12个 Python 装饰器让代码cleaner
0 — 引言
装饰器能在在不影响质量的情况下用更少的代码做更多的事情。
Python 装饰器是强大的工具,可帮助你生成干净、可重用和可维护的代码。
我等了很久才想了解这些抽象,现在我已经有了扎实的理解,本篇是为了帮助你也掌握这些对象背后的概念。
今天没有大的介绍或冗长的理论。
这篇文章是经常在项目中使用的 12 个有用的装饰器的文档列表,以使用额外的功能扩展代码。
我们将深入研究每个装饰器,分析代码并尝试一些具体示例。
如果你是 Python 开发人员,这篇文章将使用有用的脚本扩展你的工具箱,以提高你的工作效率并避免重复代码。
1 — @logger(开始)✏️
如果你不熟悉装饰器,你可以将它们视为将函数作为输入并在不改变其主要用途的情况下扩展其功能的特殊函数。
让我们从一个简单装饰器开始,它通过记录函数开始和结束执行的时间来扩展函数。
被装饰的函数的结果如下所示:
some_function(args)
# ----- some_function: 开始 -----
# some_function 执行
# ----- some_function: 结束 -----要编写这个 decroator,你首先必须选择一个合适的名称:我们称它为logger。
logger是一个函数,它接受一个函数作为输入并返回一个函数作为输出。输出函数通常是输入的扩展版本。start在我们的例子中,我们希望output函数用start 和end语句包围input函数的调用。
由于我们不知道输入函数使用什么参数,我们可以使用*args和**kwargs传递给wrapper函数。这些表达式允许传递任意数量的位置参数和keyword 参数。
下面是logger装饰器的一个简单实现:
def logger(function):
def wrapper(*args, **kwargs):
print(f"----- {function.__name__}: start -----")
output = function(*args, **kwargs)
print(f"----- {function.__name__}: end -----")
return output
return wrapper现在你可以将logger应用到some_function或任何其他函数。
decorated_function = logger(some_function)Python 为此提供了更 Pythonic 的语法,它使用@符号。
@logger
def some_function(text):
print(text)
some_function("first test")
# ----- some_function: start -----
# first test
# ----- some_function: end -----
some_function("second test")
# ----- some_function: start -----
# second test
# ----- some_function: end -----2 — @wraps 🎁
这个装饰器将wrapper包装函数更新为看起来像原始函数,并继承了它的名称和属性。
为了理解它的@wraps作用以及为什么要使用它,让我们把前面的装饰器应用到一个简单的函数中,该函数将两个数字相加。
(这个装饰器还没有使用@wraps)
def logger(function):
def wrapper(*args, **kwargs):
"""wrapper documentation"""
print(f"----- {function.__name__}: start -----")
output = function(*args, **kwargs)
print(f"----- {function.__name__}: end -----")
return output
return wrapper
@logger
def add_two_numbers(a, b):
"""this function adds two numbers"""
return a + badd_two_numbers如果我们通过调用__name__和属性来检查修饰函数的名称和文档__doc__,我们会得到……不自然(但仍是预期的)结果:
add_two_numbers.__name__
'wrapper'
add_two_numbers.__doc__
'wrapper documentation'我们取而代之的是装饰函数名称和文档 ⚠️
这是不希望的结果。我们希望保留原始函数的名称和文档。这时候@wraps装饰器 就派上用场了。
你所要做的就是装饰wrapper函数。
from functools import wraps
def logger(function):
@wraps(function)
def wrapper(*args, **kwargs):
"""wrapper documentation"""
print(f"----- {function.__name__}: start -----")
output = function(*args, **kwargs)
print(f"----- {function.__name__}: end -----")
return output
return wrapper
@logger
def add_two_numbers(a, b):
"""this function adds two numbers"""
return a + b通过重新检查名称和文档,我们看到了原始函数的元数据。
add_two_numbers.__name__
# 'add_two_numbers'
add_two_numbers.__doc__
# 'this function adds two numbers'3 — @lru_cache 💨
这是一个内置的装饰器,你可以从functools. 导入
它是缓存函数的返回值,使用最近最少使用 (LRU) 算法在缓存已满时丢弃最少使用的值。
我通常将此装饰器用于长时间运行的任务,这些任务不会使用相同的输入更改输出,例如查询数据库、请求静态远程网页或运行一些繁重的处理。
在下面的例子中,我用lru_cache装饰器来模拟一些处理的函数。然后,我连续多次将该函数应用于同一输入。
import random
import time
from functools import lru_cache
@lru_cache(maxsize=None)
def heavy_processing(n):
sleep_time = n + random.random()
time.sleep(sleep_time)
# first time
%%time
heavy_processing(0)
# CPU times: user 363 µs, sys: 727 µs, total: 1.09 ms
# Wall time: 694 ms
# second time
%%time
heavy_processing(0)
# CPU times: user 4 µs, sys: 0 ns, total: 4 µs
# Wall time: 8.11 µs
# third time
%%time
heavy_processing(0)
# CPU times: user 5 µs, sys: 1 µs, total: 6 µs
# Wall time: 7.15 µs如果你想从头开始自己实现一个缓存装饰器,你可以这样做:
你将空字典作为属性添加到包装函数,以存储输入函数先前计算的值
调用输入函数时,首先检查它的参数是否存在于缓存中。如果是这样,返回结果。否则,计算它并将其放入缓存中。
from functools import wraps
def cache(function):
@wraps(function)
def wrapper(*args, **kwargs):
cache_key = args + tuple(kwargs.items())
if cache_key in wrapper.cache:
output = wrapper.cache[cache_key]
else:
output = function(*args)
wrapper.cache[cache_key] = output
return output
wrapper.cache = dict()
return wrapper
@cache
def heavy_processing(n):
sleep_time = n + random.random()
time.sleep(sleep_time)
%%time
heavy_processing(1)
# CPU times: user 446 µs, sys: 864 µs, total: 1.31 ms
# Wall time: 1.06 s
%%time
heavy_processing(1)
# CPU times: user 11 µs, sys: 0 ns, total: 11 µs
# Wall time: 13.1 µs4 — @repeat 🔁
这个装饰器导致一个函数被连续多次调用。
这对于调试目的、压力测试或自动重复多项任务很有用。
与之前的装饰器不同,这个装饰器需要一个输入参数。
def repeat(number_of_times):
def decorate(func):
@wraps(func)
def wrapper(*args, **kwargs):
for _ in range(number_of_times):
func(*args, **kwargs)
return wrapper
return decorate下面的示例定义了一个装饰器,调用repeat它以多次作为参数。装饰器然后定义一个函数调用wrapper,它包裹在被装饰的函数周围。该wrapper函数调用装饰函数的次数等于指定的次数。
@repeat(5)
def dummy():
print("hello")
dummy()
# hello
# hello
# hello
# hello
# hello5 — @timeit ⏲️
这个装饰器测量函数的执行时间并打印结果:这用作调试或监视。
在下面的代码片段中,timeit装饰器测量函数执行所花费的时间process_data并以秒为单位打印出经过的时间。
import time
from functools import wraps
def timeit(func):
@wraps(func)
def wrapper(*args, **kwargs):
start = time.perf_counter()
result = func(*args, **kwargs)
end = time.perf_counter()
print(f'{func.__name__} took {end - start:.6f} seconds to complete')
return result
return wrapper
@timeit
def process_data():
time.sleep(1)
process_data()
# process_data took 1.000012 seconds to complete6 — @retry 🔁
这个装饰器强制函数在遇到异常时重试多次。
它需要三个参数:重试次数、捕获和重试的异常以及重试之间的休眠时间。
它是这样工作的:
包装函数启动迭代的 for 循环num_retries。
在每次迭代中,它都会调用 try/except 块中的输入函数。当调用成功时,它会打破循环并返回结果。否则,它会休眠sleep_time秒并继续下一次迭代。
当 for 循环结束后函数调用不成功时,包装函数将引发异常。
import random
import time
from functools import wraps
def retry(num_retries, exception_to_check, sleep_time=0):
"""
Decorator that retries the execution of a function if it raises a specific exception.
"""
def decorate(func):
@wraps(func)
def wrapper(*args, **kwargs):
for i in range(1, num_retries+1):
try:
return func(*args, **kwargs)
except exception_to_check as e:
print(f"{func.__name__} raised {e.__class__.__name__}. Retrying...")
if i < num_retries:
time.sleep(sleep_time)
# Raise the exception if the function was not successful after the specified number of retries
raise e
return wrapper
return decorate
@retry(num_retries=3, exception_to_check=ValueError, sleep_time=1)
def random_value():
value = random.randint(1, 5)
if value == 3:
raise ValueError("Value cannot be 3")
return value
random_value()
# random_value raised ValueError. Retrying...
# 1
random_value()
# 57 — @countcall 🔢
这个装饰器计算一个函数被调用的次数。
这个数字存储在包装器属性中count。
from functools import wraps
def countcall(func):
@wraps(func)
def wrapper(*args, **kwargs):
wrapper.count += 1
result = func(*args, **kwargs)
print(f'{func.__name__} has been called {wrapper.count} times')
return result
wrapper.count = 0
return wrapper
@countcall
def process_data():
pass
process_data()
process_data has been called 1 times
process_data()
process_data has been called 2 times
process_data()
process_data has been called 3 times8 — @rate_limited 🚧
这是一个装饰器,它通过在函数调用过于频繁时休眠一段时间来限制调用函数的速率。
import time
from functools import wraps
def rate_limited(max_per_second):
min_interval = 1.0 / float(max_per_second)
def decorate(func):
last_time_called = 0.0
@wraps(func)
def rate_limited_function(*args, **kargs):
elapsed = time.perf_counter() - last_time_called
left_to_wait = min_interval - elapsed
if left_to_wait > 0:
time.sleep(left_to_wait)
ret = func(*args, **kargs)
last_time_called = time.perf_counter()
return ret
return rate_limited_function
return decorate装饰器的工作方式是测量自上次调用该函数以来经过的时间,并在必要时等待适当的时间以确保不超过速率限制。等待时间计算为min_interval - elapsed,其中min_interval是两次函数调用之间的最小时间间隔(以秒为单位),elapsed是自上次调用以来经过的时间。
如果经过的时间小于最小间隔,该函数将等待几left_to_wait秒钟,然后再次执行。
因此,此函数在调用之间引入了轻微的时间开销,但确保不超过速率限制。
还有一个实现 API 速率限制的第三方包ratelimit:它称为ratelimit。
pip install ratelimit要使用这个包,只需装饰任何进行 API 调用的函数:
from ratelimit import limits
import requests
FIFTEEN_MINUTES = 900
@limits(calls=15, period=FIFTEEN_MINUTES)
def call_api(url):
response = requests.get(url)
if response.status_code != 200:
raise Exception('API response: {}'.format(response.status_code))
return response如果装饰函数被调用的次数超过允许的次数,ratelimit.RateLimitException则引发 a 。
为了能够处理这个异常,可以sleep_and_retry结合装饰器使用装饰器ratelimit。
@sleep_and_retry
@limits(calls=15, period=FIFTEEN_MINUTES)
def call_api(url):
response = requests.get(url)
if response.status_code != 200:
raise Exception('API response: {}'.format(response.status_code))
return response这会导致函数在再次执行之前休眠剩余的时间。
9 — @dataclass 🗂️
Python中的装饰@dataclass器是用来装饰类的。
它自动为主要存储数据的类生成特殊方法,例如__init__、__repr__、__eq__、__lt__和。__str__这可以减少样板代码并使类更具可读性和可维护性。
它还提供了现成的漂亮方法来很好地表示对象,将它们转换为 JSON 格式,使它们不可变等。
装饰@dataclass器是在 Python 3.7 中引入的,并且在标准库中可用。
from dataclasses import dataclass,
@dataclass
class Person:
first_name: str
last_name: str
age: int
job: str
def __eq__(self, other):
if isinstance(other, Person):
return self.age == other.age
return NotImplemented
def __lt__(self, other):
if isinstance(other, Person):
return self.age < other.age
return NotImplemented
john = Person(first_name="John",
last_name="Doe",
age=30,
job="doctor",)
anne = Person(first_name="Anne",
last_name="Smith",
age=40,
job="software engineer",)
print(john == anne)
# False
print(anne > john)
# True
asdict(anne)
#{'first_name': 'Anne',
# 'last_name': 'Smith',
# 'age': 40,
# 'job': 'software engineer'}如果你对数据类感兴趣,可以查看我之前的一篇文章。
10 — @register 🛑
如果你的 Python 脚本意外终止,但你仍想执行一些任务来保存你的工作、执行清理或打印一条消息,我发现 register 装饰器在这种情况下非常方便。
from atexit import register
@register
def terminate():
perform_some_cleanup()
print("Goodbye!")
while True:
print("Hello")运行此脚本并按下 CTRL+C 时,
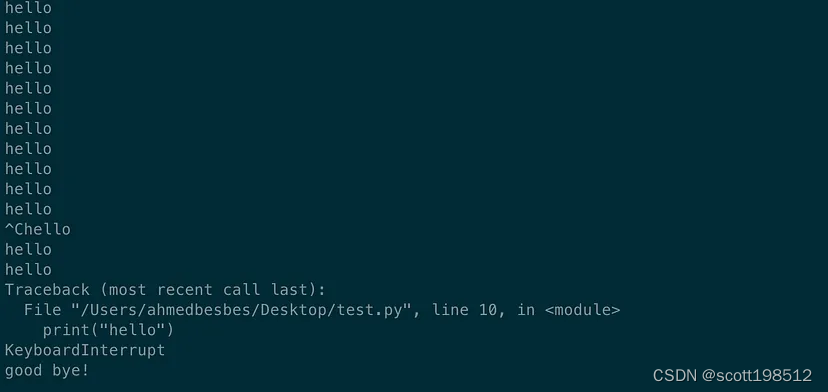
我们看到了函数的输出terminate。
11 — @property 🏠
属性装饰器用于定义类属性,这些属性本质上是类实例属性的getter、setter和deleter方法。
通过使用属性装饰器,你可以将方法定义为类属性并像访问类属性一样访问它,而无需显式调用该方法。
如果你想围绕获取和设置值添加一些约束和验证逻辑,这将很有用。
在下面的示例中,我们在 rating 属性上定义了一个 setter 以对输入(0 到 5 之间)施加约束。
class Movie:
def __init__(self, r):
self._rating = r
@property
def rating(self):
return self._rating
@rating.setter
def rating(self, r):
if 0 <= r <= 5:
self._rating = r
else:
raise ValueError("The movie rating must be between 0 and 5!")
batman = Movie(2.5)
batman.rating
# 2.5
batman.rating = 4
batman.rating
# 4
batman.rating = 10
# ---------------------------------------------------------------------------
# ValueError Traceback (most recent call last)
# Input In [16], in <cell line: 1>()
# ----> 1 batman.rating = 10
# Input In [11], in Movie.rating(self, r)
# 12 self._rating = r
# 13 else:
# ---> 14 raise ValueError("The movie rating must be between 0 and 5!")
#
# ValueError: The movie rating must be between 0 and 5!12 — @singledispatch
这个装饰器允许一个函数对不同类型的参数有不同的实现。
from functools import singledispatch
@singledispatch
def fun(arg):
print("Called with a single argument")
@fun.register(int)
def _(arg):
print("Called with an integer")
@fun.register(list)
def _(arg):
print("Called with a list")
fun(1) # Prints "Called with an integer"
fun([1, 2, 3]) # Prints "Called with a list"结论
装饰器是有用的抽象,可以使用额外的功能扩展你的代码,例如缓存、自动重试、速率限制、日志记录,或将你的类变成超级数据容器。
它并不止于此,因为你可以更有创意并实施你的自定义装饰器来解决非常具体的问题。
这里有一个很棒的装饰器列表,可以从中获得灵感,在适当的时候予以借鉴。
参考
12-python-decorators