Text2SQL研究-Chat2DB体验与剖析
文章目录
-
- 概要
- 业务数据库配置
- Chat2DB安装设置
- 原理剖析
- 小结
概要
近期笔者在做Text2SQL的研究,于是调研了下Chat2DB,基于车辆订单业务做了一些SQL生成验证,有了一点心得,和大家分享一下.:
业务数据库设置
基于车辆订单业务,模拟新建了以下四张表,并添加了一些测试数据
1. organization:组织表,包含组织id,组织名称,组织分类等3个字段;
3. vehicle:车辆信息表,包含组织id,车辆id,车牌号码,使用年限等字段;
4. refueling_order:车辆加油订单表,包含组织id,车辆id,车牌号码,加油时间,加油费用等字段
5. **driven_distance**:车辆行驶里程表,包含组织id,车辆id,车牌号码,年份,行驶里程等字段

Chat2DB安装设置
- docke安装Chat2DB服务,
//通过docker,安装运行最新版本的chat2db容器 docker run --name=chat2db -ti -p 10824:10824 -v ~/.chat2db-docker:/root/.chat2db chat2db/chat2db:latest - 安装完毕:打开链接登录系统,http://172.21.108.51:10824/login

- 配置数据库连接

- 配置Custom Ai,笔者设置体验了Chat2DB以及OpenAI
- 进入WorkSpace页面,连接配置好的业务数据库,并选择里面的的四张业务表(这一步非常重要,否则无法生成准确的SQL语句)

- 进入Dashboard页面,尝试生成SQL语句,并显示图表

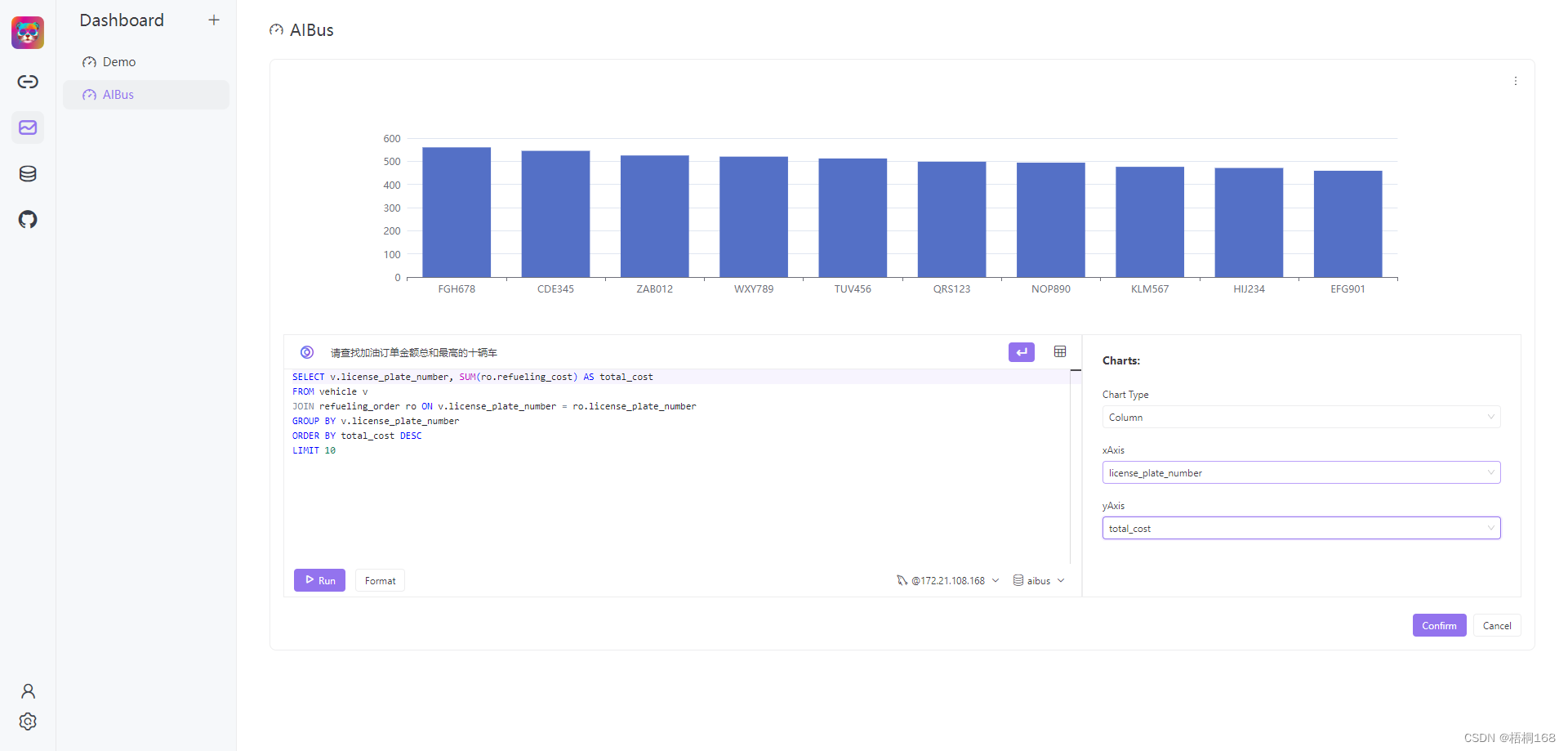
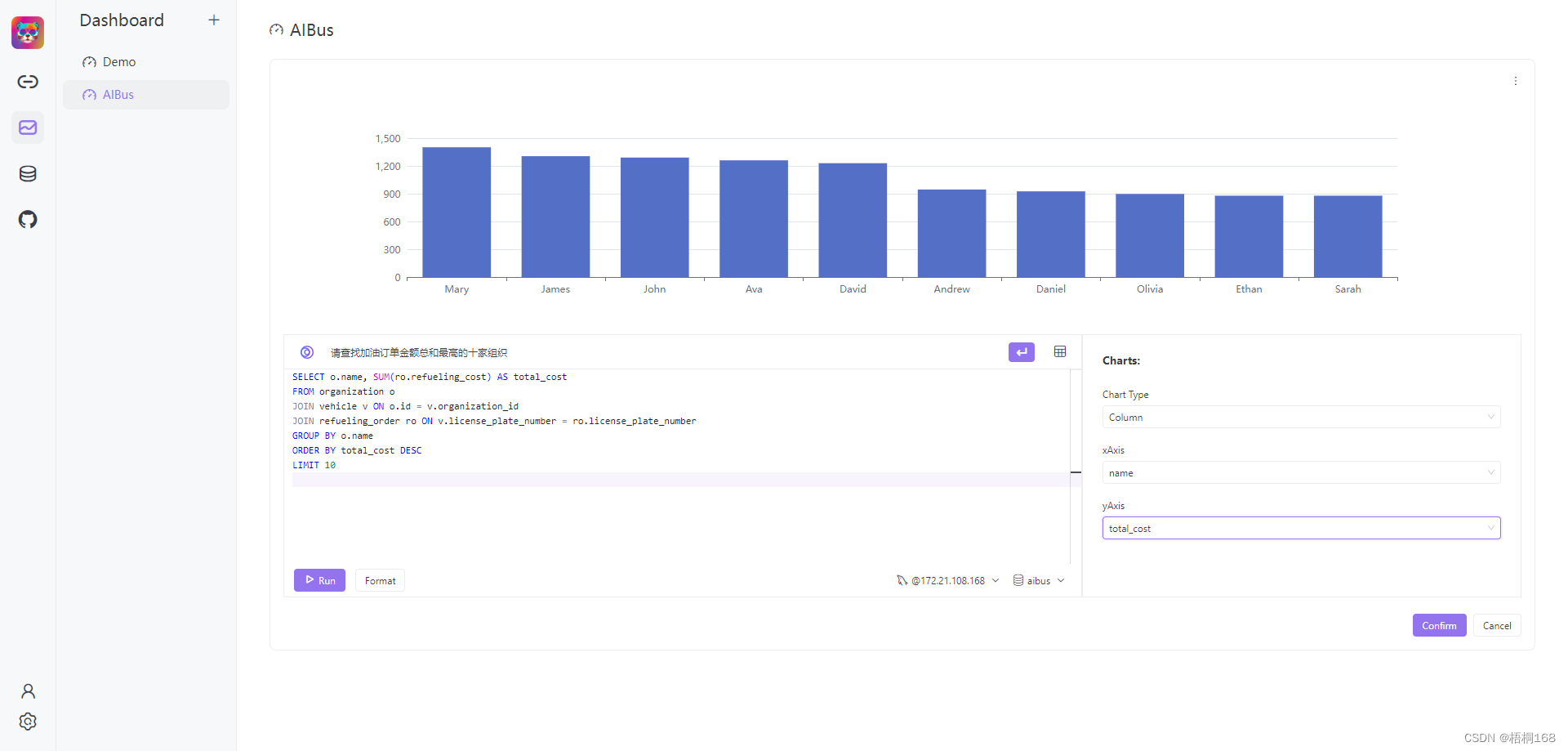

原理剖析
从GIT上下载并剖析源码,最核心的Text-2-SQL生成代码部分:
- ChatController::completions:Controller入口,接受Web端请求,生成SQL,并通过WebSocket返回
/** * SQL转换模型 * * @param queryRequest * @param headers * @return * @throws IOException */ @GetMapping("/chat") @CrossOrigin public SseEmitter completions(ChatQueryRequest queryRequest, @RequestHeader Map<String, String> headers) throws IOException { //默认30秒超时,设置为0L则永不超时 SseEmitter sseEmitter = new SseEmitter(CHAT_TIMEOUT); String uid = headers.get("uid"); if (StrUtil.isBlank(uid)) { throw new ParamBusinessException("uid"); } //提示消息不得为空 if (StringUtils.isBlank(queryRequest.getMessage())) { throw new ParamBusinessException("message"); } return distributeAISql(queryRequest, sseEmitter, uid); } - distributeAISql:根据请求语句,以及系统的Custom AI设置进行SQL生成
/** * distribute with different AI * * @return */ public SseEmitter distributeAISql(ChatQueryRequest queryRequest, SseEmitter sseEmitter, String uid) throws IOException { ConfigService configService = ApplicationContextUtil.getBean(ConfigService.class); Config config = configService.find(RestAIClient.AI_SQL_SOURCE).getData(); String aiSqlSource = AiSqlSourceEnum.CHAT2DBAI.getCode(); if (Objects.nonNull(config)) { aiSqlSource = config.getContent(); } AiSqlSourceEnum aiSqlSourceEnum = AiSqlSourceEnum.getByName(aiSqlSource); if (Objects.isNull(aiSqlSourceEnum)) { aiSqlSourceEnum = AiSqlSourceEnum.OPENAI; } uid = aiSqlSourceEnum.getCode() + uid; switch (Objects.requireNonNull(aiSqlSourceEnum)) { case OPENAI : return chatWithOpenAi(queryRequest, sseEmitter, uid); case CHAT2DBAI: return chatWithChat2dbAi(queryRequest, sseEmitter, uid); case RESTAI : case FASTCHATAI: return chatWithFastChatAi(queryRequest, sseEmitter, uid); case AZUREAI : return chatWithAzureAi(queryRequest, sseEmitter, uid); case CLAUDEAI: return chatWithClaudeAi(queryRequest, sseEmitter, uid); case WENXINAI: return chatWithWenxinAi(queryRequest, sseEmitter, uid); case BAICHUANAI: return chatWithBaichuanAi(queryRequest, sseEmitter, uid); case TONGYIQIANWENAI: return chatWithTongyiChatAi(queryRequest, sseEmitter, uid); case ZHIPUAI: return chatWithZhipuChatAi(queryRequest, sseEmitter, uid); } return chatWithOpenAi(queryRequest, sseEmitter, uid); } - chatWithOpenAi:通过选择的业务表结构以及客户的问题生成prompt,来从大模型获取所需的SQL语句
/** * 使用OPENAI SQL接口 * * @param queryRequest * @param sseEmitter * @param uid * @return * @throws IOException */ private SseEmitter chatWithOpenAi(ChatQueryRequest queryRequest, SseEmitter sseEmitter, String uid) throws IOException { String prompt = buildPrompt(queryRequest); if (prompt.length() / TOKEN_CONVERT_CHAR_LENGTH > MAX_PROMPT_LENGTH) { log.error("提示语超出最大长度:{},输入长度:{}, 请重新输入", MAX_PROMPT_LENGTH, prompt.length() / TOKEN_CONVERT_CHAR_LENGTH); throw new ParamBusinessException(); } List<Message> messages = new ArrayList<>(); prompt = prompt.replaceAll("#", ""); log.info(prompt); Message currentMessage = Message.builder().content(prompt).role(Message.Role.USER).build(); messages.add(currentMessage); buildSseEmitter(sseEmitter, uid); OpenAIEventSourceListener openAIEventSourceListener = new OpenAIEventSourceListener(sseEmitter); OpenAIClient.getInstance().streamChatCompletion(messages, openAIEventSourceListener); LocalCache.CACHE.put(uid, JSONUtil.toJsonStr(messages), LocalCache.TIMEOUT); return sseEmitter; } - 最后根据docker日志,可以发现chat2db 的mysql prompt组成,从这里可以发现真相其实并不复杂,整个Chat2DB可以说了除了通用的数据库方面的增删改查,最核心的部分其实就是根据表结构和用户问题生成prompt了

请根据以下table properties和SQL input将自然语言转换成SQL查询. MYSQL SQL tables, with their properties: ["CREATE TABLE `driven_distance` (\n `id` bigint(20) NOT NULL AUTO_INCREMENT,\n `organization_id` bigint(20) DEFAULT NULL,\n `vehicle_id` bigint(20) DEFAULT NULL,\n `license_plate` varchar(255) DEFAULT NULL,\n 。。。"] SQL input: 2023年,每个季度的加油金额各是多少元?
小结
经过测试,通常的业务查询基本上都能准确生成,另外通过上述一路使用和分析,笔者发现Text2SQL的技术几大要点
- 业务简库:跟3D渲染一样,离线渲染用精模,实时渲染用简模。Text2SQL一定要基于业务库做一个“素描”精简库
- 自组Prompt:根据业务上下文所需的库表结构,拼接prompt
- 选择合法靠谱的大模型:ChatGPT4肯定是最好的,但在国内目前商业不合法,大家要根据自己业务进行尝试和选型
- 用户数据权限:通过拦截器,在prompt中加入当前用户ID,组织id等用户信息,从而巧妙实现用户数据权限等问题