数据清洗是清洗什么?
在搭建数据中台、数据仓库或者做数据分析之前,首要的工作重点就是做数据清洗,否则会影响到后续对数据的分析利用。那么数据清洗到底是做什么事情呢?今天我就来跟大家分享一下。

数据清洗的基本概念
按百度百科给出的解释,“数据清洗是对数据进行重新审查和校验的过程,目的在于删除重复信息、纠正存在的错误,并提供数据一致性。”其实从字面上来理解也是行得通的,就是把数据中的脏东西洗掉,转变为高质量的数据。
那么数据中有哪些类型的脏东西呢?主要有四类:异常值、空值、重复值以及数据格式。
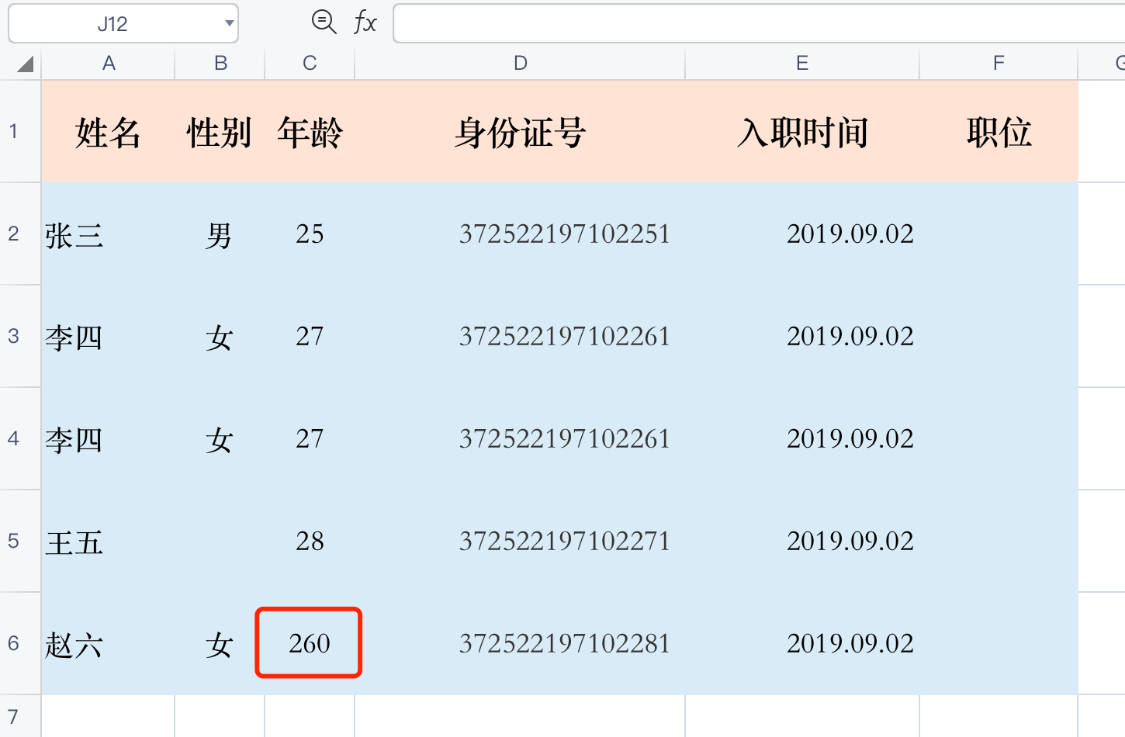
异常值
(一)判别异常值
所谓的异常值,就是指偏差较大的数据,一般常用一些统计模型设定置信区间来进行异常值的判别,包含了拉依达准则、狄克逊准则、格拉布斯准则、T 检验等。这些统计模型经常是组合起来使用,能够尽可能减少误差。
(二)清洗异常值
对于已经判别出来的异常值,尽量不要一下子就全删了,而是要进行多轮的统计判断,每轮只删除少部分数据,这样能最大程度地保证数据的完整性。并且,在判别出异常值之后,产品经理一定要追根究底,调研清楚异常值的来源和原因。
空值
对于空值的判别是很简单的事情,要关注的重点是对空值的清洗方法。
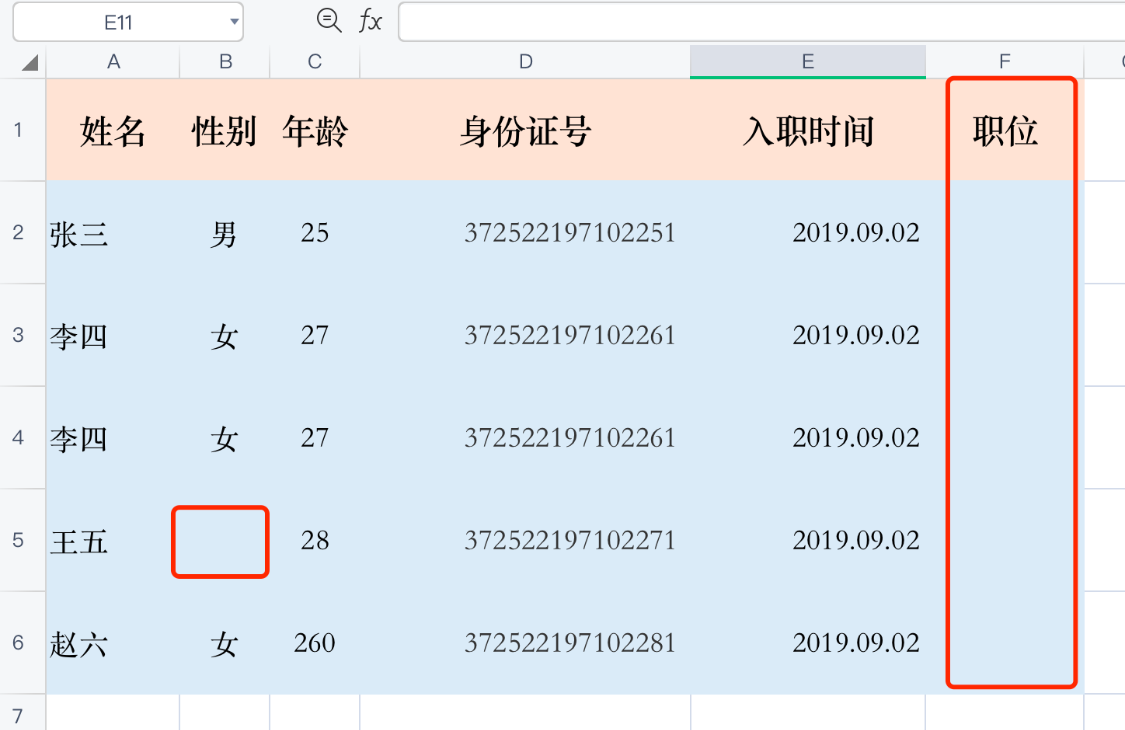
如果该维度的数据大半数以上或者全部都是空值,产品经理应该了解清楚该维度存在的必要性,可以考虑删除该维度指标。
如果该维度的数据存在少量空值,那产品经理可以根据样本量来权衡。如果样本量很大,空值占比很小,则可以考虑直接删除空值;如果样本量不大,则应该考虑将空值填充,常用的填充方法有平均值填充、回归法、多重插补法等。
重复值
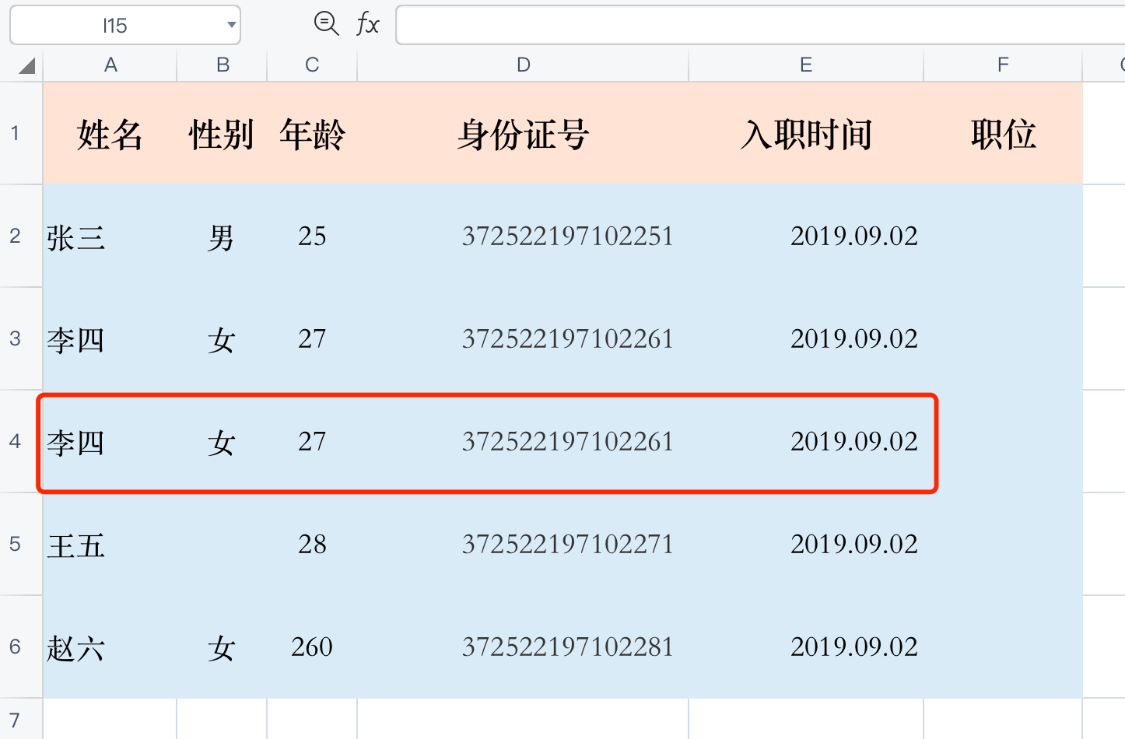
重复值比较好处理,通常来说就是直接删除,但对于重复值的判断,一定要定好重复判断的标准,规范好重复特征,明确是按照主要信息重复即算重复还是按照全部信息重复才算是重复。
数据格式
在数据清洗过程中,还存在另一种类型的错误要注意,就是数据格式。数据格式的错误主要体现在数据内容的格式与元数据描述不一致,通常这种时候就需要产品经理从输入源去着手调研。
写在最后
数据清洗是企业能够高效利用数据价值的关键前提,只有将脏数据清洗为完整、准确、有用的数据,方能更好地完全体现数据的价值。
想了解更多产品经理相关的知识和经验,欢迎关注我,和我一起共同进步。