Spark安装(Yarn模式)
一、解压
链接:https://pan.baidu.com/s/1O8u1SEuLOQv2Yietea_Uxg
提取码:mb4h
tar -zxvf /opt/software/spark-3.0.3-bin-hadoop3.2.tgz -C /opt/module/spark-yarnmv spark-3.0.3-bin-hadoop3.2/ spark-yarn二、配置环境变量
vim /etc/profile#SPARK_HOME
export SPARK_HOME=/opt/module/spark-yarn
export PATH=$PATH:$SPARK_HOME/bin使变量生效
source /etc/profile
三、配置文件
vim /opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
四、 分发刚刚修改的配置文件
scp /opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml bigdata-slave1:/opt/module/hadoop-3.1.3/etc/hadoop/scp /opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml bigdata-slave2:/opt/module/hadoop-3.1.3/etc/hadoop/五、修改spark-env.sh
cd /opt/module/spark-yarn/conf/[root@bigdata-master conf]# mv spark-env.sh.template spark-env.sh
[root@bigdata-master conf]# vim spark-env.sh
YARN_CONF_DIR=/opt/module/hadoop-3.1.3/etc/hadoop六、启动hadoop
start-all.sh
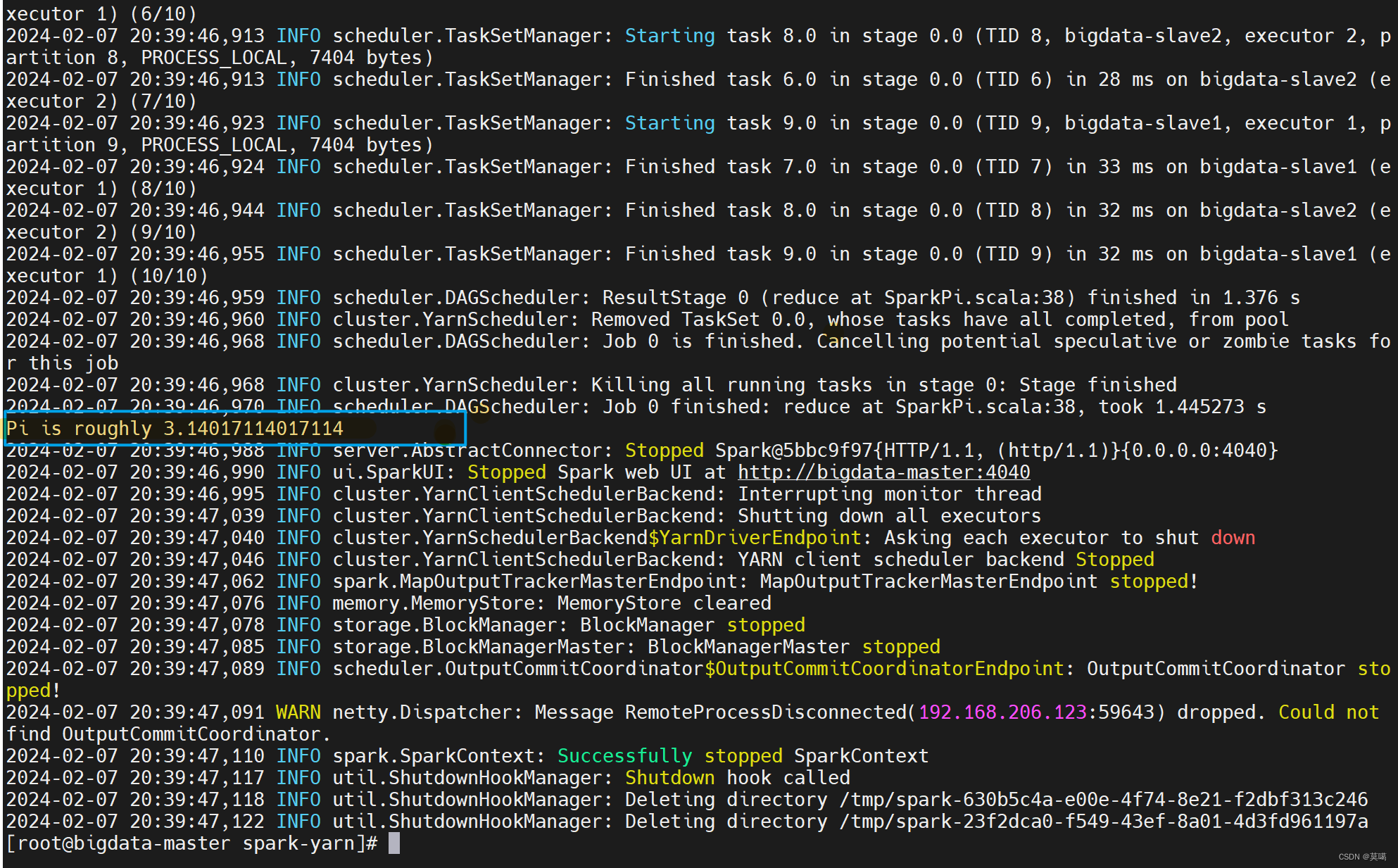
七、求PI
spark-submit --class org.apache.spark.examples.SparkPi --master yarn ./examples/jars/spark-examples_2.12-3.0.3.jar 10