Go 语言中如何大小端字节序?int 转 byte 是如何进行的?

嗨,大家好!我是波罗学。
本文是系列文章 Go 技巧第十五篇,系列文章查看:Go 语言技巧。
我们先看这样一个问题:“Go 语言中,将 byte 转换为 int 时是否涉及字节序(endianness)?我可以直接使用 int(byte_var) 进行转换吗?”
这个问题非常简单,直接回答不涉及字节序,可以直接转换。但为什么呢?如果要彻底搞明白这个问题,还是要了解下字节序这个概念。
接下来,让我带你深入地了解这个问题,以及如何在 Go 中如何处理字节序。
字节序
我们先解释一下什么是字节序?
字节序,或称为字节顺序,即数据在内存中存储的字节顺序。字节序主要有两种:大端和小端。
什么是大端模式?

大端模式指的是高位字节(0x12)存储在低地址位(0)。
什么是小端模式?

小端模式指的是低位字节(0x78)存储在低地址位(0)。
将 byte 和 int 相互转换
首先,int 如何转为 byte?
在 Go 中,byte 是 int8 的别名,占用一个字节。由于它只有一个字节,自然不存在字节序的说法。
var byteVar byte = 0x78
intVar := int(byteVar)
我们将一个 byte 变量转换为 int 类型,byte 只占用一个字节,所以没有字节序的问题。当然,一定要说有字节序,也可以。毕竟,将 byte 转为 int 时,其实是将 byte 数值存在 int 低位,而不是高位。

那么,将 int 转换为 byte 呢?当从 int 类型转换为 byte 时,字节序变得重要了。

从 int 转为 byte 时,将会截断 int 数据,将最低位的数值作为 byte 的值。
那么,如果我们想判断自己电脑上的字节序,只要将 int 转为 byte,即可判断。
示例代码,如下所示:
package main
import (
"fmt"
)
func main() {
s := int32(0x12345678)
b := byte(s)
fmt.Printf("0x%x\n", b)
}
输出:
0x78
我的电脑上的输出结果为 0x78,它是低位的值,即低位存放于低地址。这表明我的机器是小端模式。
网络传输与 Go 的 encoding/binary 包
在网络传输中,字节序至关重要。通常,网络协议要求使用大端字节序。当在不同字节序的系统之间通信时,正确处理字节序至关重要。
Go 的 encoding/binary 包提供了处理字节序的便利工具。它定义了一个 ByteOrder 接口,包括各种转换函数。
它的使用非常简单,代码如下:
package main
import (
"encoding/binary"
"fmt"
)
func main() {
bytes := []byte{0x78, 0x56, 0x34, 0x12}
fmt.Printf(
"LittleEndian: 0x%x\n",
binary.LittleEndian.Uint32(bytes),
)
fmt.Printf(
"BigEndian: 0x%x\n",
binary.BigEndian.Uint32(bytes),
)
}
我们使用 binary.LittleEndian 和 binary.BigEndian 完成小端和大端字节向 uint32 的转换。
输出:
LittleEndian: 0x12345678
BigEndian: 0x78563412
小端模式下,结果是 0x12345678,在大端模式下,是 0x78563412。这个例子演示了 Go 如何使用小端和大端模式将字节数组转换为 uint32 类型。
我们通过图示再看下这个转化的对应关系:
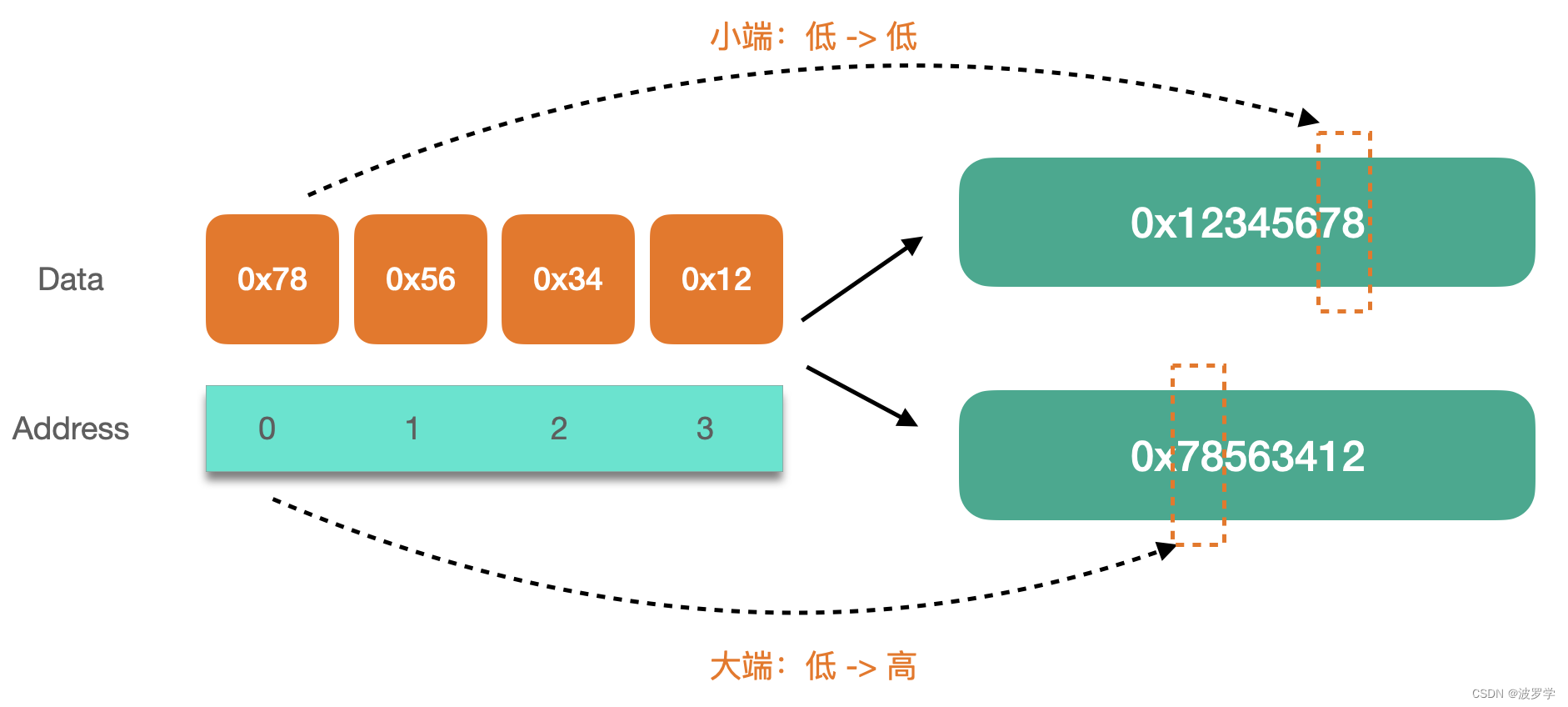
输出结果符合我们的预期。
结论
本文主要介绍字节序这个概念,还有如何在 Go 中进行正确的字节序处理。有兴趣可阅读 encoding/binary 包的源代码,以获得更深入的理解。
最后,希望这篇文章能对你有所帮助,如果你有任何问题,请随时提问。
博文地址:Go 语言中如何大小端字节序?int 转 byte 是如何进行的?