Golang 学习(一)基础知识
面向对象
-
Golang 也支持面向对象编程(OOP),但是和传统的面向对象编程有区别,并不是纯粹的面向对象语言。
-
Golang 没有类(class),Go 语言的结构体(struct)和其它编程语言的类(class)有同等的地位,Golang 是基于 struct 来实现 OOP 特性的,去掉了传统 OOP 语言的继承、方法重载、构造函数和析构函数、隐藏的 this 指针等等
-
Golang 仍然有面向对象编程的继承,封装和多态的特性,只是实现的方式和其它 OOP 语言不一样,比如继承 :Golang 没有 extends 关键字,继承是通过匿名字段来实现。
-
Golang 面向对象(OOP)很优雅,OOP 本身就是语言类型系统(type system)的一部分,通过接口(interface)关联,耦合性低,也非常灵活。
一、基础知识
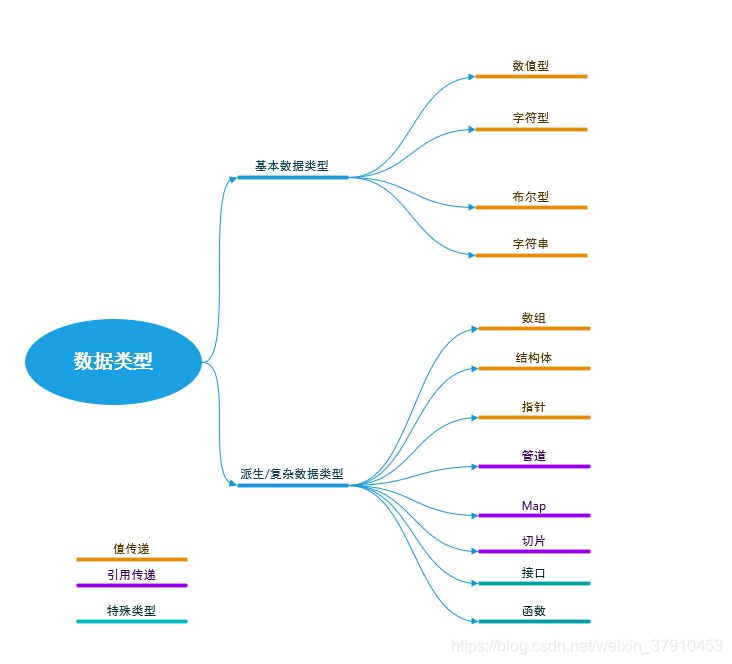
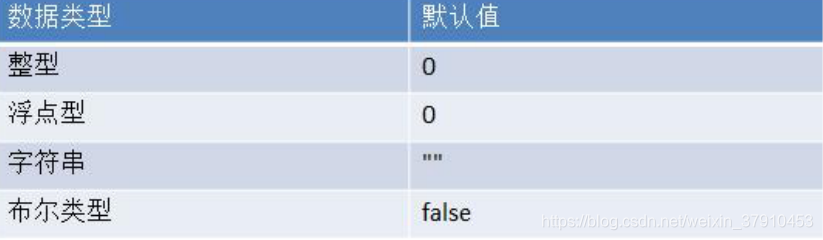
数据类型
## golang字符类型
字符类型的本质是一个整数,占8个字节(Go 的字符串是由字节组成的,根据utf-8编码)
字符型 存储到 计算机中,需要将字符对应的码值(整数)找出来
存储:字符—>对应码值---->二进制–>存储
读取:二进制----> 码值 ----> 字符 --> 读取
字符和码值的对应关系是通过字符编码表决定的(是规定好)
## golang字符串类型
两种表现形式:
(1) 双引号, 会识别转义字符
(2) 反引号,以字符串的原生形式输出,包括换行和特殊字符,可以实现防止攻击、输出源代码等效果
溢出问题
a := int8(127)
b := int8(1)
fmt.Println(a + b) // 输出-128,不会报错
a := uint8(255)
b := uint8(1)
fmt.Println(a + b) //输出0,不会报错
rune 类型:相当int32,由于golang中的字符串底层实现是通过byte数组的,中文字符在unicode下占2个字节,在utf-8编码下占3个字节
- byte 等同于int8,常用来处理ascii字符
- rune 等同于int32,常用来处理unicode或utf-8字符
数组和切片
数组:
- 数组的地址可以通过数组名来获取 &intArr
- 数组的第一个元素的地址,就是数组的首地址
- 数组的各个元素的地址间隔是依据数组的类型决定,比如 int64 -> 8 int32->4…
切片:
slice 底层数据结构是由一个 array 指针指向底层数组,len 表示切片长度,cap 表示切片容量
当扩容时:
- 假如 slice 容量够用,则追加新元素进去,slice.len++,返回原来的 slice。
- 当原容量不够,则 slice 先扩容,扩容之后 slice 得到新的 slice,将元素追加进新的 slice,slice.len++,返回新的 slice。
扩容规则:
当切片比较小时(容量小于 1024),则采用较大的扩容倍速进行扩容(新的扩容会是原来的 2 倍),避免频繁扩容,从而减少内存分配的次数和数据拷贝的代价。当切片较大的时(原来的 slice 的容量大于或者等于 1024),采用较小的扩容倍速(新的扩容将扩大大于或者等于原来 1.25 倍),主要避免空间浪费
和切片的区别:
- 1)数组是定长,访问和复制不能超过数组定义的长度,否则就会下标越界,切片长度和容量可以自动扩容
- 2)数组是值类型,切片是引用类型,每个切片都引用了一个底层数组,切片本身不能存储任何数据,都是这底层数组存储数据,所以修改切片的时候修改的是底层数组中的数据。切片一旦扩容,指向一个新的底层数组,内存地址也就随之改变
Channel
go中的channel是一个队列,遵循先进先出的原则,负责协程之间的通信,channel 是 goroutine 之间数据通信桥梁,而且是线程安全的,写入,读出数据都会加锁。
三种类型:只读 channel、只写 channel(意义在于在参数传递时候指明管道可读还是可写,即使当前管道是可读写的)、可读可写 channel
channel 中只能存放指定的数据类型
channle 的数据放满后,就不能再放入了
在没有使用协程的情况下,如果 channel 数据取完了,再取,就会报 dead lock
goroutine 中使用 recover,解决协程中出现 panic,导致程序崩溃问题
应用场景:
- 停止信号监听
- 定时任务
- 生产方和消费方解耦
- 控制并发数
底层原理:
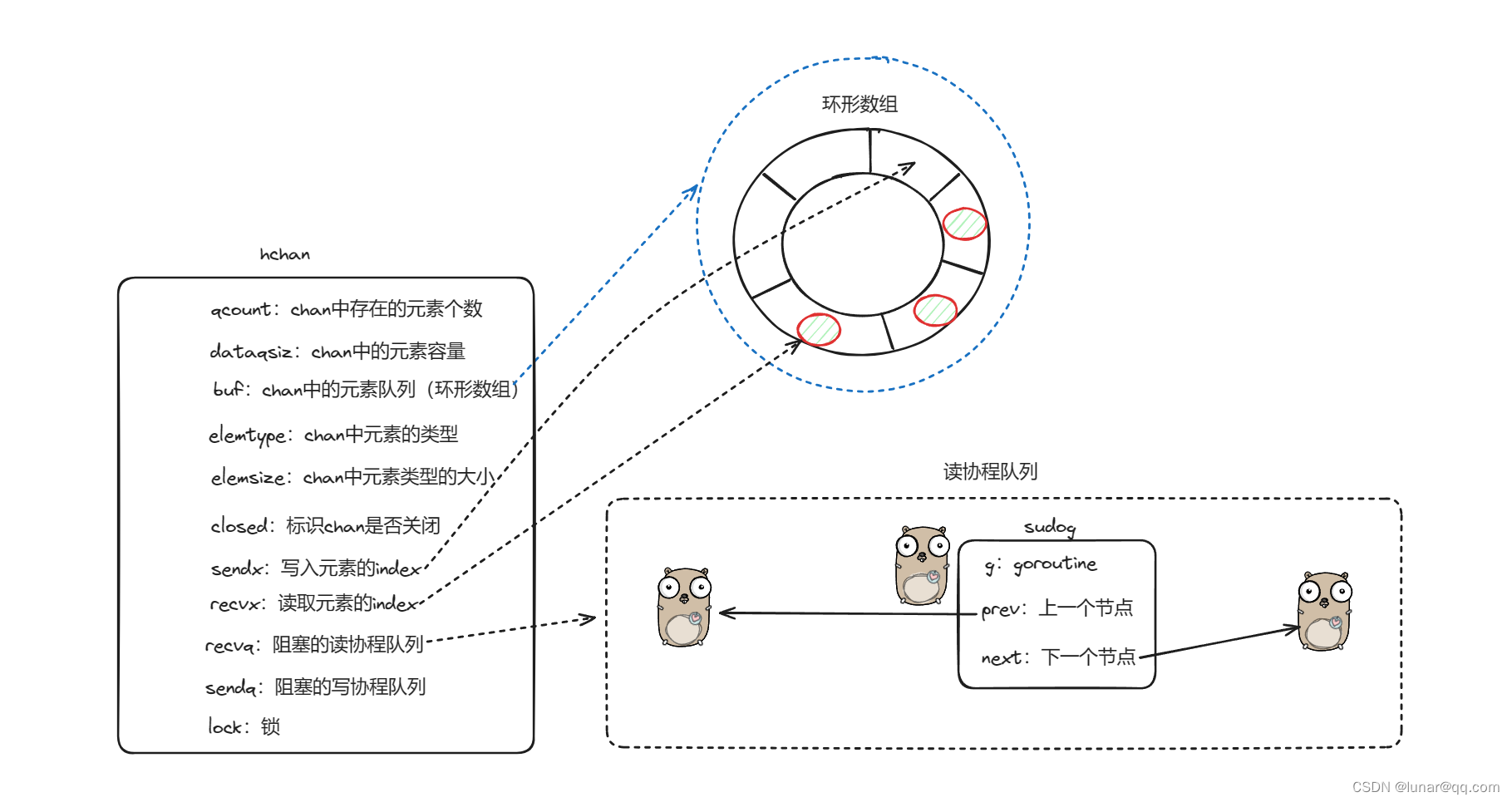
有缓冲的channel使用ring buffer(环形缓冲区)来缓存写入的数据,本质是循环数组(为啥用循环数组?普通数组容量固定、更适合指定的空间,且弹出元素时,元素需要全部前移)
流程:
## 写数据
如果channel的读等队列存在接受者goroutine
将数据直接发送给第一个等待的goroutine,唤醒接收的goroutine
如果channel的读等队列不存在接受者goroutine
如果循环数组的buf未满,那么将数据发送到循环数组的队尾
如果循环数组的buf已满,将当前的goroutine加入写等待对列,并挂起等待唤醒接收
## 读数据
如果channel的写等待队列存在发送者goroutine
如果是无缓冲channel,直接从第一个发送者goroutine那里把数据拷贝给接收变量,唤醒发送的gorontine
如果是有缓冲channel(已满),将循环数组buf的队首元素拷贝给接受变量,将第一个发送者goroutine的数据拷贝到循环数组队尾,唤醒发送端goroutine
如果channel的写等待队列不存在发送者goroutine
如果循环数组buf非空,将循环数据buf的队首元素拷贝给接受变量
如果循环数组buf为空,这个时候就会走阻塞接收的流程,将当前goroutine加入读等队列,并挂起等待唤醒
## 相比较共享内存
共享内存访问需要加锁,若持锁失败,要么忙等重试,要么待会儿再来。
降低耦合:channel以消息传递通信,消息发出后就不用管了,除非它希望得到回馈,完全异步。
Map
原理:底层使用 hash table,每个 map 的底层结构是 hmap,是有若干个结构为 bmap(链表) 的 bucket 组成的数组。用链表来解决冲突 ,出现冲突时,不是每一个 key 都申请一个结构通过链表串起来,而是以 bmap 为最小粒度挂载,一个 bmap 可以放 8 个 kv。在哈希函数的选择上,会在程序启动时,检测 cpu 是否支持 aes,如果支持,则使用 aes hash,否则使用 memhash。
key 可以是很多种类型,比如 bool, 数字,string, 指针, channel ,,接口, 结构体, 数组,slice, map 还有 function 不可以,因为这几个没法用 == 来判断
声明是不会分配内存的,初始化需要 make ,分配内存后才能赋值和使用
map对象不是线程安全的,并发读写的时候运行时会有检查,遇到并发问题就会导致panic
## 内存回收
1. go 底层map 是由若干个bmap(桶)构成的,桶只会扩容,不会缩容 ,所以 map中占用的内存不会被释放
以上只针对值类型的数据结构 例如:基本类型 int string slice struct 等
2. 如果key为 指针变量 删除后这个指针变量内存不会释放,但是这个指针指向的对象,引用计数会 -1 如果引用计数为0 在gc的时候就会被释放!
## 元素有序性
map 因扩张⽽重新哈希时,各键值项存储位置都可能会发生改变,顺序自然也没法保证了,所以官方避免大家依赖顺序,直接打乱处理,每次遍历,得到的输出 可能不一样。
for range map 在开始处理循环逻辑的时候,就做了随机播种(要想有序遍历,可以先将 key 进行排序,然后根据 key 值遍历)
## 线程安全
map对象不是线程安全的,并发读写的时候运行时会有检查,遇到并发问题就会导致panic
解决方法:使用sync.Map、使用读写锁
结构体
type Person struct {
Name string `json:name-field`
Age int
}
- 结构体指针访问字段的标准方式应该是:(*结构体指针).字段名 ,但 go 做了一个简化,也支持 结构体指针.字段名, 更加符合程序员使用的习惯,go 编译器底层 对 person.Name 做了转化 (*person).Name。
- 结构体的所有字段在内存中是连续的
- 结构体进行 type 重新定义(相当于取别名),Golang 认为是新的数据类型,但是相互间可以强转(和其它类型进行转换时需要有完全相同的字段(名字、个数和类型)
- struct 的每个字段上,可以写上一个 tag, 该 tag 可以通过反射机制获取,常见的使用场景就是序
列化和反序列化。
函数与方法
//函数
func getArea(R int) float64 {
return math.Pi * math.Pow(R, 2)
}
//方法
func (c Circle)getArea() float64 {
return math.Pi * math.Pow(c.R, 2)
}
方法的调用和传参机制和函数基本一样,不一样的地方是方法调用时,会将调用方法的变量,当做实参也传递给方法,体现了封装性。函数则是无状态的代码块。
Go 的函数参数传递都是值传递:调用函数时将实际参数复制一份传递到函数中,这样在函数中如果对参数进行修改,将不会影响到实际参数。
对象
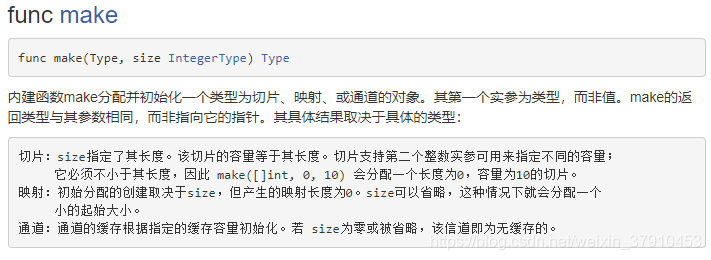
make和new
1)作用变量类型不同,new给string,int和数组分配内存,make给切片,map,channel分配内存;2)返回类型不一样,new返回指向变量的指针,make返回变量本身;3)new 分配的空间被清零。make 分配空间后,会进行初始化;
继承
type Person struct {
id int
name string
age int
}
type Student struct {
Person
id int
score int
className string
}
- 使用匿名属性,来实现继承:即将父类作为子类的匿名属性
- 如果父类和子类中有重复字段,则优先使用子类自身的属性
- 方法的重写(方法名,参数,返回值类型都必须一样)此时调用方法绑定的对象不在时父类而是子类本身
接口
- 空接口
// fmt包中的方法 Println底层
func Println(a ...interface{}) (n int, err error) {
return Fprintln(os.Stdout, a...)
}
// 接纳任意对象
var i interface{} = 45
i=[...]int{1,2,3}
可以接纳任意对象,类似java中的Object
- 接口
可以定义一些通用的方法,将被继承和实现的接口以匿名属性传入即可,但不必将所有的方法都实现
type annimal interface {
eat()
sleep()
run()
}
type cat interface {
annimal
Climb()
}
- 多态
可以在调用方法时会因传入对象的不同而得到不同的效果
// 使用 对象.(指定的类型) 判断改对象是否时指定的类型
if data,ok :=v.(cat);ok{
data.eat()
fmt.Println("this is HelloKitty : ")
}
实现接口中的方法可以通过指针和结构体绑定
type animal interface {
eat()
}
type Dog struct {
Name string
Age int
}
//func (d Dog) eat() { 结构体绑定
//}
func (d *Dog) eat() { 指针绑定
}
func main() {
var a animal
dPoint := &Dog{
Name: "susan",
Age: 12,
}
dStruct := Dog{
Name: "susan",
Age: 12,
}
a = dPoint
// 使用指针接收者实现接口不能存结构体类型变量
// a = dStruct
}
区别:使用值接受者实现接口,结构体类型和结构体指针类型的变量都能存,指针接收者实现接口只能存指针类型的变量
异常
- 编译时异常:在编译时抛出的异常,编译不通过,语法使用错误,符号填写错误等等。。。
- 运行时异常:在程序运行时抛出的异常,这个才是我们将要说的,程序运行时,有很多状况发生,例如:让用户输入一个数字,可用户偏偏输入一个字符串,导致的异常,数组的下标越界,空指针等等。。。。
编译时异常很容易找到,而运行时异常不容易提前发现,通过if err != nil判断,但是依然会漏掉很多异常,因此我们需要在运行过程中动态的捕获异常
defer和recover
defer:延时执行,即在方法执行结束(出现异常而结束或正常结束)时执行
recover:恢复的意思,如果是异常结束程序不会中断,返回异常信息,可以根据异常来做出相应的处理
recover必须放在defer的函数中才能生效
func test(a int, b int) int {
defer func() {
err := recover()
fmt.Println("err:",err)
}()
a = b / a
return a
}
func main() {
i := test(0, 1)
fmt.Println("====main方法正常结束!!====",i)
}
//结果:
err: runtime error: integer divide by zero
====main方法正常结束!!==== 0
手动抛出异常——panic
有些异常是不应该恢复的,应该抛出异常,可以让这个异常一层层的返回给调用方的程序,使其不能继续执行,从而起到保护后面业务的目的
func test(a int) int {
i:=100 - a
if i<0{
panic(errors.New("账户金额不足!!!!"))
}
fmt.Println("=======账户扣款=====")
return i
}