【Python_requests学习笔记(六)】基于requests模块构建免费代理IP池
基于requests模块构建免费代理IP池
前言
此篇文章中介绍如何使用requests模块,抓取免费代理IP,创建免费的代理IP池。
正文
1、需求梳理
构建免费代理IP池:抓取快代理 免费高匿代理,并测试是否可用,建立免费代理IP池。
2、爬虫思路
-
确认所抓数据在响应内容中是否存在
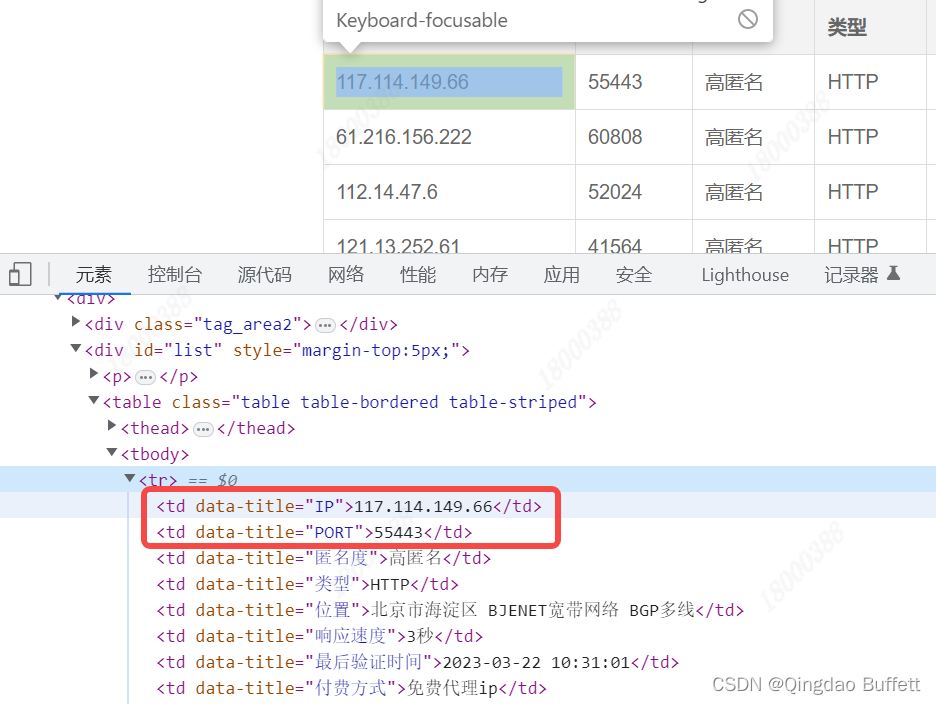
所抓取的内容在响应内容中存在 -
分析url地址规律
第1页: https://www.kuaidaili.com/free/inha/1/
第2页:https://www.kuaidaili.com/free/inha/2/
第3页:https://www.kuaidaili.com/free/inha/3/
…
第n页:https://www.kuaidaili.com/free/inha/n/
url地址:https://www.kuaidaili.com/free/inha/{}/ -
写xpath表达式
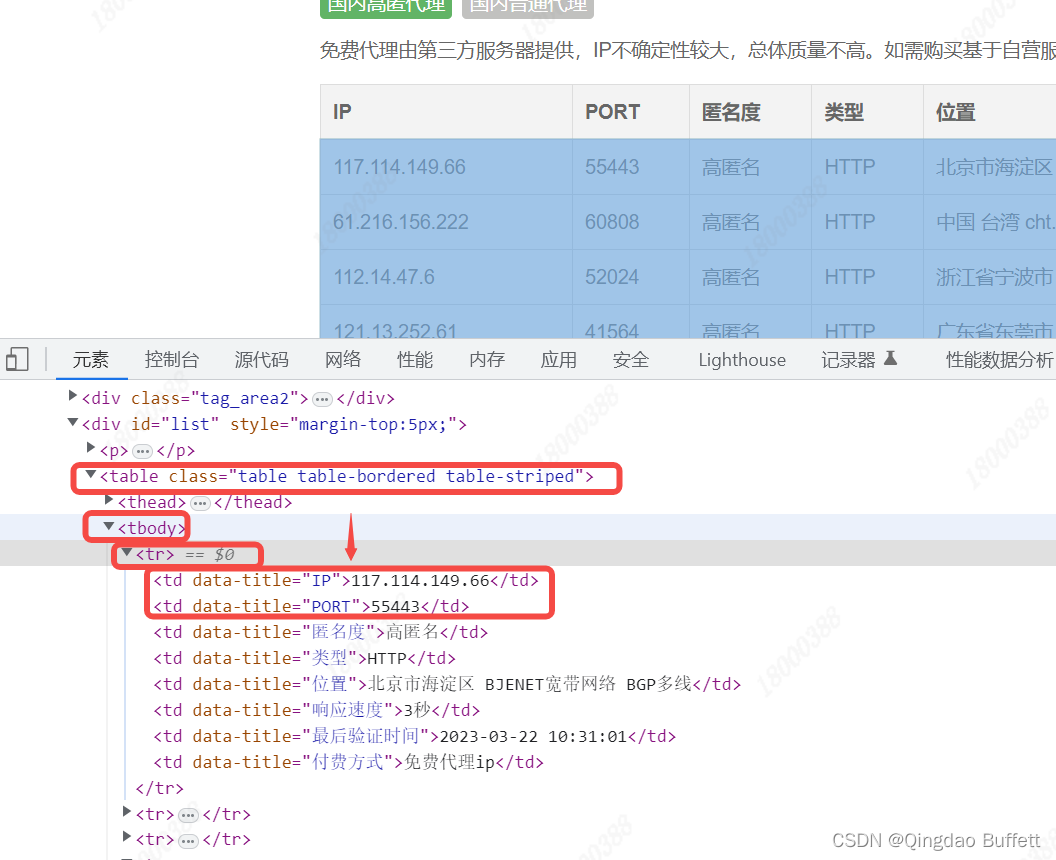
通过F12检查可以看到,想要爬取的数据IP 和 PORT 在 table节点下(class属性值为’table table-bordered table-striped’)的 tbody节点下的 tr节点。
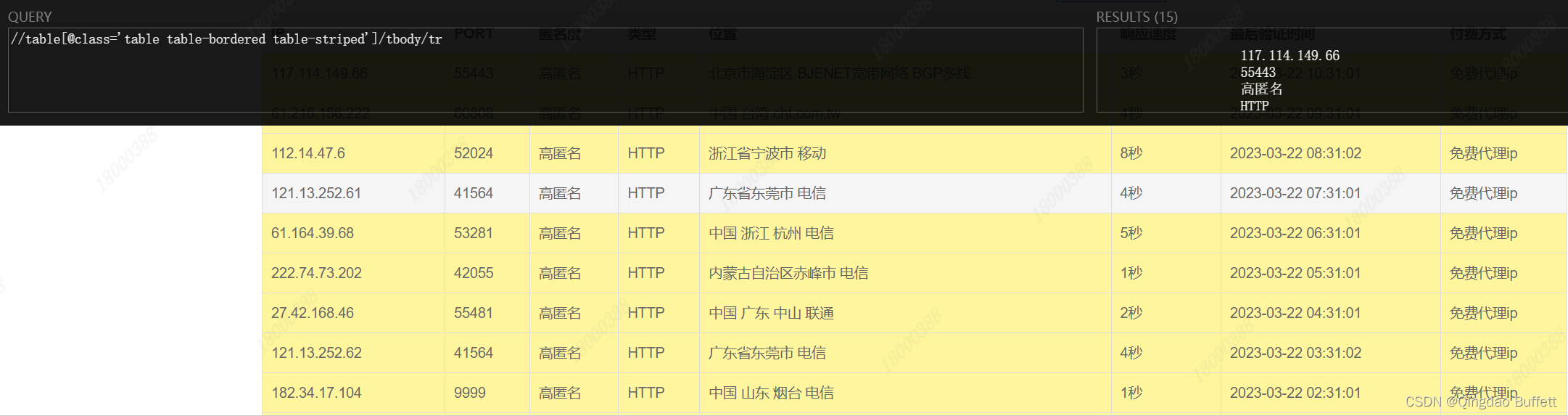
经过Xpath Helper验证正确,xpath表达式为:"//table[@class='table table-bordered table-striped']/tbody/tr" -
编写程序框架、完善程序
详情见3、程序实现
3、程序实现
- 初始化函数
初始化url地址 & 测试网站url地址
def __init__(self):
self.url = 'https://www.kuaidaili.com/free/inha/{}/' # url地址
self.text_url = "http://baidu.com/" # 测试url
- 获取IP&Port函数
def get_proxy_pool(self, url):
"""
function: 获取url地址的ip和port
in: url:传入的url地址
out: ip:代理ip
port:端口号
return: None
others: Get IP & Port Func
"""
headers = {'User-Agent': UserAgent().random} # 构建随机请求头
html = requests.get(url=url, headers=headers).text # 获取快代理页面的响应内容
p = etree.HTML(html) # 创造解析对象
# 1、基准xpath //table[@class='table table-bordered table-striped']/tbody/tr/td
tr_list = p.xpath("//table[@class='table table-bordered table-striped']/tbody/tr") # 解析对象调用xpath
for tr in tr_list[1:]:
ip = tr.xpath("./td[1]/text()")[0].strip()
port = tr.xpath("./td[2]/text()")[0].strip()
# 测试代理IP是否可用
self.text_proxy(ip, port)
- 测试代理IP函数
def text_proxy(self, ip, port):
"""
function: 测试一个代理IP是否可用函数
in: ip:代理IP
port:端口号
out: None
return: None
others: Text Proxy Func
"""
proxies = {
'http': 'http://{}:{}'.format(ip, port),
'https': 'https://{}:{}'.format(ip, port)
} # 传入ip和端口号
# noinspection PyBroadException
try:
headers = {'User-Agent': UserAgent().random} # 构建随机请求头
res = requests.get(url=self.text_url, headers=headers, timeout=2, proxies=proxies)
if res.status_code == 200: # 判断响应码是否正确
print(ip, port, '\033[31m可用\033[0m') # 打印
with open("proxy.txt", "a") as f:
f.write(ip + ':' + port + '\n') # 写入proxy.txt
except Exception as e:
print(ip, port, '不可用')
- 程序入口函数
def run(self):
"""
function: 程序入口函数
in: None
out: None
return: None
others: Program Entry Func
"""
for i in range(1, 1001):
url = self.url.format(i) # 拼接url地址
self.get_proxy_pool(url=url)
time.sleep(random.randint(1, 2)) # 随机休眠1-2s
4、完整代码
import time
import random
import requests
from lxml import etree
from fake_useragent import UserAgent
class ProxyFreePool:
"""
抓取快代理免费高匿代理,并测试是否可用,建立免费代理IP池
"""
def __init__(self):
self.url = 'https://www.kuaidaili.com/free/inha/{}/' # url地址
self.text_url = "http://baidu.com/" # 测试url
def get_proxy_pool(self, url):
"""
function: 获取url地址的ip和port
in: url:传入的url地址
out: ip:代理ip
port:端口号
return: None
others: Get IP & Port Func
"""
headers = {'User-Agent': UserAgent().random} # 构建随机请求头
html = requests.get(url=url, headers=headers).text # 获取快代理页面的响应内容
p = etree.HTML(html) # 创造解析对象
# 1、基准xpath //table[@class='table table-bordered table-striped']/tbody/tr/td
tr_list = p.xpath("//table[@class='table table-bordered table-striped']/tbody/tr") # 解析对象调用xpath
for tr in tr_list[1:]:
ip = tr.xpath("./td[1]/text()")[0].strip()
port = tr.xpath("./td[2]/text()")[0].strip()
# 测试代理IP是否可用
self.text_proxy(ip, port)
def text_proxy(self, ip, port):
"""
function: 测试一个代理IP是否可用函数
in: ip:代理IP
port:端口号
out: None
return: None
others: Text Proxy Func
"""
proxies = {
'http': 'http://{}:{}'.format(ip, port),
'https': 'https://{}:{}'.format(ip, port)
} # 传入ip和端口号
# noinspection PyBroadException
try:
headers = {'User-Agent': UserAgent().random} # 构建随机请求头
res = requests.get(url=self.text_url, headers=headers, timeout=2, proxies=proxies)
if res.status_code == 200: # 判断响应码是否正确
print(ip, port, '\033[31m可用\033[0m') # 打印
with open("proxy.txt", "a") as f:
f.write(ip + ':' + port + '\n') # 写入proxy.txt
except Exception as e:
print(ip, port, '不可用')
def run(self):
"""
function: 程序入口函数
in: None
out: None
return: None
others: Program Entry Func
"""
for i in range(1, 1001):
url = self.url.format(i) # 拼接url地址
self.get_proxy_pool(url=url)
time.sleep(random.randint(1, 2)) # 随机休眠1-2s
if __name__ == '__main__':
# spider = ProxyPool()
# spider.run()
spider = ProxyFreePool()
spider.run()
5、实现效果
