java HashSet 源码分析(深度讲解)
目录
一、前言
二、HashSet简介
三、HashSet的底层实现
四、HashSet的源码解读(断点调试)
0.准备工作 :
1.向集合中添加第一个元素(141) :
①跳入无参构造。
②跳入add方法。
③跳入put方法。
④跳入putVal方法。
⑤跳入resize方法。
⑥跳出resize方法。
⑦跳出putVal方法。
⑧跳出put方法。
⑨跳出add方法。
2.向集合中添加第二个元素("Cyan") :
①跳入putVal方法。
②跳出putVal方法,回到演示类。
3.向集合中添加第三个元素("Cyan"):(重要)
①跳入putVal方法。
②进入putVal方法的else语句。
③解读putVal方法的外层else语句。(详细)
③在else语句中终止putVal函数并逐层跳出。
4.HashMap底层扩容机制演示 :
〇准备工作。
①向集合中添加第1个元素。
②向集合中添加第13个元素。
③向集合中添加第25个元素。
5.HashMap链表树化为红黑树演示 :
〇准备工作。
①将8个元素挂载到数组的同一个链表下。
②将table数组扩容至64。
③进行树化,将链表转为红黑树。
五、完结撒❀
一、前言
大家好,本篇博文是对单列集合Set的实现类HashSet的内容补充。之前在Set集合的万字详解篇,我们只是拿HashSet演示了Set接口中的常用方法,而今天,我们要从底层源码的角度对HashSet进入深入研究。up会利用断点调试(Debug)来一步一步地给大家剖析HashSet底层的扩容机制,以及该集合的特点到底是如何实现的。
注意 : ①解读源码需要扎实的基础,比较适合希望深究的同学; ②不要眼高手低,看会了不代表你会了,自己能全程Debug下来才算有收获; ③点击文章的侧边栏目录或者前面的目录可以进行跳转。 良工不示人以朴,up所有文章都会适时进行补充完善。大家有问题都可以在评论区讨论交流,或者私信up。 感谢阅读!
二、HashSet简介
HashSet是单列集合Set接口的常用实现类之一,满足Set集合"无序,不可重复"的特点。HashSet类属于java.base模块,java.util包下,如下图所示 :

我们再来看一下HashSet的类图,如下 : 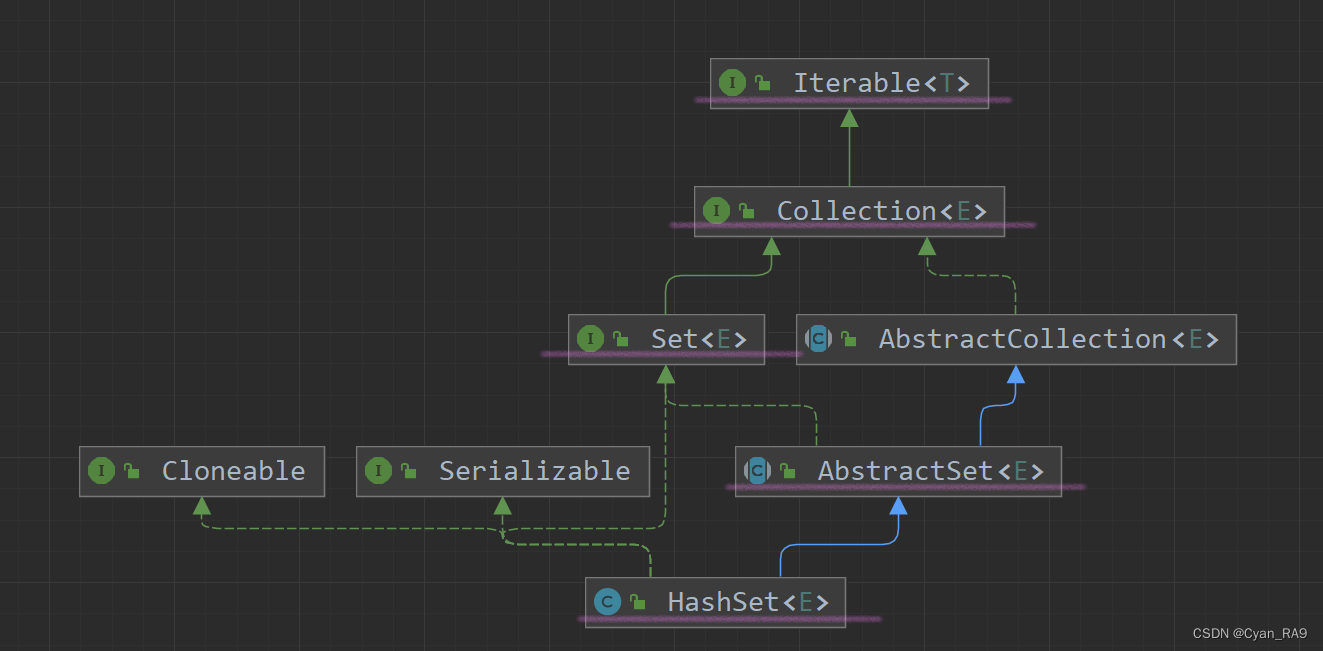
三、HashSet的底层实现
1.HashSet的底层其实是HashMap。这一点很好证明,我们创建一个HashSet类对象,并通过Ctrl + b/B 快捷键来查看一下HashSet无参构造的源码,如下图所示 :
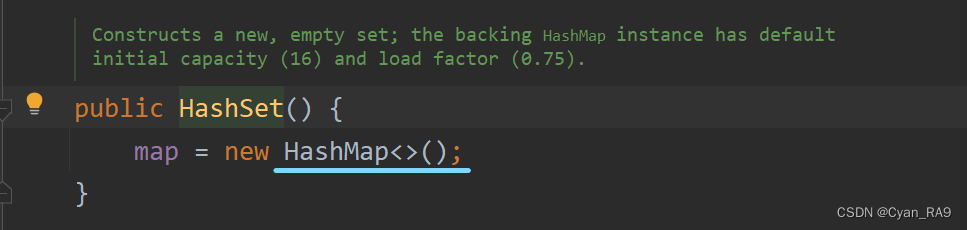
显而易见,HashSet底层调用了HashMap。 而HashMap的底层是"数组 + 链表 + 红黑树"的结构。简单来说,即数组的元素是一个链表,并且在某些条件下会将链表树化为红黑树。
2.当我们向HashSet集合中添加一个元素时,会先得到一个该数据的hash值(哈希值),然后在底层将它转化为一个索引值。这个索引值决定该元素在集合中应该存放的位置,这也解释了为什么尽管Set集合是无序的,但输出Set集合时元素的排列顺序总是一致的。
3.当索引值对应的位置没有元素存在时,直接将当前元素加入集合。
反之,则调用equals方法进行判断,如果当前要添加的元素与该位置处的元素判断为相等,放弃添加该元素;如果当前元素与该位置处的元素判断为不相等,则将当前元素添加到(挂到)该位置处元素的最后面。这便实现了"数组 + 链表"的结构。如下图所示 :
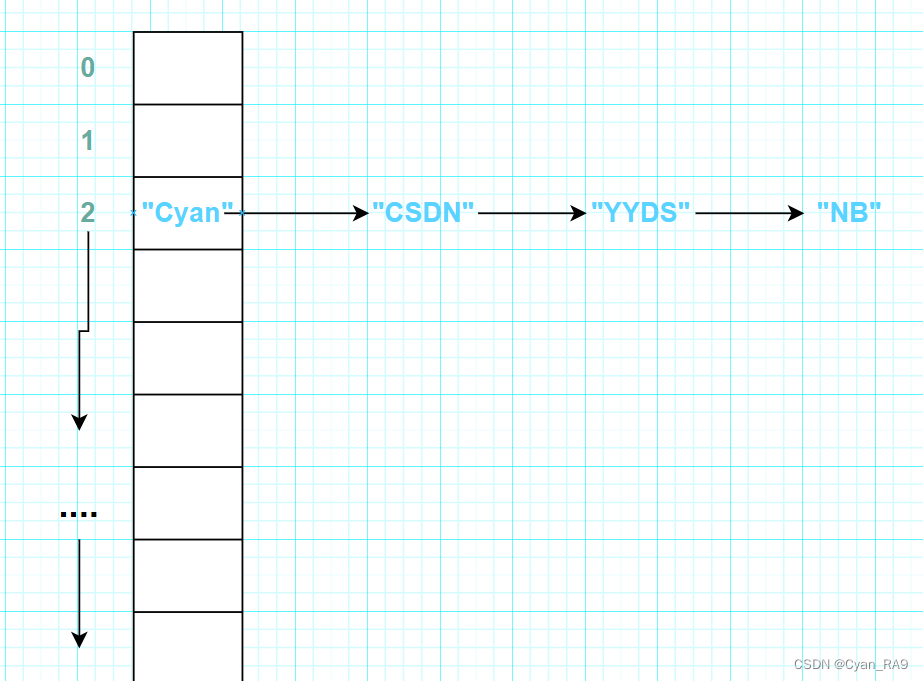
4. 在JDK17.0版本中,如果一条链表的元素个数达到或超过了TREEIFY_THRESHOLD(默认是8),并且table数组的长度达到或超过了MIN_TREEIFY_CAPACITY(默认是64),底层就会对该链表进行树化,将其转化为一棵红黑树;否则仍采用数组扩容机制。(JDK8.0同)
5.第一次像集合中添加元素时,底层的table数组会扩容到16,临界值(threshold) = 16 * 0.75 = 12;临界值的存在是为了对扩容起到一个缓冲的效果。当数组中元素的个数达到临界值12后,会对数组进行第二次扩容,16 * 2 = 32,此时临界值 = 32 * 0.75 = 24;当数组中元素的个数达到24后会进行第三次扩容,32 * 2 = 64,此时临界值 = 64 * 0.75 = 48,依次类推。(PS : 此处的0.75是增长因子,我们下面都会说到。)
四、HashSet的源码解读(断点调试)
0.准备工作 :
up以HashSet_Demo类为演示类,来给大家分析HashSet的底层实现。
代码如下 : (在创建对象的所在代码行下断点)
package csdn.knowledge.api_tools.gather.set;
import java.util.HashSet;
/**
* @author : Cyan_RA9
* @version : 21.0
*/
public class HashSet_Demo {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
hashSet.add(141);
hashSet.add("Cyan");
hashSet.add("Cyan");
}
}
别看这代码现在看着寒碜,等会儿分析底层时有你好受的😋。
1.向集合中添加第一个元素(141) :
①跳入无参构造。
首先我们跳入HashSet的无参构造,如下图所示 :
可以看到,HashSet底层的确调用了HashMap,所以我们说,讲HashSep的底层源码,实际上就是讲HashMap的底层。我们不管它,直接跳出,在测试类中我们已经可以看到hashSet对象的一些信息,如下图所示 :
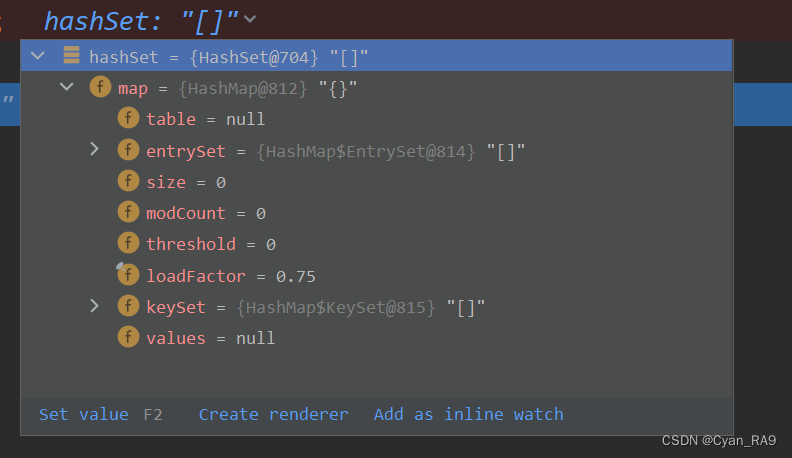
这里我们只需要注意一个地方,就是table,它就是我们说的"数组 + 链表 + 红黑树" 中的数组,当然,后面我们都会讲到,这里先给大家打个预防针,了解一下即可。
②跳入add方法。
接着,跳入add方法,如下图所示 :
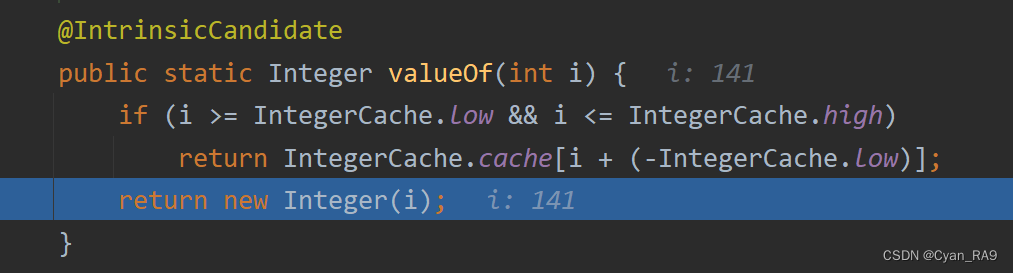
由于我们添加的第一个元素是int类型,所以底层会有自动装箱的操作。这里我们不管它,直接跳出。并重新跳入add方法,如下图所示 :

可以看到,add方法内部又通过map对象调用了put方法,显然添加元素的操作是在put方法中完成的。 我们知道,add方法如果添加元素成功,就会返回true。所以,如果我们添加元素成功,此处的put方法一定会返回一个null,因为只有这样,才能满足"null == null" 的判断,最终使add方法返回true。
好的,还有一点是add方法的形参,E代表泛型,之后我们专门出一片博文讲泛型,这里大家先了解即可,e就是我们要添加的元素了,可以看到此时e = 141。
再来看put方法的实参,我们传入了一个e(即当前要添加的元素),还有一个叫做"PRESENT"的东西。那这个PRESENT是什么东西呢?不急,我们还是通过Ctrl + b/B 快捷键看看PRESENT的源码,如下图所示 :

噢,原来PRESENT就是个Object类型的对象,那不就是啥也没有呗?你猜对了,PRESENT此处在put函数中就是充当一个占位的作用,并无实际意义。(注意,记住这个PRESENT,它是静态的。)
③跳入put方法。
继续,我们跳入put方法,如下图所示 : 
哎呦我靠,没想到这些个集合类都喜欢套包皮,一层一层的属实有丶保守了。可以看到,此处put方法内部又调用了putVal方法。
先不说这个putVal方法,先来看看put方法的形参列表。IDEA也是给出了提示,key就是我们之前传入的e(= 141),即要添加的元素。而value就是那个PRESENT。
再来看putVal方法此处的实参,一个hash方法的返回值(未知),一个key(已知),一个value(已知),一个false 和 一个true。最后那俩boolean类型的变量大家先别管,之后我们用到时再说,先来看看这个hash方法,直接追进去看看,如下图所示 :

hash方法最终要返回当前元素对应的哈希值,return语句后跟了一个三目运算符, 判断条件是"key == null",显然为false,所以要返回的是冒号后面的内容。"(h = key.hashCode()) ^ (h >>> 16)" 就是得到哈希值的一个算法,我们不用管它,只需要知道这里的">>>"指的是无符号右移。
好滴,接下来我们跳出hash方法,回到put方法。
④跳入putVal方法。
正片开始!我们跳入putVal方法,putVal方法内部语句很多,一张截图放不上,一个GIF又看不全。所以up直接给大家把源码搬过来,putVal方法源码如下 :
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
😱,不知道你看到putVal源码后的第一反应是不是左面这表情,如果是,请及时切换为右面这表情🤗捏。哈哈😂,放轻松,既然up出HashSet深度讲解的博文,就有把握给大家讲明白。我们一步一步来看——
首先,定义了几个辅助变量,如下 :

诶,还行。注意tab是Node类型的数组,而p只是个Node类型的引用(其实p后面就是用来充当tab中的某个元素的) 。至于后面n 和 i 变量,我们暂时不管,后面会用到的。
接着,第一个if 条件语句的判断,如下 :

判断条件中使用了短路或逻辑运算符(只要第一个条件满足就进入if 语句)。这个"table"不知道大家还有没有印象,我们在Debug一开始给大家提了一嘴,当然,我们也可以直接Ctrl + b/B 看看table的源码,如下 :

可以看到,table是HashMap中一个Node类型的数组,并且没有显式初始化,默认为空引用null 。再回到if 条件语句,那第一个条件"(tab = table) == null" 不就满足了?是的,要执行if语句中的内容。
if 语句中的内容又出现了一个新的方法resize() ,我靠,头都大了,欸,莫急,我们来观察,由于if 语句的判断条件中tab已经被table赋值,就是说tab现在也为null了;而此处又令resize函数的返回值赋值给了tab,所以猜测,resize函数的返回值是一个结点类型(Node类型)的数组。
⑤跳入resize方法。
于是,我们跳入resize方法一探究竟。(PS : 其实resize方法就在putVal方法的下面,大家动一动鼠标滚轮就到了😂。)当然,由于resize方法的源码也大的一批,up还是直接把源码拷贝过来吧。resize方法源码如下 :
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
} 🤗是不是很刺激捏。速速给👴切换到这个表情😅。
好的,开个玩笑。还是老规矩,我们一步一步来看——
首先,是将table引用赋值给了一个Node类型的数组oldTab,即oldTab引用现在也是null了。如下 :

接着,后面的几句都不是很重要,我们一块儿说了吧,如下 :

三目运算符的判断条件显然成立,将0返回给了oldCap变量。下一条语句,又将threshold赋值给了oldThr变量。注意,此处的threshold变量指临界值,我们后面会讲到。threshold本身就是"门槛"的意思,其源码如下 :

继续,又定义了newCap和newThr两个变量。其实目前这些都不重要,我们直接看第一个if语句,如下 :

判断条件不成立,不进入if语句;else-if语句判断也不成立,直接跳入else语句,如下 :

else语句中干了两件事,即分别给我们刚才定义的两个新变量赋值了。我们先看第一条语句,"DEFAULT_INITIAL_CAPACITY",即"默认初始容量"是个啥玩意儿?查看它的源码如下 :

即,此处将一个大小等于16的静态常量赋值给了newCap变量。(newCap,见名知意,newCapacity,表示新数组的容量)
下一步就要注意了,如下 :

第二条语句中的"DEFAULT_LOAD_FACTOR",直译过来就是"默认增长因子",IDEA显示它 = 0.75。这里是将默认增长因子和默认初始初始容量的乘积赋值给了newThr变量。(newThr,见名知意,newThreshold,表示临界值)
这里我们要重点说一下——这个所谓的临界值"Threshold"到底有什么用?
1°Threshold是门槛的意思,是java设计者提供的一个临界值。
2°临界值 = (向下转型) 增长因子 * 默认初始容量 = 0.75 * 16 = 12。(此处为12)
3°这么做是为了尽可能防止线程阻塞情况的发生。如果一直到table数组满16才扩容,当数组可用空间已经不多时,假如这时候有许多线程同时向集合中添加元素,就可能因为扩容不及时造成阻塞。因此java设计者想出了这样一个思路,假如数组目前已添加了12个元素,到达临界值了,数组就要准备开始扩容了,未雨绸缪,就不容易发生阻塞,即起到一个缓冲的作用。
4°这里所谓的"数组中的元素"既可以是数组某一个索引处的链表的第一个结点;也可以是数组某索引处链表中挂载到后面的结点。即,只要向table数组中加入一个元素,都会算作数组的元素加一。
好的,继续往下Debug : 
下一个if 条件语句,判断条件是“临界值为0吗?”,显然不满足,不进入。
再往下,将计算求得的新的临界值赋值给threshold变量,如下 :
![]()
继续,重点来了,注意 :  这里出现了new的操作,将长度为16的Node类型的新数组的地址赋给了newTab引用,并由newTab引用传递给table,到此,table已经由null变为了长度为16的数组,如下图所示 :
这里出现了new的操作,将长度为16的Node类型的新数组的地址赋给了newTab引用,并由newTab引用传递给table,到此,table已经由null变为了长度为16的数组,如下图所示 :

再往下是一个非常大的if条件语句,不过万幸地是,条件不成立,不进入,如下 :  OK,这下resize方法总算是执行完了,接下来返回new出的新数组,如下 :
OK,这下resize方法总算是执行完了,接下来返回new出的新数组,如下 : 
⑥跳出resize方法。
好滴,接下来我们跳出resize方法,返回putVal方法中。 如下图所示 : 
可以看到,n其实就是新数组的长度,此处为16。
接着一个if 条件语句,仔细看它的判断条件,它是先将tab数组中的一个特定元素给到p,再判断p是否为空,其实就是判断tab数组某个索引处的元素是否为空。至于这个索引中的一大堆,不用管它,只需要知道这就是在用我们之前hash方法获得的当前元素的哈希值来进行计算,根据该算法来获取对应的一个索引值。
这里便验证了我们上文"HashSet"的底层实现中提到的——当我们向HashSet集合中添加一个元素时,会先得到一个该数据的hash值(哈希值),然后在底层将它转化为一个索引值。这个索引值决定该元素在集合中应该存放的位置。
因为141是向集合中添加的第一个元素,所以集合的对应索引处肯定为null,条件满足,继续执行if 中语句,直接将该元素加入tab数组中。注意,这里存入的值除了key(141),value(PRESENT),和next(null),还存入了该元素的哈希值。存入哈希值的目的是为了将来再次添加元素时要进行判断。
继续Debug,如下图所示 :
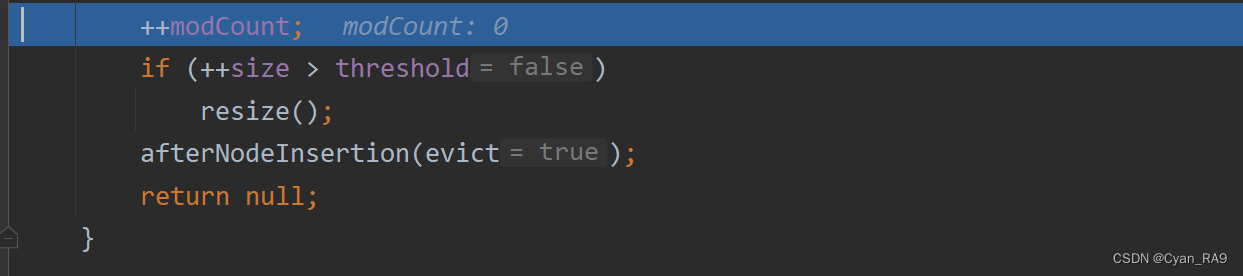
欸,putVal方法也总算要执行完了——
1° modCount不用说了吧?老面孔了,记录修改次数的变量。
2° if 语句,判断当前集合中元素的个数是否达到了临界值,如果到了临界值就准备扩容了。
3° 至于这个afterNodeInsertion方法,这里你可以无视它。因为在HashMap中,这是个空方法,该方法存在的目的在于留给它的子类,比如 linkedHashMap类,去实现一个双向链表的功能等。我们可以看一下afterNodeInsertion方法的源码,如下 : 
可以看到,空空如也。
于是,putVal方法也结束,并最终返回了null,代表添加元素成功。
⑦跳出putVal方法。
接下里,我们跳出putVal方法,回到put方法,如下 :

⑧跳出put方法。
继续往外跳,回到add方法。 如下 : 
⑨跳出add方法。
接着我们回到演示类,可以看到第一个元素——141——已经成功添加到了集合中,如下GIF图 : 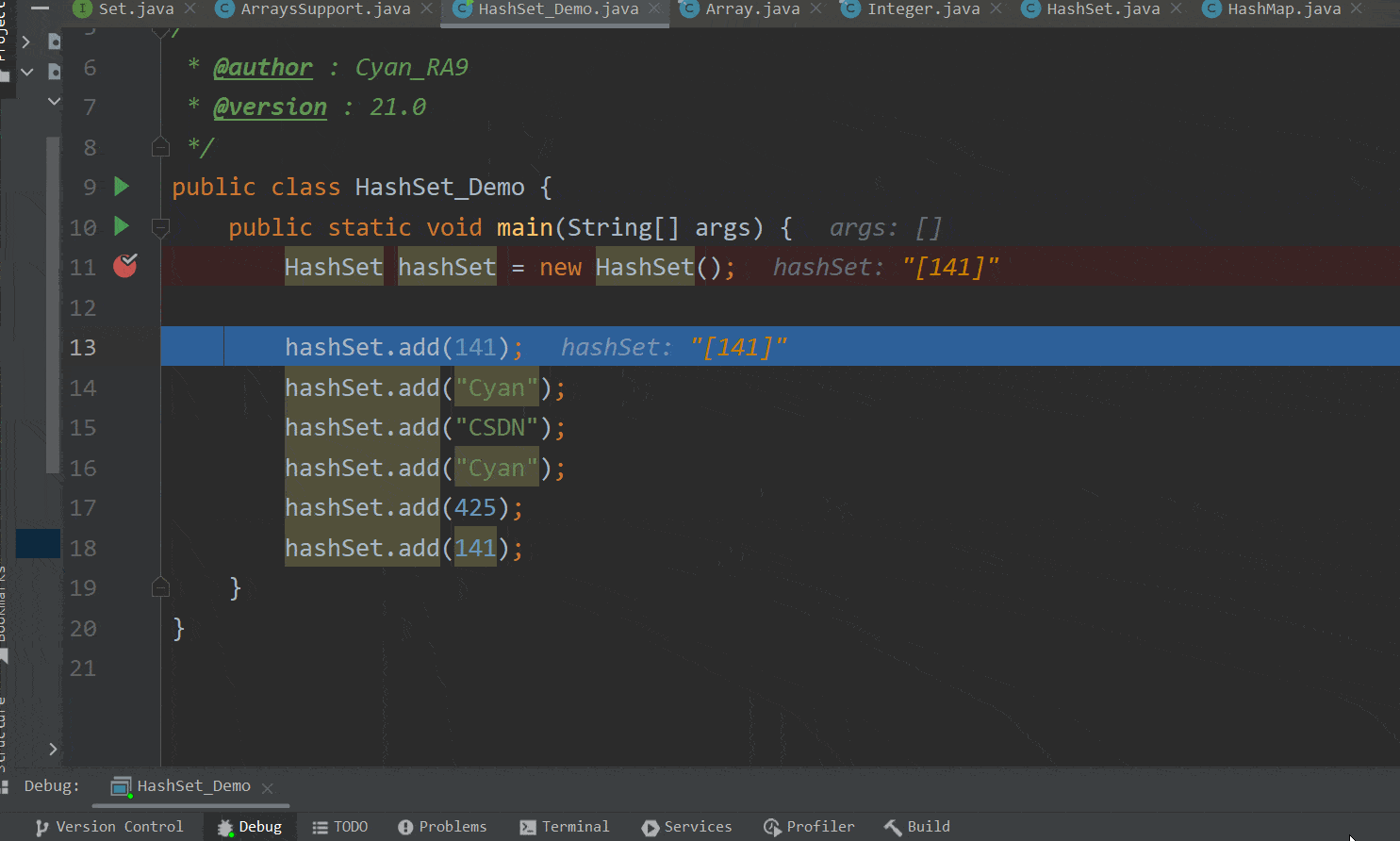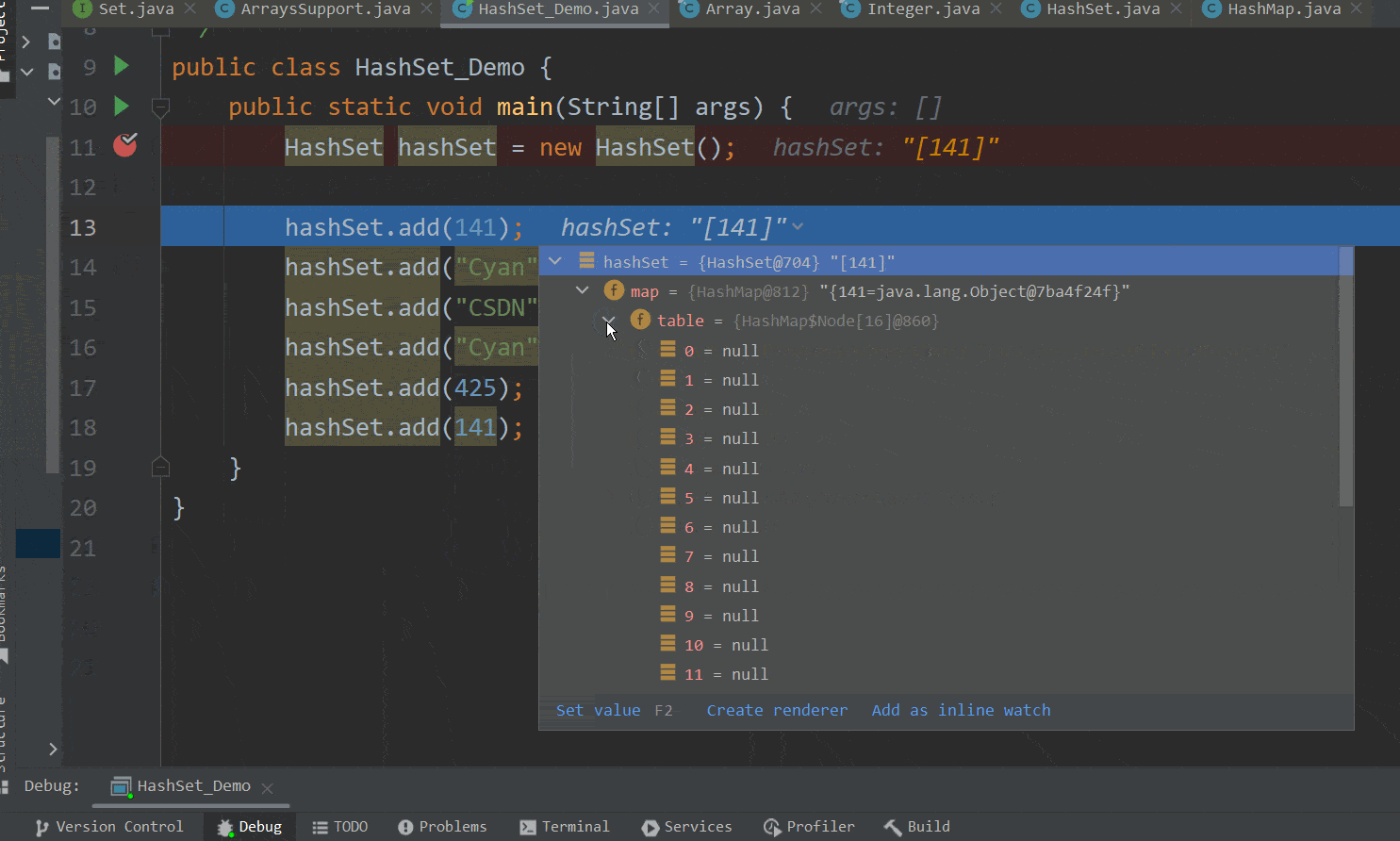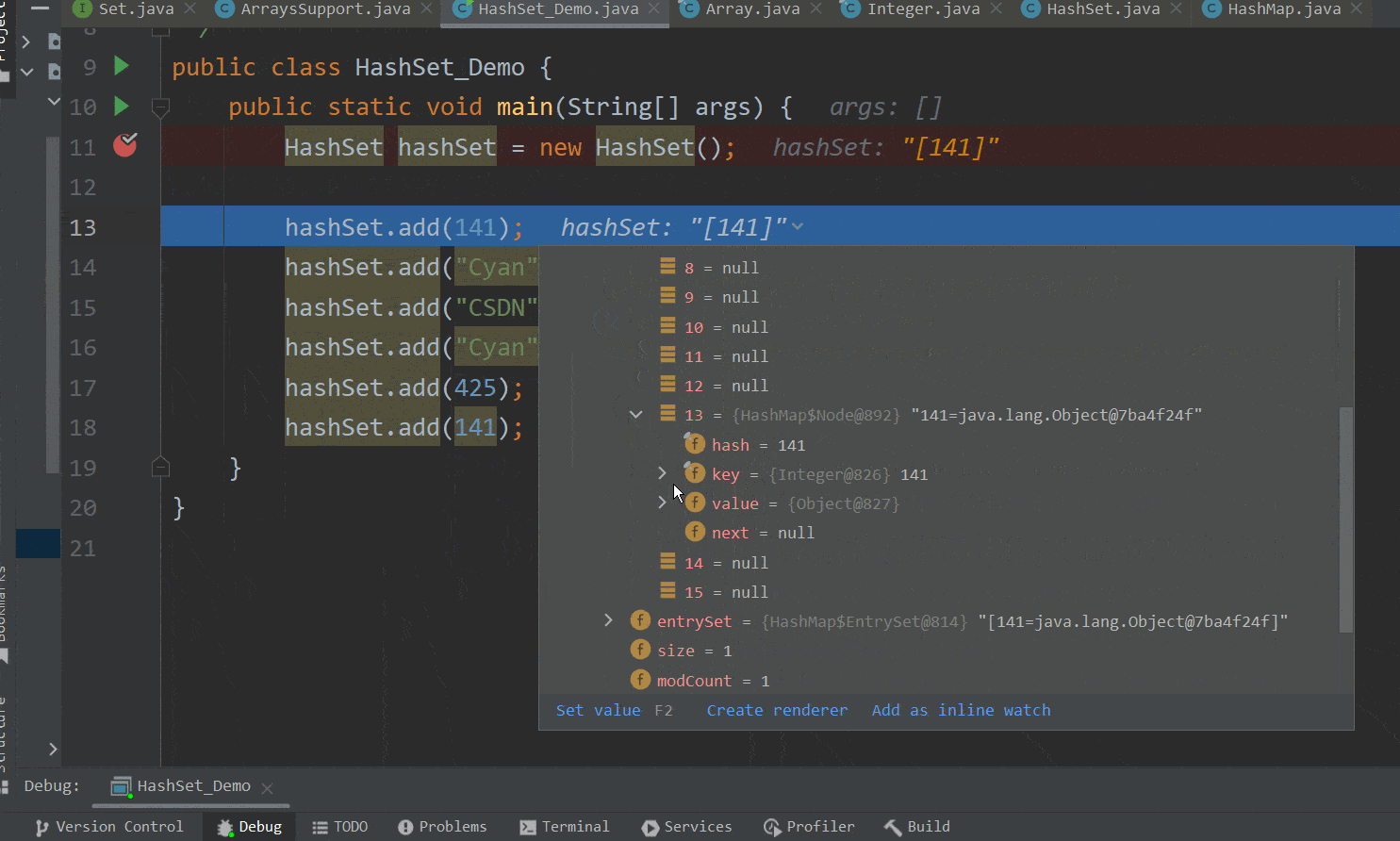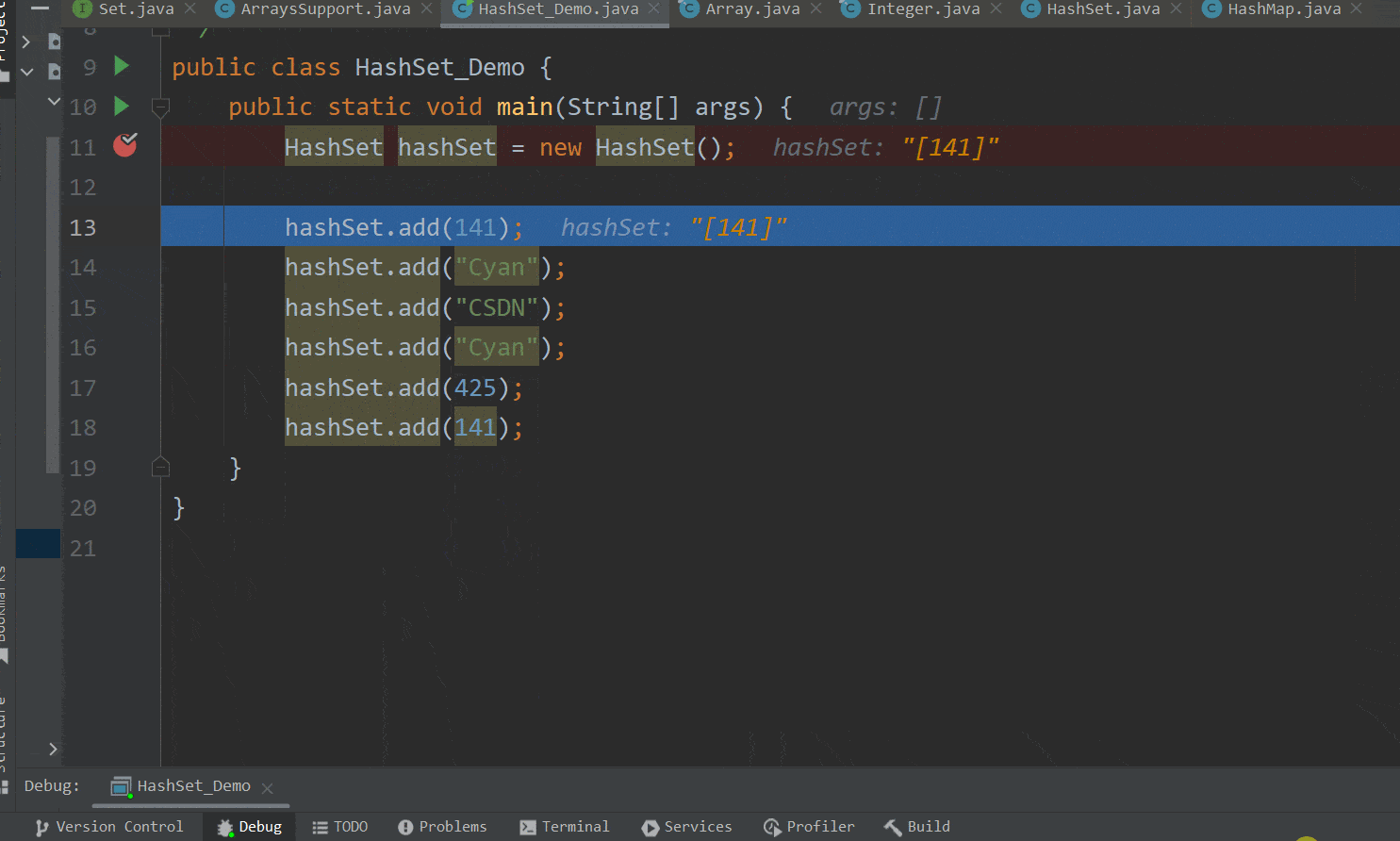 ok,到此第一个元素的添加执行完毕。
ok,到此第一个元素的添加执行完毕。
2.向集合中添加第二个元素("Cyan") :
①跳入putVal方法。
好的,我们继续Debug,对于第二个元素("Cyan")的添加,前面几个重复的步骤up就不给大家演示了,我们直接上硬菜。逐层跳入,跳到putVal方法,如下 : 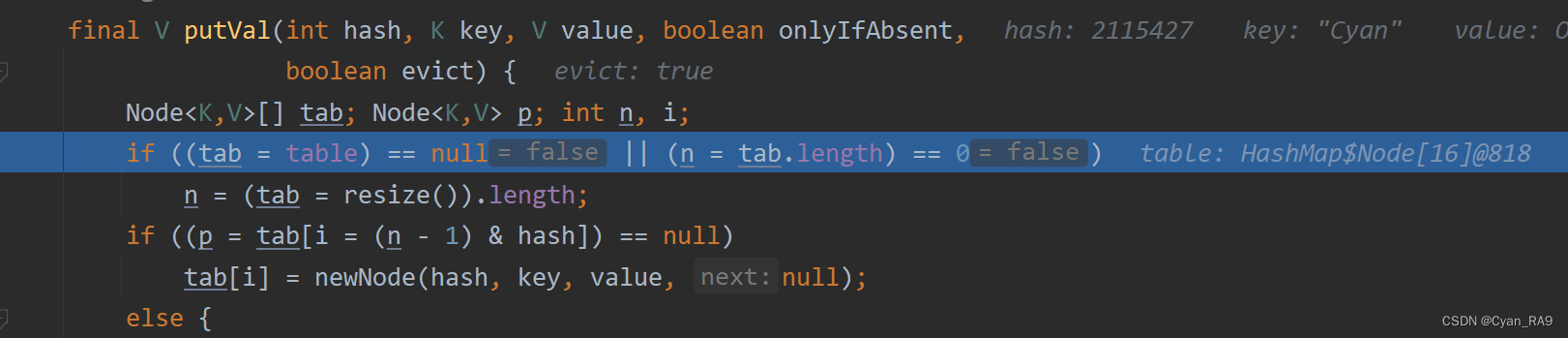
ok,还是老规矩,我们一步一步来看——
首先,看下形参吧,hash就是根据当前元素的哈希码值,通过特定算法计算生成的哈希值,我们上面已经说过了;key就是"Cyan"字符串;value就是那个PRESENT,用于占位的Object类对象;至于后面俩boolean类型变量,我们跳入putVal前可以看到是分别传入了一个"false"和"true"。
其次,还是定义了那几个辅助变量,这里不再赘述。
接着,第一个if 条件语句,因为我们刚刚添加第一个元素时已经对table数组进行了初始化,所以table现在当然不为空。所以tab也不为空,第一个判断条件不成立;table被初始化为了长度 = 16的数组,所以第二个判断条件也不成立。因此,不进入第一个if 语句。
继续,来看第二个if语句,还是先通过当前元素的哈希值来获取对应的索引值,并判断tab数组对应索引处的元素是否为null。如下 :
判断成立,直接将"Cyan"添加到tab数组中。
然后,就又到了老面孔时间,如下 :
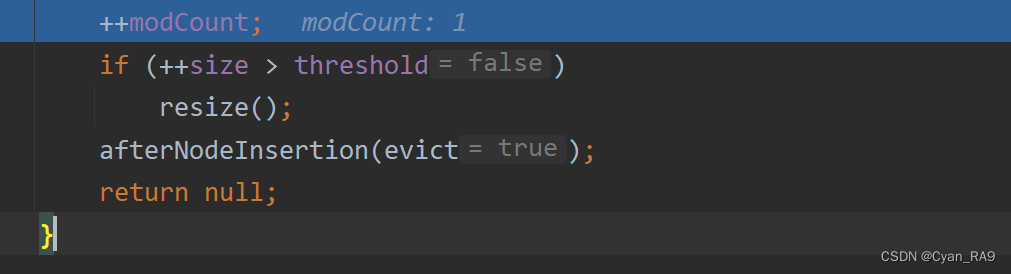
很显然,当前数组中元素的个数 = 2,远远没达到临界值 ,因此不会进入resize方法扩容。至于afterNodeInsertion方法,我们上面已经说过了,这里就是一个空方法,我们不去管他。那么,第二个元素也算成功添加到了table 数组中了。
②跳出putVal方法,回到演示类。
好滴,接下来我们逐层返回,直到演示类中。在演示类中我们已经可以看到"Cyan"元素被成功添加到了集合中,如下GIF图演示 :

3.向集合中添加第三个元素("Cyan"):(重要)
①跳入putVal方法。
我们知道,Set集合具有“无序,不可重复”的特点。第三个元素"Cyan"属于重复添加,所以它在底层肯定会被“干掉”。我们就是要通过Debug,来看看它是被怎么给“干掉的”。
同样地,前面一些相同的步骤我们不再赘述,直接从putVal方法讲起。跳入putVal方法,如下 :
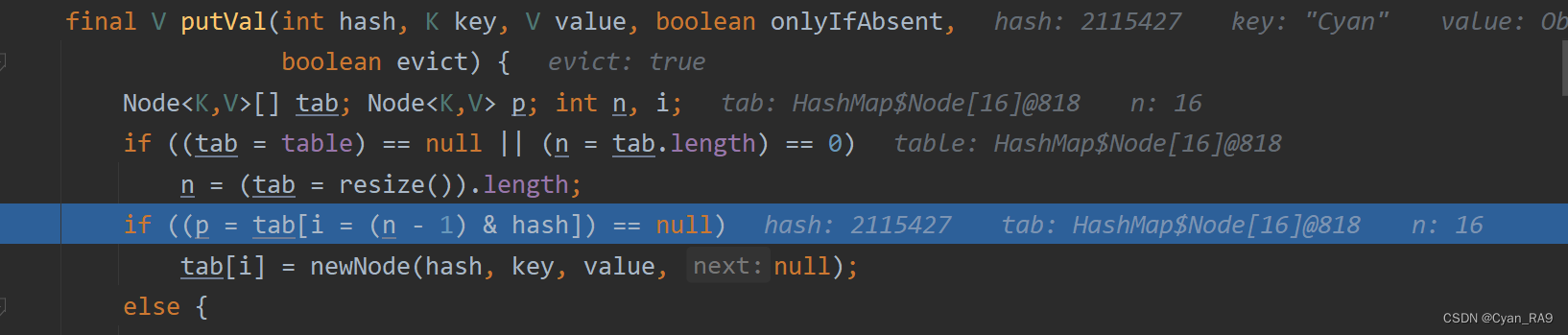
可以肯定,第一个if 语句是不可能进去的。那第二个if 语句呢?
显然,由于我们已经添加过"Cyan"元素,它的索引值是确定的,所以tab数组对应索引处的元素不可能为null。因此,第二个if语句也不进去。
②进入putVal方法的else语句。
那不久只能进入else语句了。这个else语句是相当扯淡的,up这里再单独将putVal方法的else语句部分的源码给大家放一下,如下 :
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
} 😂,可能有些小伙伴儿们编程了几年还没见过如此复杂的else语句。没关系,仍然是老规矩,我们一步一步来看——
首先,我们来分析一下这个else语句的内部结构,该else语句内容是由一个if - else if - else的复合条件语句以及后面一个单独的if 语句构成的。
其次,else语句内部定义了两个局部变量——Node类型的e和K类型的k。有小伙伴儿可能对这个k有疑问,请翻回去看看putVal方法的形参,k,见名知意,其实就是key。
③解读putVal方法的外层else语句。(详细)
好滴,接下来,高潮来了!
先来看if 的判断,如下 :

此处if 条件的判断有点复杂,首先它要满足tab数组该索引处的元素的哈希值 == 当前元素的哈希值,我们添加的是重复的元素,哈希值显然相等。然后,在满足哈希值相等的基础上,还需要满足以下两个条件之一——
1°当前元素的值和数组该索引处的元素的值相等(或者是同一个对象)。
2°当前元素和该索引处的元素不是同一个对象;但是当前元素不为空,并且其内容与数组该索引处的元素的内容相等。(注意,此处的equals方法根据动态绑定机制,取决于key对象,可以由程序员手动控制,也就是说它可以不是String类型,而是一个由程序员自定义的一个类型,根据重写的equals方法进行比较。)
显然,此处满足if 条件语句的判断,所以直接就放弃添加了。当然,我们这里先不继续往下执行,借着这个机会给大家把else语句中的内容说明白了。
我们继续往下看,else-if语句,如下 : 
此处是要判断当前索引处的元素是不是一颗红黑树,如果结点p后跟着是一棵红黑树, 那么就会调用红黑树的putTreeVal方法来进行元素的添加。当然,这里up就不追进去演示了,红黑树的putTreeVal方法非常复杂,里面调用的其他其他方法都超过了5个。大家有兴趣可以自己去看看。
我们继续正题,如下 :
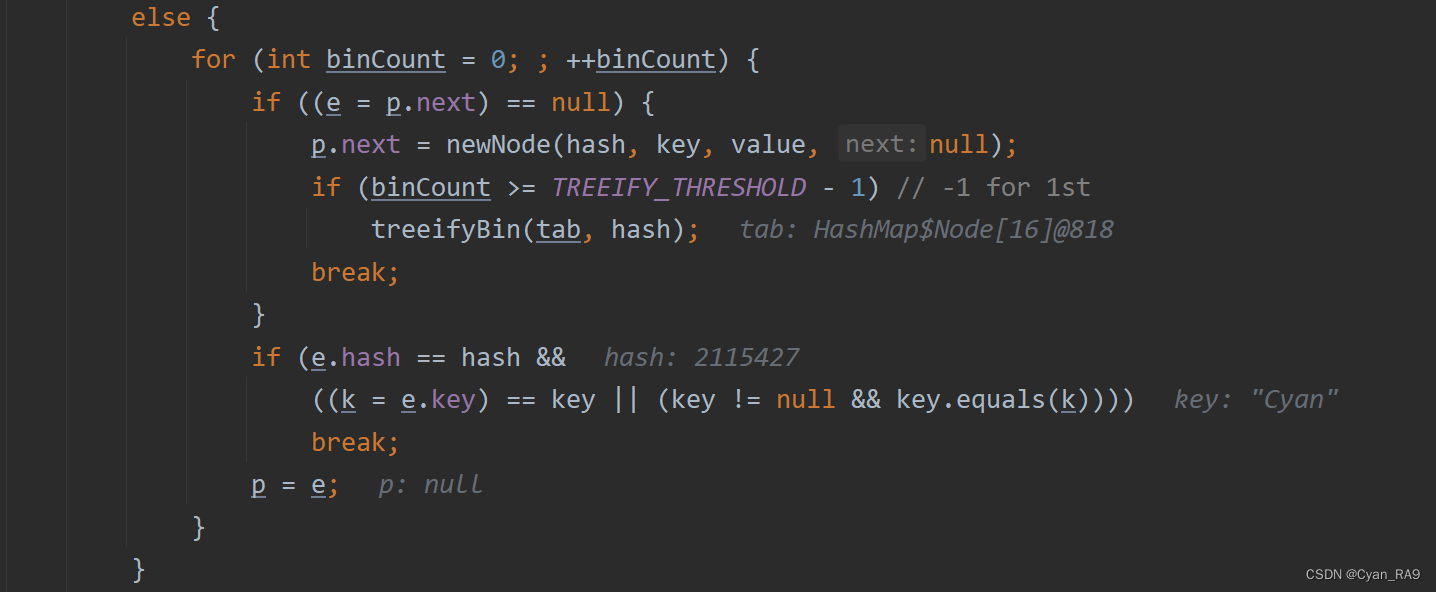
注意,此处的else语句是外层的if - else if - else 复合条件语句中的那个"else"语句,不是最外层的else语句,注意区分。
这里的else语句是说,如果我们第一个if语句判断当前元素不重复,可以添加;并且else if语句判断数组的该索引处元素不是红黑树,就要执行此处的else语句了。所以,链表元素的挂载显然是在这个小的else语句完成的。
可以看到,这个小的else语句是由一个for循环构成的,而且大家仔细观察就会发现,这是一个死循环,因为它没有设置条件语句,判断永远成立。这个for循环内部又有两个if语句。
不着急,我们一个一个来——
1° 先看第一个if语句,它要判断当前索引处元素的next指向是不是为空,如果为空,就直接将该元素添加到下一个结点的位置,即令当前索引处的结点的next指向这个新结点,如下示意图所示 : (别忘记HashMap的底层是"数组 + 链表 + 红黑树"的结构)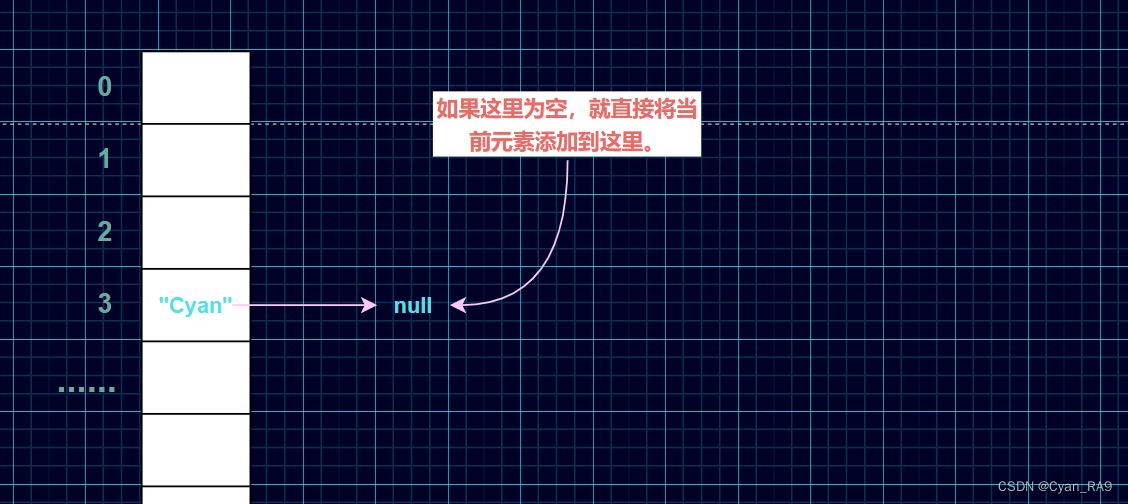
并且,假如成功添加该元素,会立刻进行判断——如果当前链表中的元素个数已经达到了8个,就要调用treeifyBin方法对数组该索引处的链表进行树化,将其转化为一颗红黑树。当然,不止是要求当前链表中的元素个数达到8个,还要求tab数组中元素的个数达到64个。关于这一点我们可以去看看treeifyBin方法的源码,如下图所示 : 
可以看到,treeifyBin方法中还有一个判断,如果当前tab数组中的元素没有大于等于64,就会先调用resize方法进行扩容,而不会树化。
2° 再看第二个if语句,如下 : 
欸,有没有眼尖的小伙伴儿发现,第二个if语句的判断条件好像在哪儿见过。™牛逼啊你,没错,其实这就是putVal方法中的外层else语句内的第一个if 的判断条件(注意定语😂),即通过for循环依次判断当前元素有没有和当前索引处链表中的元素相同的,如果有,直接break,就不继续比了,也不加了,重复了还加啥?如下图所示 : 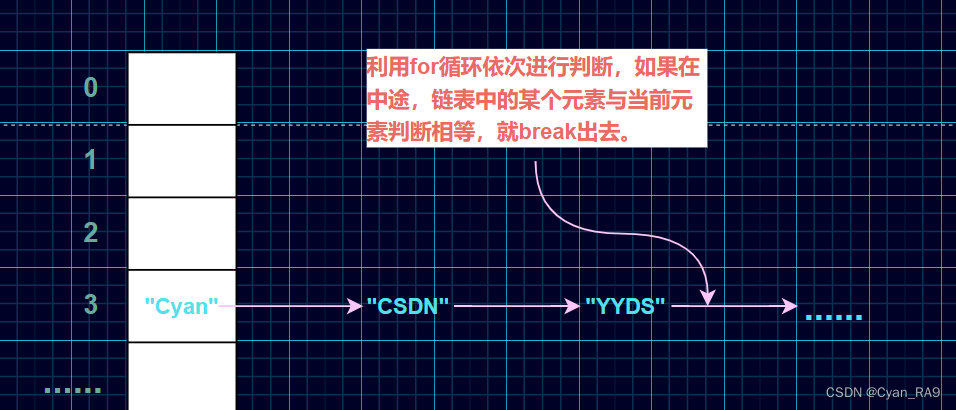 注意,第二个if语句后面还有步关键操作"p = e",这是啥意思捏?
注意,第二个if语句后面还有步关键操作"p = e",这是啥意思捏?
别忘了我们第一个if语句的判断条件中,执行了表达式e = p.next;那么此处就相当于p = p.next,也就是说,p的指针已经后移了一位,下一次for循环进行判断时,e = p.next执行,判断的就是链表的下一个元素了,其实目的就是把链表中的元素挨个比较一遍。大家如果不理解这块可以用试数法,或者在纸上画一画,其实很简单。
以上是对putVal 方法的解读,即给大家说明了HashMap底层是如何添加元素的,是如何做到"不可重复且无序"的。
接下来我们回归正题(别忘了我们正在添加重复的"Cyan"元素) 。
继续向下执行,如下 : 
后面其实就没那么重要了,大家只需要知道,putVal方法到这里就结束了,并且返回的并不是null,这就表示元素添加失败了。
③在else语句中终止putVal函数并逐层跳出。
好的,接下来我们继续执行,逐层跳出,一直回到测试类。如下 :
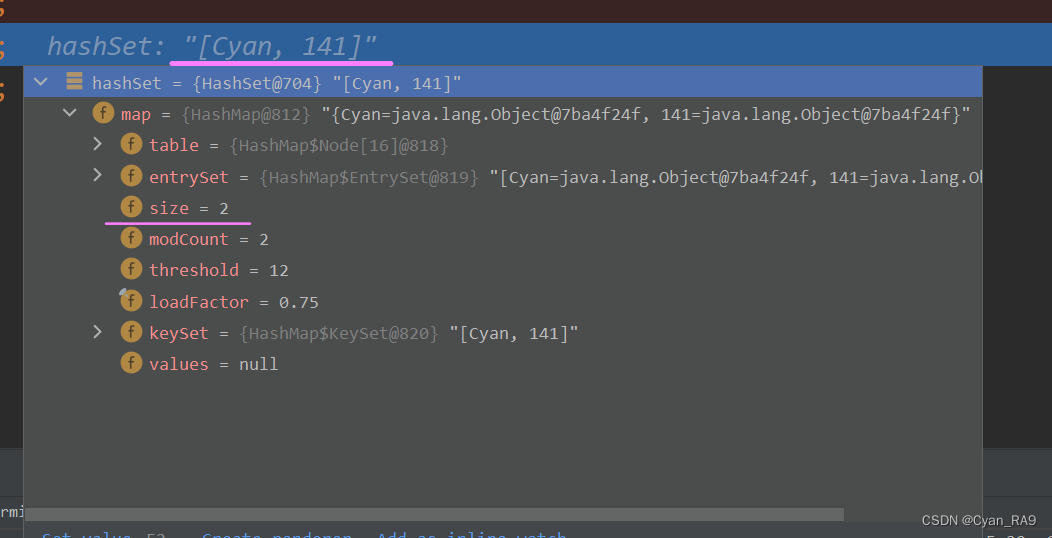
可以看到,集合中并没有加入第二个"Cyan"元素,并且当前集合中的元素个数size也显示为2。
4.HashMap底层扩容机制演示 :
〇准备工作。
up以HashSet_Demo2类为演示类,代码如下 : (main函数第一行下断点)
package csdn.knowledge.api_tools.gather.set;
import java.util.HashSet;
/**
* @author : Cyan_RA9
* @version : 21.0
*/
public class HashSet_Demo2 {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
for (int i = 0; i < 12; i++) {
hashSet.add(i);
}
hashSet.add("这是第十三个元素捏");
for (int i = 14; i < 25; i++) {
hashSet.add(i);
}
hashSet.add("这是第二十五个元素捏");
}
}
①向集合中添加第1个元素。
当我们刚创建好HashSet类对象后,底层的table数组是空的,如下 : 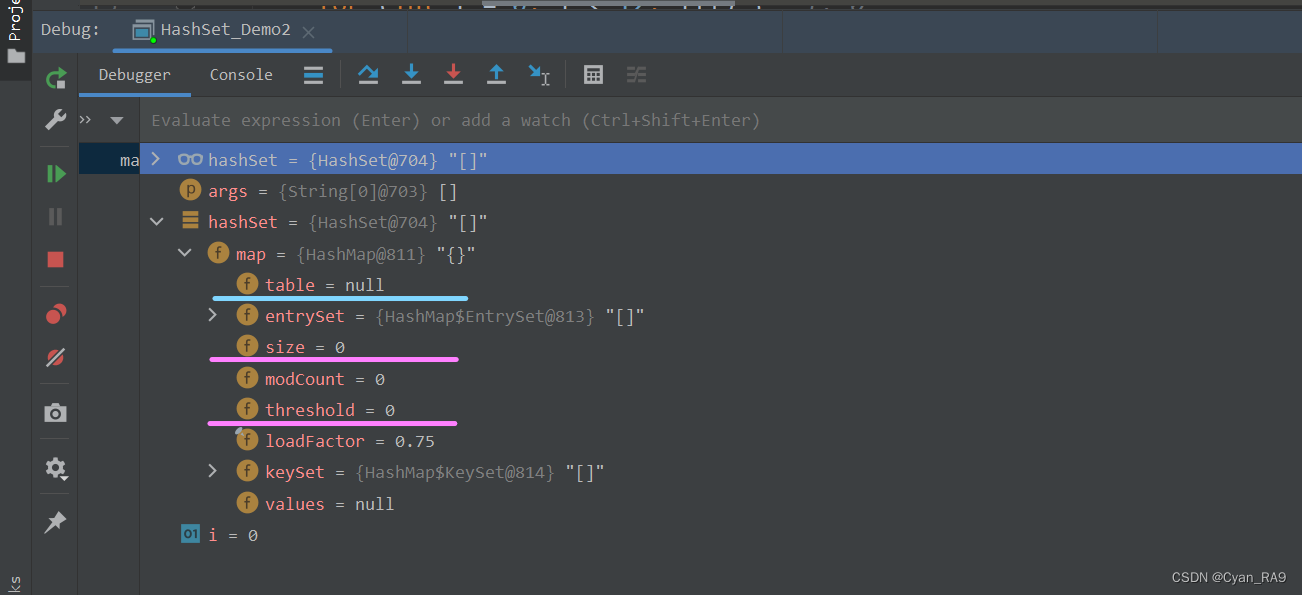
并且, 可以看到此时集合中元素的个数size = 0,临界值也是0。
我们通过第一个for循环,向集合中添加第一个元素。如下图所示 : 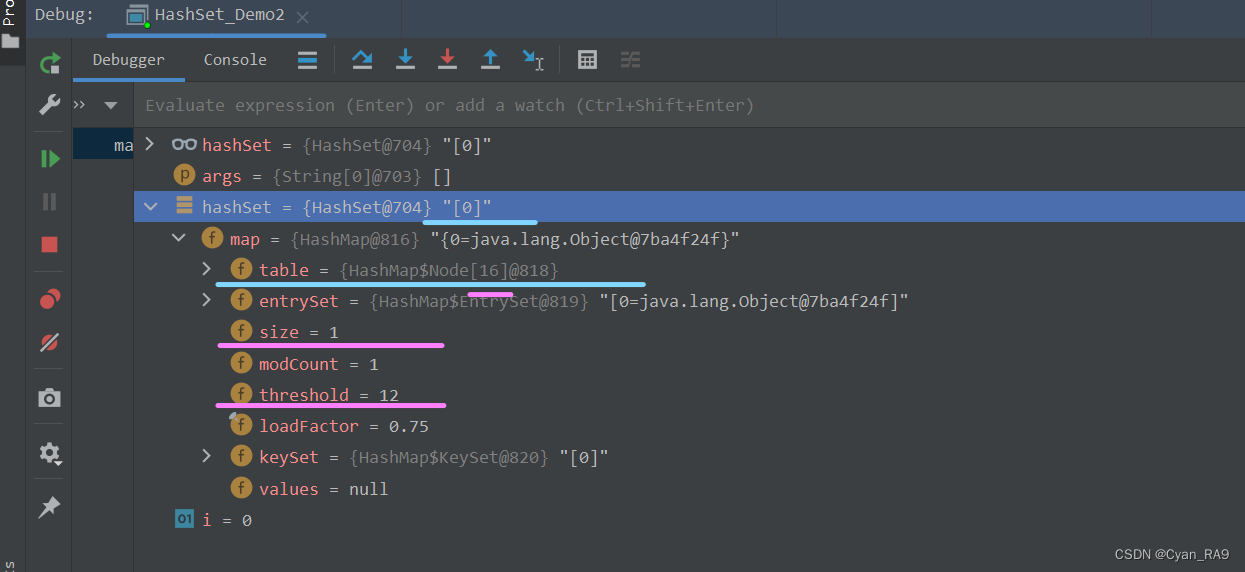
可以看到,此时table数组的容量已经扩到了16,临界值则 = 12;并且,当前集合中元素的个数size从0变成了1。
②向集合中添加第13个元素。
我们先通过for循环将集合添加到12个元素,如下图所示 : 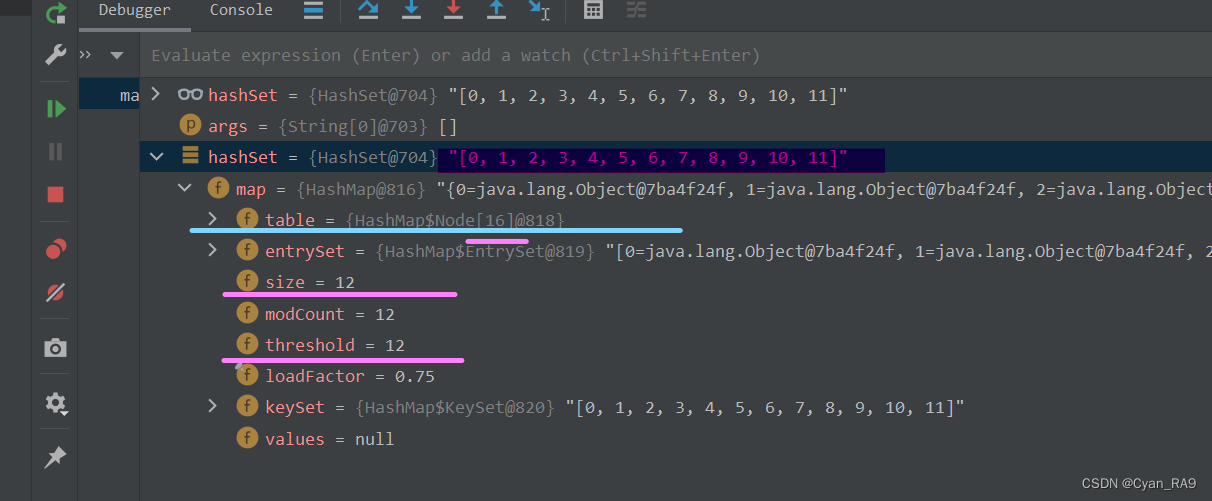
可以看到,这时候size已经到达了临界值12。根据我们之前的理论,如果我们继续向集合中添加元素,table数组就应该扩容到32了(临界值变成24)。
下面我们就添加第十三个元素,看看是真是假。如下图所示 :
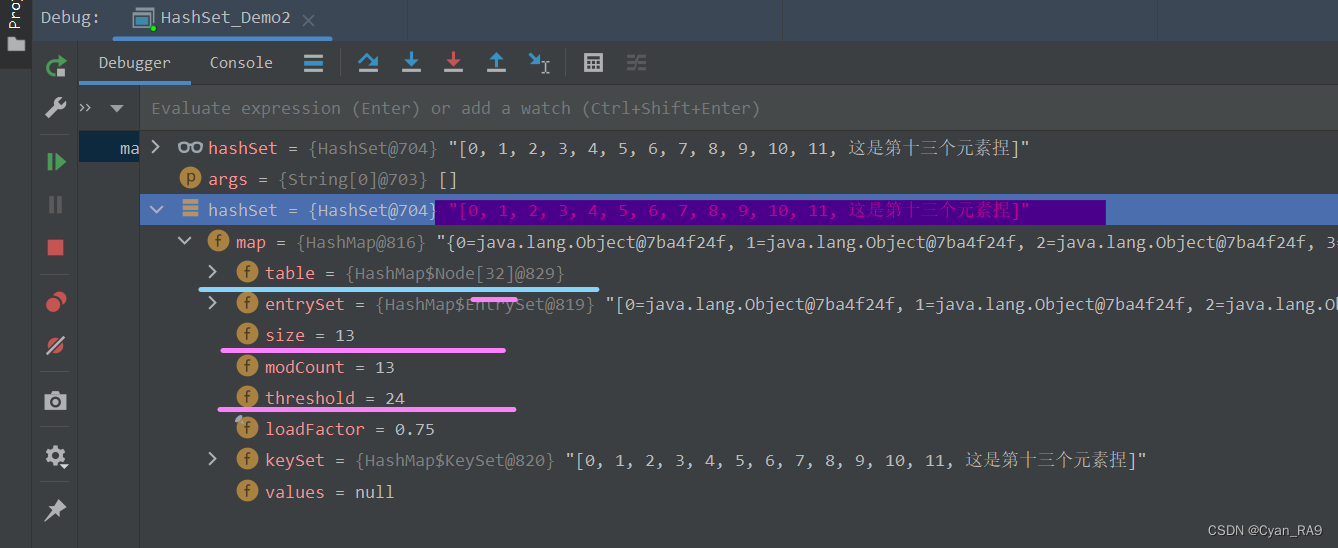
非常直观,集合容量由16 ——> 32,临界值则由12 ——> 24。
③向集合中添加第25个元素。
我们先通过for循环将集合添加到24个元素,如下图所示 :
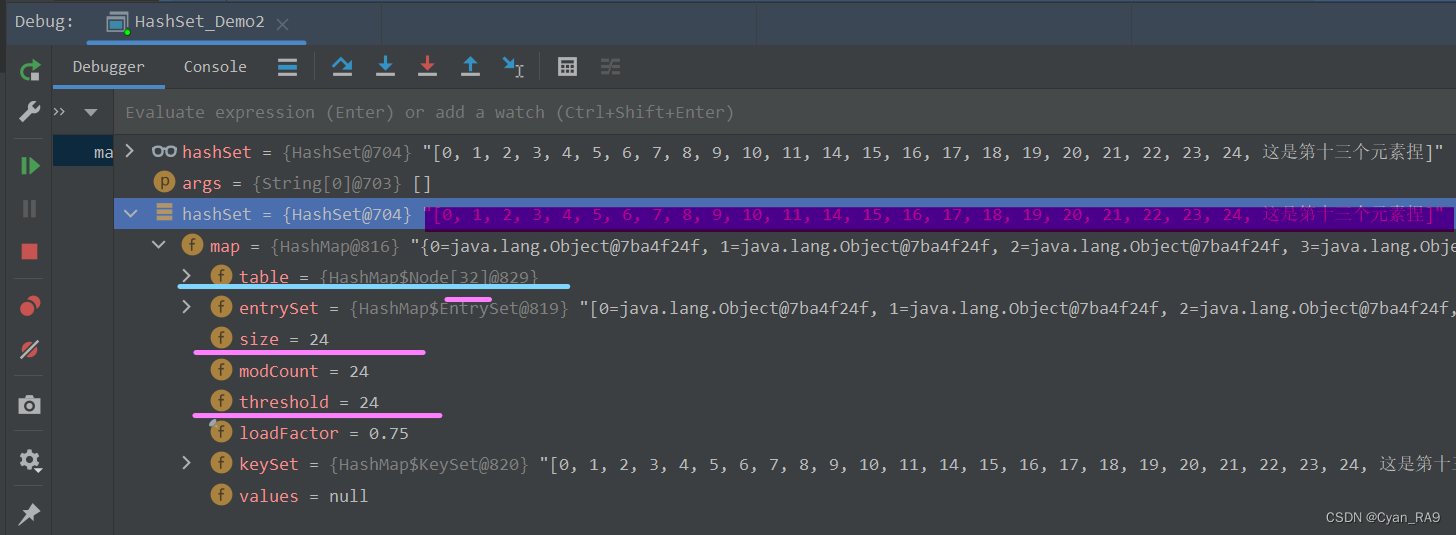
可以看到,size再次到达了临界值,size等于threshold等于24。那么下一次添加元素(第25个元素)时,集合应该会再次扩容(32 ——> 64)。如下所示 :
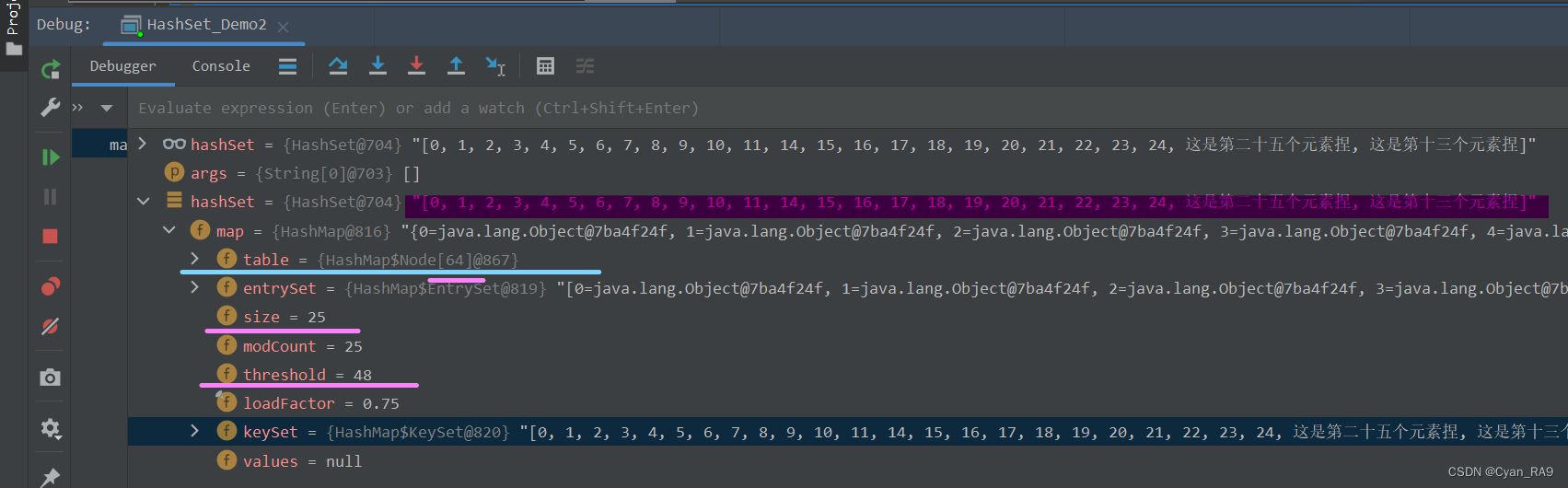
果然,table数组长度由32扩到了64,而临界值也由24变成了48(64 * 0.75 = 48)。
经过实践,我们前文"HashSet的底层实现"中提到的结论确实是正确的。
5.HashMap链表树化为红黑树演示 :
〇准备工作。
链表要转化为红黑树,除了要满足table数组的长度要达到或超过64外,还必须满足数组中某一个链表的所含元素个数达到或超过8个,但是如何才能保证我们每添加一个元素都能挂到同一个链表上呢?
很简单,自定义一个类并重写hashCode方法,令hashCode方法的返回值为固定值,那么该类对象的哈希码值就相同;从而,经过特定算法后,该类对象的哈希值就相同;从而经过特定算法后,该类对象在数组中对应的索引值便相同。只要我们一直向集合中添加new出来的对象,就可以准确将它们挂载到同一个链表下。
up以HashSet_Demo3类为演示类,并在其源文件下自定义一个Apple类,在Apple类中给出带参构造和重写过后的hashCode方法。代码如下 : (main函数第一行下断点)
package csdn.knowledge.api_tools.gather.set;
import java.util.HashSet;
/**
* @author : Cyan_RA9
* @version : 21.0
*/
public class HashSet_Demo3 {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
for (int i = 1; i < 9; i++) {
hashSet.add(new Fruit("水果"));
}
for (int i = 9; i < 17; i++) {
hashSet.add(new Fruit("水果"));
}
}
}
class Fruit {
private String name;
public Fruit(String name) {
this.name = name;
}
@Override
public int hashCode() {
return 233;
}
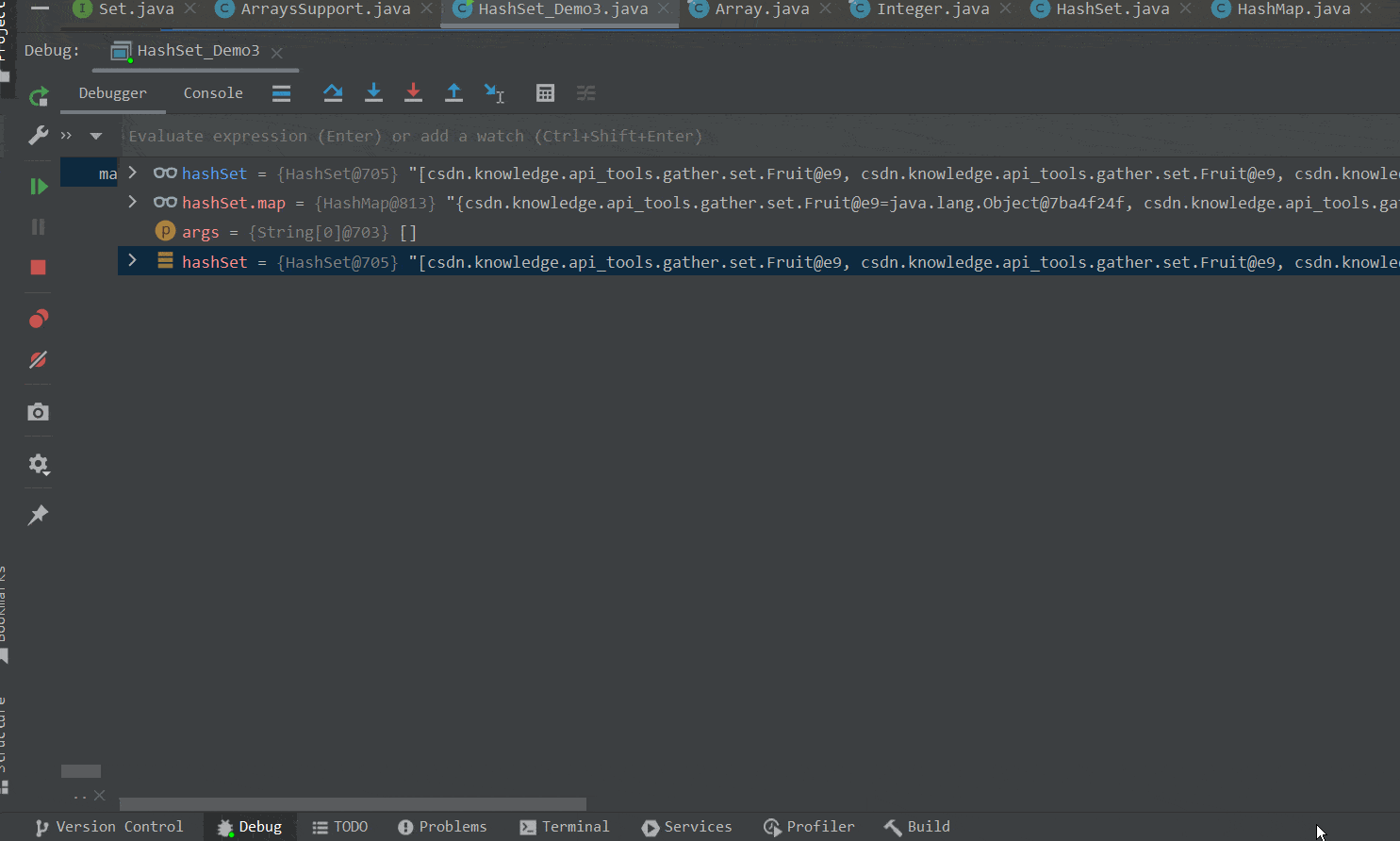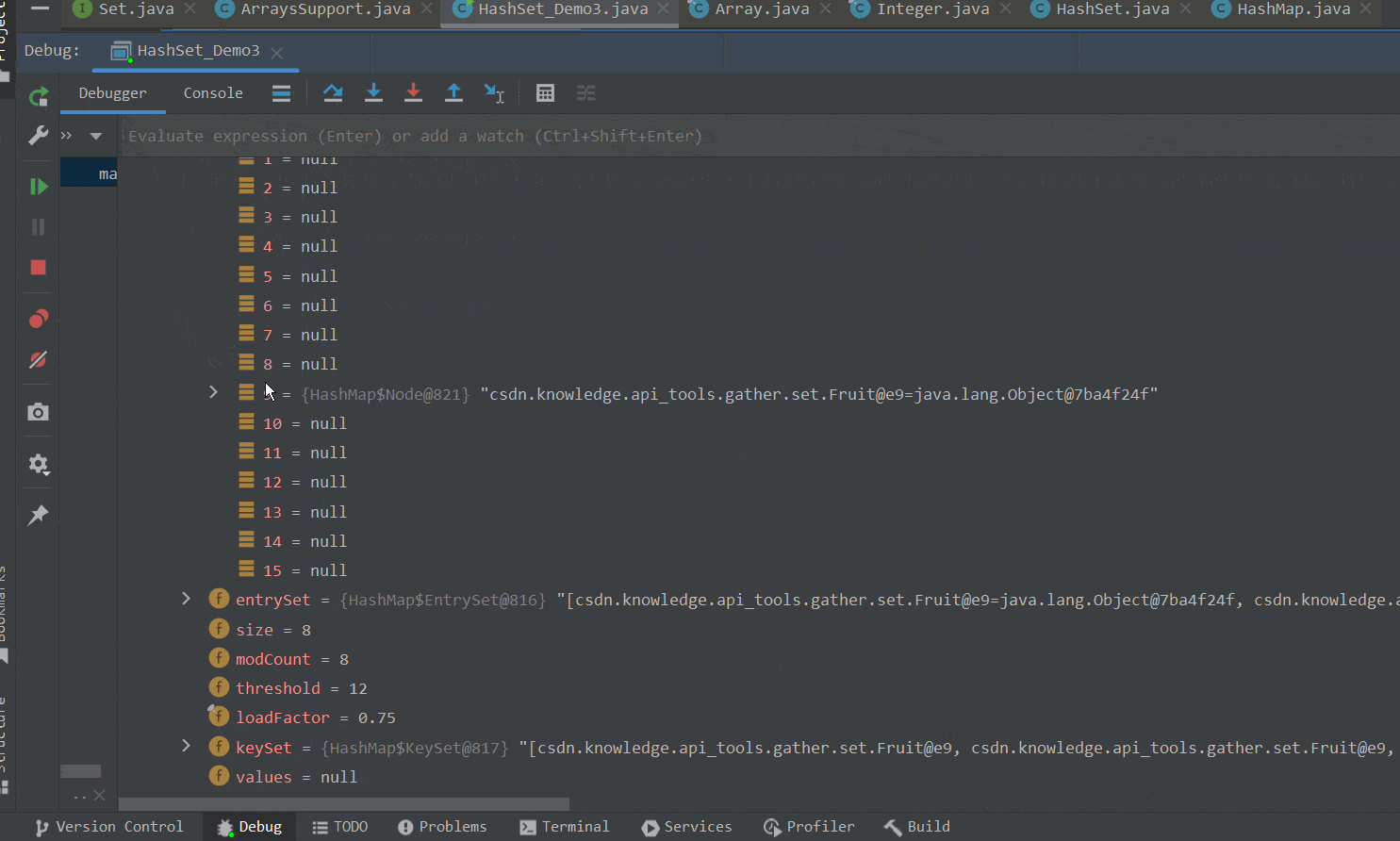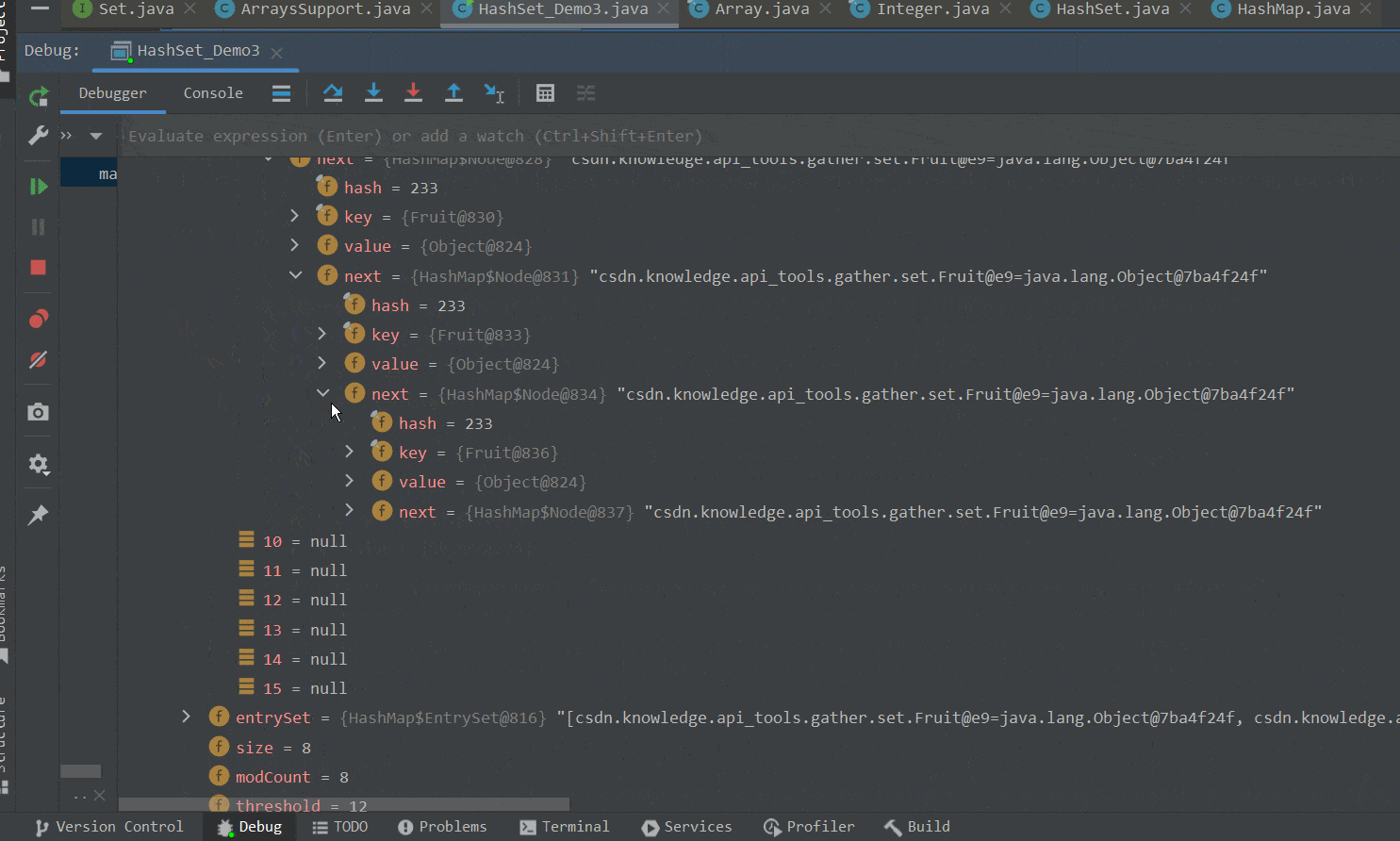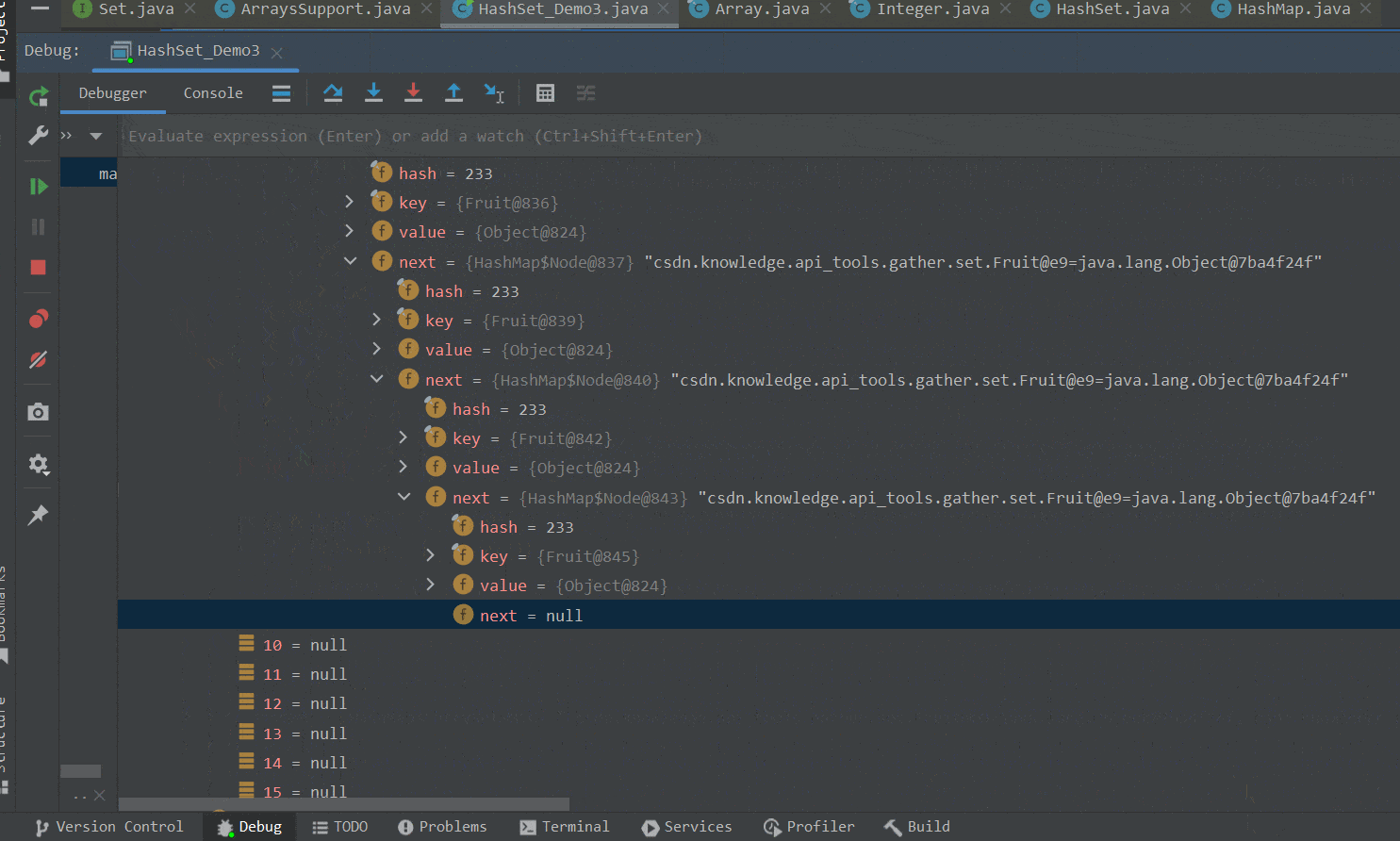
}①将8个元素挂载到数组的同一个链表下。
在第一个for循环中,我们向集合中添加不同的Fruit对象,由于Fruit类重写了hashCode方法,返回相同的哈希码值。因此这些对象最后都会添加到数组的同一索引处,即挂载到同一链表下。如下GIF图所示 :
②将table数组扩容至64。
接着,我们需要满足第二个条件,即table数组的长度达到或超过64。我们可以通过第二个for循环来实现,继续向table数组中添加Fruit类对象。
根据我们上面的源码解读,当table数组中有一条链表的元素个数达到或超过8时,如果这时候table数组的长度不到64,就会先对table数组进行扩容,等扩到64后再进行树化。
注意看,我们刚才添加了8个元素后,已经满足了第一个条件,但是table数组此时的长度只有16,而table数组的扩容是按2倍2倍来扩的。因此,我们只需要再向集合中添加两个对象,就可以实现(16 ——> 32 ——> 64)的扩容,使table数组达到64的长度,如下图所示 :

③进行树化,将链表转为红黑树。
可以看到,此时集合中元素的个数为10(即在之前8个元素的基础上又加入了2个),但是table数组的长度已经由原来的16扩到了64。下一步我们再次添加元素时,就要对该table数组中的该链表进行树化了。当然,在树化前,我们还需要明确当前链表的状态,如下所示 :
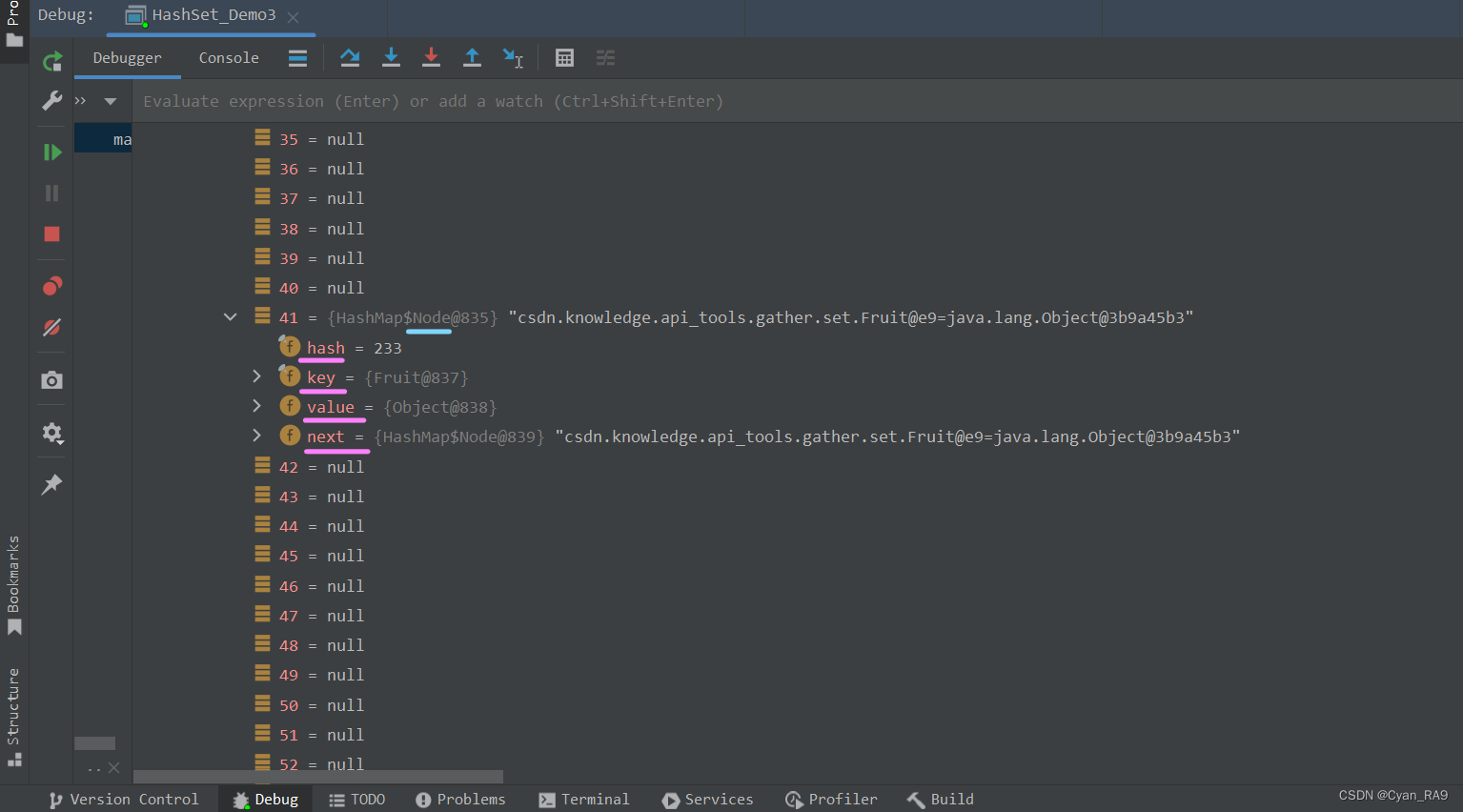
仔细观察,一定要记住,目前我们的链表还是Node类型,并且里面存放了hash, key, value, next这四个值。
好的,接下来我们继续向集合中添加元素,如下图所示 : 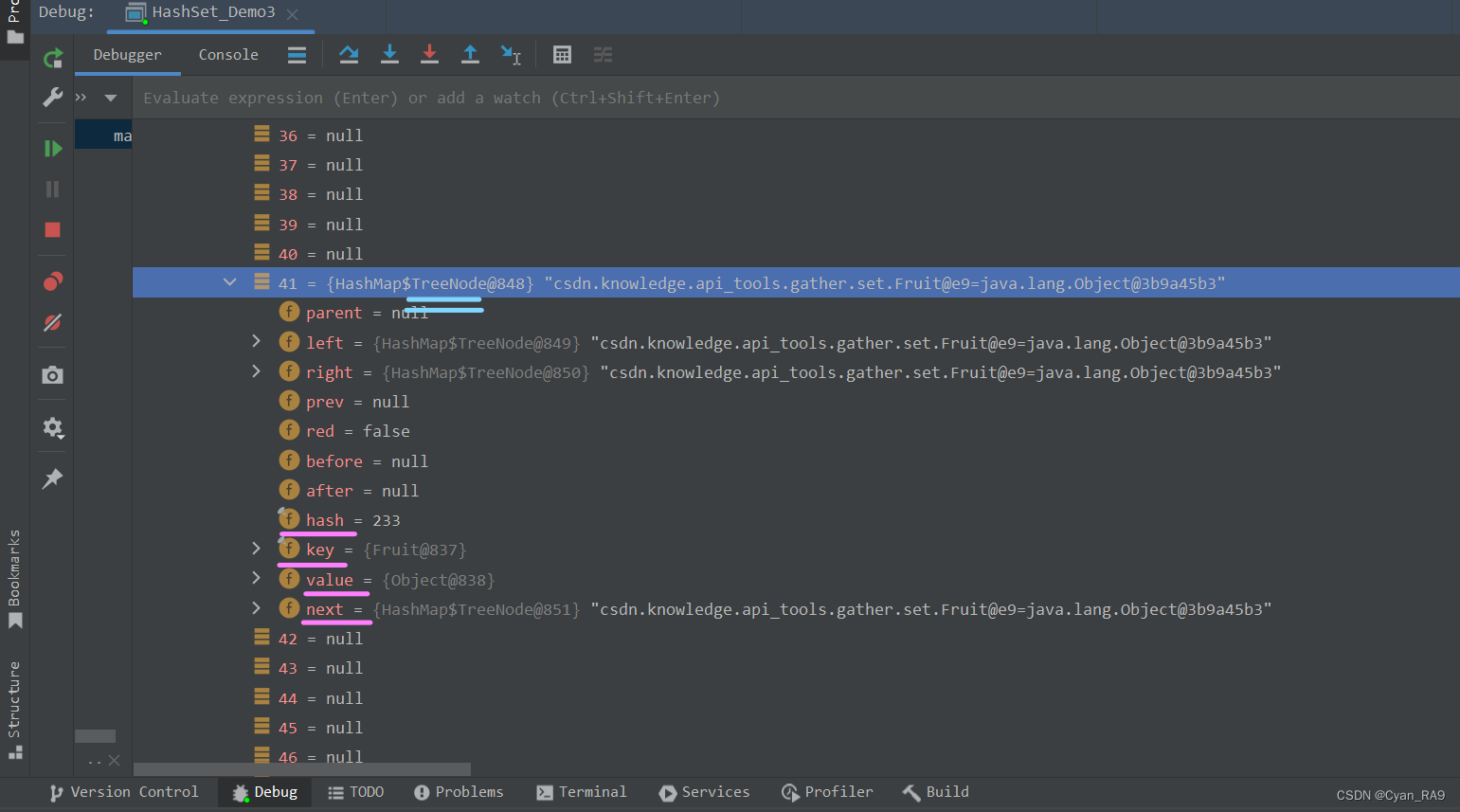 可以看到,除了我们之前存入的那4个值,链表中的结点又存储许多其他的信息。
可以看到,除了我们之前存入的那4个值,链表中的结点又存储许多其他的信息。
而且,最重要的是,该链表的类型已经从Node类型变成TreeNode类型,成功转化成了红黑树。
这下大家对HashMap底层的树化过程算是了解了吧。
五、完结撒❀
🆗,以上就是我们HashSet源码分析的全部内容了😆。up觉得已经讲得够细了,至少比培训机构讲得细(bushi)。好的,回顾以下,我们利用Debug,从底层给大家解释了HashSet(其实就是HashMap)是如何在添加元素时进行判断的;还给大家演示了HashMap底层的扩容机制和链表转化为红黑树的过程。
当然,还是希望大家下去以后多多动手。之后up还打算继续出HashMap的源码解读,当然,鉴于HashSet底层就是HashMap,我们在HashMap源码解读中就不会讲这么细了。感谢阅读!
System.out.println("END----------------------------------------------------");