矮胖”,IO操作更少
(2)、其次,因为卫星数据的不同,导致查询过程也不同;B树的查找只需找到匹配元素即可,最好情况下查找到根节点,最坏情况下查找到叶子结点,所说性能很不稳定,而B+树每次必须查找到叶子结点,性能稳定
(3)在范围查询方面,B+树的优势更加明显
B树的范围查找需要不断依赖中序遍历。首先二分查找到范围下限,在不断通过中序遍历,知道查找到范围的上限即可。整个过程比较耗时。
而B+树的范围查找则简单了许多。首先通过二分查找,找到范围下限,然后同过叶子结点的链表顺序遍历,直至找到上限即可,整个过程简单许多,效率也比较高。
B+树相对B树的优势:
- 1.单一节点存储更多的元素,使得查询的IO次数更少;
- 2.所有查询都要查找到叶子节点,查询性能稳定;
- 3.所有叶子节点形成有序链表,便于范围查询。
索引原理
- 唯一索引:唯一索引不允许两行具有相同的索引值
- 主键索引:为表定义一个主键将自动创建主键索引,主键索引是唯一索引的特殊类型。主键索引要求主键中的每个值是唯一的,并且不能为空
- 聚集索引(Clustered):表中各行的物理顺序与键值的逻辑(索引)顺序相同,每个表只能有一个
- 非聚集索引(Non-clustered):非聚集索引指定表的逻辑顺序。数据存储在一个位置,索引存储在另一个位置,索引中包含指向数据存储位置的指针。可以有多个,小于 249 个
MyISAM原理
MyISAM是的索引是一种非聚集索引。所以可以看到MyISAM引擎创建的表有三个文件:.frm表示表的结构,.MYD存储表的数据,.MYI存储表的索引。
主键索引
使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址 。以Col1为主键,MyISAM的示意图,可以看出MyISAM的索引文件仅仅保存数据记录的地址。
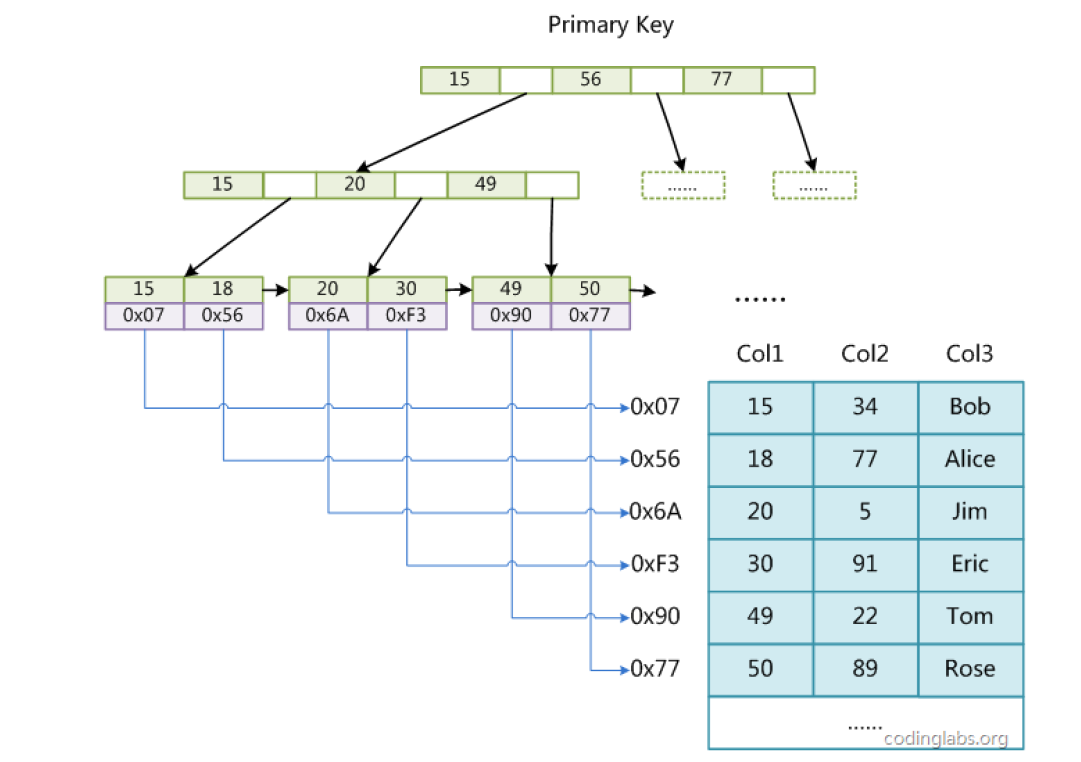
辅助索引
在MyISAM中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复。如果想在Col2上建立一个辅助索引,则此索引的结构如下图所示:

InnoDB原理
由于InnoDB的数据文件就是索引文件,所以可以看到创建一张表对应生成了两个文件:.frm表示表的结构,.idb既是数据文件也是索引文件。
主键索引
而InnoDB索引,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。
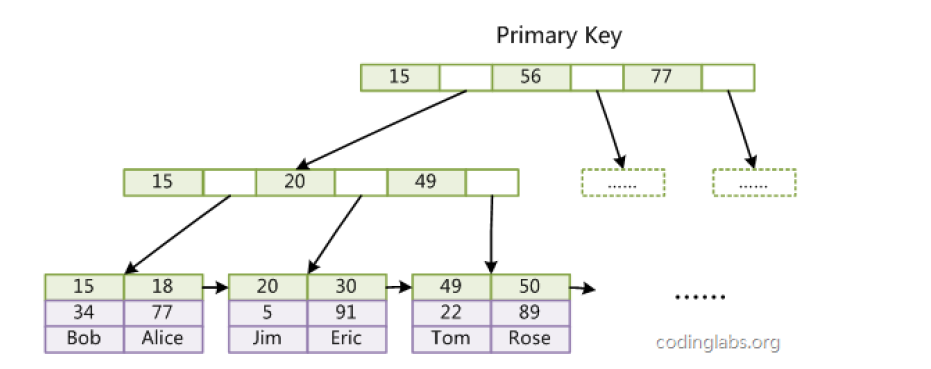
上图是InnoDB主索引(同时也是数据文件)的示意图,可以看到叶节点包含了完整的数据记录,这种索引叫做聚集索引。因为InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键(MyISAM可以没有)。
辅助索引
InnoDB的辅助索引data域存储相应记录主键的值而不是地址,所有辅助索引都引用主键作为data域。聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。
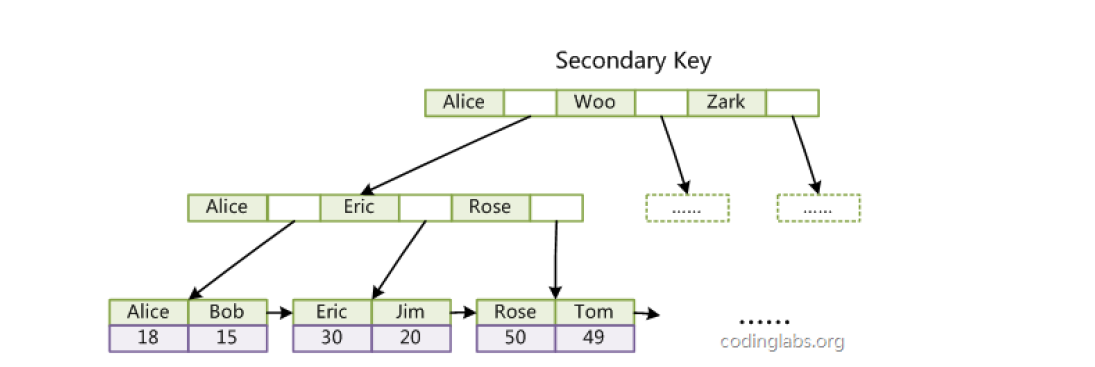
为什么InnoDB不建议使用过长的字段作为主键?
因为所有辅助索引都引用主索引,过长的主索引会令辅助索引变得过大。
为什么用非单调的字段作为主键在InnoDB中不是个好主意?
因为InnoDB数据文件本身是一颗B+Tree,非单调的主键会造成在插入新记录时数据文件为了维持B+Tree的特性而频繁的分裂调整,十分低效,而使用自增字段作为主键则是一个很好的选择。