目标检测:2如何生成自己的数据集
目录
1. 数据采集
2. 图像标注
3. 开源已标记数据集
4. 数据集划分
参考:
1. 数据采集
数据采集是深度学习和人工智能任务中至关重要的一步,它为模型提供了必要的训练样本和测试数据。在实际应用中,数据采集的方法多种多样,每种方法都有其独特的优势和适用场景。本次将介绍如何标记数据集、
一、什么是数据标注?
数据标注即通过分类、画框、标注、注释等,对图片、语 音、文本、视频等数据进行处理,标记对象的特征,以作为机器学习基础 素材的过程。机器学习需要反复学习以训练模型和提高精度,同时自动驾驶、语言大模型、AI医疗、等各大应用场景都需要标注数据。
二、数据标注的分类
对于数据标注,按照不同的分类标准,可以有不同划分。以标注对象作为分类基础,可将数据标注划分为图像标注、语音标注、文本标注以及视频标注。
2. 图像标注
图像标注是一个将标签添加到图像上的过程。图像标注类型包括拉框、语义分割、实例分割、 目标检测、图像分类、关键点、线段标注、文字识别转写、点云标注、属性判断等。图像标注在人工智能与各行各业应用相结合的研究过程中扮演着重要的角色:通过对路况图片中的汽车和行人进行筛选、分类、标框, 可以提高安防摄像头以及无人驾驶系统的识别能力。
- 通过
LabelImg来标注矩形框; - 通过
LabelMe来进行多边形框的标定; - 通过
PPOCRLabel来完成文本识别标注任务; - 通过
roLabelImg来解决旋转目标检测的功能; - 通过
DarkLabel来完成视频文件的标注及对象的跟踪功能; - 通过
ELAN完成对视频序列中人物动作的识别以及对应字幕的捕捉;
简单的使用,在线标注数据集的工具Make Sense。
开始标注
打开Make Sense点击Get Start即可开始标注。
进入下一个页面,点击Drop images并选中所有数据集。
点击 Object Detection ,并添加标签,笔者这里以安全帽为例,所以创建标签Helmet。然后手动画出安全帽对应的矩形。

标注完成后,点击Action->Export Annotation,即可导出Yolo格式的标签。
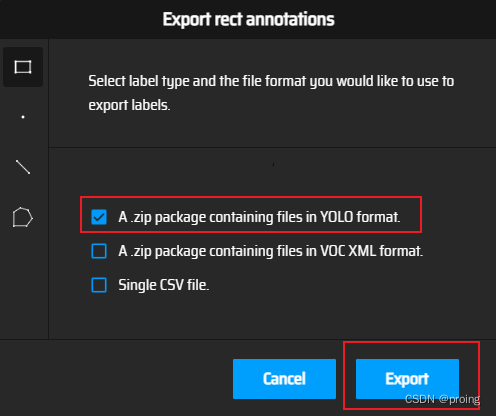
导出的文件如下所示
 、
、
<object-class> <x> <y> <width> <height>
其中,object-class为类别,x,y,width和height是指目标的中心点坐标及宽高信息。
3. 开源已标记数据集
使用开源数据集是一种常见且有效的数据采集方法。开源数据集通常已经过标记和验证,可大大节省数据采集和标注的时间和资源成本。例如ImageNet数据集,包含超过1400万张图像,可用于深度学习模型训练。此外,还有像Coco、DOTA数据集等,笔者在这里为大家整理了常见的深度学习开源数据集地址,具体如下,以供参考。
coco数据集:https://cocodataset.org
Pascal Voc数据集:https://pjreddie.com/projects/pascal-voc-dataset-mirror/
猫咪数据集:http://m6z.cn/5TAgbw
宠物图像数据集:http://m6z.cn/5TAgdC
HMDB人类动作识别数据集:http://m6z.cn/6gGlzF
KITTI道路数据集:http://m6z.cn/5xz4OW
MPII人体模型数据集:http://m6z.cn/69aaIe
天池铝型材表面缺陷数据集:http://m6z.cn/61EksR
防护装备-头盔和背心检测:http://m6z.cn/61zarT
Linkopings交通标志数据集:http://m6z.cn/68ldS0
RMFD口罩遮挡人脸数据集:http://m6z.cn/61z9Fv
生活垃圾数据集:http://m6z.cn/6n5Adu
火焰和烟雾图像数据集:http://m6z.cn/6fzn0f
MTFL人脸识别数据集:http://m6z.cn/6fHmaT
4. 数据集划分
有了数据集之后,对齐划分,分别分为train,val,test三块。
创建helmet_dataset/images保存图像文件,创建helmet_dataset/labels保存标记文件。
分割脚本如下:
import os
import shutil
import zipfile
from sklearn.model_selection import train_test_split
# 定义目录路径
dataset_directory = r'helmet_dataset'
images_directory = os.path.join(dataset_directory, 'images')
labels_directory = os.path.join(dataset_directory, 'labels')
# 定义备份 zip 文件路径
backup_zip_path = os.path.join(dataset_directory, 'helmet_dataset.zip')
# 将整个数据集目录压缩备份
with zipfile.ZipFile(backup_zip_path, 'w') as backup_zip:
for folder in [images_directory, labels_directory]:
for root, dirs, files in os.walk(folder):
for file in files:
file_path = os.path.join(root, file)
backup_zip.write(file_path, os.path.relpath(file_path, dataset_directory))
# 所有图像文件名(不带扩展名)的列表
image_filenames = [os.path.splitext(filename)[0] for filename in os.listdir(images_directory) if filename.endswith('.jpg')]
# 定义拆分比例
train_ratio = 0.7
validation_ratio = 0.2
test_ratio = 0.1
# 执行拆分
train_filenames, test_filenames = train_test_split(image_filenames, test_size=1 - train_ratio)
validation_filenames, test_filenames = train_test_split(test_filenames, test_size=test_ratio/(test_ratio + validation_ratio))
# 创建目录并移动文件的函数
def create_and_move_files(file_list, source_folder, destination_folder, file_extension):
os.makedirs(destination_folder, exist_ok=True)
for filename in file_list:
shutil.move(os.path.join(source_folder, filename + file_extension),
os.path.join(destination_folder, filename + file_extension))
# 为每个集创建目录并移动文件
sets_directories = {
'train': os.path.join(dataset_directory, 'train'),
'val': os.path.join(dataset_directory, 'val'),
'test': os.path.join(dataset_directory, 'test')
}
for set_name, file_list in zip(['train', 'val', 'test'], [train_filenames, validation_filenames, test_filenames]):
images_set_directory = os.path.join(sets_directories[set_name], 'images')
labels_set_directory = os.path.join(sets_directories[set_name], 'labels')
create_and_move_files(file_list, images_directory, images_set_directory, '.jpg')
create_and_move_files(file_list, labels_directory, labels_set_directory, '.txt')
# 删除空的images和labels文件夹
for folder in [images_directory, labels_directory]:
if os.path.exists(folder) and not os.listdir(folder):
os.rmdir(folder)
# 返回备份文件路径和已创建目录的路径
print(backup_zip_path, sets_directories)
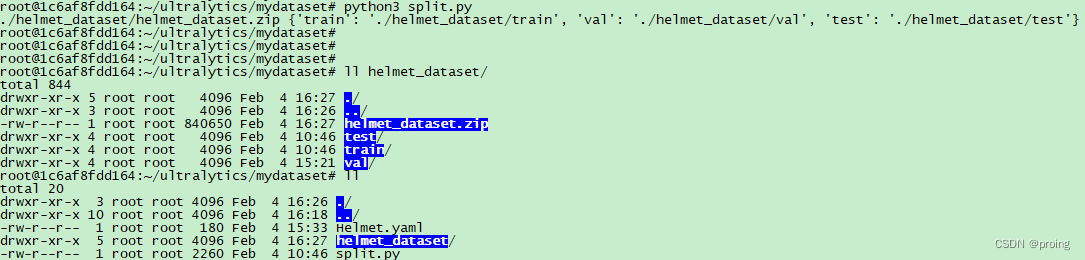
创建好的数据集,留待使用,下一次学习如何利用数据集训练。
参考:
目标检测:1预备知识