机器学习 | 深入集成学习的精髓及实战技巧挑战
目录
xgboost算法简介
泰坦尼克号乘客生存预测(实操)
lightGBM算法简介
《绝地求生》玩家排名预测(实操)
xgboost算法简介
XGBoost全名叫极端梯度提升树,XGBoost是集成学习方法的王牌,在Kaggle数据挖掘比赛中,大部分获胜者用了XGBoost。XGBoost在绝大多数的回归和分类问题上表现的十分顶尖,接下来将较详细的介绍XGBoost的算法原理。
最优模型构建方法:构建最优模型的一般方法是最小化训练数据的损失函数。用字母L表示损失:
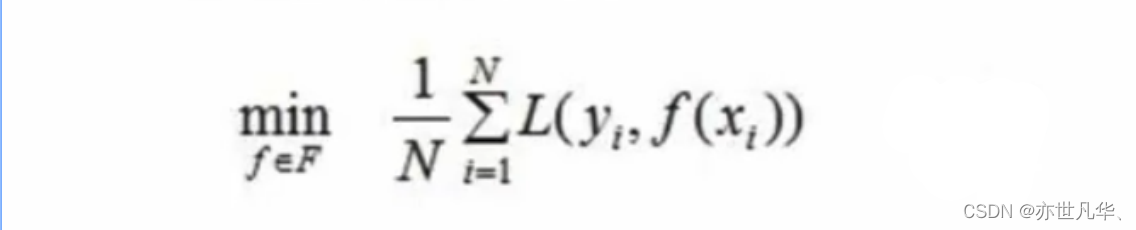
其中,F是假设空间,假设空间是在已知属性和属性可能取值的情况下,对所有可能满足目标的情况的一种毫无遗漏的假设集合。
上述公式称为经验风险最小化,训练得到的模型复杂度较高。当训练数据较小时,模型很容易出现过拟合问题。
为了降低模型的复杂度,常采用下式:
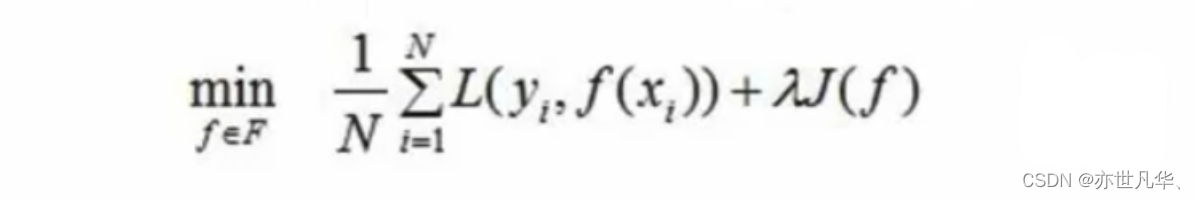
上述公式称为结构风险最小化,结构风险最小化的模型往往对训练数据以及未知的测试数据都有较好的预测。
目标函数:即损失函数,通过最小化损失函数来构建最优模型。由前面可知,损失函数应加上表示模型复杂度的正则项,且XGBoost对应的模型包含了多个CART树,因此,模型的目标函数为:

上述公式是正则化的损失函数,其中yi是模型的实际输出结果,yi^是模型的输出结果,等式右边第一部分是模型的训练误差,第二部分是正则化项,这里的正则化项是K棵树的正则化项相加而来的。
CART树的介绍:下图为第K棵CART树,确定一棵CART树需要确定两部分:
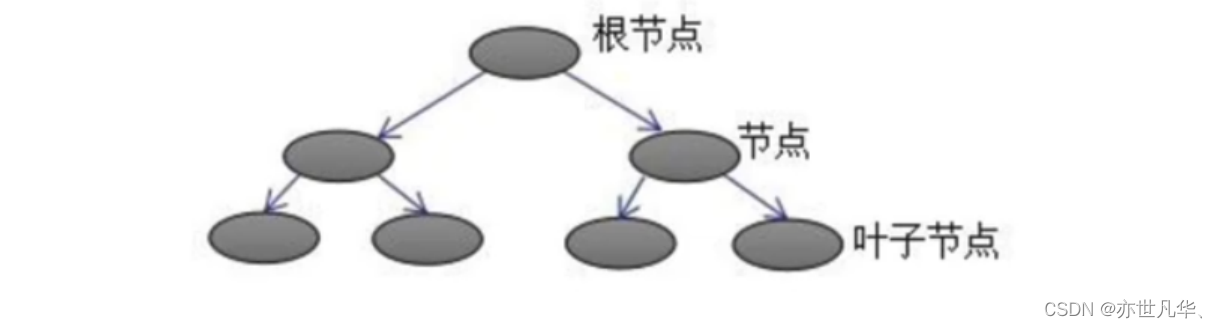
第一部分就是树的结构,这个结构将输入样本映射到一个确定的叶子节点上,记为fk(x);
第二部分就是各个叶子节点的值,q(x)表示输出的叶子节点序号,wq(x)表示对应叶子节点序号的值。由定义得:
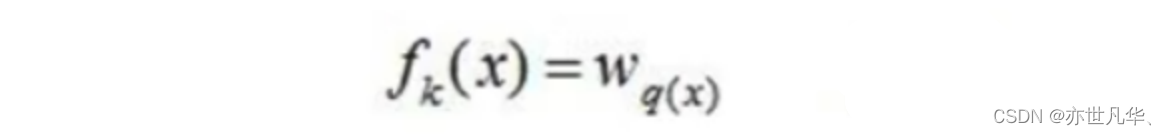
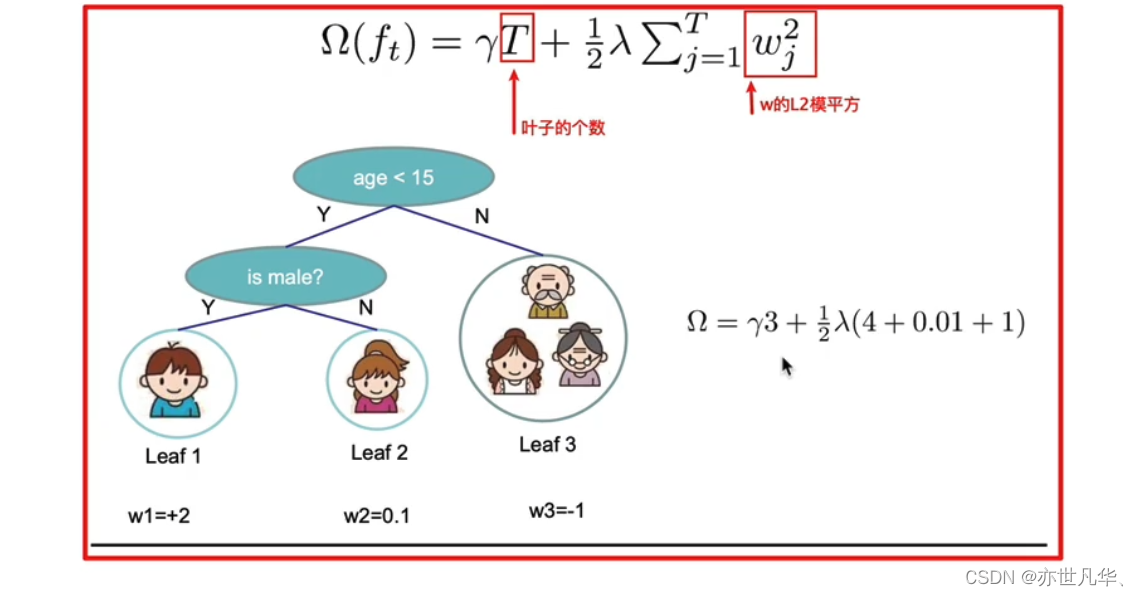
树的复杂度定义:XGBoost法对应的模型包含了多棵cart树,定义每棵树的复杂度:

树的复杂度举例:
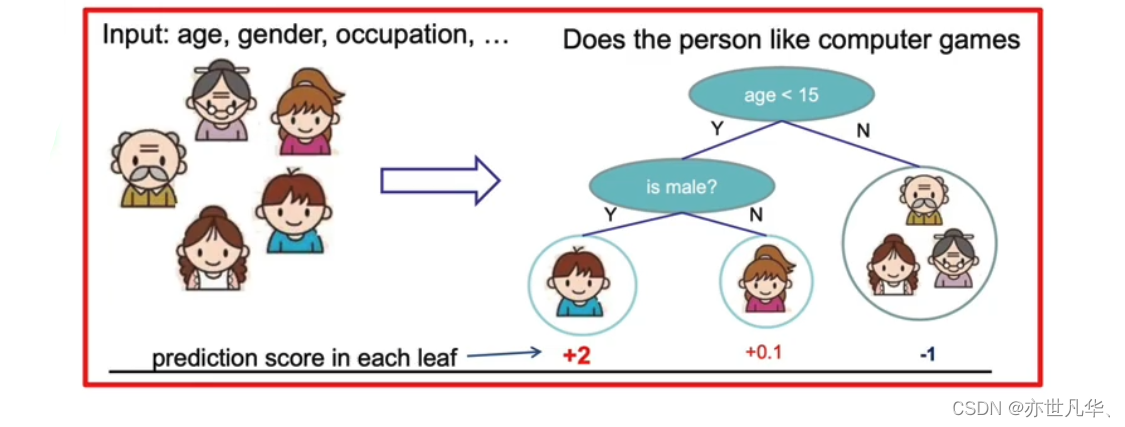
假设我们要预测一家人对电子游戏的喜好程度,考虑到年轻和年老相比,年轻更可能喜欢电子游戏,以及男性和女性相比,男性更喜欢电子游戏,故先根据年龄大小区分小孩和大人,然后再通过性别区分开是男是女,逐一给各人在电子游戏喜好程度上打分,如下图所示:
就这样,训练出了2棵树tree1和tree2,类似之前gbdt的原理,两棵树的结论累加起来便是最终的结论,所以:
1)小男孩的预测分数就是两棵树中小孩所落到的结点的分数相加:2+0.9=2.9。
2)爷爷的预测分数同理:-1+(-0.9)= -1.9。
具体如下图所示:

如下例树的复杂度表示:
如果想使用 xgboost 的话,需要终端执行如下命令进行安装:
pip install xgboost -i https://pypi.mirrors.ustc.edu.cn/simplexgboost虽然被称为kaggle比赛神奇,但是,我们要想训练出不错的模型,必须要给参数传递合适的值。 xgboost中封装了很多参数,主要由三种类型构成:通用参数(generalparameters),Booster参数(boosterparameters)和学习目标参数(taskparameters)
通用参数:主要是宏观函数控制

Booster参数:取决于选择的Booster类型,用于控制每一步的booster(tree,regressiong)



学习目标参数:控制训练目标的表现

泰坦尼克号乘客生存预测(实操)
泰坦尼克号沉没是历史上最臭名昭着的沉船之一。1912年4月15日,在她的处女航中,泰坦尼克号在与冰山相撞后沉没,在2224名乘客和机组人员中造成1502人死亡。这场耸人听闻的悲剧震惊了国际社会,并为船舶制定了更好的安全规定。造成海难失事的原因之一是乘客和机组人员没有足够的救生艇。尽管幸存下沉有一些运气因素,但有些人比其他人更容易生存,例如妇女,儿童和上流社会。在这个案例中,我们要求您完成对哪些人可能存活的分析。特别是,我们要求您运用机器学习工具来预测哪些乘客幸免于悲剧。
我们参考kaggle平台提供的案例:网址 :
我们提取到的数据集中的特征包括票的类别,是否存活,乘坐班次,年龄,登陆home.dest,房间,船和性别等。数据来自:数据集 :
经过观察数据得到:
1)坐班是指乘客班(1,2,3),是社会经济阶层的代表。
2)其中age数据存在缺失。

接下来我们借助 jupyter 工具进行构建我们这个预测,方便我们观察:
导入需要的模块:
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.tree import DecisionTreeClassifier获取数据:
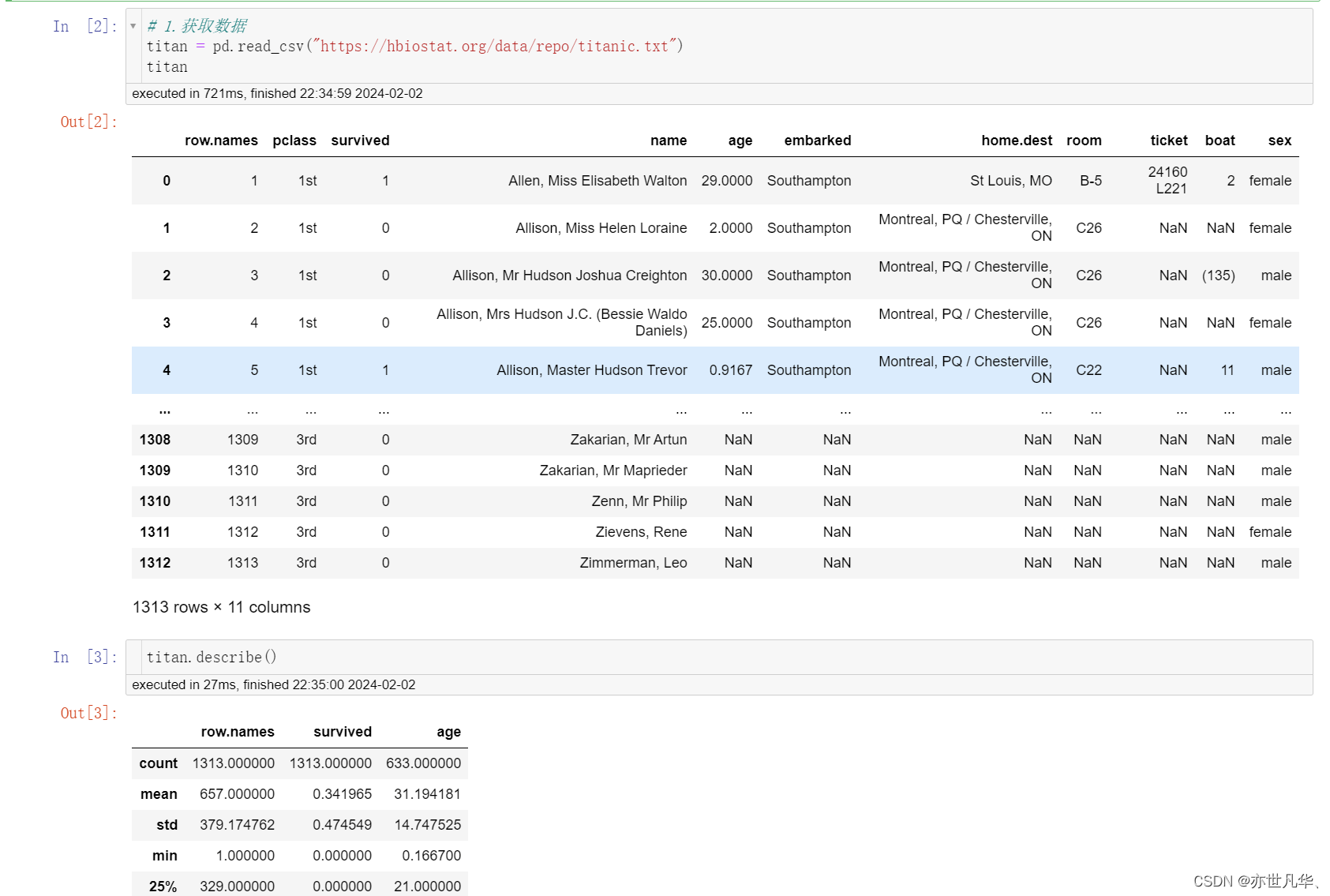
数据基本处理:
# 2.数据基本处理
# 2.1确定特征值,目标值
x = titan[["pclass", "age", "sex"]]
y = titan["survived"]
# 2.2缺失值处理
x["age"].fillna(value=titan["age"].mean(), inplace=True)
# 2.3数据集的划分
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22, train_size=0.2)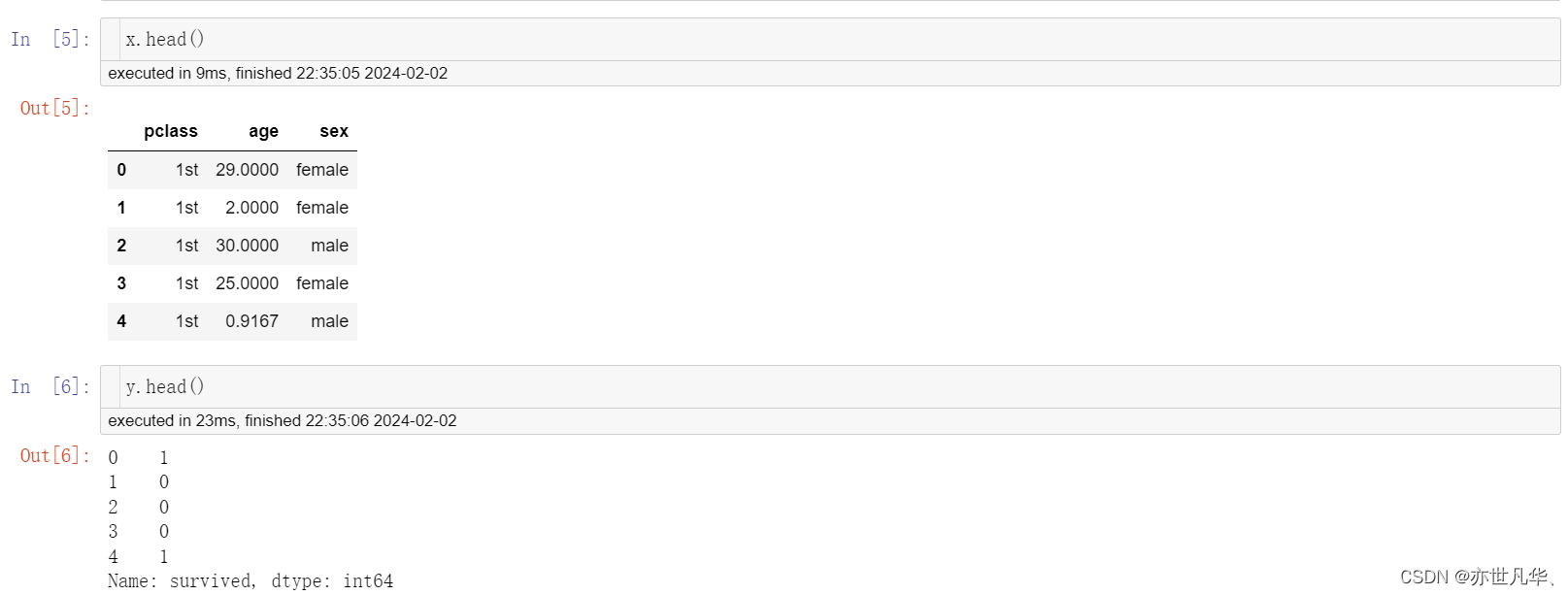
特征工程—字典特征抽取:特征出现类别符号需进行one-hot编码处理x.to_dict(orient="records")需要将数组特征转换成字典数据:
x_train = x_train.to_dict(orient="records")
x_test = x_test.to_dict(orient="records")
transfer = DictVectorizer()
x_train = transfer.fit_transform(x_train)
x_test = transfer.fit_transform(x_test)
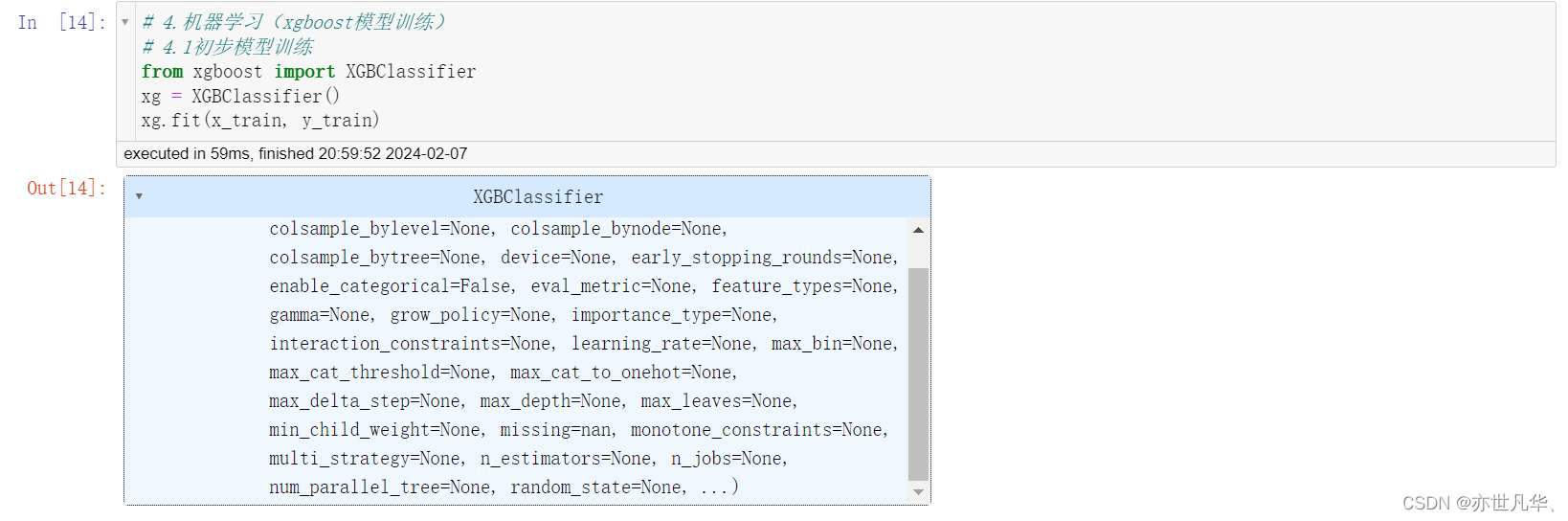
机器学习—xgboost模型训练:这段代码使用了 XGBoost 框架中的 XGBClassifier 类,用于构建一个基于 XGBoost 算法的分类模型。整个过程实现了一个监督学习的分类算法:
# 4.1初步模型训练
from xgboost import XGBClassifier
xg = XGBClassifier()
xg.fit(x_train, y_train)XGBoost 以其高效性、准确性和可拓展性等方面的优点而闻名,在很多数据科学任务中都被广泛使用:
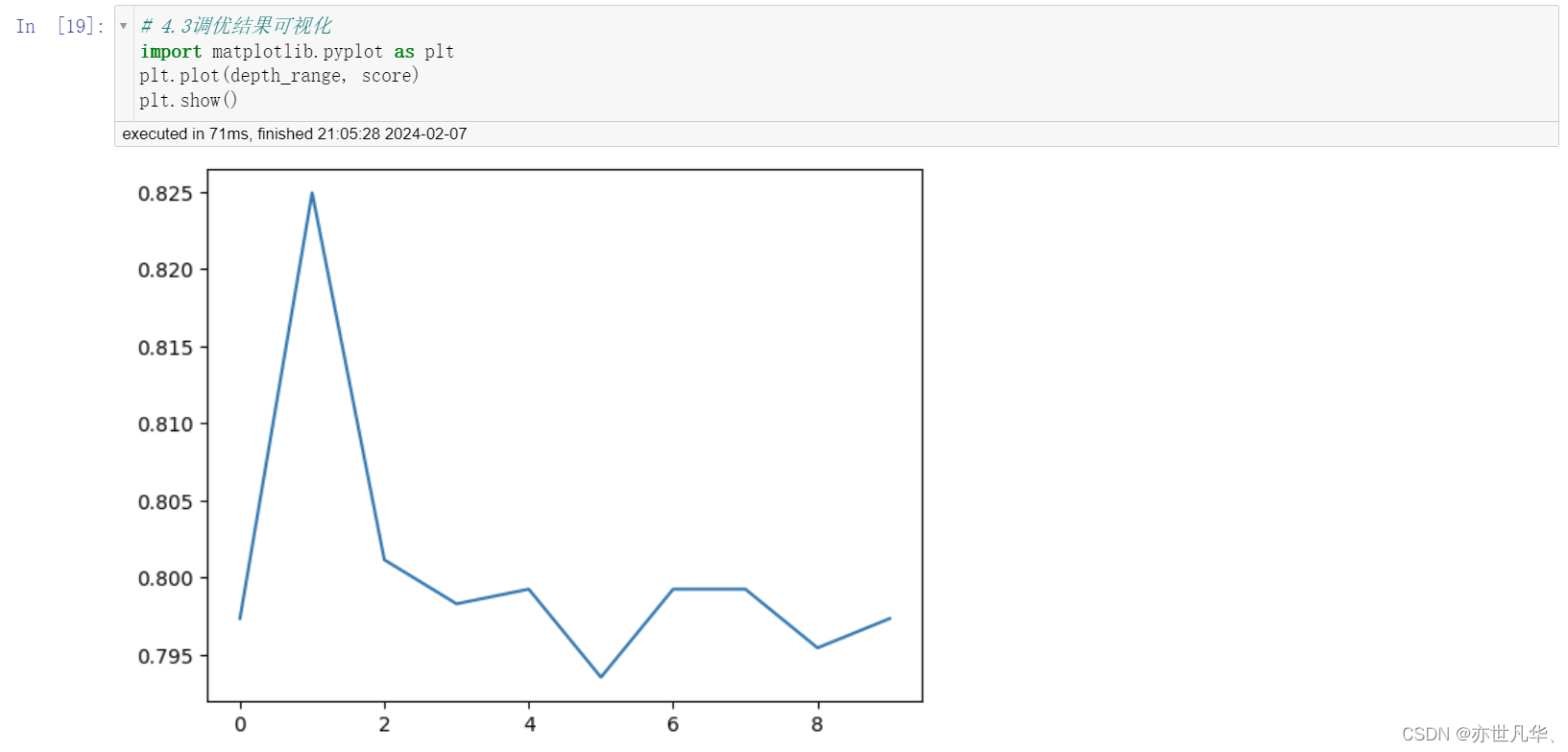
这段代码是在对 XGBoost 模型中的 max_depth 参数进行调优。max_depth 参数代表每棵树的最大深度,它控制了树的复杂度,过大的值可能会导致过拟合,而过小的值可能会导致欠拟合。为了找到最佳的 max_depth 值,代码使用了一个循环来尝试不同的深度值,并记录每个深度值对应的模型得分:
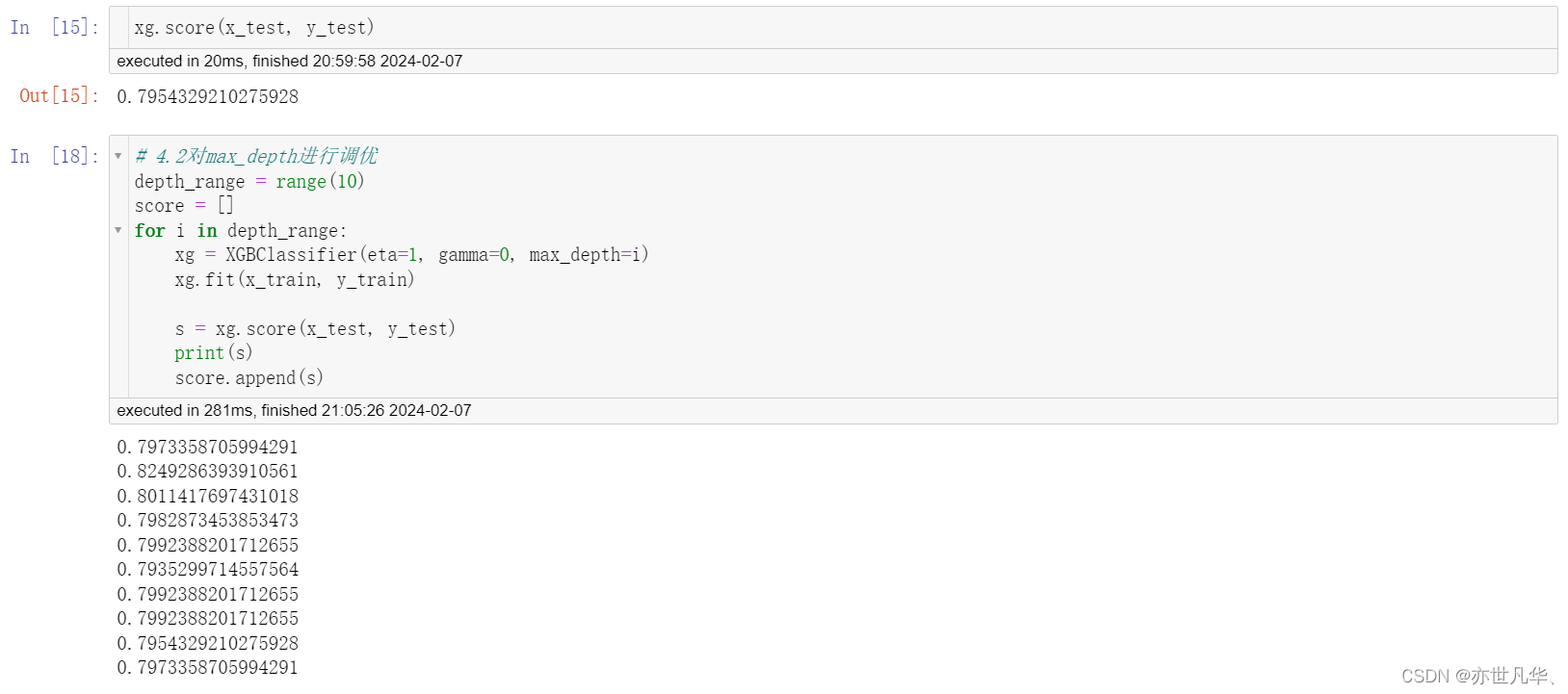
最后对所得的数据结果进行一个可视化展示:
lightGBM算法简介
LightGBM 是一种梯度提升框架中的基于决策树的机器学习算法。它是由微软研究院开发的,旨在提供高效、快速和准确的模型训练和预测。其演进过程如下:

AdaBoost算法:AdaBoost是一种提升树的方法,和三个臭皮匠,赛过诸葛亮的道理一样。特点:
改变训练数据的权重或概率分布,提高前一轮被弱分类器错误分类的样本的权重,降低前一轮被分对的权重;
将弱分类器组合成一个强分类,采取”多数表决”的方法.加大分类错误率小的弱分类器的权重,使其作用较大,而减小分类错误率大的弱分类器的权重,使其在表决中起较小的作用。
GBDT算法:GBDT和其它Boosting算法一样,通过将表现一般的几个模型(通常是深度固定的决策树)组合在一起来集成一个表现较好的模型。GradientBoosting通过负梯度来识别问题,通过计算负梯度来改进模型,即通过反复地选择一个指向负梯度方向的函数,该算法可被看做在函数空间里对目标函数进行优化。其缺点如下:
1)空间消耗大:样的算法需要保存数据的特征值,还保存了特征排序的结果(例如排序后的索引,为了后续快速的计算分割点),这里需要消耗训练数据两倍的内存。
2)时间上也有较大的开销:在遍历每一个分割点的时候,都需要进行分裂增益的计算,消耗的代价大。
3)对内存(cache)优化不友好:在预排序后,特征对梯度的访问是一种随机访问,并且不同的特征访问的顺序不一样,无法对cache进行优化;同时,在每一层长树的时候,需要随机访问一个行索引到叶子索引的数组,并且不同特征访问的顺序也不一样,也会造成较大的cache miss。
lightGBM原理:lightGBM主要基于以下方面优化,提升整体特特性:
基于Histogram(直方图)的决策树算法
基本思想是:先把连续的浮点特征值离散化成k个整数,同时构造一个宽度为k的直方图;在遍历数据的时候,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点:
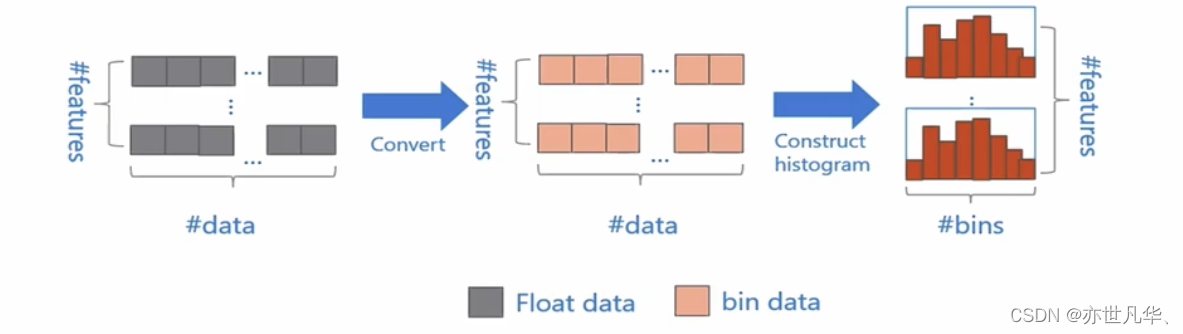
使用直方图算法有很多优点。首先,最明显就是内存消耗的降低,直方图算法不仅不需要额外存储预排序的结果,而且可以只保存特征离散化后的值,而这个值一般用8位整型存储就足够了,内存消耗可以降低为原来的1/8:

然后在计算上的代价也大幅降低,预排序算法每遍历一个特征值就需要计算一次分裂的增益,而直方图算法只需要计算k次(k可以认为是常数),时间复杂度从O(#data#feature)优化到O(k#features)。
Lightgbm的Histogram(直方图)做差加速
一个叶子的直方图可以由它的父亲节点的直方图与它兄弟的直方图做差得到。通常构造直方图,需要遍历该叶子上的所有数据,但直方图做差仅需遍历直方图的k个桶。利用这个方法,LightGBM可以在构造一个叶子的直方图后,可以用非常微小的代价得到它兄弟叶子的直方图,在速度上可以提升一倍:

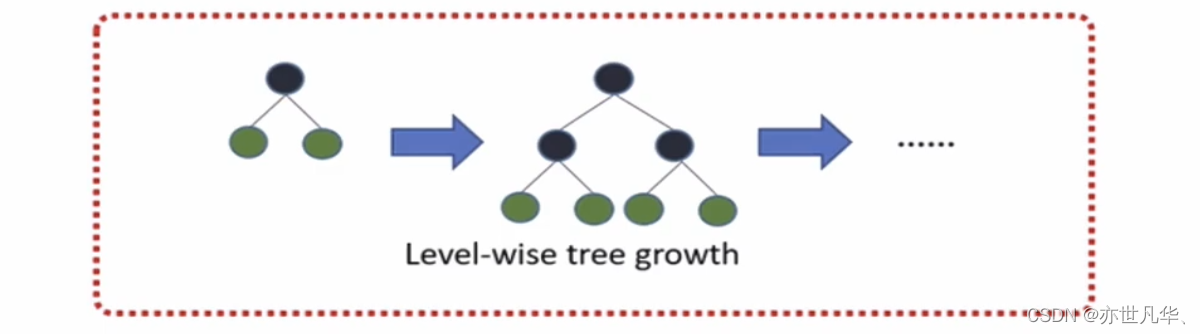
带深度限制的Leaf-wise的叶子生长策略
Level-wise便利一次数据可以同时分裂同一层的叶子,容易进行多线程优化,也好控制模型复杂度,不容易过拟合。
实际上Level-wise是一种低效的算法,因为它不加区分的对待同一层的叶子,带来了很多没必要的开销,因为实际上很多叶子的分裂增益较低,没必要进行搜索和分裂。
Leaf-wise则是一种更为高效的策略,每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后分裂,如此循环。
因此同Level-wise相比,在分裂次数相同的情况下,Leaf-wise可以降低更多的误差,得到更好的精度。Leaf-wise的缺点是可能会长出比较深的决策树,产生过拟合。因此LightGBM在Leaf-wise之上增加了一个最大深度的限制,在保证高效率的同时防止过拟合。

直接支持类别特征
实际上大多数机器学习工具都无法直接支持类别特征,一般需要把类别特征,转化到多维的0/1特征,降低了空间和时间的效率。
而类别特征的使用是在实践中很常用的。基于这个考虑,LightGBM优化了对类别特征的支持,可以直接输入类别特征,不需要额外的0/1展开。并在决策树算法上增加了类别特征的决策规则。
在Expo数据集上的实验,相比0/1展开的方法,训练速度可以加速8倍,并且精度一致。目前来看,LightGBM是第一个直接支持类别特征的GBDT工具。
直接支持高效并行
LightGBM还具有支持高效并行的优点。LightGBM原生支持并行学习,目前支持特征并行和数据并行的两种。
特征并行的主要思想是在不同机器在不同的特征集合上分别寻找最优的分割点,然后在机器间同步最优的分割点。
数据并行则是让不同的机器先在本地构造直方图,然后进行全局的合并,最后在合并的直方图上面寻找最优分割点。
lightGBM算法详细使用:对于lightGBM的使用,这里需要终端执行如下命令进行安装:
pip install lightgbm -i https://pypi.mirrors.ustc.edu.cn/simple对于lightGBM参数有以下相关内容的介绍:
Control Parameters
| ControlParameters | 含义 | 用法 |
|---|---|---|
| max_depth | 树的最大深度 | 当模型过拟合时,可以考虑首先降低max_depth |
| min_data_in_leaf | 叶子可能具有的最小记录数 | 默认20,过拟合时用 |
| feature_fraction | 例如为0.8时,意味着在每次迭代中随机选择80%的参数来建树 | boosting为random forest时用 |
| bagging_fraction | 每次迭代时用的数据比例 | 用于加快训练速度和减小过拟合 |
| early_stopping_round | 如果一次验证数据的一个度量在最近的early_stopping_round回合中没有提高模型将停止训练 | 加速分析,减少过多迭代 |
| lambda | 指定正则化 | 0~1 |
| min_gain_to_split | 描述分裂的最小 gain | 控制树的有用的分裂 |
| max_cat_group | 在group边界上找到分割点 | 当类别数量很多时,找分割点很容易过拟合时 |
| n_estimators | 最大迭代次数 | 最大迭代数不必设置过大,可以在进行一次迭代后,根据最佳迭代数设置 |
Core Parameters
| Core Parameters | 含义 | 用法 |
|---|---|---|
| Task | 数据的用途 | 选择train或者predict |
| application | 模型的用途 | 选择regression:回归时,binary:二分类时,multiclass:多分类时 |
| boosting | 要用的算法 | gbdt, rf:random forest, dart:DropoutsmeetMultipleAdditiveRegressionTrees, goss: Gradient-based One-Side Sampling |
| num_boost_round | 迭代次数 | 通常100+ |
| learning_rate | 学习率 | 常用0.1,0.001,0.003... |
| num_leaves | 叶子数量 | 默认31 |
| device | cpu 或者 gpu | |
| metric | mae:mean absolute error, mse:mean squared error, binary_logloss:loss for binary classification, multi_logloss:lossformulti classification |
IO parameter
| IO parameter | 含义 |
|---|---|
| max_bin | 表示feature将存入的bin的最大数量 |
| categorical_feature | 如果categorical_features=0,1,2,则列0,1,2是categorical变量 |
| ignore_column | 与categorical_features类似,只不过不是将特定的列视为categorical,而是完全忽略 |
| save_binary | 这个参数为true时,则数据集被保存为二进制文件,下次读数据时速度会变快 |
接下来我们借助鸢尾花数据集对 LightGBM 的进行一个基本使用:
下面这段代码实现了在 iris 数据集上使用 LightGBM 进行回归任务的训练和评估过程。模型在训练过程中会监控验证集的表现,当连续5次迭代模型性能没有提升时,会提前停止训练。最后输出模型在测试集上的准确率:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import mean_squared_error
import lightgbm as lgb
from lightgbm import early_stopping
# 读取数据
iris = load_iris()
data = iris.data
target = iris.target
# 数据基本处理
x_train, x_test, y_train, y_test = train_test_split(data, target, test_size=0.2)
# 模型训练
gbm = lgb.LGBMRegressor(objective="regression", learning_rate=0.05, n_estimators=20, device="gpu") # n_estimators为迭代次数
gbm.fit(x_train, y_train, eval_set=[(x_test, y_test)], eval_metric="l1", callbacks=[early_stopping(5)])
# 模型评估
acc = gbm.score(x_test, y_test)
print(f"LightGBM 模型准确率为:{acc*100:.4f}%")最终呈现的效果如下:

下面这段代码实现了在 iris 数据集上使用 GridSearchCV 进行参数网格搜索调参,并基于最优参数重新训练 LightGBM 回归模型的过程,并输出最优参数下模型在测试集上的准确率。这样可以帮助找到最佳的超参数组合,从而提高模型性能:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import mean_squared_error
import lightgbm as lgb
from lightgbm import early_stopping
# 读取数据
iris = load_iris()
data = iris.data
target = iris.target
# 数据基本处理
x_train, x_test, y_train, y_test = train_test_split(data, target, test_size=0.2)
# 通过网格搜索进行训练
estimators = lgb.LGBMRegressor(num_leaves=31)
param_grid = {
"learning_rate": [0.01, 0.1, 1],
"n_estimators": [20, 40, 60, 80]
}
gbm = GridSearchCV(estimators, param_grid, cv=5)
# 模型训练
gbm.fit(x_train, y_train)
# 输出模型最优参数
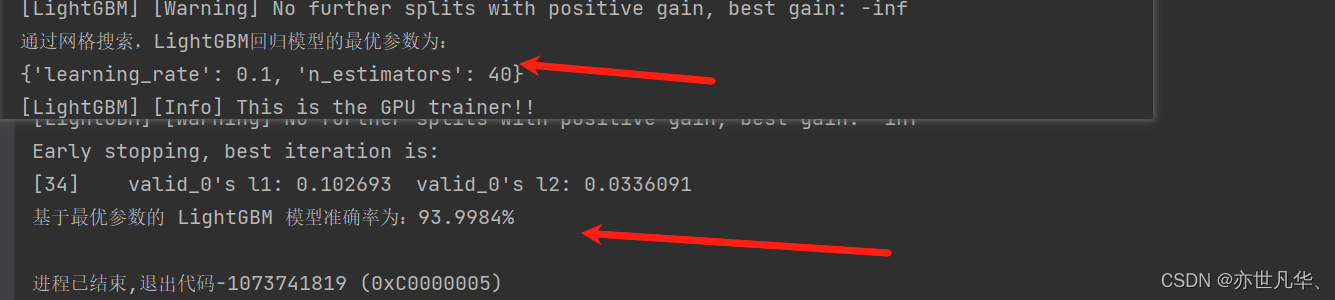
print(f"通过网格搜索,LightGBM回归模型的最优参数为:\r\n{gbm.best_params_}")
# 基于最优参数再进行模型训练
gbm = lgb.LGBMRegressor(objective="regression", learning_rate=0.1, n_estimators=40, device="gpu") # n_estimators为迭代次数
gbm.fit(x_train, y_train, eval_set=[(x_test, y_test)], eval_metric="l1", callbacks=[early_stopping(5)])
acc = gbm.score(x_test, y_test)
print(f"基于最优参数的 LightGBM 模型准确率为:{acc*100:.4f}%")最终呈现的结果如下:
《绝地求生》玩家排名预测(实操)
绝地求生(Playerunknown'sBattlegrounds),俗称吃鸡,是一款战术竞技型射击类沙盒游戏。

这款游戏是一款大逃杀类型的游戏,每一局游戏将有最多100名玩家参与,他们将被投放在绝地岛(battlegrounds)上,在游戏的开始时所有人都一无所有。玩家需要在岛上收集各种资源,在不断缩小的安全区域内对抗其他玩家,让自己生存到最后。

本作拥有很高的自由度,玩家可以体验飞机跳伞、开越野车、丛林射击、抢夺战利品等玩法,小心四周埋伏的敌人,尽可能成为最后1个存活的人。该游戏中,玩家需要在游戏地图上收集各种资源,并在不断缩小的安全区域内对抗其他玩家,让自己生存到最后。
本项目提供大量匿名的《PUBG》游戏统计数据。其格式为每行包含一个玩家的游戏后统计数据,列为数据的特征值。
数据来自所有类型的比赛:单排,双排,四排;不保证每场比赛有 100 名玩家,每组最多 4 名玩家。

数据集下载:PUBG Finish Placement Prediction ,登录账号之后,点击rule后接收规则:
然后再点击data数据当中,下载相应的数据集:
数据集当中的字段解释如下:
Id:用户 id
groupId:所处小队 id
matchId:该场比赛 id
assists:助攻数
boosts:使用能量、道具数量
DBNOs:击倒敌人数量
headshotKills:爆头数
heals:使用治疗药品数量
killPlace:本场比赛杀敌排行
killPoints:Elo 杀敌排名
kills:杀敌数
killStreaks:连续杀敌数
longestKill:最远杀敌距离
matchDuration:比赛时长
matchType:比赛类型(小组人数)
maxPlace:本场最差名次
numGroups:小组数量
rankPoints:Elo 排名
revives:救活队友的次数
rideDistance:驾车距离
roadKills:驾车杀敌数
swimDistance:游泳距离
teamKills:杀死队友的次数
vehicleDestorys:毁坏载具的数量
walkDistance:步行距离
weaponsAcquired:手机武器的数量
winPoints:Elo 胜率排名
winPlacePerc:百分比排名 —— 这是一个百分位获胜排名,其中1对应第一名,0对应比赛中最后一名
项目评估方式:你必须创建一个模型,根据他们的最终统计数据预测玩家的排名,从1(第一名)到0(最后一名)。最后结果通过平均绝对误差(MAE)进行评估,即通过预测的winPlacePerc和真实的winPlacePerc之间的平均绝对误差。关于MAE:

项目实现:在接下来的分析中,我们将分析数据集,检测异常值。然后我们通过随机森林模型对其训练,并对对该模型进行了优化。以下是本次案例的具体步骤实现:
获取数据,基本数据查看:
# 导入数据基本处理阶段需要用到的api
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
以下是查看数据进行的一些场景操作:
train.head() # 数据集头部前五行
train.tail() # 数据集尾部前五行
train.describe() # 数据集整体描述
train.info() # 数据集字段信息
train.shape # 数据集整体有多少数据
np.unique(train["matchId"]).shape # 查看一共有多少场比赛
np.unique(train["groupId"]).shape # 查看一共有多少组下面是这些命令的操作得到的具体数据展现:

数据基本处理:
寻找训练集当中是否存在缺失值:
# 查看缺失值,通过下面方法查看
pd.isnull(train).any()查看目标值,我们发现有一条样本,比较特殊,其“winplaceperc"的值为NaN,也就是目标值是缺失值。

# 寻找缺失值行
train[train["winPlacePerc"].isnull()]发现只有这一条数据存在缺失值:

接下来对缺失值进行删除操作:

查看每场比赛参加的人数:处理完缺失值之后,我们看一下每场参加的人数会有多少呢,是每次都会匹配100个人,才开始游戏吗?
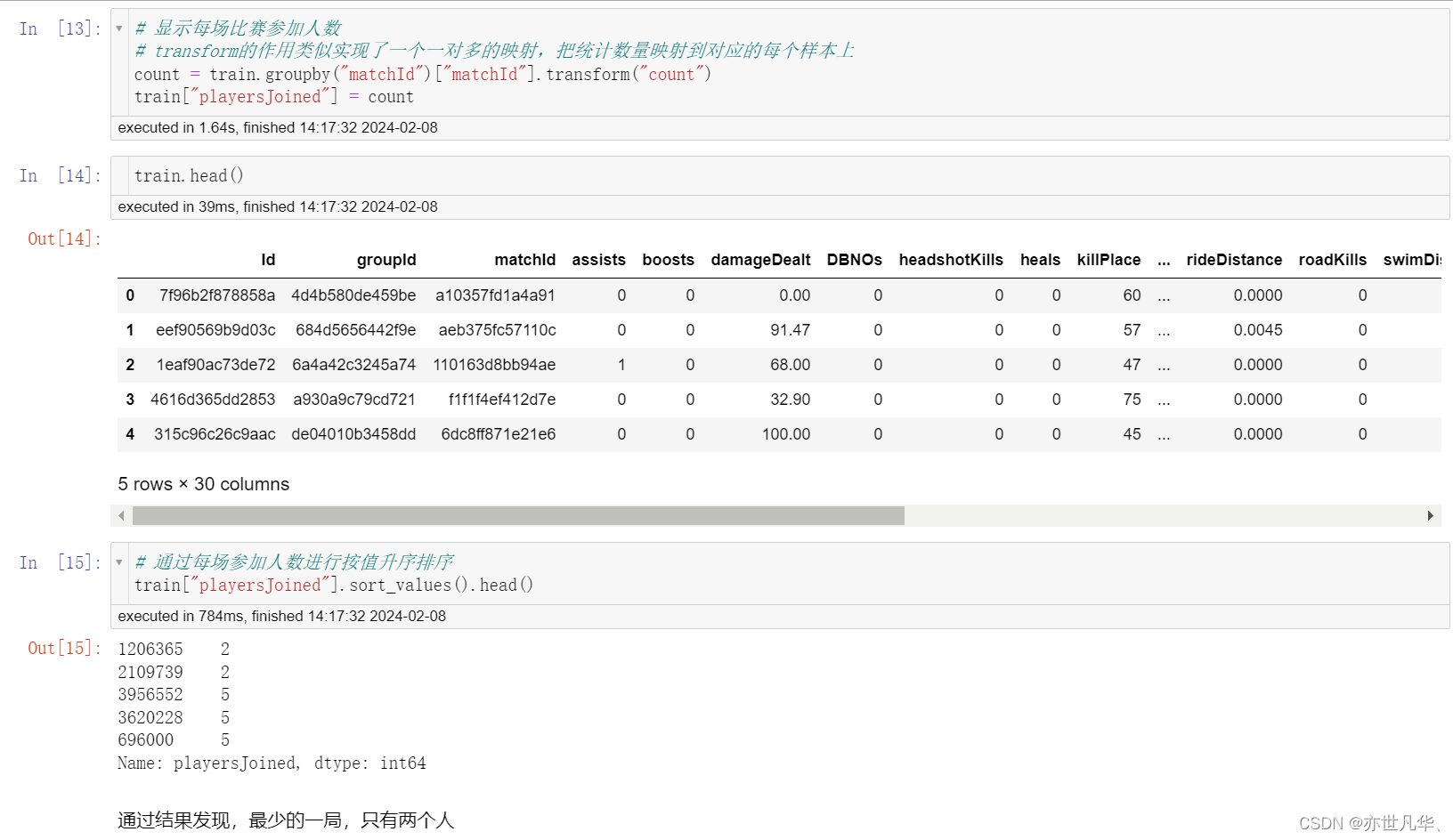
# 通过绘制图像,查看每局开始人数
# 通过seaborn下的countplot方法,可以直接绘制统计过数量之后的直方图
plt.figure(figsize=(20, 8))
sns.countplot(train['playersJoined'])
plt.grid()
plt.show()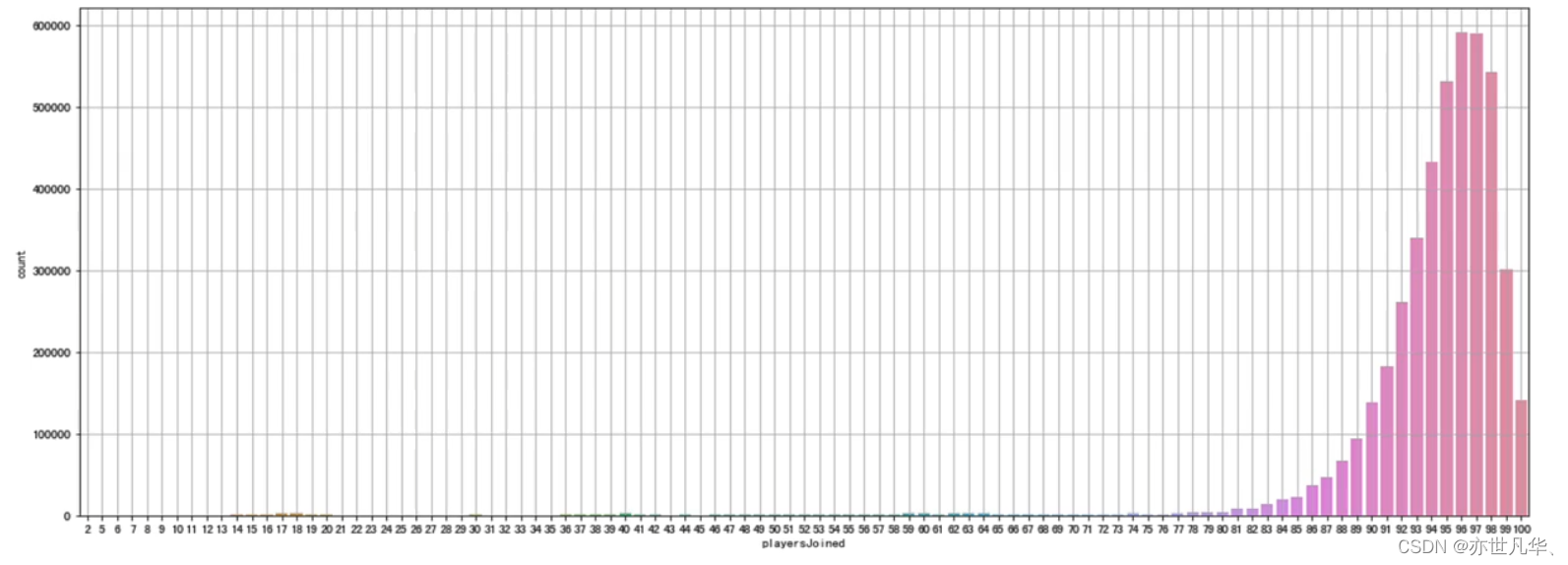
通过观察,发现一局游戏少于 75 个玩家的情况是很罕见的,大部分游戏都是在 96 人左右的时候才开始。我们限制每局开始人数大于等于 75,再进行绘制:
# 再次绘制每局参加人数的直方图
plt.figure(figsize=(20, 4))
sns.countplot(train['playersJoi
plt.grid()
plt.show()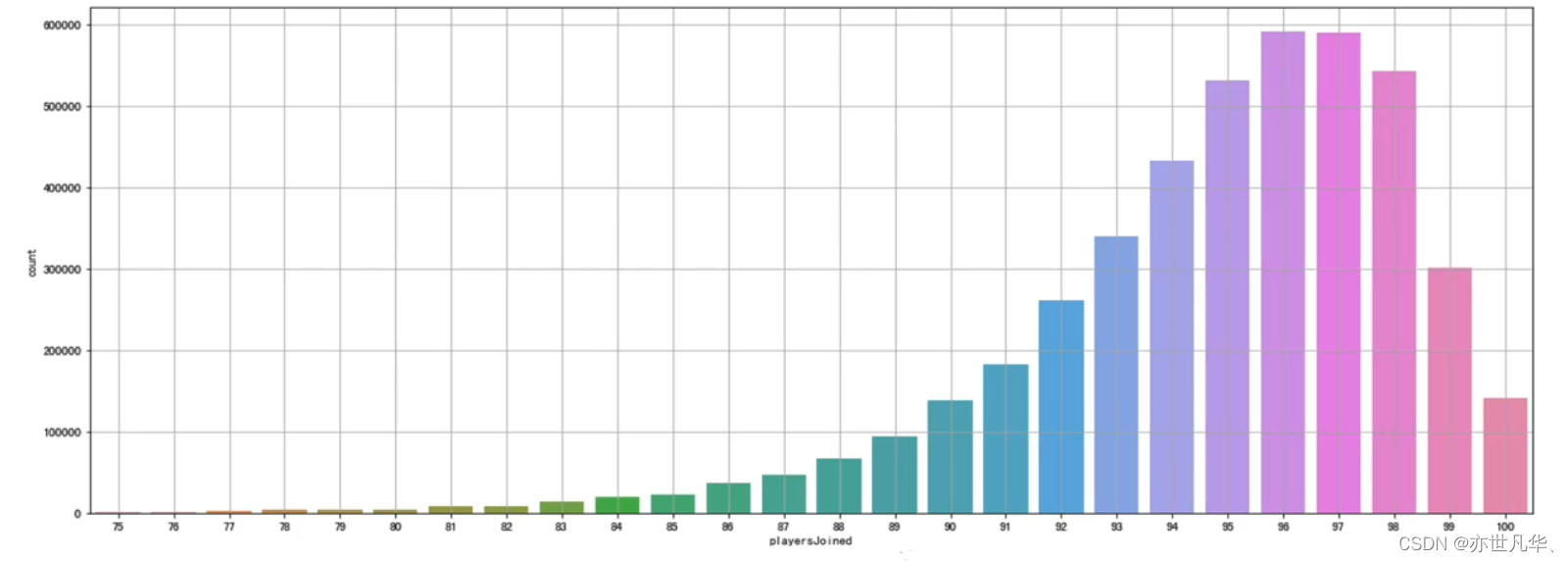
规范化输出部分数据:现在我们统计了“每局玩家数量”,那么我们就可以通过“每局玩家数量”来进一步考证其它特征,同时对其规范化设置试想:一局只有70个玩家的杀敌数,和一局有100个玩家的杀敌数,应该是不可以同时比较的,可以考虑的特征值包括:(1)kills (杀敌数)(2)damageDealt(总伤害)(3)maxPlace(本局最差名次)(4)matchDuration(比赛时长)
# 对部分特征值进行规范化处理
train["killsNorm"] = train["kills"] * ((100 - train["playersJoined"]) / 100 + 1)
train["damageDealtNorm"] = train["damageDealt"] * ((100 - train["damageDealt"]) / 100 + 1)
train["maxPlaceNorm"] = train["maxPlace"] * ((100 - train["maxPlace"]) / 100 + 1)
train["matchDurationNorm"] = train["matchDuration"] * ((100 - train["matchDuration"]) / 100 + 1)
# 比较经过规范化的特征值和原始特征值的值
to_show = ['Id', 'kills', 'killsNorm', 'damageDealt', 'damageDealtNorm',
'maxPlace', 'maxPlaceNorm', 'matchDuration', "matchDurationNorm"]
train[to_show][0:11]呈现的结果如下所示:
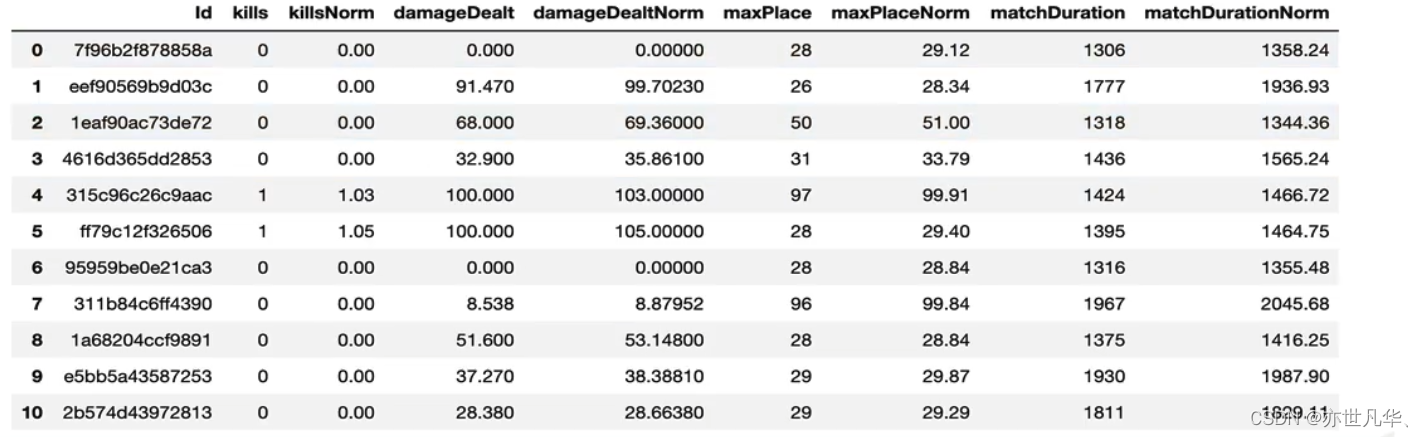
部分变量合成:此处我们把特征:heals(使用治疗药品数量)和boosts(能量、道具使用数量)合并成一个新的变量,命名:"healsandboosts",这是一个探索性过程,最后结果不一定有用,如果没有实际用处,最后再把它删除。
异常值处理: 一些行中的数据统计出来的结果非常反常规,那么这些玩家肯定有问题,为了训练模型的准确性,我们会把这些异常数据剔除
删除有击杀,但是完全没有移动的玩家:这类型玩家肯定是存在异常情况(挂**),我们把这些玩家删除。通过以下操作,识别出玩家在游戏中有击杀数,但是全局没有移动:
下面代码首先使用布尔索引来选择 train 中所有被标记为作弊者的行。然后再使用 drop 方法来删除这些行,并使用 inplace=True 参数来指定在原地修改 DataFrame 对象。
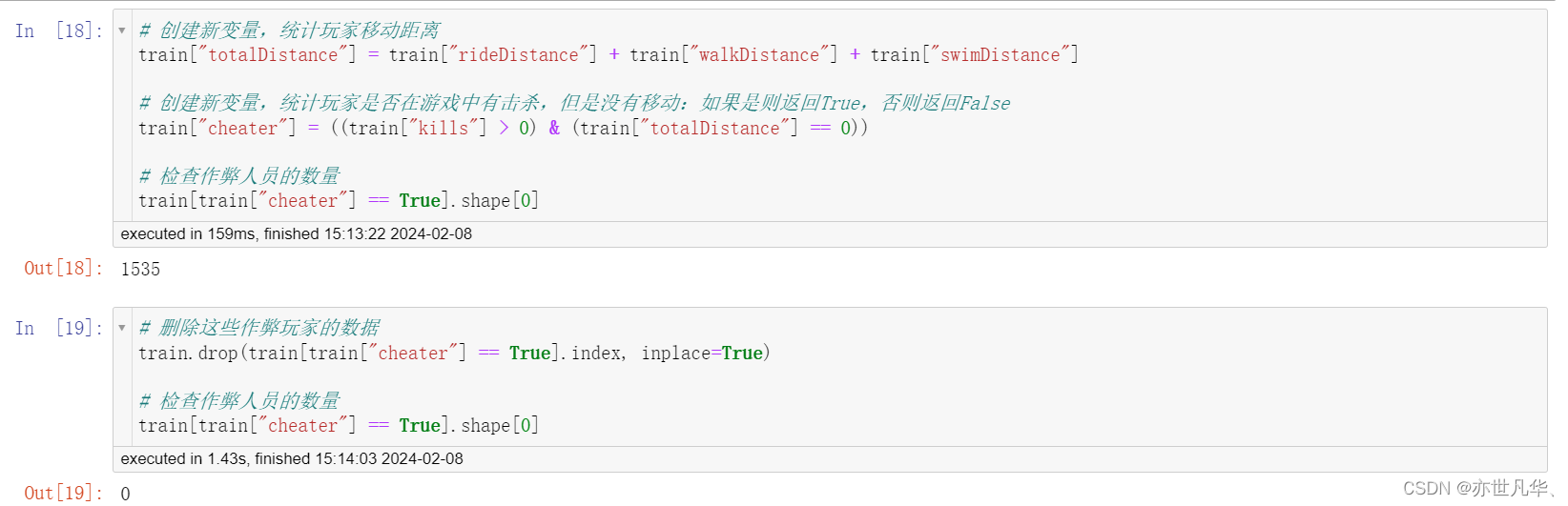
删除驾车杀敌数异常的数据:

删除一局中杀敌数超过30人的玩家数据:
# 首先绘制玩家杀敌数的统计图
plt.figure(figsize=(10, 4), dpi=200)
sns.countplot(x=train["kills"])
plt.ylabel("达到的玩家人数")
plt.xlabel("击杀数")
plt.show()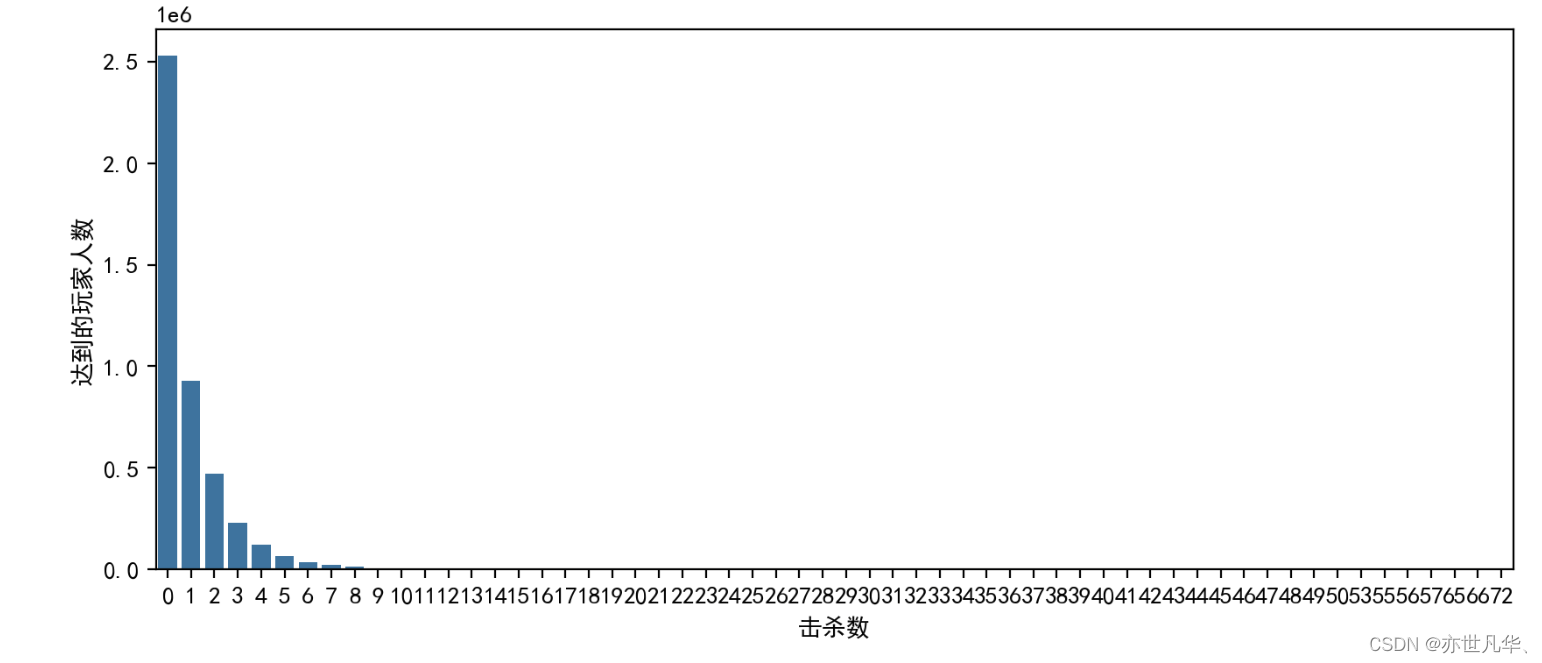
# 再删除一局中杀敌数超过 30 人的玩家数据
train.drop(train[train["kills"] > 30].index, inplace=True)删除爆头率异常数据:
# 创建爆头率变量
train["headshot_rate"] = train["headshotKills"] / train["kills"]
# 对于那些没有击杀记录的玩家,他们的爆头率将被设置为 0
train["headshot_rate"] = train["headshot_rate"].fillna(0)
# 绘制爆头率统计图
plt.figure(dpi=300)
sns.displot(train["headshot_rate"], bins=10, kde=False)
plt.ylabel("达到的玩家人数")
plt.xlabel("爆头率∈[0,1]")
plt.show()
# 删除爆头率异常的数据(爆头率 = 1 且击杀 > 9)
train.drop(train[(train["headshot_rate"] == 1) & (train["kills"] > 9)].index, inplace=True)删除最远杀敌距离异常数据:
# 绘制远距离杀敌直方图
plt.figure(dpi=300)
sns.displot(train["longestKill"], bins=10, kde=False)
plt.ylabel("达到的玩家人数")
plt.xlabel("远距离杀敌数")
plt.show()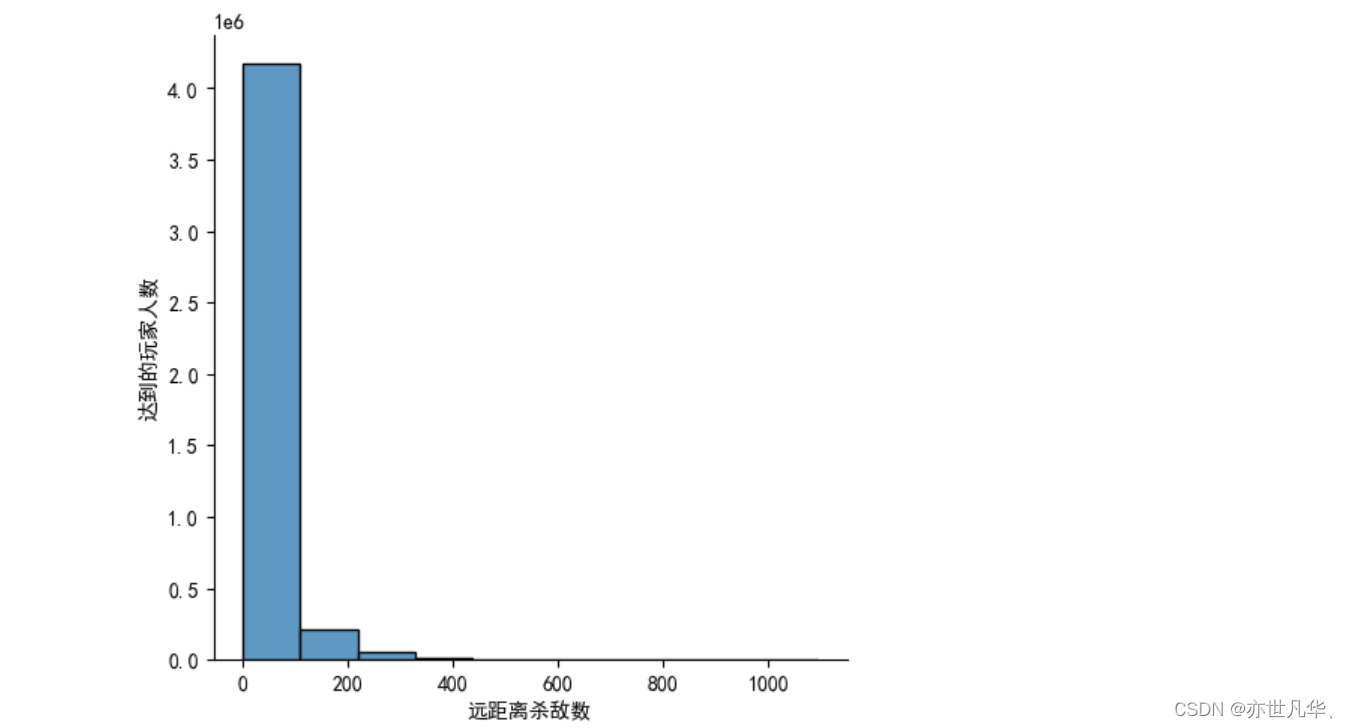
# 删除杀敌距离 ≥ 1km 的玩家
train.drop(train[train["longestKill"] >= 1000].index, inplace=True)删除关于运动距离的异常值:
# 距离整体描述
train[["walkDistance", "rideDistance", "swimDistance", "totalDistance"]].describe()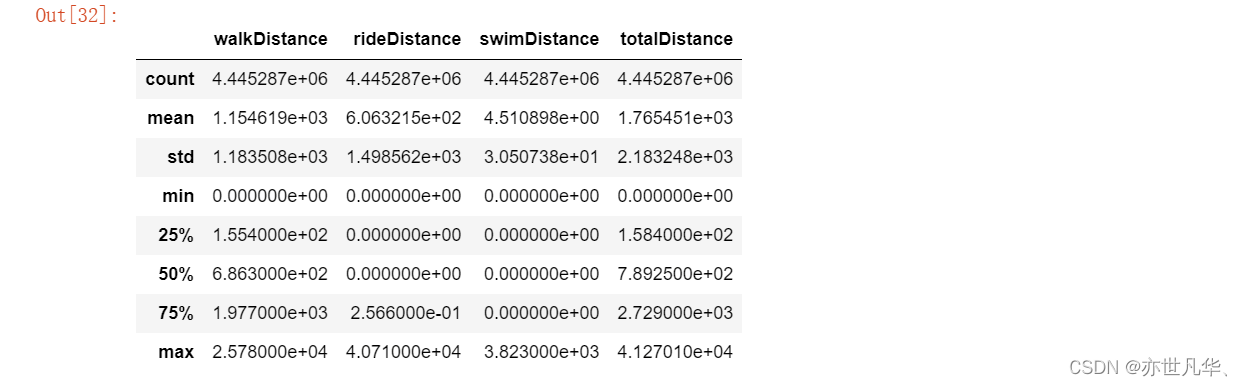
# a. 删除行走距离异常的数据
train.drop(train[train["walkDistance"] >= 10000].index, inplace=True)
# b. 删除载具行驶距离异常的数据
train.drop(train[train["rideDistance"] >= 20000].index, inplace=True)
# c. 删除游泳距离异常的数据
train.drop(train[train["swimDistance"] >= 20000].index, inplace=True)武器收集异常值处理:
# 绘制武器收集直方图
plt.figure(dpi=300)
sns.displot(train["weaponsAcquired"], bins=10, kde=False)
plt.ylabel("达到的玩家人数")
plt.xlabel("武器收集数量")
plt.show()
# 删除武器收集异常的数据
train.drop(train[train["weaponsAcquired"] >= 80].index, inplace=True)删除使用治疗药品数量异常值:
# 绘制使用治疗药品数量直方图
plt.figure(figsize=(20, 10), dpi=300)
sns.displot(train["heals"], bins=10, kde=False)
plt.ylabel("达到的玩家人数")
plt.xlabel("使用治疗药品数量")
plt.savefig("./data/snsdisplot.png", dpi=300)
plt.show()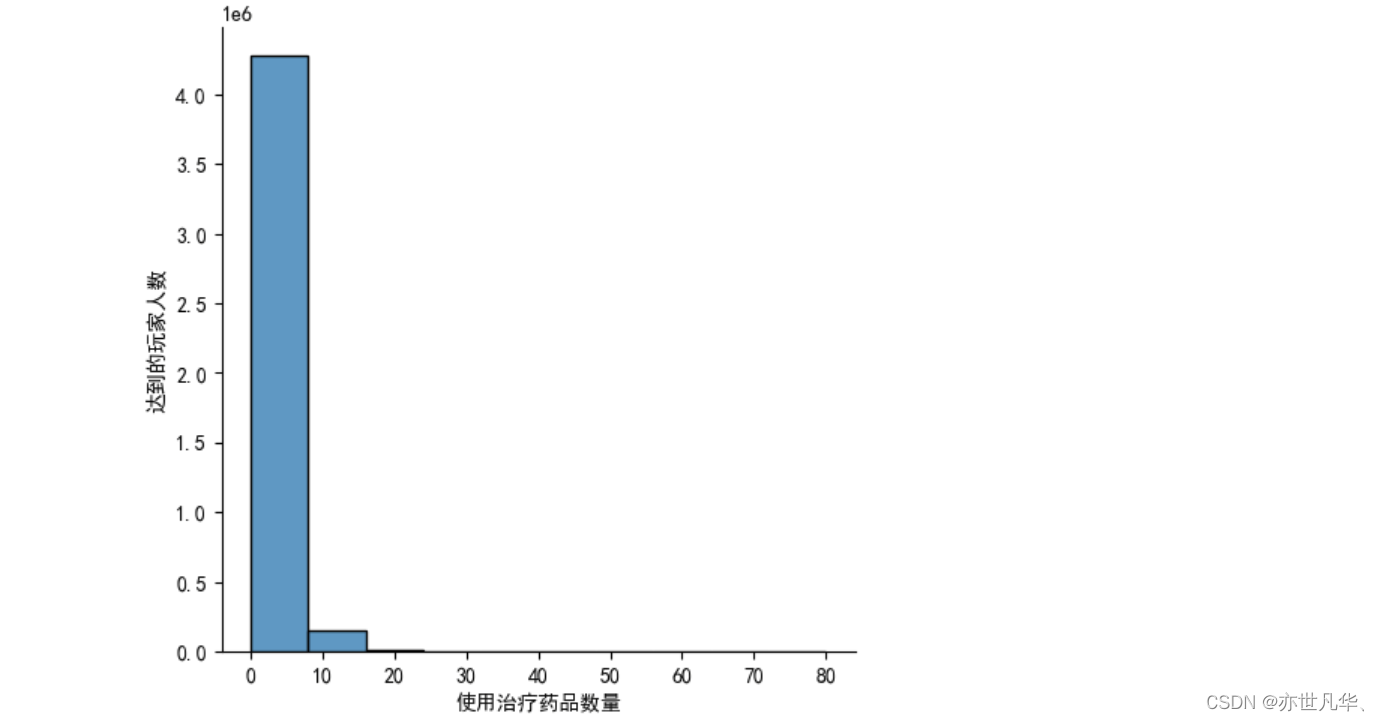

类别型数据处理:
对比赛类型 one-hot 处理:
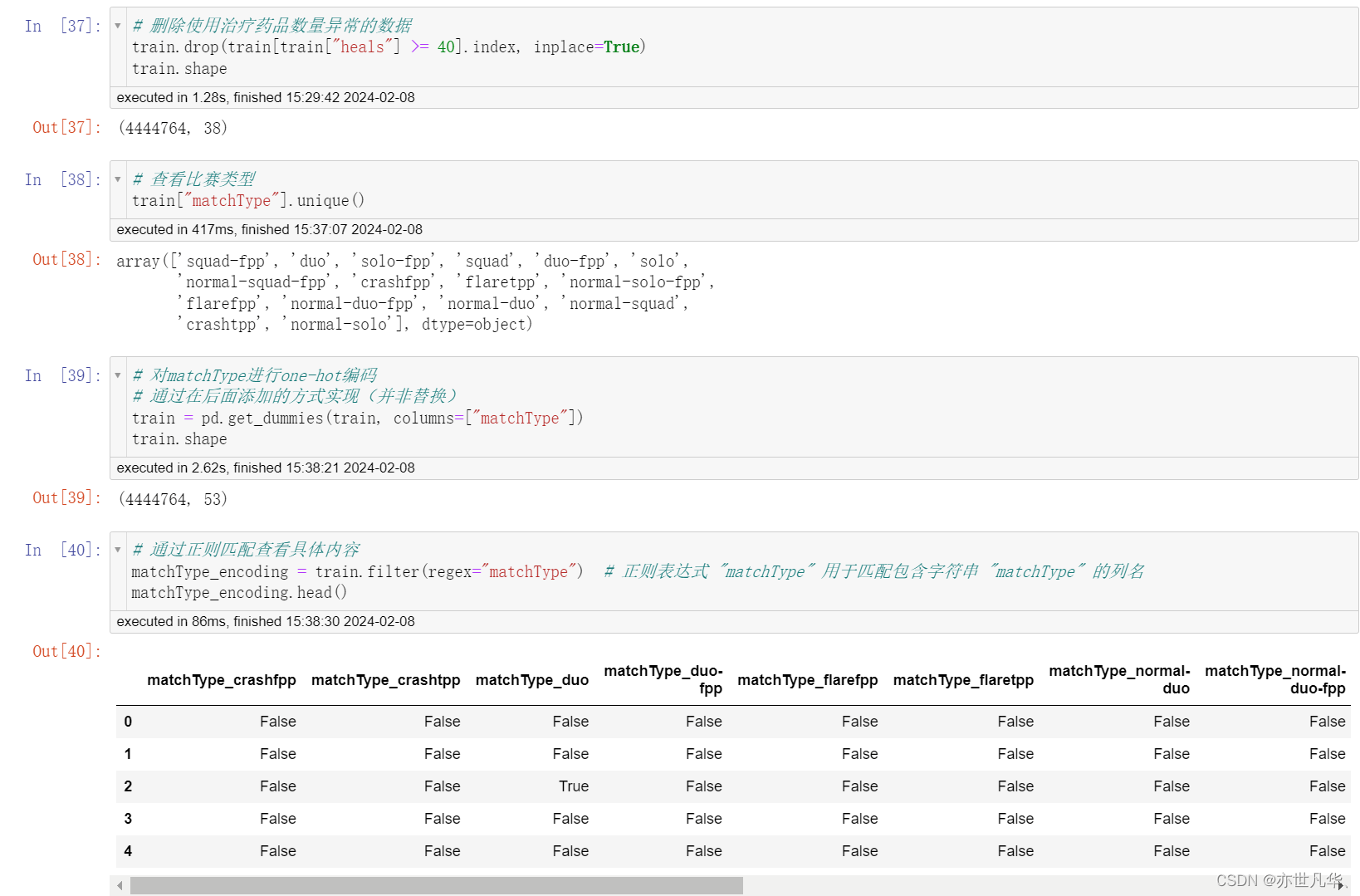
对 groupId,matchId 等数据进行处理:
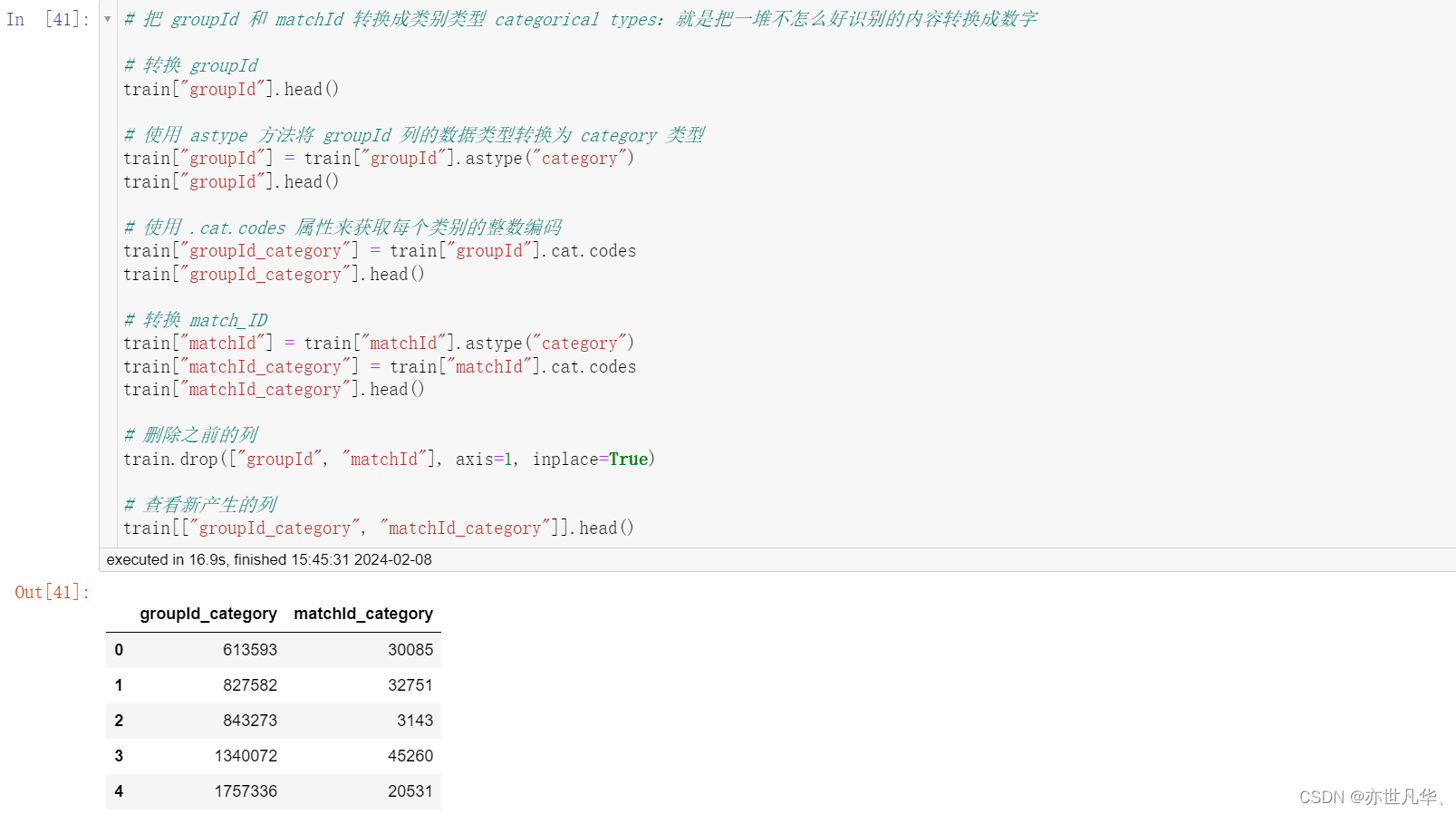
数据截取:
确定特征值和目标值:

分割训练集和测试集:

机器学习(模型训练)和评估:
初步使用随机森林进行模型训练:
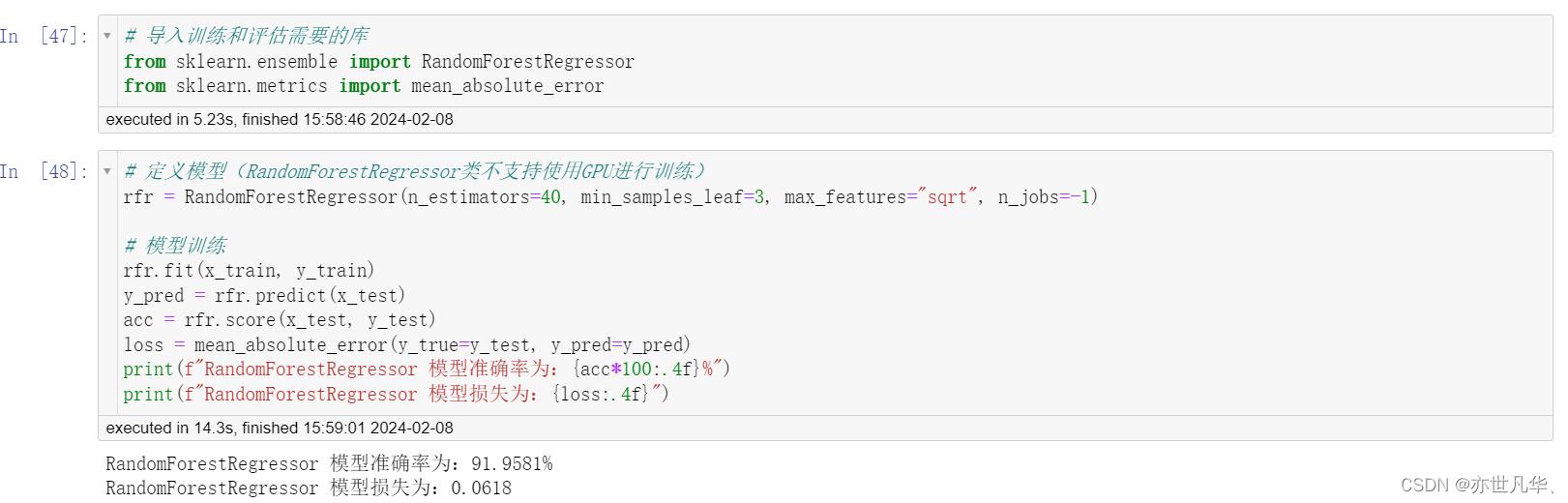
再次使用随机森林,进行模型训练:

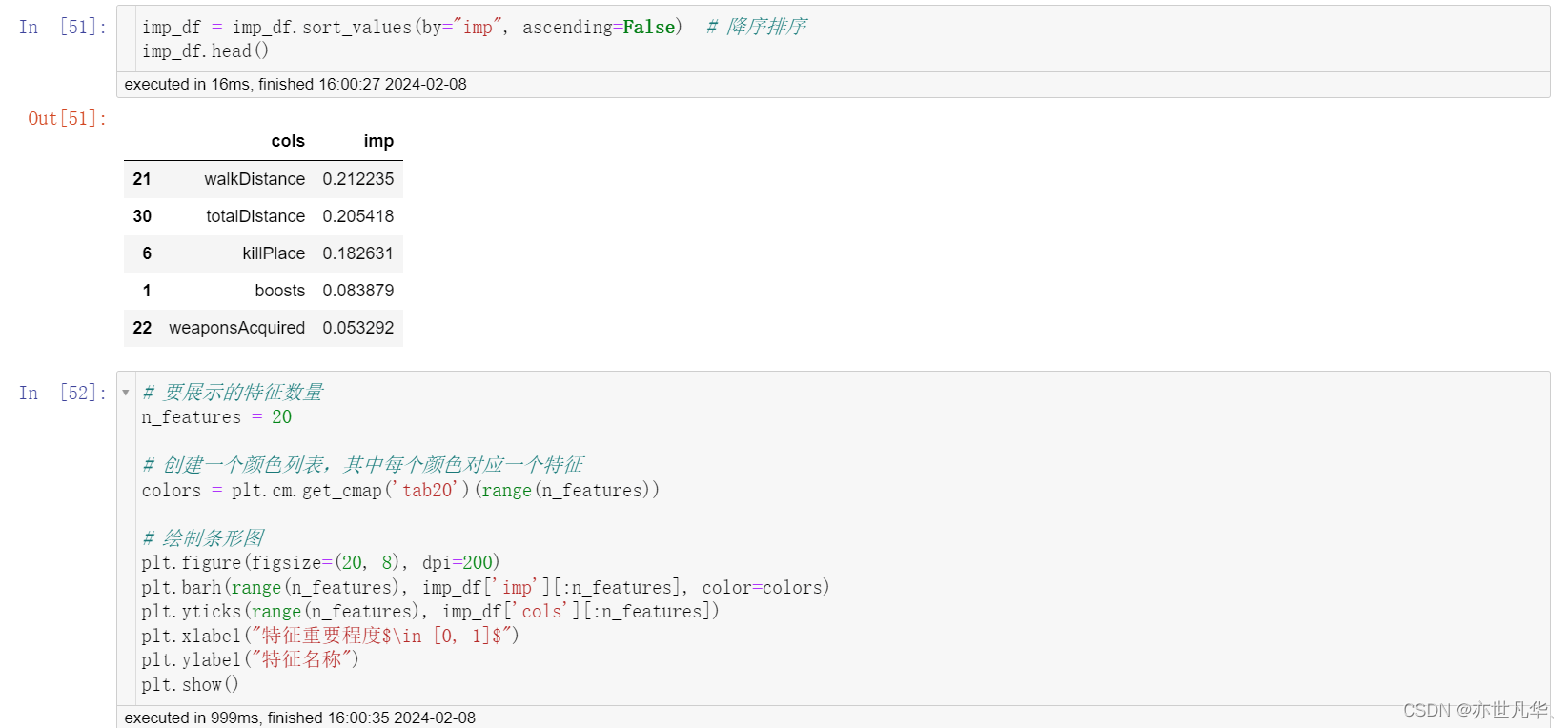
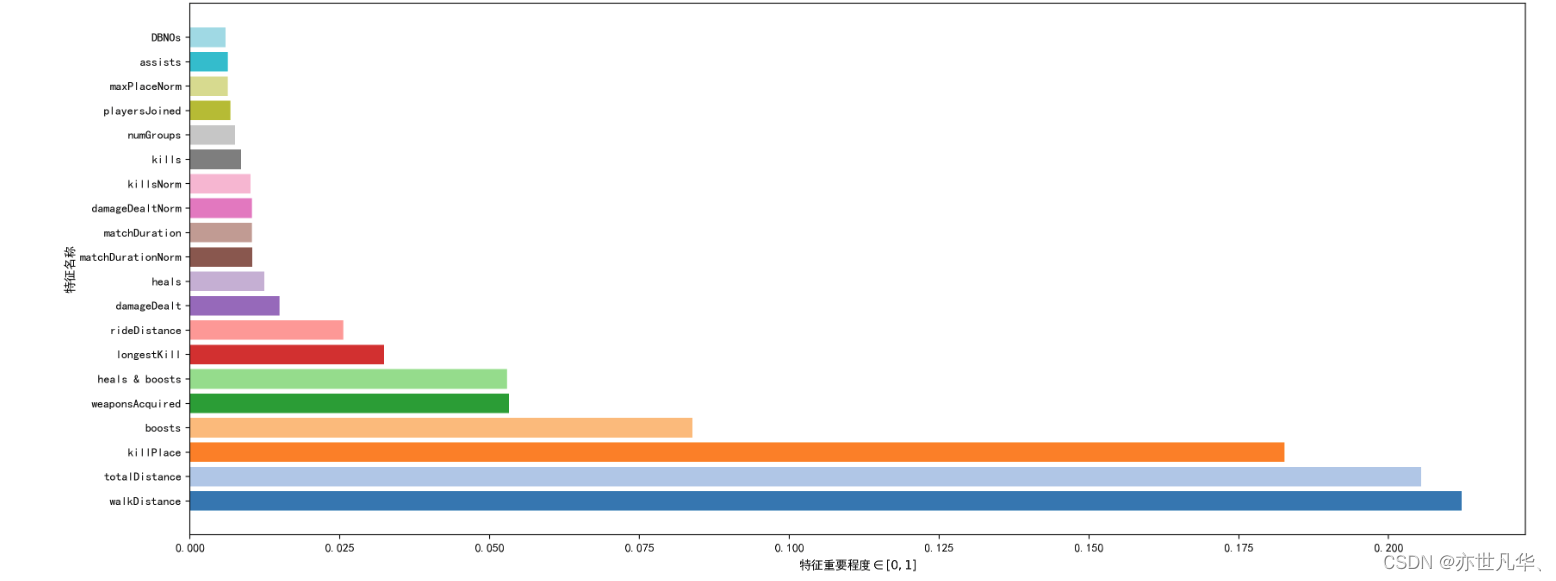
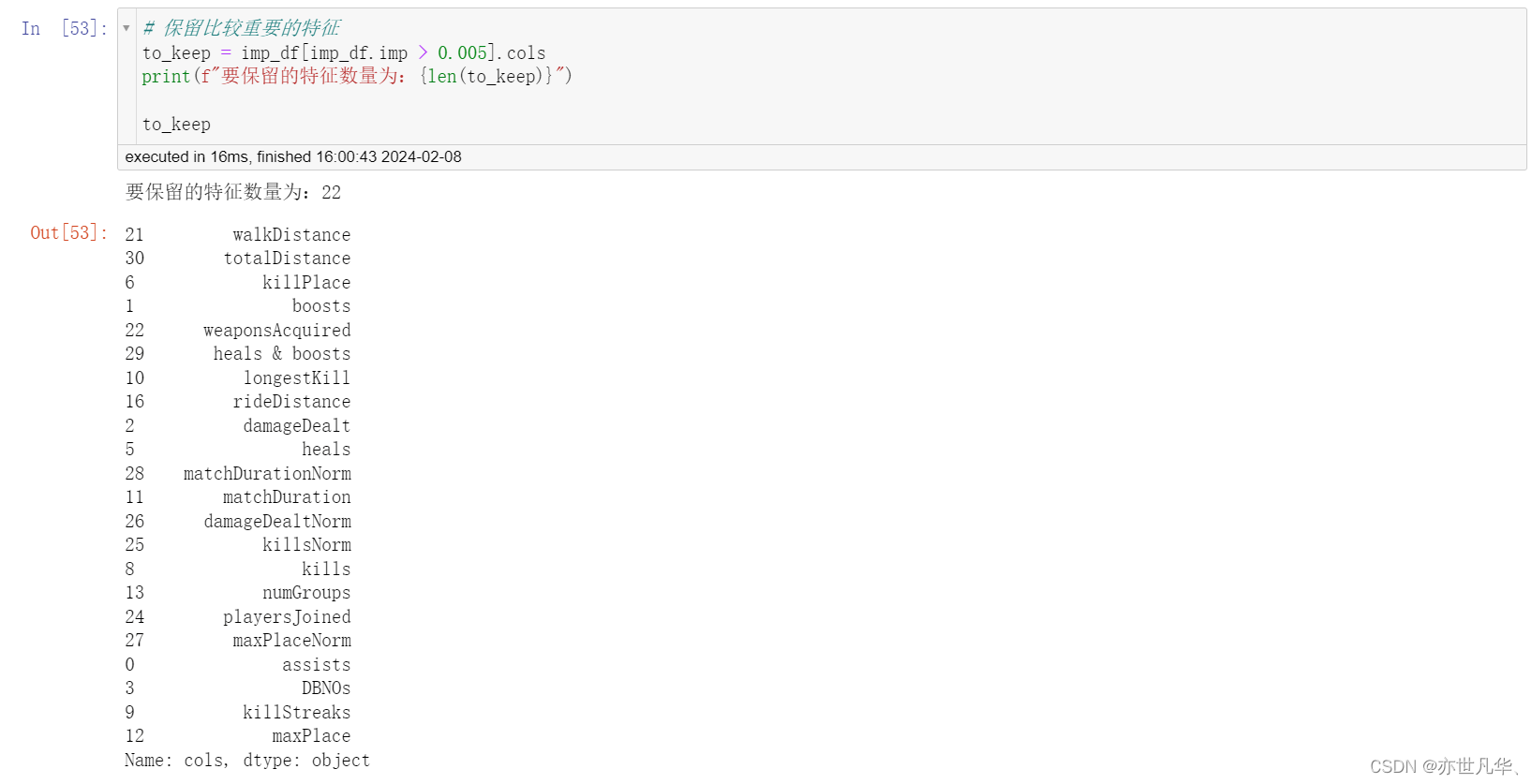
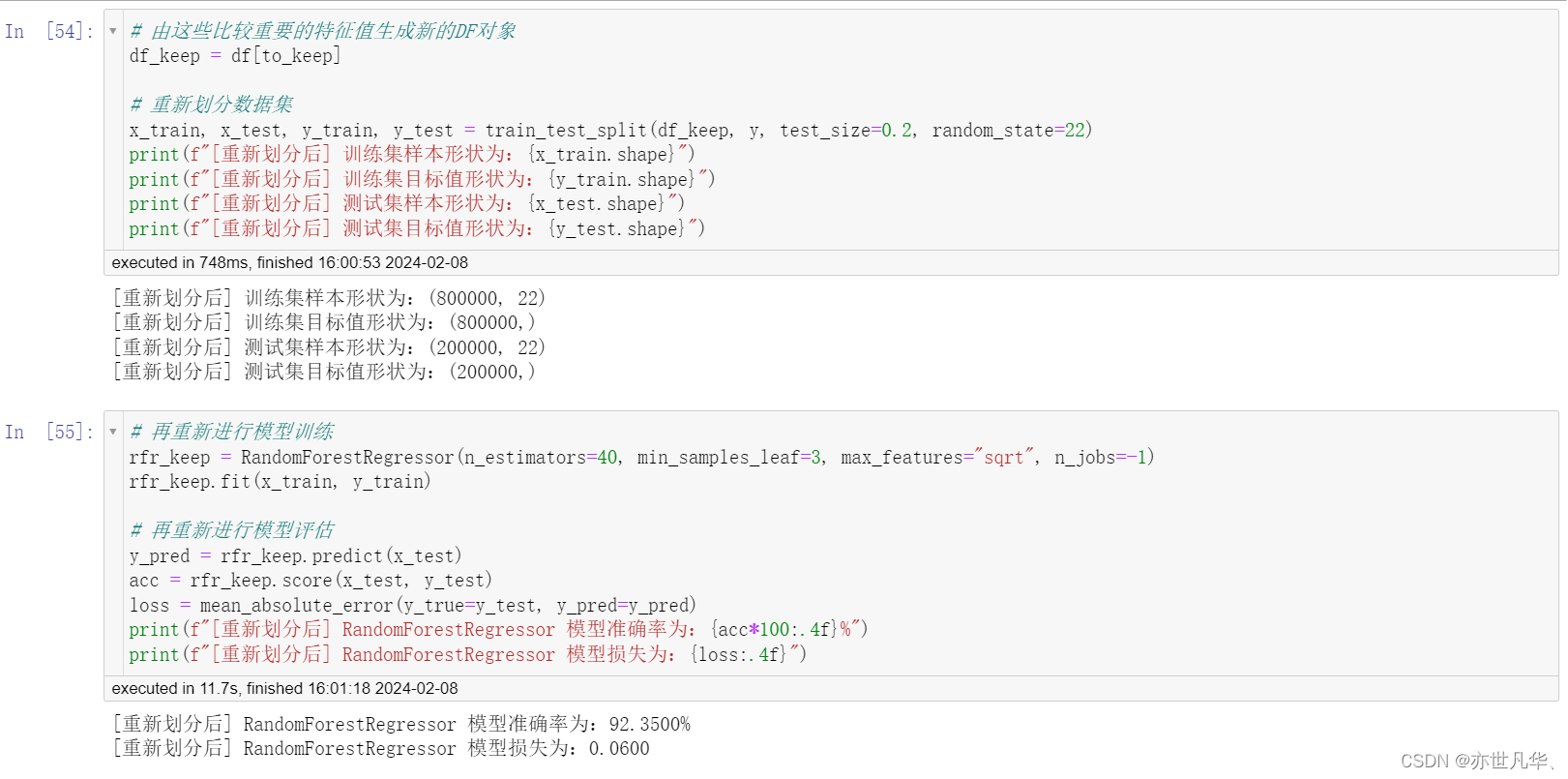
使用 LightGBM 对模型进行训练:
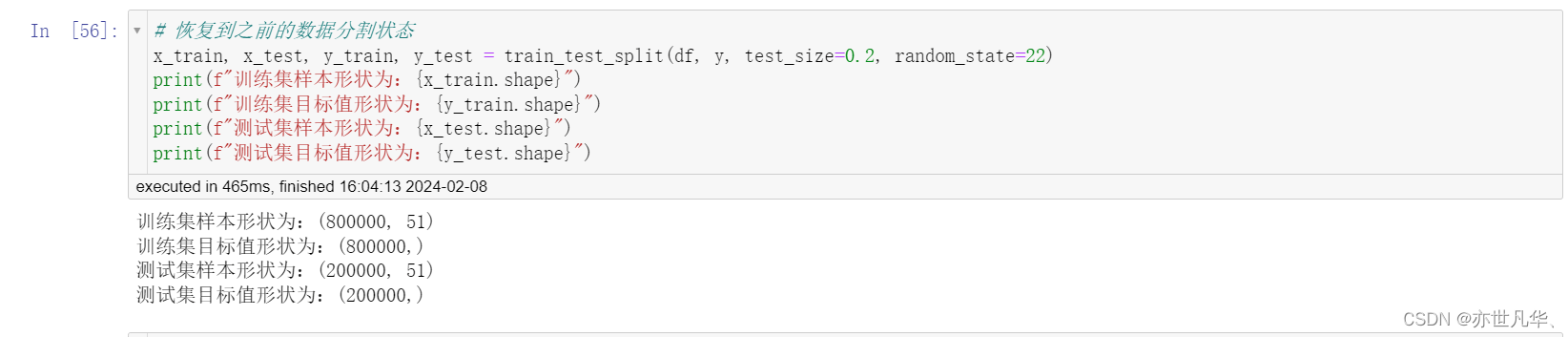
模型初次尝试结果如下:


模型二次调优:
from sklearn.model_selection import GridSearchCV
# 定义模型
model = lgbm.LGBMRegressor(num_leaves=31, device="gpu")
param_grid_lst = {"learning_rate": [0.01, 0.05, 0.1, 0.15, 0.2],
"n_estimators": [20, 50, 100, 200, 300, 500]}
model = GridSearchCV(estimator=model, param_grid=param_grid_lst, cv=5, n_jobs=-1, verbose=2)
model.fit(x_train, y_train)得到如下结果,过程相当耗费时间:
Fitting 5 folds for each of 30 candidates, totalling 150 fits
GridSearchCV(cv=5, estimator=LGBMRegressor(device='gpu'), n_jobs=-1,
param_grid={'learning_rate': [0.01, 0.05, 0.1, 0.15, 0.2],
'n_estimators': [20, 50, 100, 200, 300, 500]},
verbose=2)
# 最优模型预测
y_pred = model.predict(x_test)
acc = model.score(x_test, y_test)
loss = mean_absolute_error(y_test, y_pred)
print(f"LGBMRegressor 网格交叉搜索最优模型准确率为:{acc*100:.4f}%")
print(f"LGBMRegressor 网格交叉搜索最优模型损失为:{loss:.4f}")
# LGBMRegressor 网格交叉搜索最优模型准确率为:93.5980%
# LGBMRegressor 网格交叉搜索最优模型损失为:0.0553# 查看网格搜索/交叉验证的结果
print("Best parameters:", model.best_params_)
print("Best score:", model.best_score_)
print("Best estimator:", model.best_estimator_)
print("CV results:", model.cv_results_)
# 结果如下
Best parameters: {'learning_rate': 0.15, 'n_estimators': 500}
Best score: 0.9359144823173906
Best estimator: LGBMRegressor(device='gpu', learning_rate=0.15, n_estimators=500)
CV results: {'mean_fit_time': array([14.34503574, 20.01631103, 25.97441425, 43.4136445 , 60.82093949,
89.25930433, 11.62595191, 16.23543158, 25.54000373, 36.26000762,
49.61888871, 66.26681533, 11.1753377 , 15.24283795, 20.54040017,
30.36953435, 41.37112398, 52.48080788, 11.32525654, 16.418437 ,
19.51573868, 29.89882855, 37.1528873 , 48.23137908, 10.68091936,
13.80297165, 19.0142149 , 26.71594262, 33.4341989 , 34.97594118]), 'std_fit_time': array([0.89452845, 0.69153922, 1.30721953, 0.59971748, 1.47560355,
1.69149272, 0.38846451, 0.26956315, 0.66550434, 0.40090513,
0.64625266, 0.58125147, 0.81862829, 0.39151642, 0.25658152,
1.89966286, 1.02374619, 2.16053993, 0.59936112, 1.262003 ,
1.13085383, 1.16485342, 0.86350695, 0.98988553, 0.4670428 ,
0.35239315, 0.6680641 , 0.72602143, 0.32089537, 3.72148617]), 'mean_score_time': array([1.5022016 , 1.42152162, 2.12359066, 4.06432238, 5.19431663,
8.55703535, 1.32677093, 2.00913296, 2.52904983, 4.60726891,
6.05252767, 9.39462171, 1.47626009, 1.72542372, 2.56810923,
4.31121016, 6.6386538 , 9.39059463, 1.7088644 , 2.02408352,
2.97478876, 4.52777481, 5.31689487, 7.65328541, 1.4070025 ,
1.96806068, 2.37317958, 3.95138211, 4.22260122, 4.59180803]), 'std_score_time': array([0.26366997, 0.10020396, 0.14991592, 0.1966688 , 0.1009084 ,
0.25914634, 0.12654092, 0.30676004, 0.37853699, 0.23382102,
0.23462405, 0.40300067, 0.06112725, 0.07371341, 0.09753172,
0.1741567 , 0.7262754 , 1.32623107, 0.21834994, 0.25155977,
0.23926274, 0.52417874, 0.21302958, 0.12573272, 0.12746464,
0.20380246, 0.0958619 , 0.18764002, 0.30194442, 0.14234936]), 'param_learning_rate': masked_array(data=[0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.05, 0.05, 0.05,
0.05, 0.05, 0.05, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.15,
0.15, 0.15, 0.15, 0.15, 0.15, 0.2, 0.2, 0.2, 0.2, 0.2,
0.2],
mask=[False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False],
fill_value='?',
dtype=object), 'param_n_estimators': masked_array(data=[20, 50, 100, 200, 300, 500, 20, 50, 100, 200, 300, 500,
20, 50, 100, 200, 300, 500, 20, 50, 100, 200, 300, 500,
20, 50, 100, 200, 300, 500],
mask=[False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False],
fill_value='?',
dtype=object), 'params': [{'learning_rate': 0.01, 'n_estimators': 20}, {'learning_rate': 0.01, 'n_estimators': 50}, {'learning_rate': 0.01, 'n_estimators': 100}, {'learning_rate': 0.01, 'n_estimators': 200}, {'learning_rate': 0.01, 'n_estimators': 300}, {'learning_rate': 0.01, 'n_estimators': 500}, {'learning_rate': 0.05, 'n_estimators': 20}, {'learning_rate': 0.05, 'n_estimators': 50}, {'learning_rate': 0.05, 'n_estimators': 100}, {'learning_rate': 0.05, 'n_estimators': 200}, {'learning_rate': 0.05, 'n_estimators': 300}, {'learning_rate': 0.05, 'n_estimators': 500}, {'learning_rate': 0.1, 'n_estimators': 20}, {'learning_rate': 0.1, 'n_estimators': 50}, {'learning_rate': 0.1, 'n_estimators': 100}, {'learning_rate': 0.1, 'n_estimators': 200}, {'learning_rate': 0.1, 'n_estimators': 300}, {'learning_rate': 0.1, 'n_estimators': 500}, {'learning_rate': 0.15, 'n_estimators': 20}, {'learning_rate': 0.15, 'n_estimators': 50}, {'learning_rate': 0.15, 'n_estimators': 100}, {'learning_rate': 0.15, 'n_estimators': 200}, {'learning_rate': 0.15, 'n_estimators': 300}, {'learning_rate': 0.15, 'n_estimators': 500}, {'learning_rate': 0.2, 'n_estimators': 20}, {'learning_rate': 0.2, 'n_estimators': 50}, {'learning_rate': 0.2, 'n_estimators': 100}, {'learning_rate': 0.2, 'n_estimators': 200}, {'learning_rate': 0.2, 'n_estimators': 300}, {'learning_rate': 0.2, 'n_estimators': 500}], 'split0_test_score': array([0.28454907, 0.54923917, 0.76022635, 0.88293465, 0.91060857,
0.9244634 , 0.76505124, 0.90190306, 0.92444864, 0.93187006,
0.93394925, 0.93529471, 0.88553821, 0.92402019, 0.93150503,
0.93446068, 0.9352919 , 0.93604723, 0.91159903, 0.92893752,
0.93328694, 0.93504886, 0.93565664, 0.93623854, 0.91960025,
0.93077007, 0.93357905, 0.93492508, 0.93552697, 0.93608738]), 'split1_test_score': array([0.28436306, 0.54875665, 0.75954484, 0.88222918, 0.91018844,
0.92418283, 0.76438739, 0.90153518, 0.92425756, 0.9319695 ,
0.934071 , 0.93554092, 0.8849283 , 0.92402688, 0.93171493,
0.93470062, 0.93560521, 0.93640918, 0.91033221, 0.92893088,
0.93318294, 0.93526183, 0.9358338 , 0.93635082, 0.91873591,
0.93101601, 0.93364595, 0.93507168, 0.93551916, 0.93595913]), 'split2_test_score': array([0.2843355 , 0.54855371, 0.75959117, 0.88183133, 0.91004533,
0.92409252, 0.764491 , 0.90155836, 0.92413334, 0.93163902,
0.93377787, 0.93513166, 0.88560984, 0.92399051, 0.93142455,
0.93422112, 0.93510549, 0.93571943, 0.91129593, 0.92855244,
0.93301829, 0.93474559, 0.93526989, 0.93578894, 0.91839872,
0.93037481, 0.93342368, 0.93463735, 0.93512018, 0.93561078]), 'split3_test_score': array([0.28416371, 0.54822298, 0.75871174, 0.88129364, 0.90952787,
0.923619 , 0.76384192, 0.90058734, 0.92375681, 0.93143612,
0.93350314, 0.93487847, 0.88453036, 0.92307768, 0.93082085,
0.93394062, 0.9348608 , 0.93564594, 0.90959224, 0.92776206,
0.9324688 , 0.93431994, 0.93499641, 0.93558379, 0.91865493,
0.93035951, 0.93341205, 0.93466532, 0.93519394, 0.93567325]), 'split4_test_score': array([0.28496283, 0.54958736, 0.76029536, 0.8823003 , 0.91004134,
0.92396112, 0.76498543, 0.90173034, 0.92393124, 0.93143822,
0.93352341, 0.93492248, 0.88570397, 0.92331548, 0.9307633 ,
0.93378324, 0.93464401, 0.93540764, 0.91073014, 0.92823403,
0.93259306, 0.93435349, 0.93502704, 0.93561031, 0.91849981,
0.93000466, 0.93288866, 0.93428614, 0.93477511, 0.93522242]), 'mean_test_score': array([0.28447483, 0.54887197, 0.75967389, 0.88211782, 0.91008231,
0.92406378, 0.7645514 , 0.90146286, 0.92410552, 0.93167058,
0.93376493, 0.93515365, 0.88526213, 0.92368615, 0.93124573,
0.93422126, 0.93510148, 0.93584588, 0.91070991, 0.92848339,
0.93291001, 0.93474594, 0.93535676, 0.93591448, 0.91877793,
0.93050501, 0.93338988, 0.93471711, 0.93522707, 0.93571059]), 'std_test_score': array([0.00027289, 0.00048629, 0.00057283, 0.000543 , 0.00034602,
0.00027679, 0.00044094, 0.00045743, 0.00024232, 0.00021868,
0.00022569, 0.00024475, 0.00045591, 0.00040693, 0.00038279,
0.00033398, 0.00033383, 0.0003481 , 0.0007108 , 0.00044581,
0.00032355, 0.0003724 , 0.00033574, 0.00032033, 0.00042761,
0.0003521 , 0.00026616, 0.00026972, 0.00028002, 0.00030113]), 'rank_test_score': array([30, 29, 28, 26, 23, 19, 27, 24, 18, 14, 11, 6, 25, 20, 15, 10, 7,
2, 22, 17, 13, 8, 4, 1, 21, 16, 12, 9, 5, 3])}模型三次调优:
acc_lst = []
loss_lst = []
n_estimators_lst = [50, 100, 300, 500, 1000]
for n in n_estimators_lst:
lgbmr = lgbm.LGBMRegressor(boosting_type="gbdt", num_leaves=31,
max_depth=5, learning_rate=0.1,n_estimators=n,
min_child_samples=20, n_jobs=-1, device="gpu")
lgbmr.fit(x_train, y_train, eval_set=[(x_test, y_test)], eval_metric="l1", callbacks=[early_stopping(5)])
y_pred = lgbmr.predict(x_test)
acc = lgbmr.score(x_test, y_test)
loss = mean_absolute_error(y_test, y_pred)
acc_lst.append(acc)
loss_lst.append(loss)
print(f"[n_estimators = {n}] LGBMRegressor 模型准确率为:{acc*100:.4f}%")
print(f"[n_estimators = {n}] LGBMRegressor 模型损失为:{loss:.4f}\r\n")
接下来可以调整 max_depth 参数:
acc_lst = []
loss_lst = []
max_depth_lst = [1, 3, 5, 7, 9, 11]
for n in max_depth_lst:
lgbmr = lgbm.LGBMRegressor(boosting_type="gbdt", num_leaves=31,
max_depth=n, learning_rate=0.1,n_estimators=1000,
min_child_samples=20, n_jobs=-1, device="gpu")
lgbmr.fit(x_train, y_train, eval_set=[(x_test, y_test)], eval_metric="l1", callbacks=[early_stopping(5)])
y_pred = lgbmr.predict(x_test)
acc = lgbmr.score(x_test, y_test)
loss = mean_absolute_error(y_test, y_pred)
acc_lst.append(acc)
loss_lst.append(loss)
print(f"[max_depth = {n}] LGBMRegressor 模型准确率为:{acc*100:.4f}%")
print(f"[max_depth = {n}] LGBMRegressor 模型损失为:{loss:.4f}\r\n")
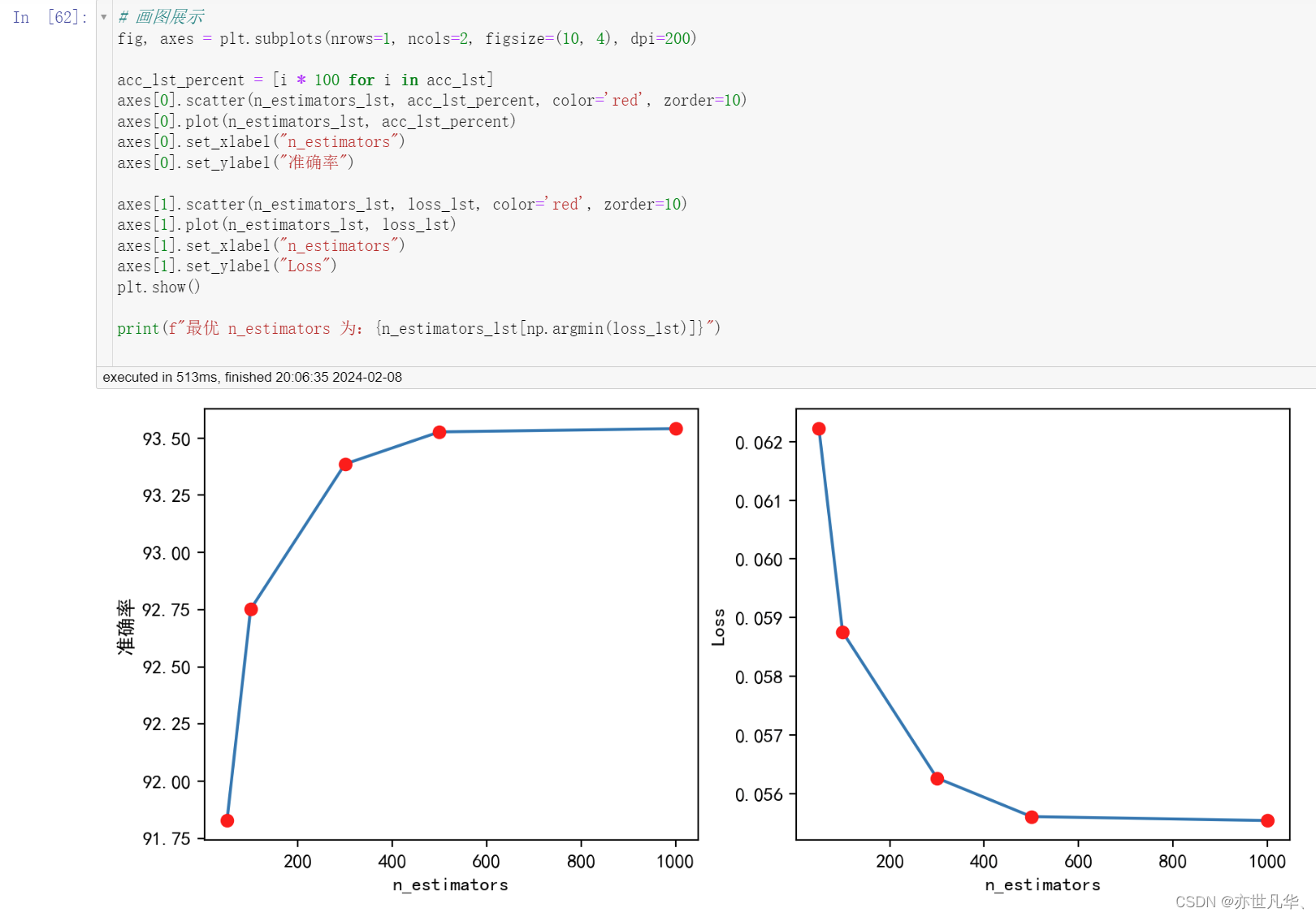
# 绘图展示结果
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(10, 4), dpi=200)
acc_lst_percent = [i * 100 for i in acc_lst]
axes[0].scatter(max_depth_lst, acc_lst_percent, color='red', zorder=10)
axes[0].plot(max_depth_lst, acc_lst_percent)
axes[0].set_xlabel("max_depth")
axes[0].set_ylabel("准确率")
axes[1].scatter(max_depth_lst, loss_lst, color='red', zorder=10)
axes[1].plot(max_depth_lst, loss_lst)
axes[1].set_xlabel("max_depth")
axes[1].set_ylabel("Loss")
plt.show()
print(f"最优 max_depth 为:{max_depth_lst[np.argmin(loss_lst)]}")
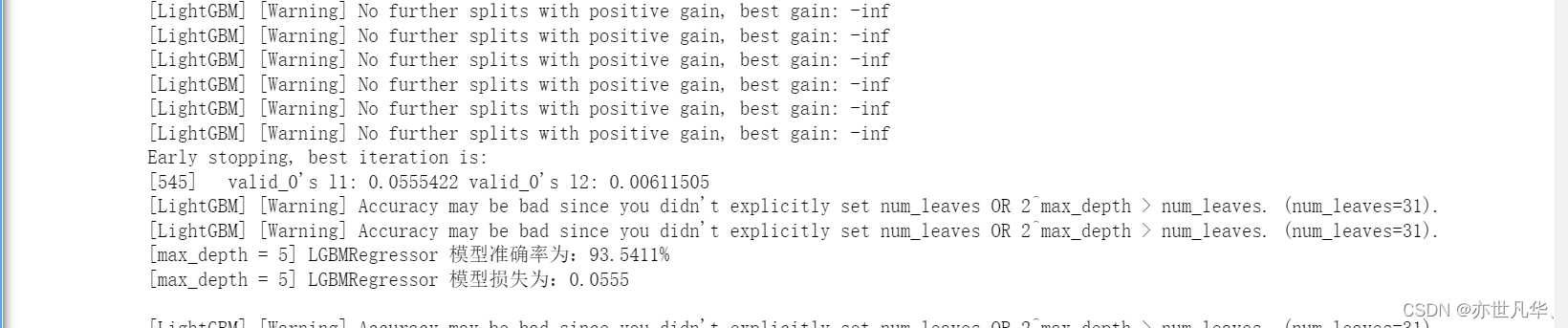
最佳模型性能如下:
best_model = lgbm.LGBMRegressor(boosting_type="gbdt", num_leaves=31,
max_depth=7, learning_rate=0.10, n_estimators=1000,
min_child_samples=20, n_jobs=-1, device="gpu")
best_model.fit(x_train, y_train, eval_set=[(x_test, y_test)], eval_metric="l1", callbacks=[early_stopping(5)])
y_pred = best_model.predict(x_test)
acc = best_model.score(x_test, y_test)
loss = mean_absolute_error(y_test, y_pred)
acc_lst.append(acc)
loss_lst.append(loss)
print(f"LGBMRegressor 最佳模型准确率为:{acc*100:.4f}%")
print(f"LGBMRegressor 最佳模型损失为:{loss:.4f}\r\n")
# 结果如下
Training until validation scores don't improve for 5 rounds
Early stopping, best iteration is:
[729] valid_0's l1: 0.0550691 valid_0's l2: 0.00599729
LGBMRegressor 最佳模型准确率为:93.6428%
LGBMRegressor 最佳模型损失为:0.0551模型调优两种方式对比:在上面的代码中,我们在循环中对不同的参数进行了调优。在每次循环中,您都使用了一个不同的单一参数值来训练一个 LGBMRegressor 模型,并计算了模型的准确率和损失。
这种方法比使用 GridSearchCV 快,是因为我们只调整了一个参数,而且只尝试了 有限个 个不同的值。相比之下,GridSearchCV 会对多个参数进行调优,并且会尝试每个参数的所有可能值。因此,使用 GridSearchCV 需要更多的计算。
但是,我们需要注意的是,这种方法只能调整一个参数,而且只能尝试有限个值。如果我们想要同时调整多个参数,并且尝试更多的值,那么使用 GridSearchCV 或其他自动调参方法可能会更方便。
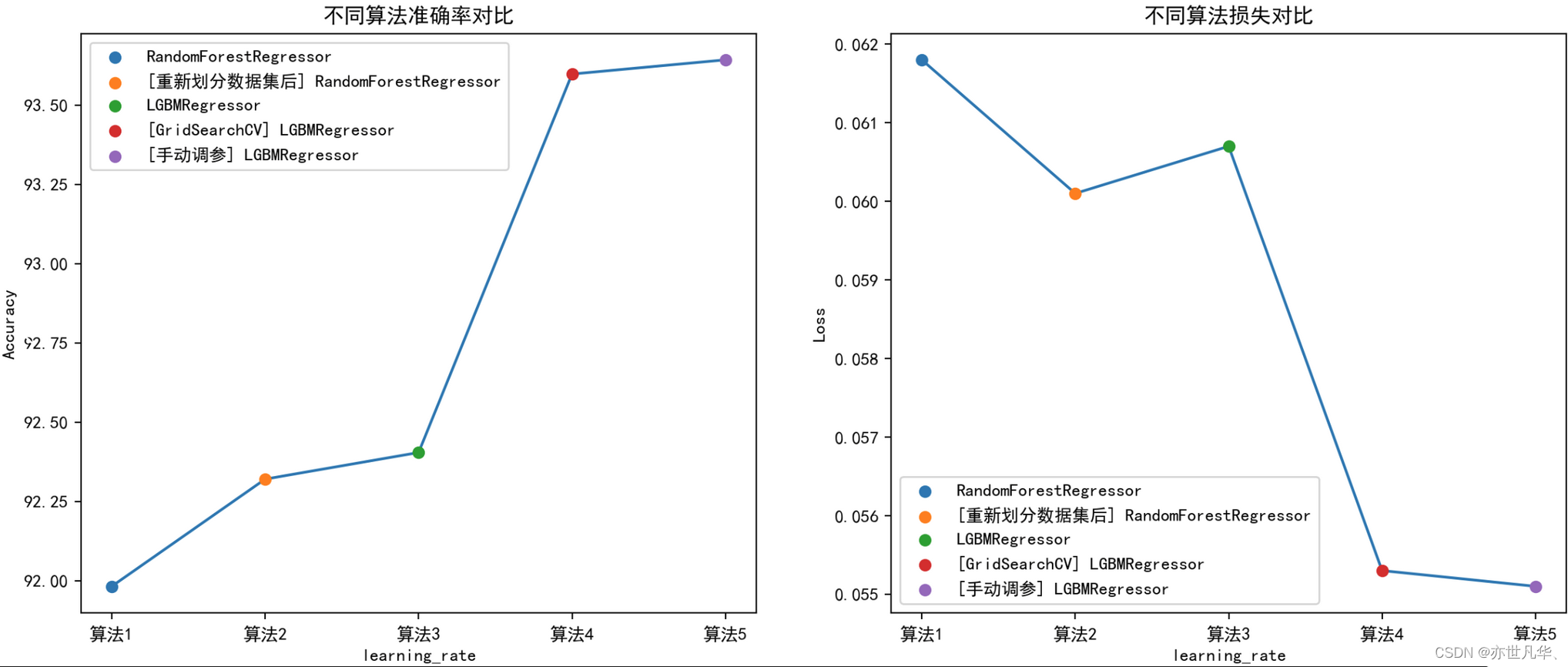
algorithm_names = ["RandomForestRegressor", "[重新划分数据集后] RandomForestRegressor", "LGBMRegressor", "[GridSearchCV] LGBMRegressor", "[手动调参] LGBMRegressor"]
x_label = [f"算法{i}" for i in range(1, len(algorithm_names) + 1)]
accs = [91.9824, 92.3205, 92.4044, 93.5980, 93.6428]
losses = [0.0618, 0.0601, 0.0607, 0.0553, 0.0551]
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(15, 6), dpi=200)
for x, y, label in zip(x_label, accs, algorithm_names):
axes[0].scatter(x, y, zorder=10, label=label)
axes[0].plot(x_label, accs)
axes[0].set_xlabel("learning_rate")
axes[0].set_ylabel("Accuracy")
axes[0].set_title("不同算法准确率对比")
axes[0].legend()
for x, y, label in zip(x_label, losses, algorithm_names):
axes[1].scatter(x, y, zorder=10, label=label)
axes[1].plot(x_label, losses)
axes[1].set_xlabel("learning_rate")
axes[1].set_ylabel("Loss")
axes[1].set_title("不同算法损失对比")
axes[1].legend()
plt.show()