NLP入门系列—词嵌入 Word embedding
NLP入门系列—词嵌入 Word embedding
2013年,Word2Vec横空出世,自然语言处理领域各项任务效果均得到极大提升。自从Word2Vec这个神奇的算法出世以后,导致了一波嵌入(Embedding)热,基于句子、文档表达的word2vec、doc2vec算法,基于物品序列的item2vec算法,基于图模型的图嵌入技术相继诞生。
现有的机器学习方法往往无法直接处理文本数据,因此需要找到合适的方法,将文本数据转换为数值型数据,由此引出了Word Embedding(词嵌入)的概念。
词嵌入是自然语言处理(NLP)中语言模型与表征学习技术的统称,它是NLP里的早期预训练技术。它是指把一个维数为所有词的数量的高维空间嵌入到一个维数低得多的连续向量空间中,每个单词或词组被映射为实数域上的向量,这也是分布式表示:向量的每一维度都没有实际意义,而整体代表一个具体概念。
文本表示
文本是一种非结构化的数据信息,是不可以直接被计算的。
文本表示的作用就是将这些非结构化的信息转化为结构化的信息,这样就可以针对文本信息做计算,来完成我们日常所能见到的文本分类,情感判断等任务。
‘
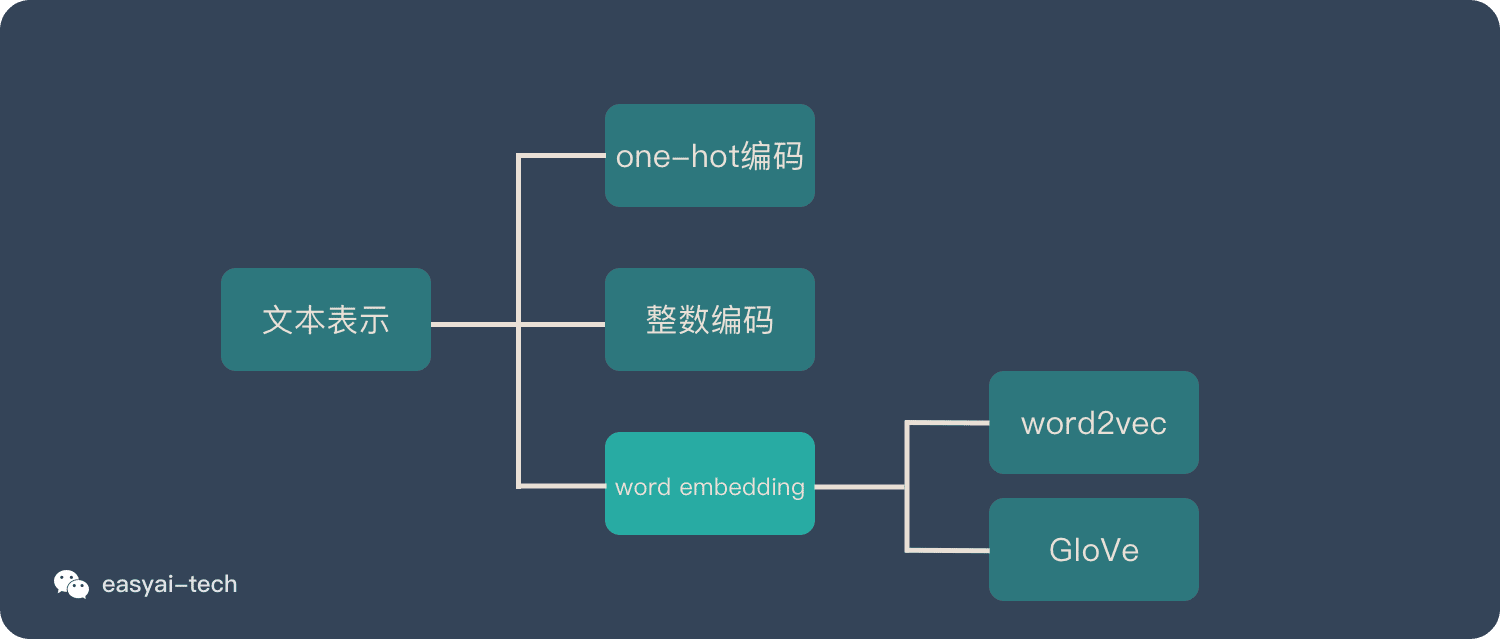
文本表示的方法有很多种,下面只介绍 3 类方式:
- 独热编码 | one-hot representation
- 整数编码
- 词嵌入 | word embedding
’
独热编码 one-hot representation
假如我们要计算的文本中一共出现了4个词:猫、狗、牛、羊。向量里每一个位置都代表一个词。所以用 one-hot 来表示就是:
猫:[1,0,0,0]
狗:[0,1,0,0]
牛:[0,0,1,0]
羊:[0,0,0,1]
’
但是在实际情况中,文本中很可能出现成千上万个不同的词,这时候向量就会非常长。其中99%以上都是 0。
one-hot 的缺点如下:
- 无法表达词语之间的关系
- 这种过于稀疏的向量,导致计算和存储的效率都不高
这里稍微解释一下
- 无法表达词语之间的关系,因为站在向量的角度,我们是可以计算向量之间的距离,one-hot 模式之下,所有的向量之间的距离都一样
- 关于向量过于稀疏,这主要是因为不论向量多长,只有一个位置是非0的
整数编码
这种方式也非常好理解,用一种数字来代表一个词,上面的例子则是:
猫:1
狗:2
牛:3
羊:4
‘
将句子里的每个词拼起来就是可以表示一句话的向量。
整数编码的缺点如下:
- 无法表达词语之间的关系
- 对于模型解释而言,整数编码可能具有挑战性。
什么是词嵌入 word embedding
word embedding 是文本表示的一类方法。跟 one-hot 编码和整数编码的目的一样,不过他有更多的优点。
词嵌入并不特指某个具体的算法,跟上面2种方式相比,这种方法有几个明显的优势:
- 可以将文本通过一个低维向量来表达,不像 one-hot 那么长。
- 语意相似的词在向量空间上也会比较相近。
- 通用性很强,可以用在不同的任务中。
’
目前有两种主流的 word embedding 算法
‘
Word2vec
这是一种基于统计方法来获得词向量的方法,他是 2013 年由谷歌的 Mikolov 提出了一套新的词嵌入方法。
Word2vec,是一群用来产生词向量的相关模型。这些模型为浅而双层的神经网络,用来训练以重新建构语言学之词文本。网络以词表现,并且需猜测相邻位置的输入词,在word2vec中词袋模型假设下,词的顺序是不重要的。训练完成之后,word2vec模型可用来映射每个词到一个向量,可用来表示词对词之间的关系,该向量为神经网络之隐藏
这种算法有2种训练模式:
- 通过上下文来预测当前词
- 通过当前词来预测上下文
Word2vec 是 Word Embedding 方式之一,属于 NLP 领域,是将词转化为「可计算」「结构化」的向量的过程,这种方式在 2018 年之前比较主流,但是随着 BERT、GPT2.0 的出现,这种方式已经不算效果最好的方法了。
在说明 Word2vec 之前,需要先解释一下 Word Embedding。 它就是将「不可计算」「非结构化」的词转化为「可计算」「结构化」的向量。
将现实问题转化为数学问题只是第一步,后面还需要求解这个数学问题。所以 Word Embedding 的模型本身并不重要,重要的是生成出来的结果——词向量。因为在后续的任务中会直接用到这个词向量。
Word2vec 的 2 种训练模式
CBOW(Continuous Bag-of-Words Model)和Skip-gram (Continuous Skip-gram Model),是Word2vec 的两种训练模式。下面简单做一下解释:
CBOW
通过上下文来预测当前值。相当于一句话中扣掉一个词,让你猜这个词是什么。
’
Skip-gram
用当前词来预测上下文。相当于给你一个词,让你猜前面和后面可能出现什么词。
‘
优化方法
为了提高速度,Word2vec 经常采用 2 种加速方式:
- Negative Sample(负采样)
- Hierarchical Softmax
Word2vec 的优缺点
需要说明的是:Word2vec 是上一代的产物(18 年之前), 18 年之后想要得到最好的效果,已经不使用 Word Embedding 的方法了,所以也不会用到 Word2vec。
优点:
- 由于 Word2vec 会考虑上下文,跟之前的 Embedding 方法相比,效果要更好(但不如 18 年之后的方法)
- 比之前的 Embedding方 法维度更少,所以速度更快
- 通用性很强,可以用在各种 NLP 任务中

缺点:
- 由于词和向量是一对一的关系,所以多义词的问题无法解决。
- Word2vec 是一种静态的方式,虽然通用性强,但是无法针对特定任务做动态优化

GloVe
GloVe 是对 Word2vec 方法的扩展,它将全局统计和 Word2vec 的基于上下文的学习结合了起来。
GloVe的全称叫Global Vectors for Word Representation,它是一个基于全局词频统计(count-based & overall statistics)的词表征(word representation)工具,它可以把一个单词表达成一个由实数组成的向量,这些向量捕捉到了单词之间一些语义特性,比如相似性(similarity)、类比性(analogy)等。我们通过对向量的运算,比如欧几里得距离或者cosine相似度,可以计算出两个单词之间的语义相似性。
GloVe是如何实现的
GloVe的实现分为以下三步:
-
根据语料库(corpus)构建一个共现矩阵(Co-ocurrence Matrix)𝑋(什么是共现矩阵),矩阵中的每一个元素𝑋𝑖𝑗代表单词𝑖和上下文单词𝑗在特定大小的上下文窗口(context window)内共同出现的次数。
一般而言,这个次数的最小单位是1,但是GloVe不这么认为:它根据两个单词在上下文窗口的距离𝑑,提出了一个衰减函数(decreasing weighting):𝑑𝑒𝑐𝑎𝑦=1/𝑑
用于计算权重,也就是说距离越远的两个单词所占总计数(total count)的权重越小
In all cases we use a decreasing weighting function, so that word pairs that are d words apart contribute 1/d to the total count.
-
构建词向量(Word Vector)和共现矩阵(Co-ocurrence Matrix)之间的近似关系,论文的作者提出以下的公式可以近似地表达两者之间的关系:
(1)𝑤𝑖𝑇𝑤𝑗+𝑏𝑖+𝑏𝑗=log(𝑋𝑖𝑗)
其中,**𝑤𝑖𝑇和𝑤𝑗是我们最终要求解的词向量;**𝑏𝑖和𝑏𝑗分别是两个词向量的bias term。
当然你对这个公式一定有非常多的疑问,比如它到底是怎么来的,为什么要使用这个公式,为什么要构造两个词向量𝑤𝑖𝑇和𝑤𝑗~?下文我们会详细介绍。 -
有了公式1之后我们就可以构造它的loss function了:
(2)𝐽=∑𝑖,𝑗=1𝑉𝑓(𝑋𝑖𝑗)(𝑤𝑖𝑇𝑤𝑗+𝑏𝑖+𝑏𝑗–log(𝑋𝑖𝑗))2
这个loss function的基本形式就是最简单的mean square loss,只不过在此基础上加了一个权重函数𝑓(𝑋𝑖𝑗),那么这个函数起了什么作用,为什么要添加这个函数呢?我们知道在一个语料库中,肯定存在很多单词他们在一起出现的次数是很多的(frequent co-occurrences),那么我们希望:
- 1.这些单词的权重要大于那些很少在一起出现的单词(rare co-occurrences),所以这个函数要是非递减函数(non-decreasing);
- 2.但我们也不希望这个权重过大(overweighted),当到达一定程度之后应该不再增加;
- 3.如果两个单词没有在一起出现,也就是𝑋𝑖𝑗=0,那么他们应该不参与到loss function的计算当中去,也就是𝑓(𝑥)要满足𝑓(0)=0
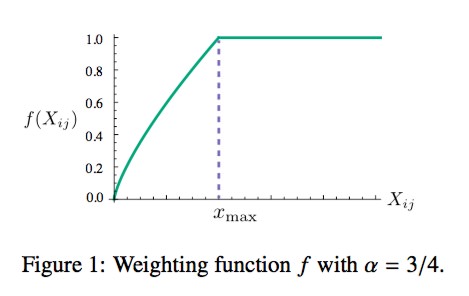
满足以上两个条件的函数有很多,作者采用了如下形式的分段函数:
(3)𝑓(𝑥)={(𝑥/𝑥𝑚𝑎𝑥)𝛼if 𝑥<𝑥𝑚𝑎𝑥1otherwise
这个函数图像如下所示:
’