ElasticSearch查询语句用法
查询用法包括:match、match_phrase、multi_match、query_string、term
1.match
1.1 不同字段权重
如果需要为不同字段设置不同权重,可以考虑使用bool查询的should子句来组合多个match查询,并为每个match查询设置不同的权重
{
"query": {
"bool": {
"should": [
{
"match": {
"product_name": {
"query": "apple",
"boost": 3
}
}
},
{
"match": {
"description": {
"query": "apple",
"boost": 1
}
}
}
]
}
}
}上面的查询将在product_name字段和description字段中搜索包含"apple"的文档,并为product_name字段设置权重为3,而为description字段设置权重为1。这样,在计算匹配得分时,product_name字段的匹配将比description字段的匹配更加重要,因为它的权重更高。
这种方式可以灵活地控制不同字段地权重,以满足不同的搜索需求。
2、match_phrase
match_phrase查询是ES中一种用于精确匹配短语的查询方式,可以确保查询字符串中的关键词按照给定的顺序在文档中连续出现。以下是match_phrase查询的用法:
2.1 简单用法
match_phrase查询可以直接指定一个字段和一个短语进行匹配。
GET grade2/_search
{
"query": {
"match_phrase": {
"character": "谦虚 态度"
}
},
"track_total_hits": true
}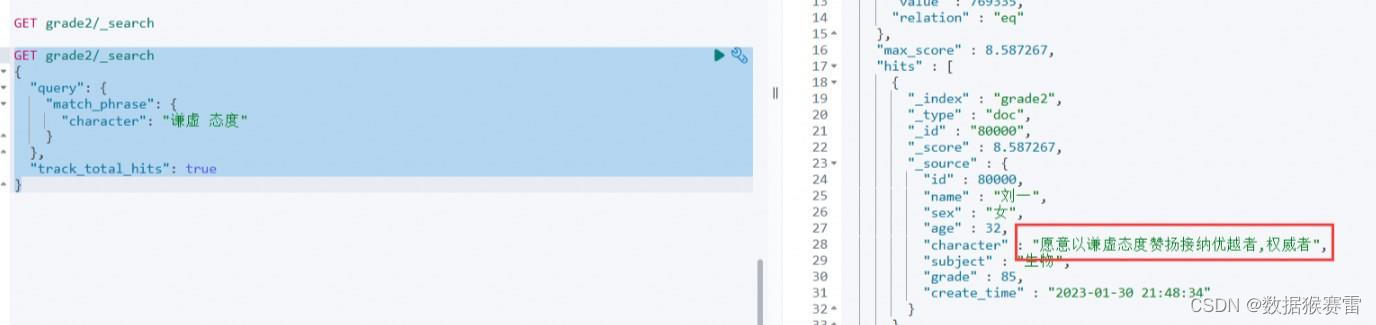
上面的查询将在character字段中搜索包含短语"谦虚 态度"的文档。
2.2 可调节因子
match_phrase默认要求完全匹配上query的短语,完全匹配可能比较严,我们会希望有个可调节因子,少匹配一个也满足,那就需要用到slop
GET grade2/_search
{
"query": {
"match_phrase": {
"character": {
"query": "谦虚 赞扬",
"slop": 2
}
}
},
"track_total_hits": true
}
3、multi_match
multi_match查询是ES中一种用于在多个字段中搜索相同查询字符串的查询方式。它可以在多个字段之间执行相同的查询,并且可以指定不同字段之间的权重(boost),从而影响匹配的相对重要性。
3.1 简单用法
multi_match查询可以直接指定一个查询字符串,然后在多个字段中进行搜索,其中一个字段有这个字符串就满足。
GET grade2/_search
{
"query": {
"multi_match": {
"query": "张一",
"fields": ["name", "character"]
}
},
"track_total_hits": true
}
上面的查询将在name和character字段中搜索包含"张一"的文档。
3.2 类型匹配
multi_match查询可以通过type参数指定匹配的类型,如 "best_fields"、 "most_fields"、 "cross_fields"、 "phrase"、 "phrase_prefix" 等。不同的类型在匹配方式和结果计算上有所不同。
GET grade2/_search
{
"query": {
"multi_match": {
"query": "张一",
"fields": ["name", "character"],
"type": "best_fields"
}
}
}上面的查询将使用 "best_fields" 类型在 name 和 character字段中搜索包含短语 "张一" 的文档。
(1)best_fields:我们希望完全匹配的文档占的评分比较高,multi_match默认是best_fields
{
"query": {
"multi_match": {
"query": "王阳明",
"fields": [
"title",
"yearAlias"
],
"minimum_should_match": "70%"
}
}
}(2)most_fields:我们希望越多字段匹配的文档评分越高
{
"query": {
"multi_match": {
"query": "王阳明",
"type": "most_fields",
"fields": [
"title",
"keywords"
]
}
}
}(3)cross_fields:我们希望这个词条词汇是分配到不同字段中的
{
"query": {
"multi_match": {
"query": "王阳明",
"fields": [
"title",
"keywords"
],
"type": "cross_fields"
}
},
"highlight": {
"fields": {
"title": {
"pre_tags": ["<a>" ],
"post_tags": [ "</a>"]
},
"keywords": {
"pre_tags": ["<b>" ],
"post_tags": ["</b>" ]
}
}
}
}4、query_string
在ES中,query_string是一种查询方式,用于在文本字段上执行灵活且强大的搜索操作。query_string查询支持使用Lucene查询语法进行高级搜索,可以通过在查询字符串中指定不同的搜索条件、操作符和逻辑关系来构建复杂的搜索查询。
4.1 简单的关键词匹配
GET grade2/_search
{
"query": {
"query_string": {
"default_field": "character",
"query": "乐观"
}
},
"track_total_hits": true
}上面的查询将在character字段中搜索包含关键词"乐观"的文档。
4.2 使用逻辑关系和操作符进行组合查询
GET grade2/_search
{
"query": {
"query_string": {
"default_field": "character",
"query": "乐观 OR (赞扬 AND 优越)"
}
},
"track_total_hits": true
}
上面的查询将在character字段中搜索包含关键词"乐观"或者 "赞扬 和 优越"的文档。
GET grade2/_search
{
"query": {
"query_string": {
"default_field": "character",
"query": "乐观 OR (name:刘一 AND age:25 AND 优越)"
}
},
"track_total_hits": true
}上面的查询将在character字段中搜索包含关键词"乐观"或者name字段为"刘一"且age字段为"25"且character字段为"优雅"的文档。
4.3 模糊搜索和通配符搜索
GET account_info/_search
{
"query": {
"query_string": {
"default_field": "email",
"query": "qq?com~"
}
}
}GET account_info/_search
{
"query": {
"query_string": {
"default_field": "email",
"query": "qqcom~"
}
}
}
上面的查询都可以在email中搜索类似于"qq?com"的词,其中"?"表示单个字符的通配符,"~"表示模糊搜索,"*"表示多个字符的通配符。
GET account_info/_search
{
"query": {
"query_string": {
"default_field": "email",
"query": "qqcom~",
"fuzziness": 1
}
}
}
可以指定模糊搜索的最大编辑距离。上面的查询将在文档中搜索与"qqcom~"关键词的拼写相似且最大编辑距离为1的文档。
4.4 指定搜索字段和搜索条件
GET grade2/_search
{
"query": {
"query_string": {
"fields": ["name", "age"],
"default_operator": "AND",
"query": "name:刘一, age:26"
}
},
"track_total_hits": true
}
GET grade2/_search
{
"query": {
"query_string": {
"fields": ["name", "age"],
"default_operator": "AND",
"query": "name:刘一 AND age:[25 TO 26]"
}
},
"track_total_hits": true
}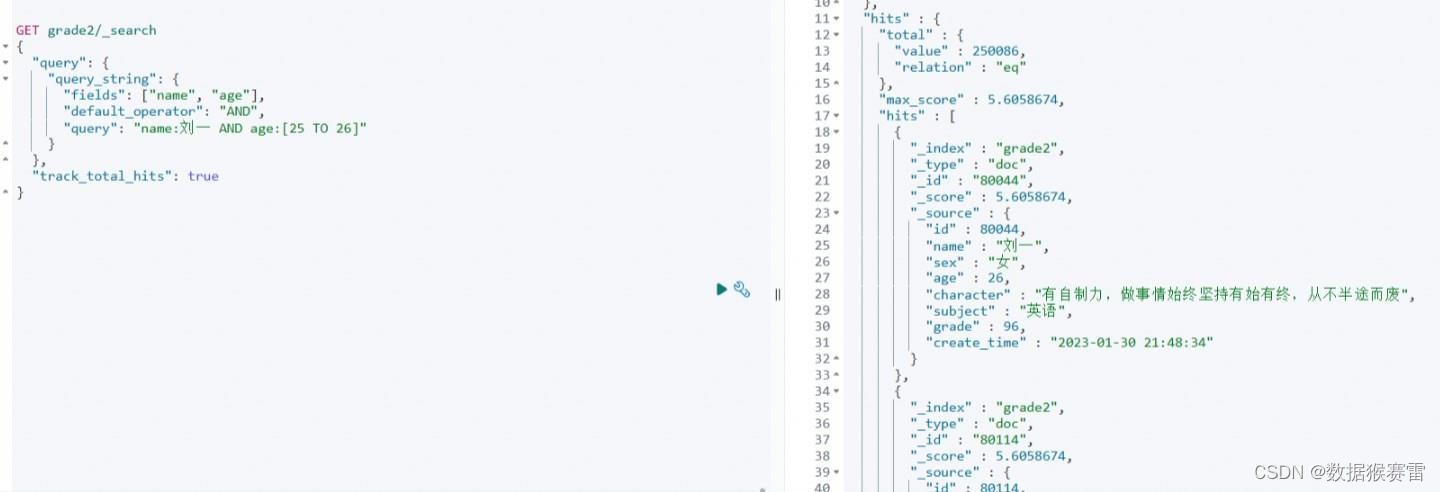
上面的查询将在 name 和 age 字段中搜索包含关键词 "刘一" 并且年龄在 25 到 26 之间的文档,其中 fields 参数用于指定搜索字段,default_operator 参数用于指定默认的逻辑操作符。
需要注意的是,query_string 查询可能存在安全风险,因为它允许直接执行用户输入的查询字符串,可能导致潜在的搜索注入攻击,因此在使用时需谨慎验证和过滤用户输入,以防止安全漏洞。同时,根据实际需求和场景,可以根据 Elasticsearch 的文档和查询语法进行更多的配置和优化。
5、term精确值查找
{
"query": {
"term": {
"title": "王阳明"
}
}
}完全匹配,不进行分词词分析,文档中必须包含整个搜索的词汇。
但是term和terms是 必须包含(must contain) 操作,而不是必须精确相等(must equal exactly)。比如当查询"jack"时,[jack]和[jack,jone]两条数据都会被找到。