Elastic 之 elasticsearch 基本操作
一、基本概念
Elasticsearch也是基于Lucene的全文检索库,本质也是存储数据,很多概念与MySQL类似的。
对比关系:
索引(indices)----------------------Databases 数据库
类型(type)--------------------------Table 数据表 [7.x废弃]
文档(Document)----------------------Row 行
字段(Field)-------------------------Columns 列
要注意的是:Elasticsearch本身就是分布式的,因此即便你只有一个节点,Elasticsearch默认也会对你的数据进行分片和副本操作,当你向集群添加新数据时,数据也会在新加入的节点中进行平衡。
二、索引操作
1. 查询索引
查看es中有哪些索引库(类似mysql数据库):GET /_cat/indices?v
# es默认对中文的分词 支持不友好,它认为一个字代表一个词
# 查看es的分词方式
GET _analyze
{
"text": ["我是中国人"]
}
{
"text": "我爱你你爱我"
}
# 给es配置中文分词器:ik分词器
# 指定ik分词器分词:ik_smart粗粒度分词
# ik_max_word细粒度分词
GET _analyze
{
"text": "咖喱人,鸡你太美,你这个老六",
"analyzer": "ik_max_word"
}
es 中会默认存在一个名为.kibana和.kibana_task_manager的索引
| 字段名 | 含义说明 |
|---|---|
| health | green(集群完整) yellow(单点正常、集群不完整) red(单点不正常) |
| status | 是否能使用 |
| index | 索引名 |
| uuid | 索引统一编号 |
| pri | 主节点几个 |
| rep | 从节点几个 |
| docs.count | 文档数 |
| docs.deleted | 文档被删了多少 |
| store.size | 整体占空间大小 |
| pri.store.size | 主节点占 |
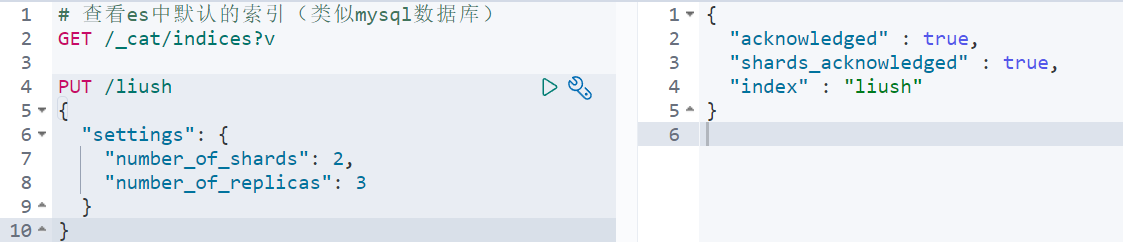
2. 创建索引
PUT /索引名
参数可选:指定分片及副本,默认分片为3,副本为2。
PUT /liush
{
"settings": {
"number_of_shards": 2,
"number_of_replicas": 3
}
}
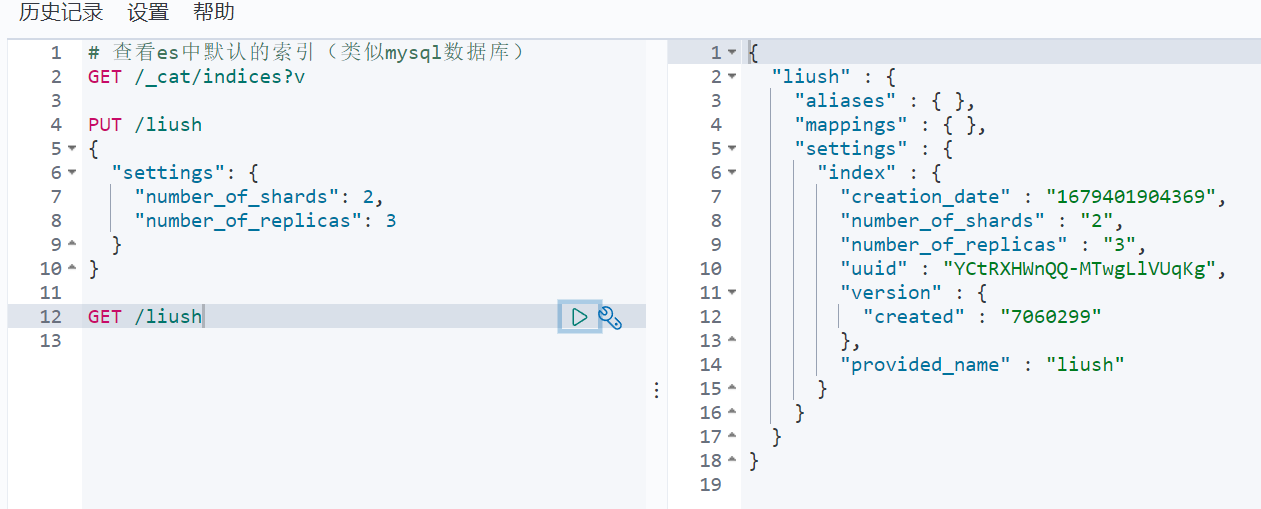
3. 查看索引具体信息
GET /索引名
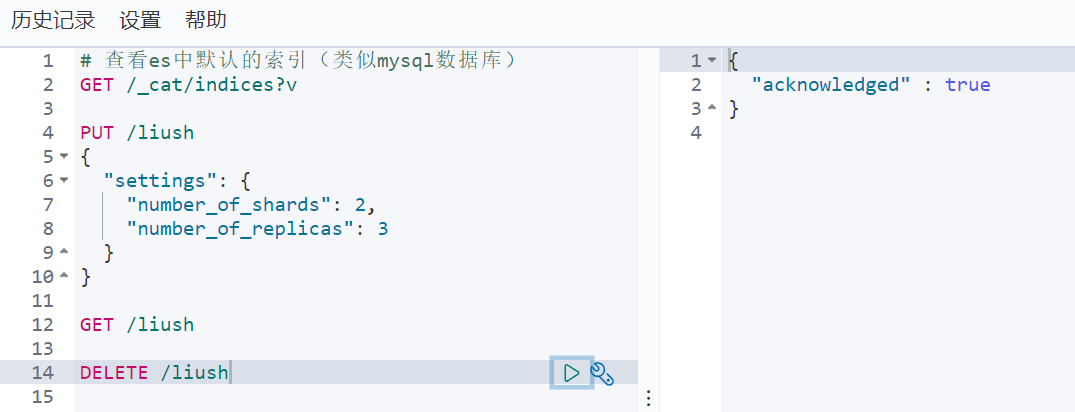
4. 删除索引
DELETE /索引库名
三、映射配置(_mapping)
索引有了,接下来肯定是添加数据。但是,在添加数据之前必须定义映射。
什么是映射?
映射是定义文档的过程,文档包含哪些字段,这些字段是否保存,是否索引,是否分词等
只有配置清楚,Elasticsearch才会帮我们进行索引库的创建(不一定)
1. 创建映射字段
PUT /索引库名/_mapping
{
"properties": {
"字段名": {
"type": "类型",
"index": true,
"store": true,
"analyzer": "分词器"
}
}
}字段名:类似于列名,properties下可以指定许多字段。
每个字段可以有很多属性。例如:
type:类型,String(text keyword) Numeric(long integer float double) date boolean
index:是否索引,默认为true
store:是否存储,默认为false,即使为false也会存储到_source中,如果为true则会额外存储一份
analyzer:分词器,这里使用ik分词器:
ik_max_word或者ik_smart
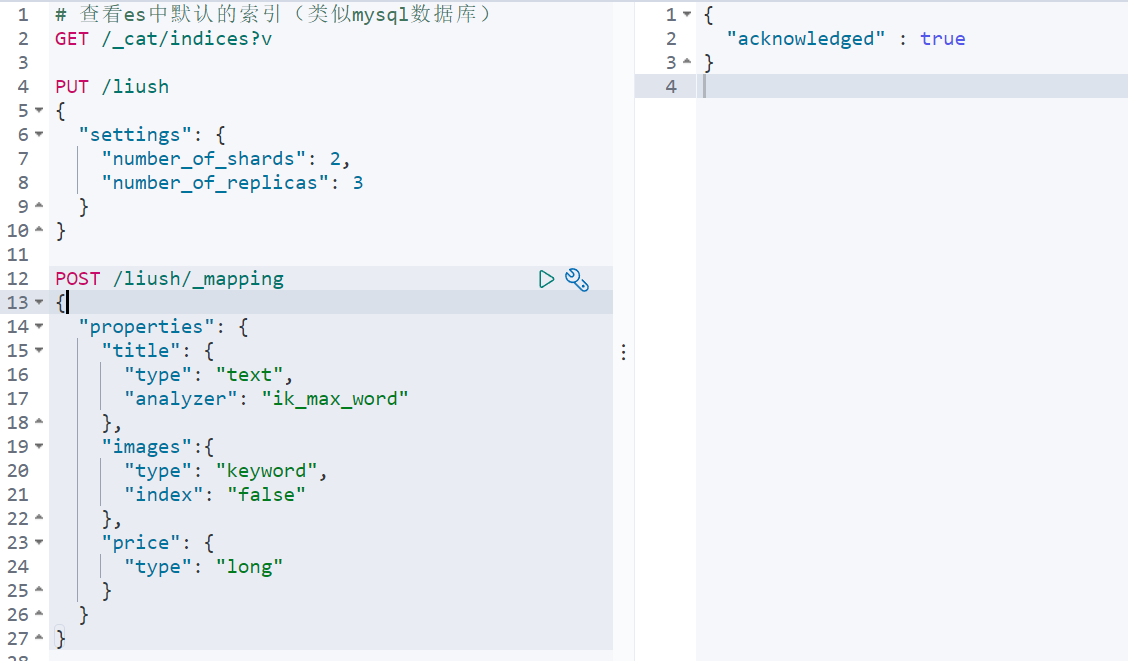
PUT /liush
{
"settings": {
"number_of_shards": 2,
"number_of_replicas": 3
}
}
POST /liush/_mapping
{
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word"
},
"images":{
"type": "keyword",
"index": "false"
},
"price": {
"type": "long"
}
}
}2. 查看映射关系
语法:GET /索引库名/_mapping
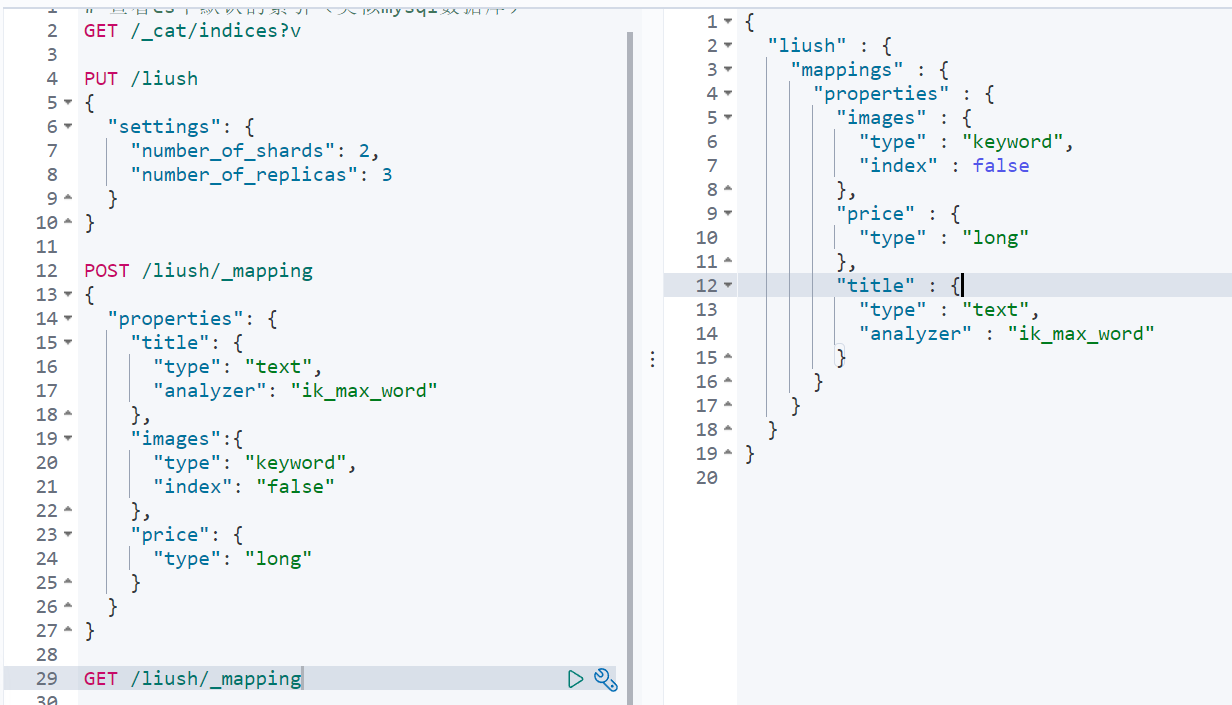
四、新增文档(document)
有了索引、类型和映射,就可以对文档做增删改查操作了。
1. 基本玩法
如果我们想要自己新增的时候指定id,可以这么做:
POST /索引库名/_doc/id值
{
...
}
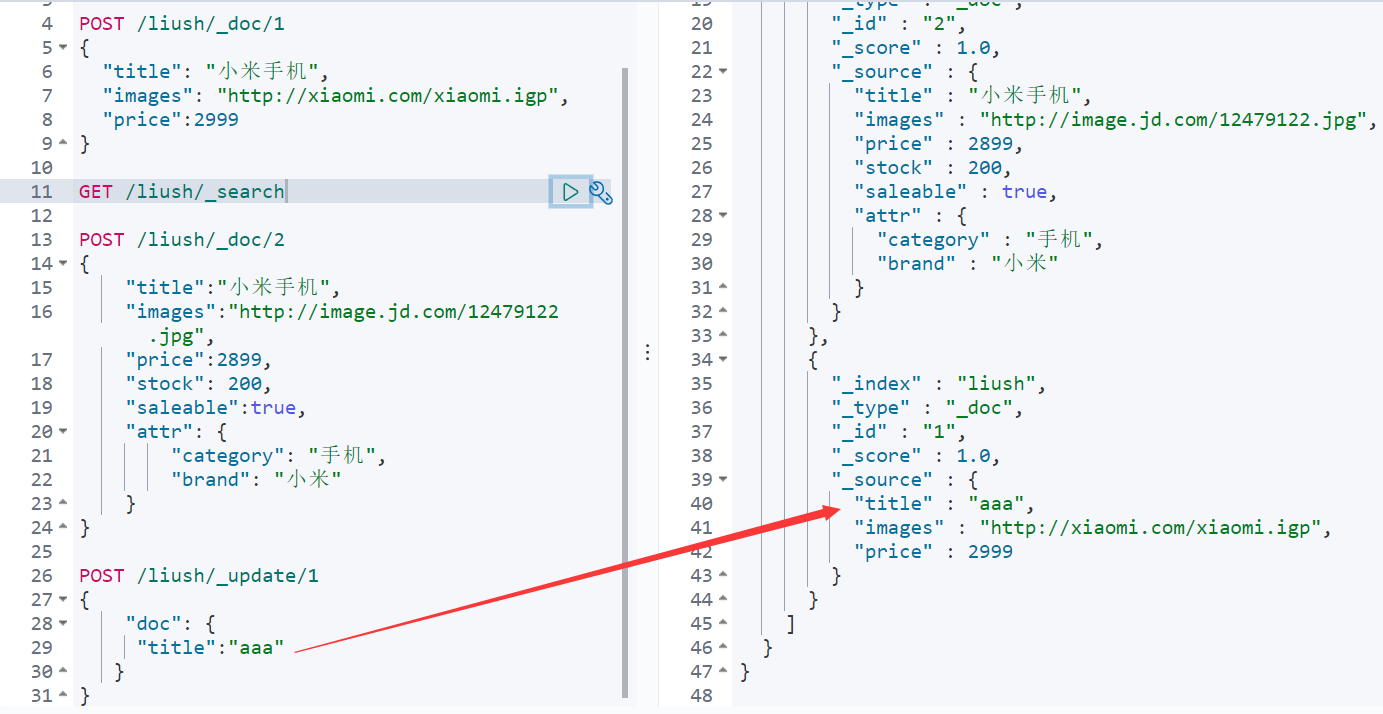
POST /liush/_doc/1
{
"title": "小米手机",
"images": "http://xiaomi.com/xiaomi.igp",
"price":2999
}
GET /liush/_search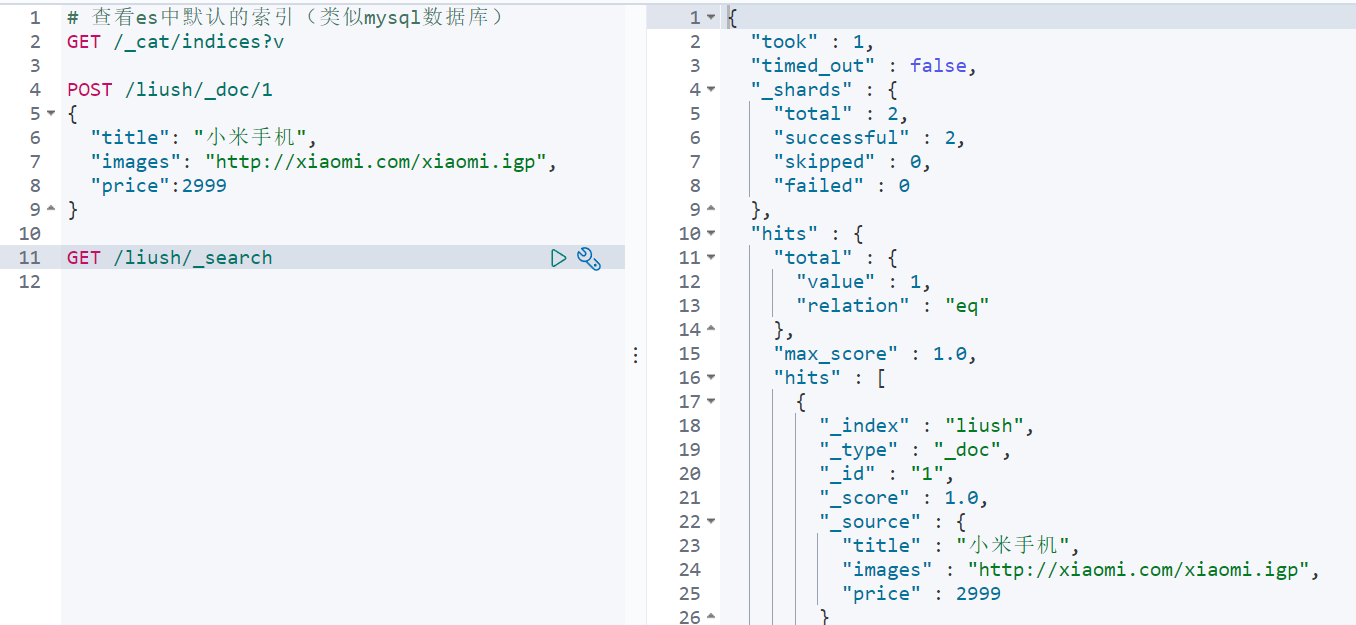
2. 智能判断
事实上Elasticsearch非常智能,你不需要给索引库设置任何mapping映射,它也可以根据你输入的数据来判断类型,动态添加数据映射。
POST /liush/_doc/2
{
"title":"小米手机",
"images":"http://image.jd.com/12479122.jpg",
"price":2899,
"stock": 200,
"saleable":true,
"attr": {
"category": "手机",
"brand": "小米"
}
}我们额外添加了stock库存,saleable是否上架,attr其他属性几个字段。
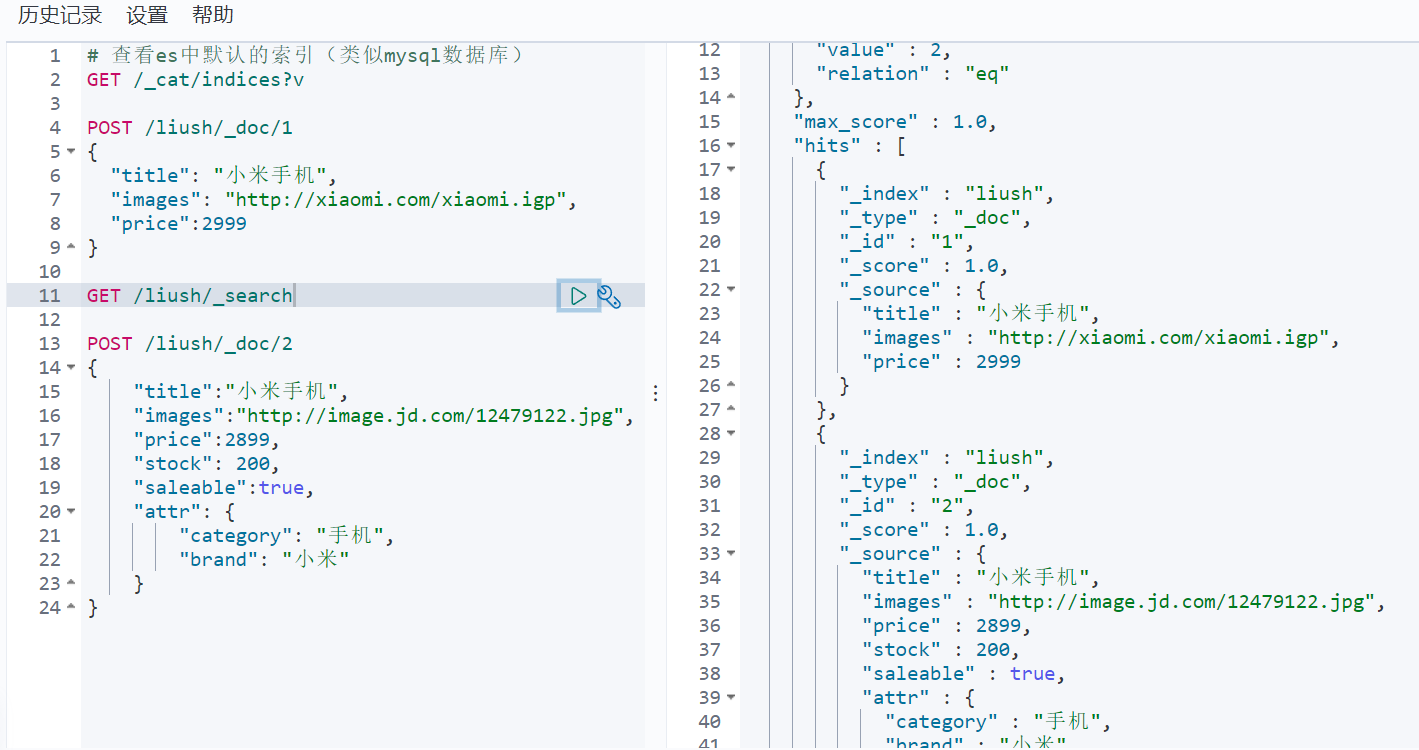
stock,saleable,attr都被成功映射了。
如果是字符串类型的数据,会添加两种类型:text + keyword。如上例中的category 和 brand
五、删除数据
删除使用DELETE请求,同样,需要根据id进行删除:
语法:DELETE /索引库名/_doc/id值
示例:DELETE /liush/_doc/2
六、更新文档
语法:
POST /索引库名/_update/id值
{
doc:{
"属性":"值"
}
}
POST /liush/_update/1
{
"doc": {
"title":"aaa"
}
}