Mac上新版InfluxDB使用教程
一、简介
官网:influxdb

二、influxdb安装
建议使用Homebrew在 macOS 上安装 InfluxDB v2:
brew install influxdb
启动influxdb服务:brew services start influxdb
停止influxdb服务:brew services stop influxdb
查看是否启动成功:ps -ef | grep influxd
删除influxdb:brew uninstall influxdb
如果使用brew 不能彻底删除,请删除文件:rm -rf ~/.influxdbv2
服务启动完之后,默认端口号是8086,在控制台打开localhost:8086来访问控制台。
打开控制台,会先创建一个用户,输入username,password,org,bucket。
token一定要保存下来,因为默认没办法查。
按步骤操作完成后就完成初始化了。
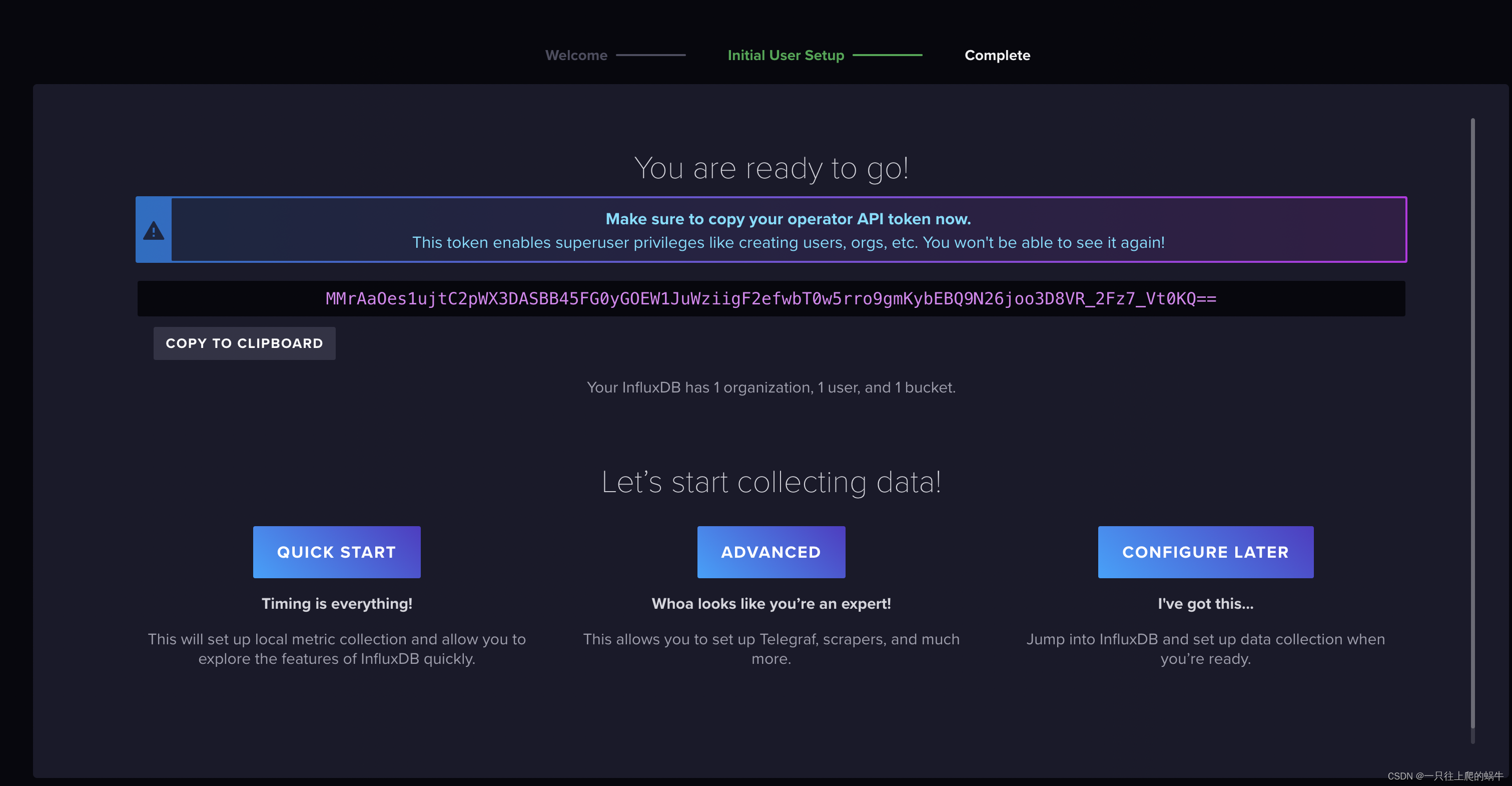
我那时候的token是:
MMrAaOes1ujtC2pWX3DASBB45FG0yGOEW1JuWziigF2efwbT0w5rro9gmKybEBQ9N26joo3D8VR_2Fz7_Vt0KQ==
三、influxdb 交互工具

3.1 influx 命令行
步骤1:安装命令行客户端:brew install influxdb-cli
步骤2:需要配置客户端与 InfluxDB 的初始连接。
下面的代码片段创建了一个名为 onboarding 的配置文件。如果您愿意,可以选择不同的名称。您可能会使用不同的令牌创建另一个配置文件来处理您自己的数据。
influx config create --config-name onboarding \
--host-url "http://localhost:8086" \
--org "5469caff5112762e" \
--token "3lR92AhlSEUqy4vU7baECT9lJM7vlcfaBpW2VH717koCaFTQ0jvhqam2gW70jz01sN8c4nHFRMvbIqlff1UhmA==" \
--active
步骤3:创建桶(bucket):influx bucket create --name bucket_test1 -c onboarding
步骤4:写入数据:influx write --bucket bucket_test1 --url https://influx-testdata.s3.amazonaws.com/air-sensor-data-annotated.csv
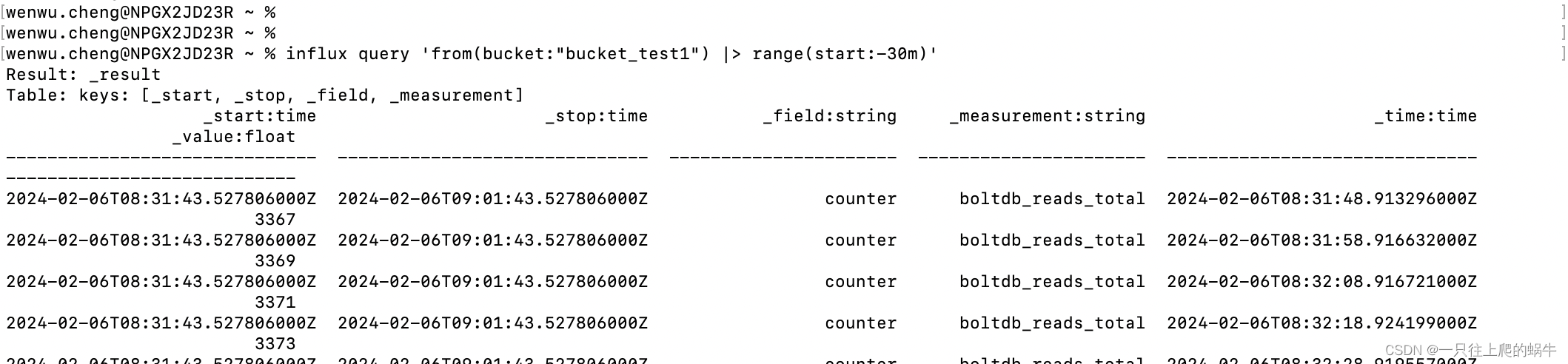
步骤5:查询数据:influx query ‘from(bucket:“bucket_test1”) |> range(start:-30m)’
3.2 InfluxDB HTTP API
步骤1:安装python依赖:pip3 install influxdb-client
步骤2:初始化客户端
import influxdb_client, os, time
from influxdb_client import InfluxDBClient, Point, WritePrecision
from influxdb_client.client.write_api import SYNCHRONOUS
token = "MMrAaOes1ujtC2pWX3DASBB45FG0yGOEW1JuWziigF2efwbT0w5rro9gmKybEBQ9N26joo3D8VR_2Fz7_Vt0KQ=="
org = "QATeam"
url = "http://localhost:8086"
client = influxdb_client.InfluxDBClient(url=url, token=token, org=org)
步骤3:写入数据
bucket = "bucket_test1"
write_api = client.write_api(write_options=SYNCHRONOUS)
for value in range(5):
point = (
Point("measurement1")
.tag("tagname1", "tagvalue1")
.field("field1", value)
)
write_api.write(bucket=bucket, org="QATeam", record=point)
time.sleep(1) # separate points by 1 second
步骤4:查询数据
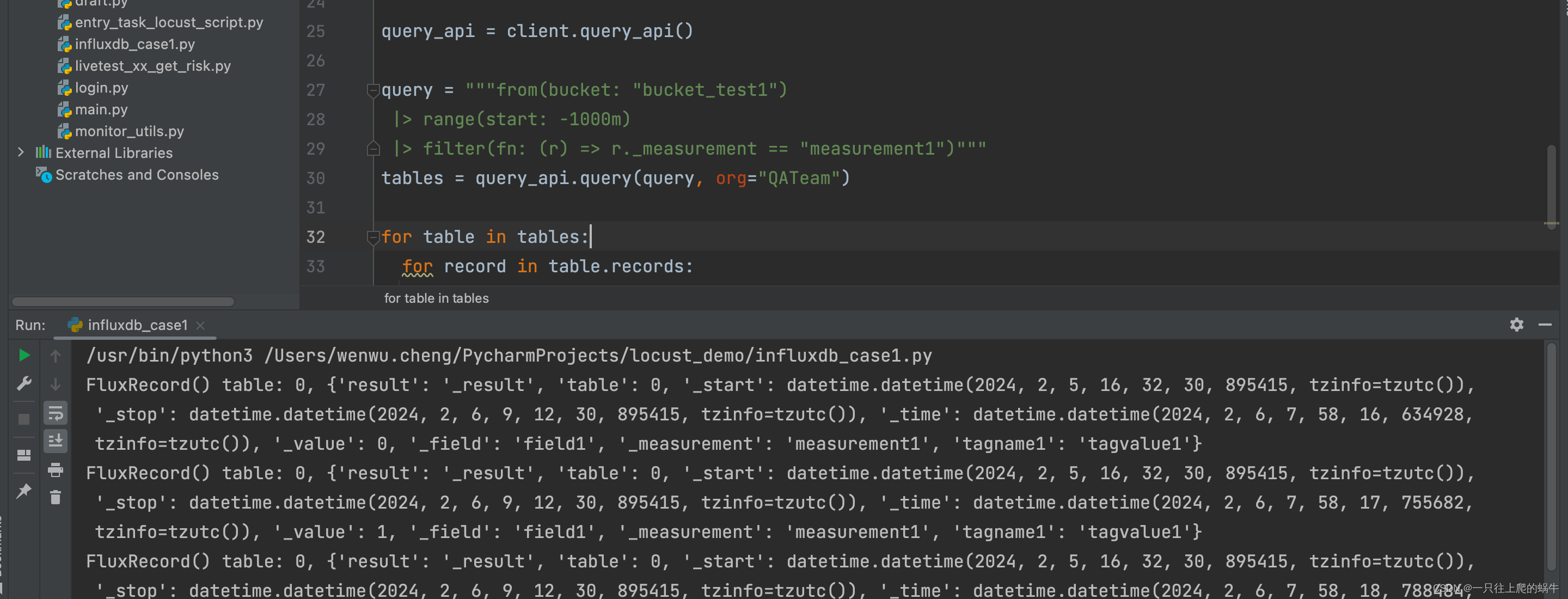
query_api = client.query_api()
query = """from(bucket: "bucket_test1")
|> range(start: -10m)
|> filter(fn: (r) => r._measurement == "measurement1")"""
tables = query_api.query(query, org="QATeam")
for table in tables:
for record in table.records:
print(record)
四、应用场景
作为服务器性能指标的监控工具,
比如Locust + python + influxdb + grafana 展示性能压测QPS图表;
Jmeter + influxdb + grafana展示性能压测QPS图表 等
后续实践完,再更新相应博客~