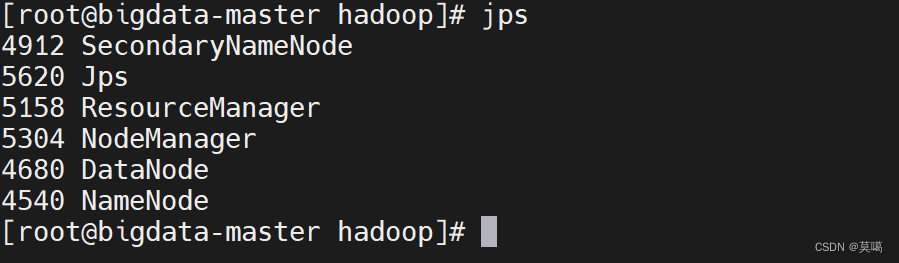
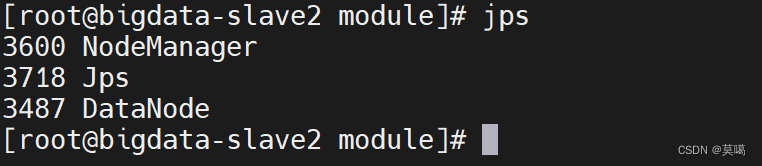
Hadoop搭建(完全分布式)
节点分布:
| bigdata-master | bigdata-slave1 | bigdata-salve2 |
|
|
|
|
SecondaryNameNode | DataNode | DataNode |
ResourceManager | ||
NodeManager | ||
DataNode |
目录
一、jdk安装:
二、hadoop安装
一、jdk安装:
jdk-8u212链接:https://pan.baidu.com/s/1avN5VPdswFlMZQNeXReAHg
提取码:50w6
1.解压
[root@bigdata-master software]# tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
2.环境变量
vim /etc/profile添加如下配置
```
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
```
:wq保存退出
使配置生效
source /etc/profile3.查看版本
java -version

4.免密登录(三台都执行)一定要弄的
ssh-keygen -t rsa其中会让输入密码等操作,直接不输入,按enter键
会在/root/.ssh产生id_rsa和id_rsa.pub文件
cd /root/.sshcat id_rsa.pub >>authorized_keys将其他节点的id_rsa.pub内容添加到本节点的authorized_keys文件中(每个节点需要执行)
二、hadoop安装
hadoop-3.1.3链接:https://pan.baidu.com/s/11yFkirCiT6tdo_9i1jWwkw
提取码:stgv
1.解压
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
2.配置文件
cd /opt/module/hadoop-3.1.3/etc/hadoop/(1). core-site.xml
vim core-site.xml<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/module/hadoop-3.1.3/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata-master:9000</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<description>对root用户不进行限制</description>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
<description>对root群组不限制</description>
</property>
</configuration>
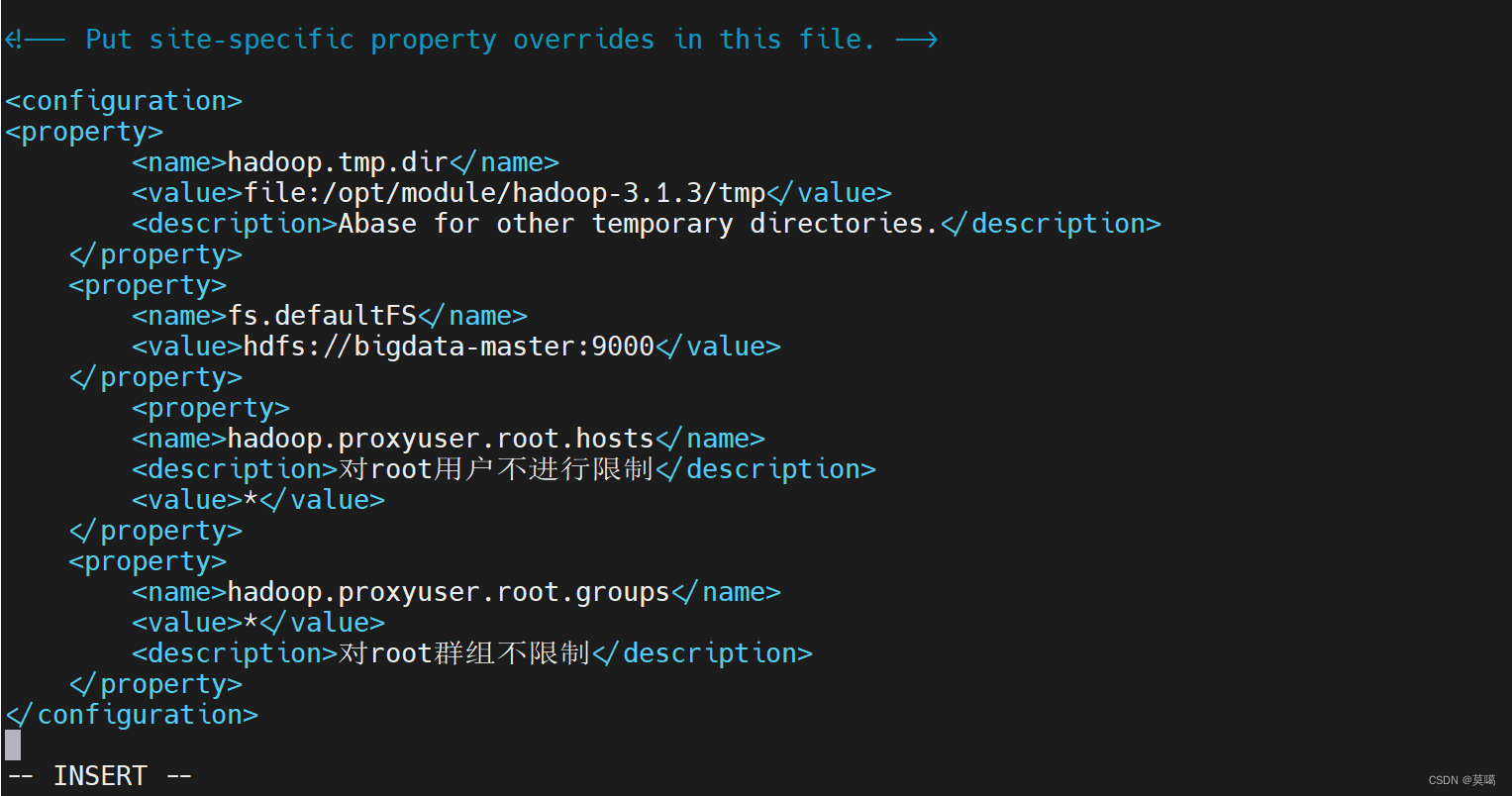 保存退出(:wq)
保存退出(:wq)
(2). hdfs-site.xml
vim hdfs-site.xml<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/module/hadoop-3.1.3/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/module/hadoop-3.1.3/tmp/dfs/data</value>
</property>
</configuration> 保存退出(:wq)
保存退出(:wq)
(3). mapred-site.xml
vim mapred-site.xml<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>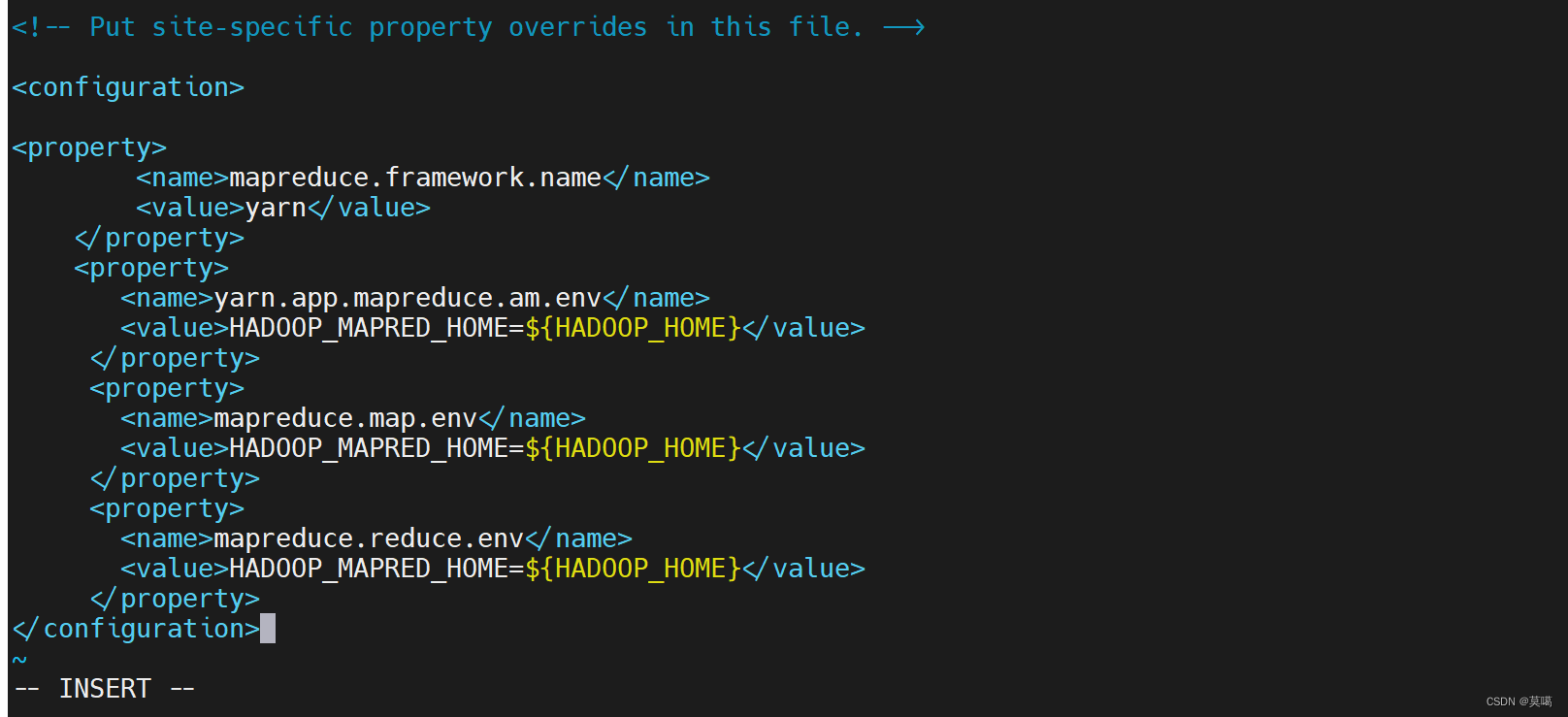
保存退出(:wq)
(4). yarn-site.xml
vim yarn-site.xml<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata-master</value>
</property>
</configuration>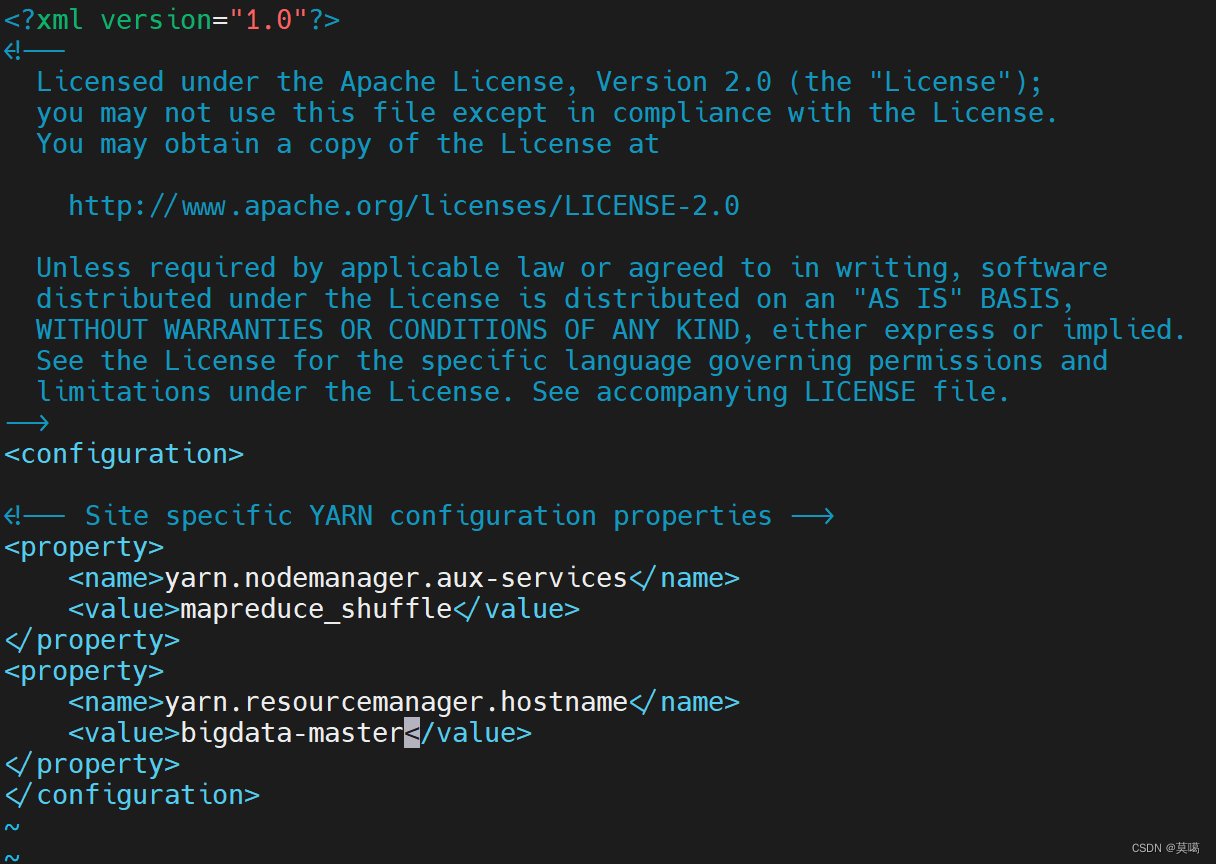
保存退出(:wq)
(5).yarn-env,sh
vim yarn-env.shexport JAVA_HOME=/opt/module/jdk1.8.0_212
(6).workers
vim workersbigdata-master
bigdata-slave1
bigdata-slave2 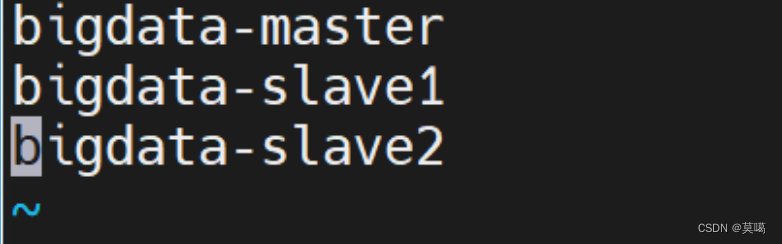
(7).
修改 /opt/module/hadoop-3.1.3/sbin/start-dfs.sh和 /opt/module/hadoop-3.1.3/sbin/stop-dfs.sh
vim /opt/module/hadoop-3.1.3/sbin/start-dfs.shHDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root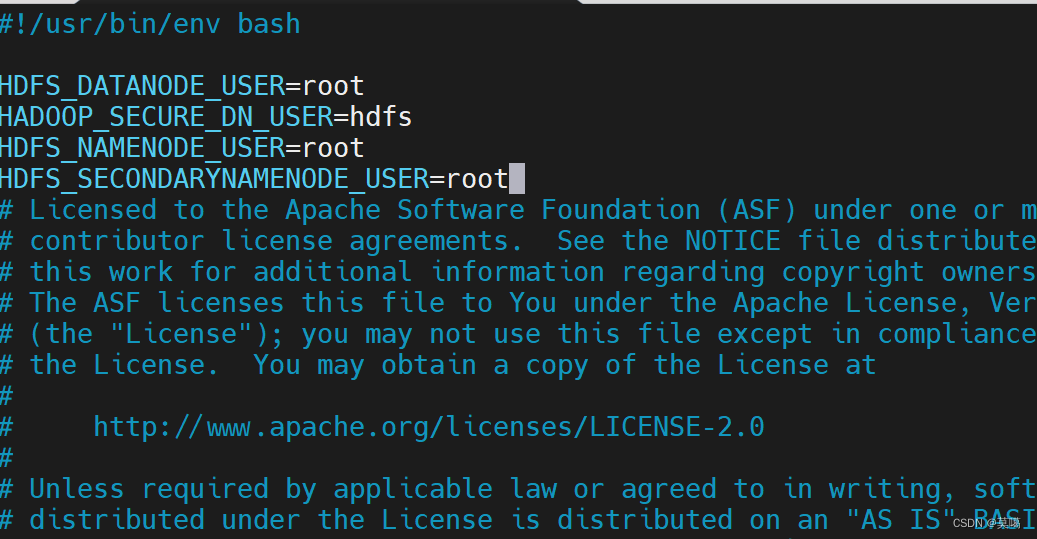
/opt/module/hadoop-3.1.3/sbin/stop-dfs.shHDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root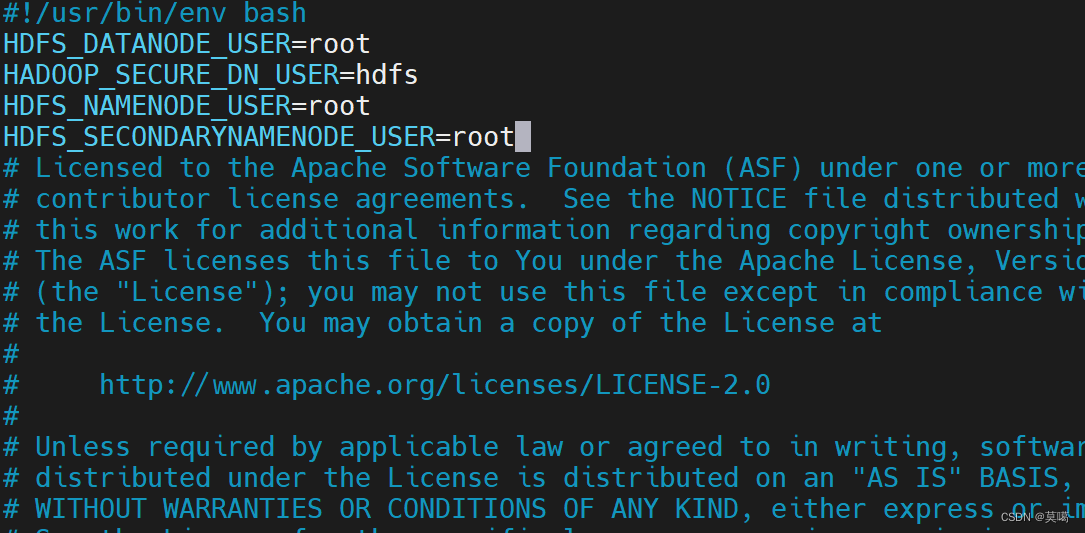
(8).
修改 /opt/module/hadoop-3.1.3/sbin/start-yarn.sh和 /opt/module/hadoop-3.1.3/sbin/stop-yarn.sh
vim /opt/module/hadoop-3.1.3/sbin/start-yarn.shYARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root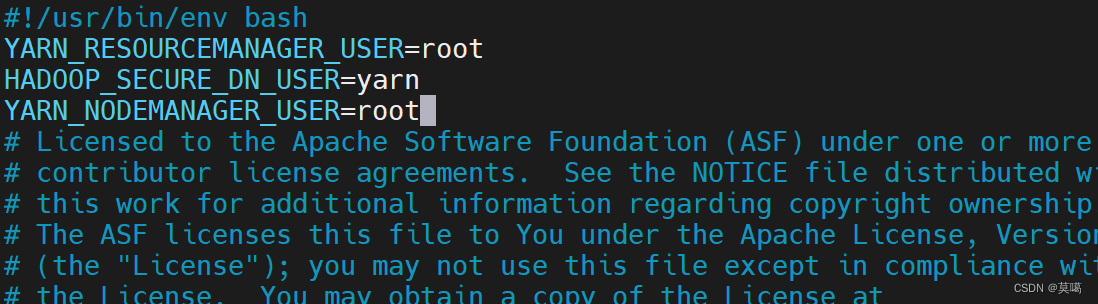
vim /opt/module/hadoop-3.1.3/sbin/stop-yarn.shYARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root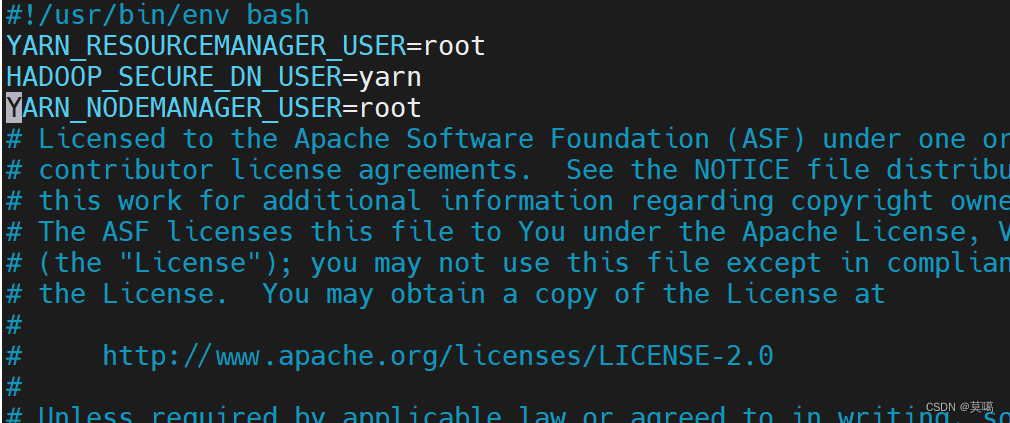
3.环境变量
vim /etc/profile#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin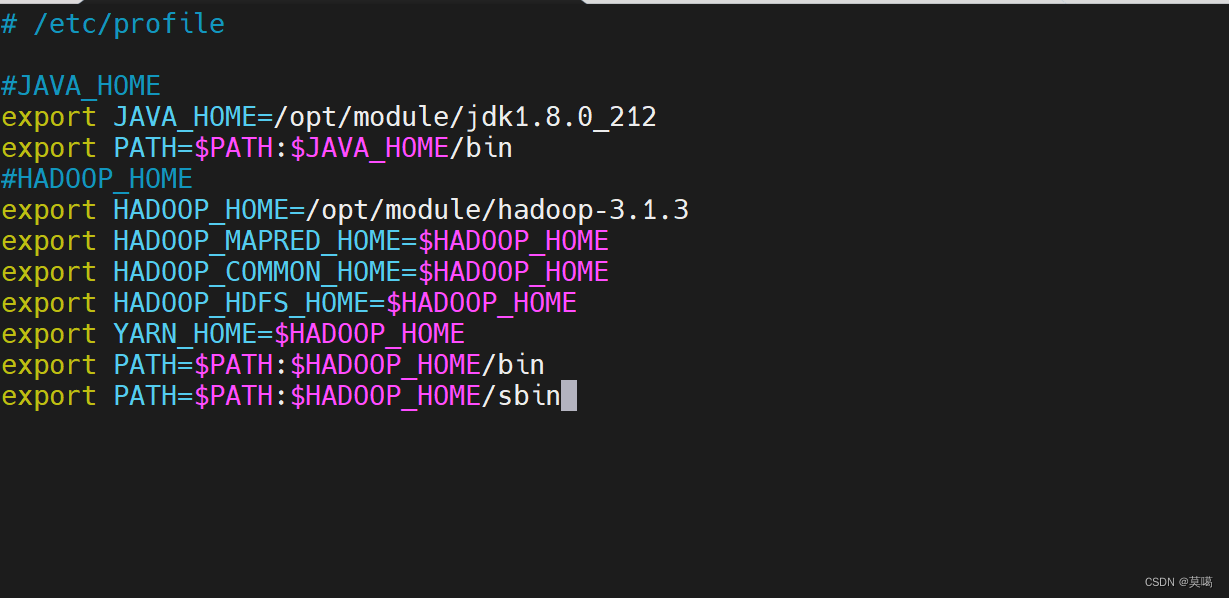
使变量生效
source /etc/profile4.分发(或者自己手配以上步骤给另外两台)

分发hadoop和jdk
[root@bigdata-master hadoop]# scp -r /opt/module/ root@bigdata-slave1:/opt/module
[root@bigdata-master hadoop]# scp -r /opt/module/ root@bigdata-slave2:/opt/module
配置另外两台的环境变量 并使变量生效
source /etc/profile5.Hdfs格式化(bigdata-master)
不要多次格式化
hdfs namenode -format
6.启动hadoop
start-all.sh
jps查看进程: