【Flink入门修炼】1-3 Flink WordCount 入门实现
本篇文章将带大家运行 Flink 最简单的程序 WordCount。先实践后理论,对其基本输入输出、编程代码有初步了解,后续篇章再对 Flink 的各种概念和架构进行介绍。
下面将从创建项目开始,介绍如何创建出一个 Flink 项目;然后从 DataStream 流处理和 FlinkSQL 执行两种方式来带大家学习 WordCount 程序的开发。
Flink 各版本之间变化较多,之前版本的函数在后续版本可能不再支持。跟随学习时,请尽量选择和笔者同版本的 Flink。本文使用的 Flink 版本是 1.13.2。
一、创建项目
在很多其他教程中,会看到如下来创建 Flink 程序的方式。虽然简单方便,但对初学者来说,不知道初始化项目的时候做了什么,如果报错了也不知道该如何排查。
mvn archetype:generate
-DarchetypeGroupId=org.apache.flink
-DarchetypeArtifactId=flink-quickstart-java
-DarchetypeVersion=1.13.2
通过指定 Maven 工程的三要素,即 GroupId、ArtifactId、Version 来创建一个新的工程。同时 Flink 给我提供了更为方便的创建 Flink 工程的方法:
curl https://flink.apache.org/q/quickstart.sh | bash -s 1.13.2
因此,我们手动来创建一个 Maven 项目,看看到底如何创建出一个 Flink 项目。
1、通过 IDEA 创建一个 Maven 项目
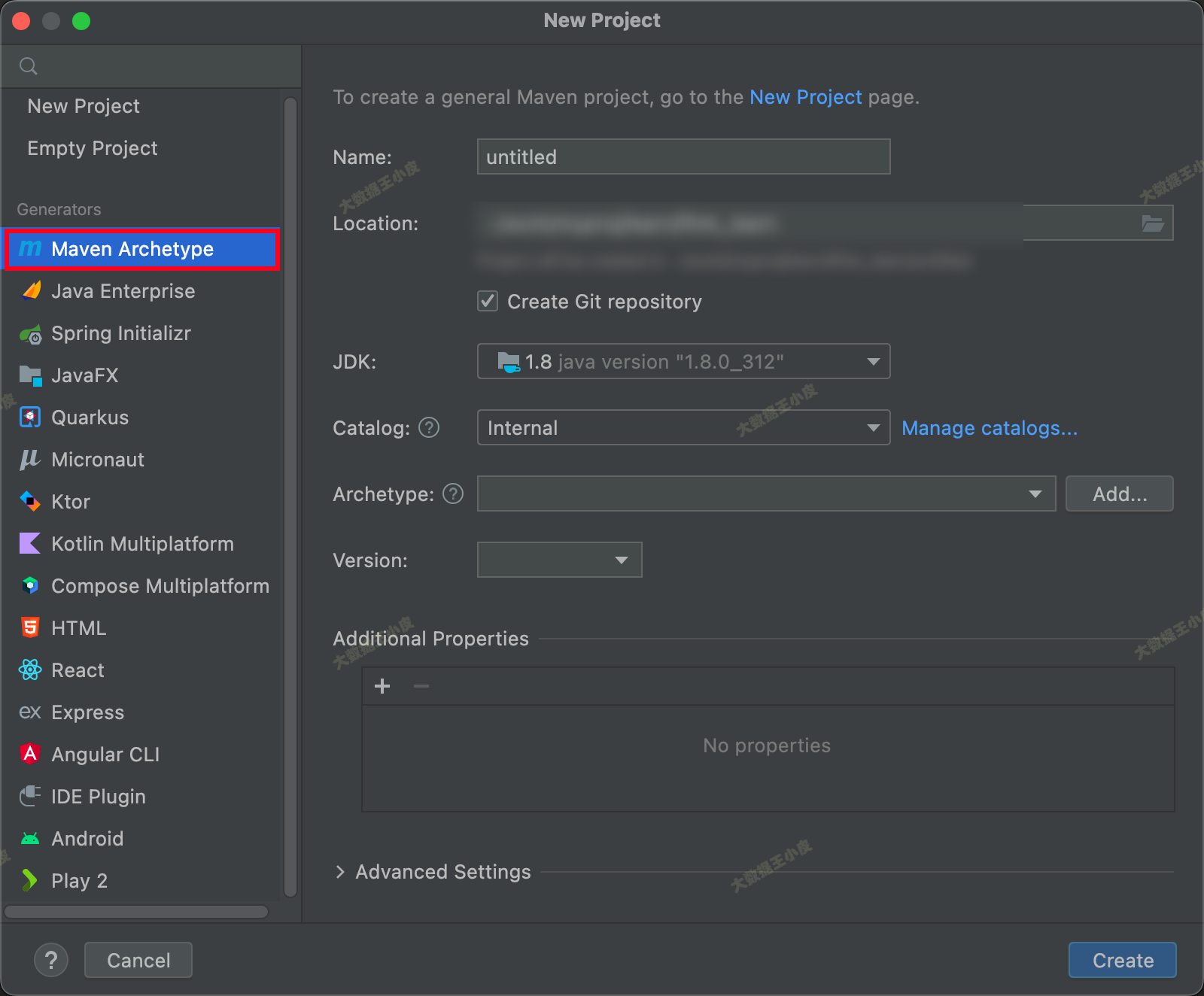
2、pom.xml 添加:
这里我们选择的是 Flink 1.13.2 版本(Flink 1.14 之后部分类和函数有变化,可自行探索)。
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<flink.version>1.13.2</flink.version> <!-- 1.14 之后部分类和函数有变化,可自行探索 -->
<target.java.version>1.8</target.java.version>
<scala.binary.version>2.12</scala.binary.version>
<maven.compiler.source>${target.java.version}</maven.compiler.source>
<maven.compiler.target>${target.java.version}</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>
二、DataStream WordCount
一)编写程序
基础项目环境已经搞好了,接下来我们模仿一个流式环境,监听本地的 Socket 端口,使用 Flink 统计流入的不同单词个数。
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class SocketTextStreamWordCount {
public static void main(String[] args) throws Exception {
//参数检查
if (args.length != 2) {
// System.err.println("USAGE:\nSocketTextStreamWordCount <hostname> <port>");
// return;
args = new String[]{"127.0.0.1", "9000"};
}
String hostname = args[0];
Integer port = Integer.parseInt(args[1]);
// 创建 streaming execution environment
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 获取数据
DataStreamSource<String> stream = env.socketTextStream(hostname, port);
// 计数
SingleOutputStreamOperator<Tuple2<String, Integer>> sum = stream.flatMap(new LineSplitter())
.keyBy(0)
.sum(1);
sum.print();
env.execute("Java WordCount from SocketTextStream Example");
}
public static final class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) {
String[] tokens = s.toLowerCase().split("\\W+");
for (String token: tokens) {
if (token.length() > 0) {
collector.collect(new Tuple2<String, Integer>(token, 1));
}
}
}
}
}
二)测试
接下来我们进行程序测试。
我们在本地使用 netcat 命令启动一个端口:
nc -l 9000
然后启动程序,能看到控制台一些输出:
接下来,在 nc 中输入:
$ nc -l 9000
hello world
flink flink flink
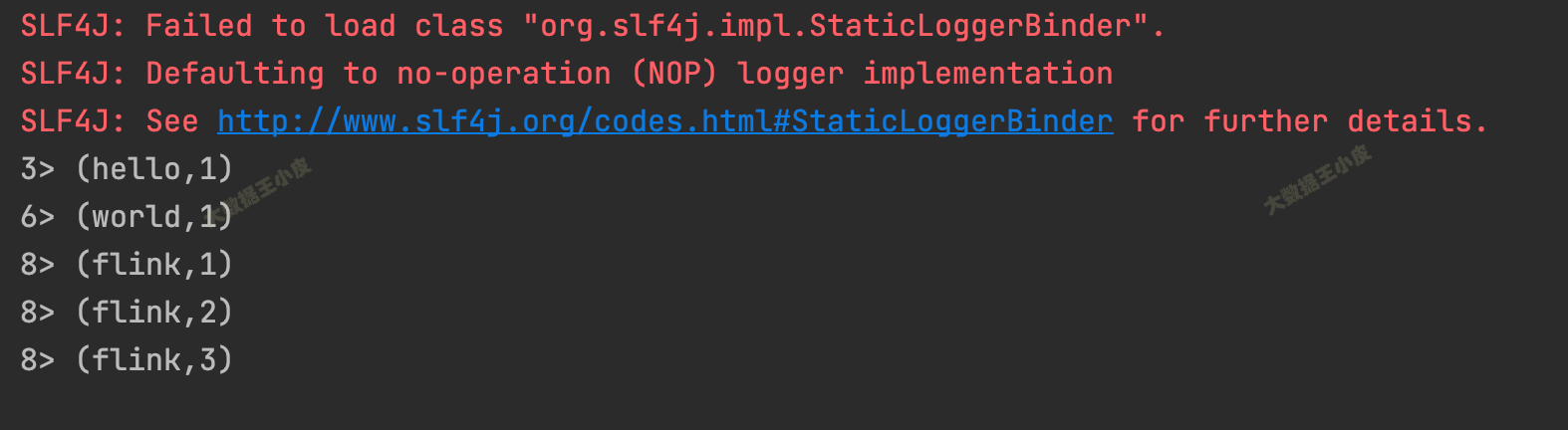
回到我们的程序,能看到统计的输出:
3> (hello,1)
6> (world,1)
8> (flink,1)
8> (flink,2)
8> (flink,3)
三)如果有报错
如果出现执行报错:
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/flink/api/java/io/TextInputFormat
at com.shuofxz.SocketTextStreamWordCount.main(SocketTextStreamWordCount.java:25)
Caused by: java.lang.ClassNotFoundException: org.apache.flink.api.java.io.TextInputFormat
at java.net.URLClassLoader.findClass(URLClassLoader.java:387)
at java.lang.ClassLoader.loadClass(ClassLoader.java:419)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:352)
at java.lang.ClassLoader.loadClass(ClassLoader.java:352)
... 1 more
在 IDE 中把 「Add dependencies with “Provided” scope to classpath」勾选上:

三、Flink Table & SQL WordCount
一)介绍 FlinkSQL
Flink SQL 是 Flink 实时计算为简化计算模型,降低用户使用实时计算门槛而设计的一套符合标准 SQL 语义的开发语言。
上面单词统计的逻辑可以转化为下面的 SQL。
直接来看这个 SQL:
select word as word, sum(frequency) as frequency from WordCount group by word
WordCount是要进行单词统计的表,我们会先做一些处理,将输入的单词都存放到这个表中- 表我们定义为两列
(word, frequency),初始转化输入每个单词占一行,frequency 都是 1 - 然后,就可以按照 SQL 的逻辑来进行统计聚合了。
其中,WordCount 表数据如下:
| word | frequency |
|---|---|
| hello | 1 |
| world | 1 |
| flink | 1 |
| flink | 1 |
| flink | 1 |
那么接下来我们看,如何写一个 FlinkSQL 的程序。
二)环境和程序
首先,添加 FlinkSQL 需要的依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-scala-bridge_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
程序如下:
public class SQLWordCount {
public static void main(String[] args) throws Exception {
// 创建上下文环境
ExecutionEnvironment fbEnv = ExecutionEnvironment.getExecutionEnvironment();
BatchTableEnvironment fbTableEnv = BatchTableEnvironment.create(fbEnv);
// 读取一行模拟数据作为输入
String words = "hello world flink flink flink";
String[] split = words.split("\\W+");
ArrayList<WC> list = new ArrayList<>();
for (String word : split) {
WC wc = new WC(word, 1);
list.add(wc);
}
DataSource<WC> input = fbEnv.fromCollection(list);
// DataSet 转 SQL,指定字段名
Table table = fbTableEnv.fromDataSet(input, "word,frequency");
table.printSchema();
// 注册为一个表
fbTableEnv.createTemporaryView("WordCount", table);
Table table1 = fbTableEnv.sqlQuery("select word as word, sum(frequency) as frequency from WordCount group by word");
DataSet<WC> ds1 = fbTableEnv.toDataSet(table1, WC.class);
ds1.printToErr();
}
public static class WC {
public String word;
public long frequency;
public WC() {}
public WC(String word, long frequency) {
this.word = word;
this.frequency = frequency;
}
@Override
public String toString() {
return word + ", " + frequency;
}
}
}
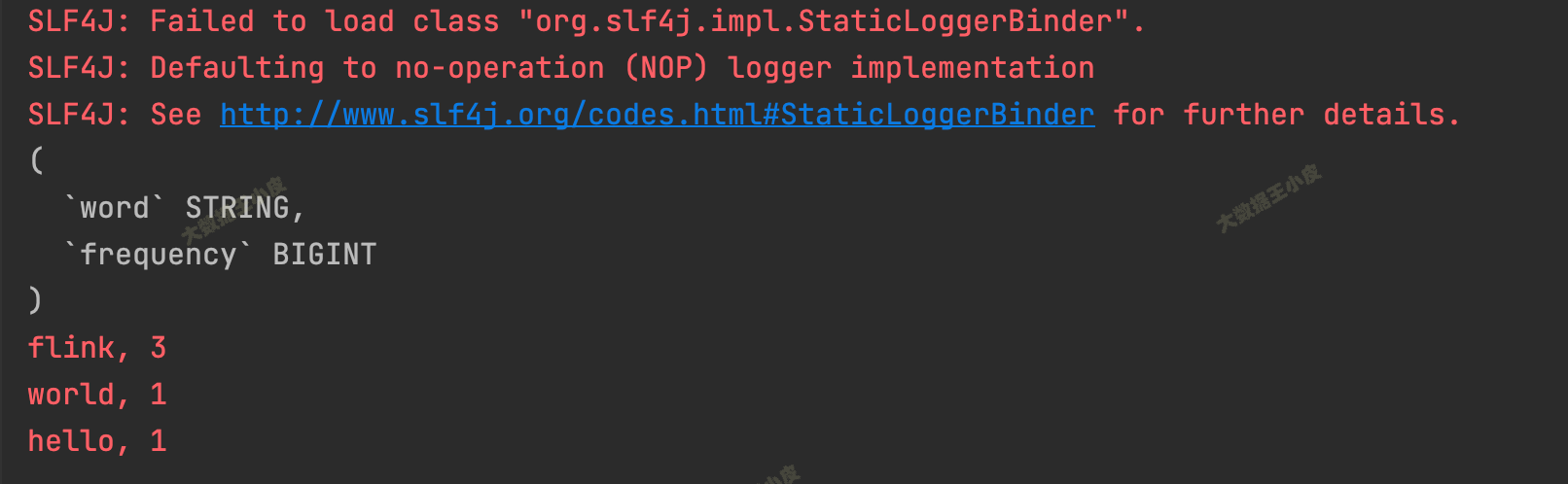
执行,结果输出:
(
`word` STRING,
`frequency` BIGINT
)
flink, 3
world, 1
hello, 1
四、小结
本篇手把手的带大家搭建起 Flink Maven 项目,然后使用 DataStream 和 FlinkSQL 两种方式来学习 WordCount 单词计数这一最简单最经典的 Flink 程序开发。跟着步骤一步步执行下来,大家应该对 Flink 程序基本执行流程有个初步的了解,为后续的学习打下了基础。