【初中生讲机器学习】6. 分类算法中常用的模型评价指标有哪些?here!
创建时间:2024-02-07
最后编辑时间:2024-02-09
作者:Geeker_LStar
你好呀~这里是 Geeker_LStar 的人工智能学习专栏,很高兴遇见你~
我是 Geeker_LStar,一名初三学生,热爱计算机和数学,我们一起加油~!
⭐(●’◡’●) ⭐
那就让我们开始吧!
前面已经讲了两个分类算法(SVM & 朴素贝叶斯),其中在 【初中生讲机器学习】4. 支持向量机算法怎么用?一个实例带你看懂!中我提到 “准确率、召回率等是分类算法中常用的模型评价指标”,但是没有展开讲。so!这一篇咱们就来详细看看,在分类算法中,① 到底有哪些常用的模型评价指标?② 它们分别反映模型哪方面的性能?③ 它们如何利用 sklearn 库进行计算?④ 在实际应用当中,这些指标又该如何选择 and 侧重呢?
文章目录
- 混淆矩阵 Confusion Matrix
- 准确率 Accuracy
- 召回率 Recall
- 精确率 Precision
- F1 值
- ROC 曲线
- AUC 值 Area Under Curve
- PR 曲线
混淆矩阵 Confusion Matrix
混淆矩阵,听上去好酷噢,但其实并没有,它很简单的(但同时它也很重要)。
well,我们假设现在有一个二分类程序,A 为正样本集,B 为负样本集。那么对于一个样本,它可能的情况就四种:
- 属于 A,被分类为 A(实际为正样本,预测为正样本,True Positive,记作 TP)
- 属于 A,被分类为 B(实际为正样本,预测为负样本,False Negative,记作 FN)
- 属于 B,被分类为 A(实际为负样本,预测为正样本,False Positive,记作 FP)
- 属于 B,被分类为 B(实际为负样本,预测为负样本,记作 True Negative,记作 TN)
混淆矩阵可以看成一个表格,罗列了以上四种情况的样本数量。
| 预测为正类 | 预测为负类
————————|—————————|—————————
实际为正类 | TP | FN
————————|—————————|—————————
实际为负类 | FP | TN
给一个例子,下面的计算中会用到这些数据。
| 预测为正 | 预测为负
————————|—————————|—————————
实际为正 | 1320 | 218
————————|—————————|—————————
实际为负 | 520 | 1102
务必熟悉混淆矩阵。有了它,我们可以计算出准确率、精确率、召回率、F1 等多个指标。
ok,带上混淆矩阵,走起!
准确率 Accuracy
好,先从最简单的准确率讲起。
准确率嘛,就是所有被分类正确的(TP 和 TN)样本量除以样本总量,即:
A
c
c
u
r
a
c
y
=
T
P
+
T
N
T
P
+
F
N
+
F
P
+
T
N
Accuracy = \frac{TP+TN}{TP+FN+FP+TN}
Accuracy=TP+FN+FP+TNTP+TN
比如上面的那个例子,准确率就是 1320 + 1102 1320 + 1102 + 520 + 218 ≈ 76.6 % \frac{1320+1102}{1320+1102+520+218} ≈ 76.6\% 1320+1102+520+2181320+1102≈76.6%
在所有的指标中,可以说准确率是最容易理解的(也很常用的),它的值介于 0-1,越接近 1 表示模型的性能越好。
但是,准确率也有一些缺陷,尤其是在正负样本数量不平衡的时候。比如,现在有 20% 的正样本和 80% 的负样本,就算我直接让模型全部回答 “负样本”,准确率都能达到 80%,但是这个模型其实根本不会分类(或者说它的泛化能力很弱)。and,准确率只能告诉我们 “模型分类错误了多少”,但它不会告诉我们具体是 “把正样本分成负样本了” 还是 “把负样本分成正样本了”,也就是说,准确率无法区分不同类别之间的错误分类,对于模型的缺陷无法提供详细的分析。
不过,绝大多数情况下,准确率还是很能反映模型的整体性能的。在 sklearn 库中,我们可以使用 accuracy_score() 来计算准确率:
# 通过 sklearn 库计算准确率
from sklearn.metrics import accuracy_score
# 获取并划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=218)
# 以支持向量机为例
svm = svm.SVC(kernel="rbf", C=1, gamma="auto", probability=True)
svm.fit(X_train, y_train) # 训练
y_predict = svm.predict(X_test) # 预测(测试)
print("支持向量机准确率:", accuracy_score(y_test, y_predict))
召回率 Recall
一句话:提高召回率是为了 “不漏报”,让模型尽量找全所有的正样本,哪怕把一些负样本错分成正样本了也没关系。
(召回率也叫查全率,后者似乎更好理解一些~)
如果说准确率是针对 “全体数据”,那么召回率就是针对 “正样本”。召回率等于 “被分类正确的正样本数量(TP)” 除以 “正样本总量(TP+FN)”,即:
R
e
c
a
l
l
=
T
P
T
P
+
F
N
Recall = \frac{TP}{TP+FN}
Recall=TP+FNTP
召回率的范围也在 0-1,召回率越接近 1 说明模型对正样本越敏感,漏掉正样本的概率就越小,越能做到 “不漏报”。
前面讲过,准确率在正负样本不平衡的时候会有所偏差,但召回率可以在一定程度上弥补这种偏差(因为它只关注正样本)。比如我下一篇会写的基于朴素贝叶斯算法的垃圾邮件分类器就是一个正负样本不平衡的例子,在评价那个模型的时候,我同时用了准确率、召回率和精确率三个指标。
那么,什么时候应该重点关注召回率呢?很明显嘛,对 “不要漏掉正样本(不漏报)” 的要求越高,就越要关注召回率。比如医院对某种很严重的病的检查(患病是正样本),肯定要抱着 “宁可错判一千不肯放过一个” 的心态去啊,毕竟得了重病却以为自己没得的后果可比虚惊一场严重多了。在这种情况下,召回率就显得比准确率和精确率(后面会讲)更重要了,召回率 100% 精确率 80% 比召回率 90% 精确率 97% 好很多。
在 sklearn 库中,我们可以使用 recall_score() 来计算召回率:
# 通过 sklearn 库计算召回率(查全率)
from sklearn.metrics import recall_score
# 获取并划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=218)
# 以支持向量机为例
svm = svm.SVC(kernel="rbf", C=1, gamma="auto", probability=True)
svm.fit(X_train, y_train) # 训练
y_proba = svm.predict_proba(X_test)
print("支持向量机召回率:", recall_score(y_test, y_predict, pos_label="1"))
用上面混淆矩阵中的数据,算出的召回率是 1320 1320 + 218 ≈ 85.8 % \frac{1320}{1320+218} ≈ 85.8\% 1320+2181320≈85.8%
精确率 Precision
一句话:提高精确率是为了 “不错报”,让模型做到 “它说是正样本的几乎都是正样本”,哪怕漏掉了一些正样本也没关系。
emmm,精确率,准确率,一字之差,实际上可是差了不少呢。
精确率主要用于衡量模型对于正样本的预测准确程度,计算公式为:“被分类正确的正样本(TP)” 除以 “被分类为正样本的样本总数(TP+FP)”,即:
P
r
e
c
i
s
i
o
n
=
T
P
T
P
+
F
P
Precision = \frac{TP}{TP+FP}
Precision=TP+FPTP
注意,精确率和召回率虽然都是针对正样本,但它们可不一样。召回率可以理解为 “在所有正样本中,模型识别出了多少(不漏报)”,精确率可以理解为 “在被识别成正样本的样本中,有多少的确是正样本(不错报)”。
那么,什么时候应该重点关注精确率?其实很简单,对 “不要把负样本错误分类为正样本(不错报)” 的要求越高,越要关注精确率。比如你刷脸支付(你的脸是正样本,别人的脸是负样本),模型总是识别不出来你的脸而让你多刷几次的情况很常见,但是模型把别人的脸错误地判定为你的脸(and 让你帮那人付钱)的事情几乎不可能。也就是说,人脸识别系统可以接受 “漏报”,但是不能接受 “误报”,这种时候就需要高精确度,而准确率和召回率就相对显得不那么重要了。
在正负样本分布不平衡的时候,精确率也是一个常用的指标,在 sklearn 库中,precision_score() 帮助我们计算精确率:
# 利用 sklearn 计算精确率
from sklearn.metrics import precision_score
# 获取并划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=218)
# 以支持向量机为例
svm = svm.SVC(kernel="rbf", C=1, gamma="auto", probability=True)
svm.fit(X_train, y_train) # 训练
y_predict = svm.predict(X_test) # 预测(测试)
print("支持向量机精确率:", precision_score(y_test, y_predict, pos_label="1"))
用上面混淆矩阵中的数据,算出的精确率是 1320 1320 + 520 ≈ 71.7 % \frac{1320}{1320+520} ≈ 71.7\% 1320+5201320≈71.7%
F1 值
一句话:F1 值是召回率和精确率的调和平均值,能够反映模型的综合性能。
你可能已经发现了——这这这,召回率和精确率难道不是 “此消彼长” 的吗?我提高了其中一个,另一个势必会降低呀,这可咋整呢…
ok 先来解释一下为什么它俩不可兼得。
把两个公式放在一起,方便对比。
召回率
R
e
c
a
l
l
=
T
P
T
P
+
F
N
召回率 Recall = \frac{TP}{TP+FN}
召回率Recall=TP+FNTP
精确率 P r e c i s i o n = T P T P + F P 精确率 Precision = \frac{TP}{TP+FP} 精确率Precision=TP+FPTP
召回率的分母是 “所有正样本”,所以想要让召回率等于 1(其实很少这么苛刻,但是这样后面好表述),必须要把所有正样本都找出来,而为了不漏掉任何一个正样本,模型会倾向于把一些 “具有一两个类似于正样本特征的负样本” 也分为正样本,也就是说,正样本确实都找全了,但代价是一些负样本也被错误地归为正样本了(参考前面医院诊断的例子)。
但是,精确率的分母是 “被分为正样本的样本总量”,当然也包括被错分为正样本的负样本。so 在让召回率趋近于 1 的过程中,精确率的分母会不断变大,那精确率自然会随之变小。
包括从后面会讲的 PR 曲线来看,召回率和精确率确实很难兼顾,具体该侧重谁,还得看具体的需求了。
嗯,不过在很多场景中,召回率和精确率在重要性上并没有明显的区别,我们更希望模型的召回率和精确率是均衡的,也就是模型在对正负样本的预测上都比较不错,这种时候又该怎么衡量呢?
没错,F1 值登场~
F1 值是召回率和精确率的调和平均值,它可以综合反映模型的性能。计算公式:
F
1
=
2
×
r
e
c
a
l
l
×
p
r
e
c
i
s
i
o
n
r
e
c
a
l
l
+
p
r
e
c
i
s
i
o
n
F1 = \frac{2×recall×precision}{recall+precision}
F1=recall+precision2×recall×precision
well,或许需要插播一下用调和平均数有什么好处。换言之,为什么偏要用调和平均数,而不直接用算术平均数?
调和平均数的原始形式是:两个数的倒数的平均数的倒数,即 A、B 的调和平均数是
2
1
A
+
1
B
\frac{2}{\frac{1}{A}+\frac{1}{B}}
A1+B12。
调和平均数对于极端值具有更高的敏感度。因为当数据集中有很小(很大)的值的时候,这个数的倒数会变得很大(很小),so 倒数的平均数会变小(大),使得调和平均数变得比算术平均数更小(大)。但是对于召回率和精确率而言,它们最大也就是 1,所以它们的倒数再小也小不到哪里去(也就是说,不用考虑极大值对调和平均数的影响,但是极小值对调和平均数的影响就很大)。也就是说,想要 F1 的值大,需要召回率和精确率都大才可以,所以 F1 值能够很好地反映模型的整体性能。
在 sklearn 中,我们可以借助 f1_score() 函数来计算 F1 值。
# 利用 sklearn 计算 F1 值
from sklearn.metrics import f1_score
# 获取并划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=218)
# 以支持向量机为例
svm = svm.SVC(kernel="rbf", C=1, gamma="auto", probability=True)
svm.fit(X_train, y_train) # 训练
y_predict = svm.predict(X_test) # 预测(测试)
print("支持向量机 F1 值:", f1_score(y_test, y_predict, pos_label="1"))
ROC 曲线
我们来思考一下,分类器在分类样本的时候,怎么判断这个样本是正是负呢?
yes,分类器通常会先计算出模型属于正样本的概率,如果这个概率大于阈值,则分为正样本,否则分为负样本。
ok 那问题来了,这个 “阈值” 怎么选,才能让分类器的综合性能最好呢?
带着这个问题,我们来看看 ROC 曲线。
ROC 曲线又叫 “受试者工作特征曲线”,被广泛运用在医学和机器学习领域。它的横坐标是假阳性率,false positive rate,简记为 FPR,即把负样本错分为正样本的概率(误诊率);纵坐标是真阳性率,true positive rate,简记为 TPR,即把正样本分对的概率(说白了就是召回率)。
其中,TPR 又被称为灵敏度(真阳性率,sensitive),从医学角度讲,它反映模型 “识别病人” 的能力; 1-FPR 又被称为特异度(真阴性率,specificity),它反映模型 “识别非病人” 的能力。
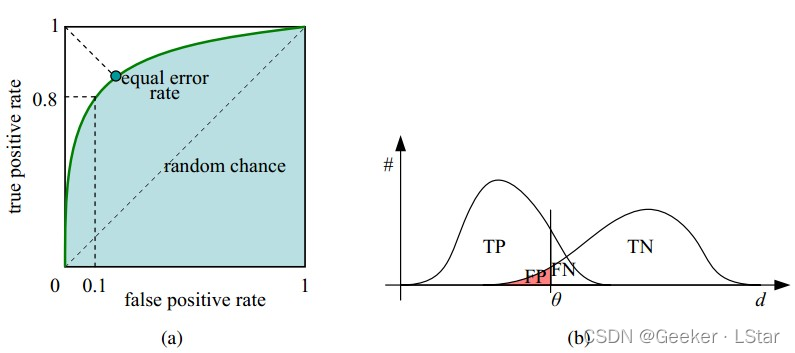
先来看左下角和右上角两点,理解一下 ROC 是怎么工作的。
左下角 TPR 和 FPR 都是 0,这对应把所有样本全部分为负样本,这样就不存在把负样本错分为正样本了,FPR 就是 0 了,但同时所有的正样本都被分错了,所以 TPR 也就是 0 了。
右上角 TPR 和 FPR 都是 1,这对应把所有样本全部分为正样本,这样就不存在把正样本分错的事情了,TPR 就是 1 了,但同时所有负样本都被错分为正样本了,所以 FPR 也就是 1 了。
ROC 曲线是怎么画出来的?
我们假设现有 n 个样本,给出每个样本属于正样本的概率,把这些概率从大到小排序,比如:
| 样本 | 预测的属于正类的概率 | 实际分类 |
|---|---|---|
| 1 | 99.9% | 正 |
| 2 | 72.5% | 正 |
| 3 | 52.1% | 负 |
| 4 | 11.02% | 负 |
| 5 | 2.18% | 负 |
| 6 | 0.01% | 负 |
ok,我们来选取阈值,从 100% 到 0% 这个顺序,所有概率大于等于阈值的样本会被分为正样本,其他被分为负样本。
如果阈值是 100%,那很明显所有样本全部被分为负样本,TPR 为 0,FPR 为 0,对应之前讲过的左下角的点。
如果阈值是 90%,那第一个样本会被分为正样本,其他样本被分为负样本,TPR 为 50%,FPR 为 0。
如果阈值是 50%,那前三个样本会被分为正样本,其它样本被分为负样本,TPR 为 1,FPR 为 25%。
如果阈值是 0%,那所有样本都会被分为正样本,TPR 是 1,FPR 也是 1,对应之前讲过的右上角的点。
简单点概括,ROC 曲线反映出 “不漏诊率(TPR)” 和 “误诊率(FPR)” 随阈值变化的趋势。
emm 由于例子中的样本数很少且数据很主观,阈值的选取间隔也很大,so 如果画图的话会稍显怪异(()不过也能大概看出趋势:随着阈值的下降,TPR 和 FPR 都呈上升趋势,曲线大概长下面这个样子:
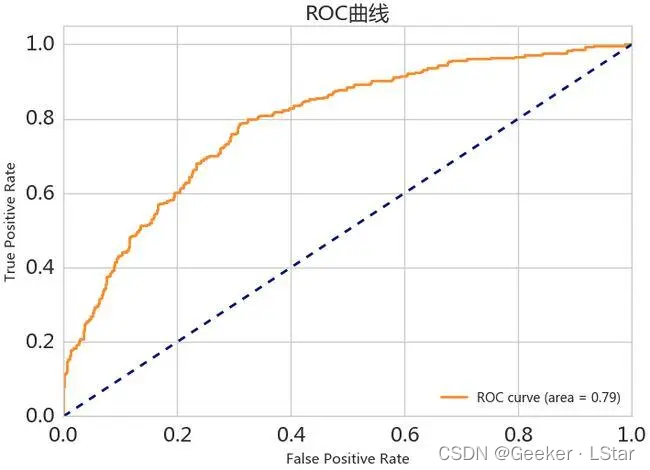
我们想要 TPR 尽量大,FPR 尽量小,也就是说,越靠近左上角(几何距离或约登指数)的点所对应的阈值,就是我们想要的阈值。
当然也有例外,当我们对灵敏度和特异度其中之一有很高的要求(而另一个可以稍微放宽)的时候,阈值的选取就需要综合实际需求来看了(后面有相关例子)。
现在假设我们并不偏重灵敏度或特异度中的哪一个,下图中的红点大致标出了最佳阈值。
至于最佳阈值如何精确计算,我们可以利用约登指数:TPR+TNR-1 = TPR-FPR,即横纵坐标差值最大的点所对应的阈值就是最佳阈值。
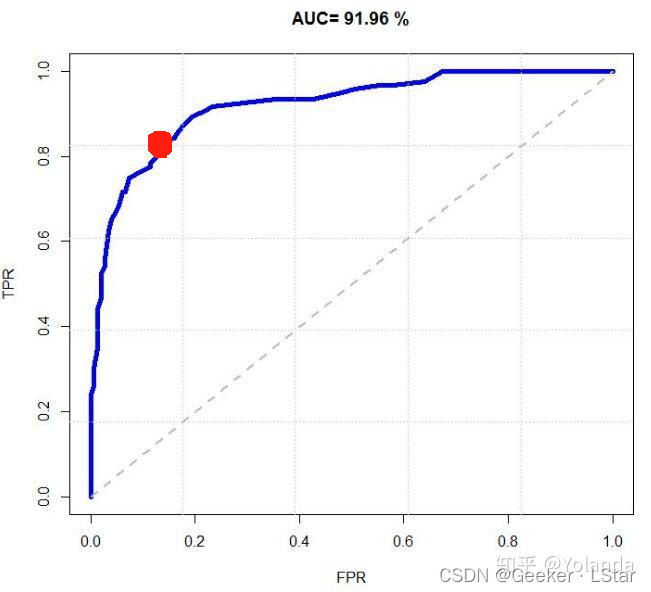
一般而言,ROC 曲线越靠近左上角,说明模型的综合性能越好。ROC 曲线是选取阈值和评价模型性能的重要指标。
利用 sklearn 和 matplotlib,我们可以这样绘制 ROC 曲线:
# 利用 sklearn 和 matplotlib 绘制 ROC 曲线
from sklearn.metrics import roc_curve, roc_auc_score
# 获取并划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=218)
# 以支持向量机为例
svm = svm.SVC(kernel="rbf", C=1, gamma="auto", probability=True)
svm.fit(X_train, y_train) # 训练
score_s = svm.predict_proba(X_test)[:, 1]
#使用 roc_curve 方法得到三个模型的真正率 TP,假正率 FP和阈值 threshold
fpr_s, tpr_s, thres_s = roc_curve(y_test, score_s, pos_label="1")
# 创建画布
fig, ax = plt.subplots(figsize=(10,8))
# 自定义标签名称(使用 AUC 值)
ax.plot(fpr_s,tpr_s,linewidth=2,
label='SVM (AUC={})'.format(str(round(roc_auc_score(y_test, y_proba[:, 1]), 3))))
# 绘制对角线
ax.plot([0,1],[0,1],linestyle='--',color='grey')
# 调整字体大小
plt.legend(fontsize=12)
# 展现画布
plt.show()
AUC 值 Area Under Curve
嗯,AUC 的英文名已经很好地表明它是什么了,Area Under Curve,不就是 ROC 曲线下方的面积嘛。
上面讲过,ROC 曲线越靠近左上角,模型的综合性能越好,比如下面这张图,蓝线对应的模型性能最好;蓝点对应的是最理想的模型(所有样本全部分对),但在实际情况中不存在;对角线(红线)代表随机预测的结果(一半一半),一般不会有比对角线还差的情况。
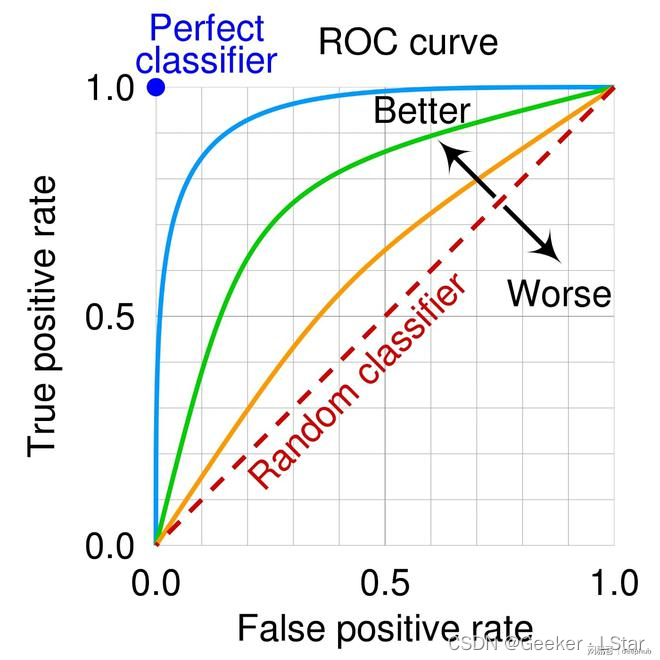
那很明显啦,模型性能越好,ROC 曲线越接近左上角,模型下方的面积就越大。so 我们可以用 AUC 值反推模型性能,即 AUC 越大,模型性能越好。下面这组图形象地反映了不同 AUC 值代表的不同分类性能:
AUC 值为 1 时,对应最理想的模型,此时所有的样本都被分类正确。
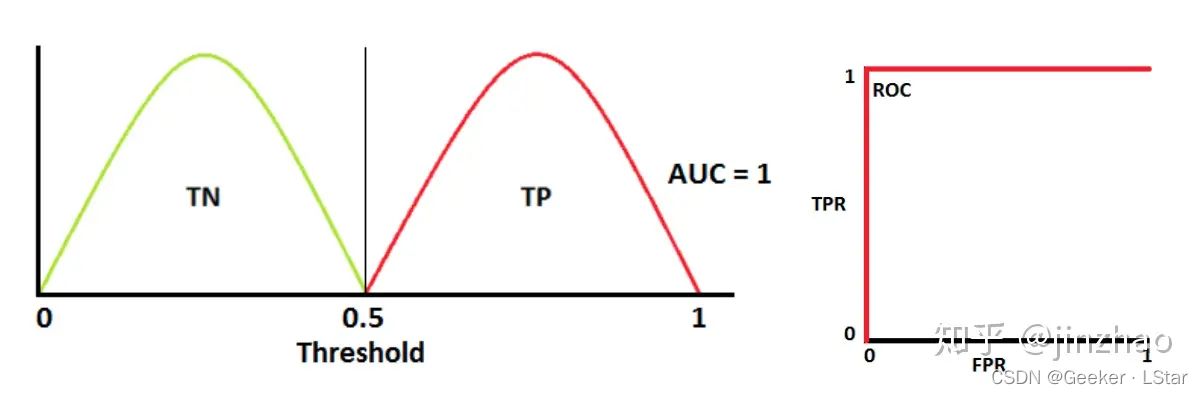
AUC 值为 0.7 时,有一些错误,但比纯猜的效果好。
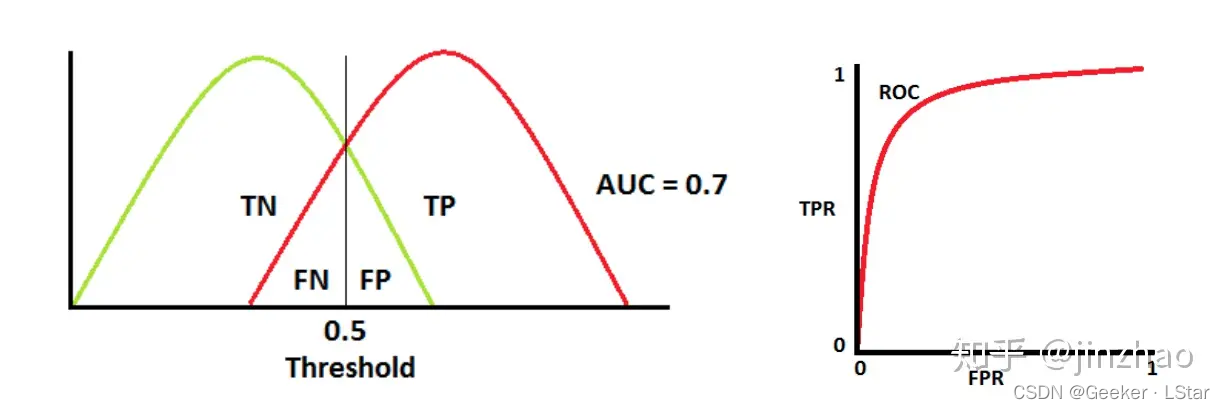
AUC 值为 0.5 时,等于纯猜 (真是的要是选择题让我二分类就好了(( 。
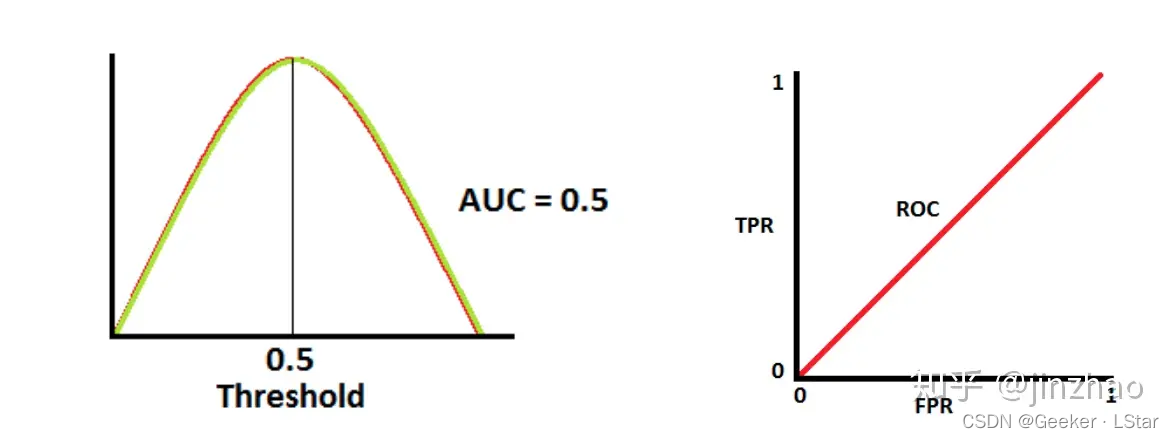
但是,数学知识告诉我们,AUC 值相同,ROC 曲线不一定相同,比如下面这种情况:
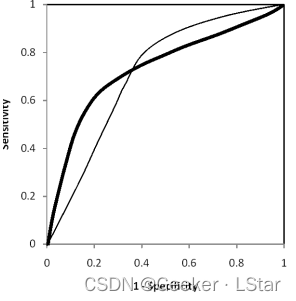
这就涉及到对灵敏度和特异度的侧重程度了(类似于对召回率和精确率的侧重程度),如果更重视灵敏度(sensitive,即 TPR),则下图中的曲线 A 比曲线 B 更好;如果更重视特异度(specificity,即 1-FPR),则下图中的曲线 B 比曲线 A 更好。
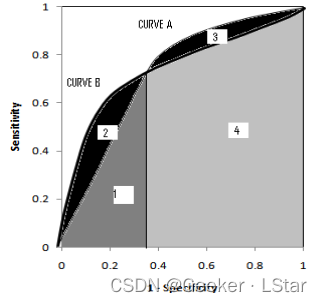
总而言之,AUC 值是衡量模型综合综合性能的重要指标。AUC 值的计算其实在 ROC 那部分代码中已经写过了,这里不再写了~
PR 曲线
嗯,PR 曲线,ROC 曲线的好基友(
ROC 曲线衡量的是灵敏度和特异度之间的关系,PR 曲线则衡量的是召回率和精确率之间的关系。
PR 曲线的横坐标是召回率(TPR),纵坐标是精确率。PR曲线的画法和 ROC 曲线完全相同——从 100% 到 0% 取阈值,计算每个阈值下的召回率和精确率,画出曲线后依据实际需求(不同侧重)选取最合适的阈值。
如果没有明确的侧重需求,可以依据 F1 值选取最适合的阈值。
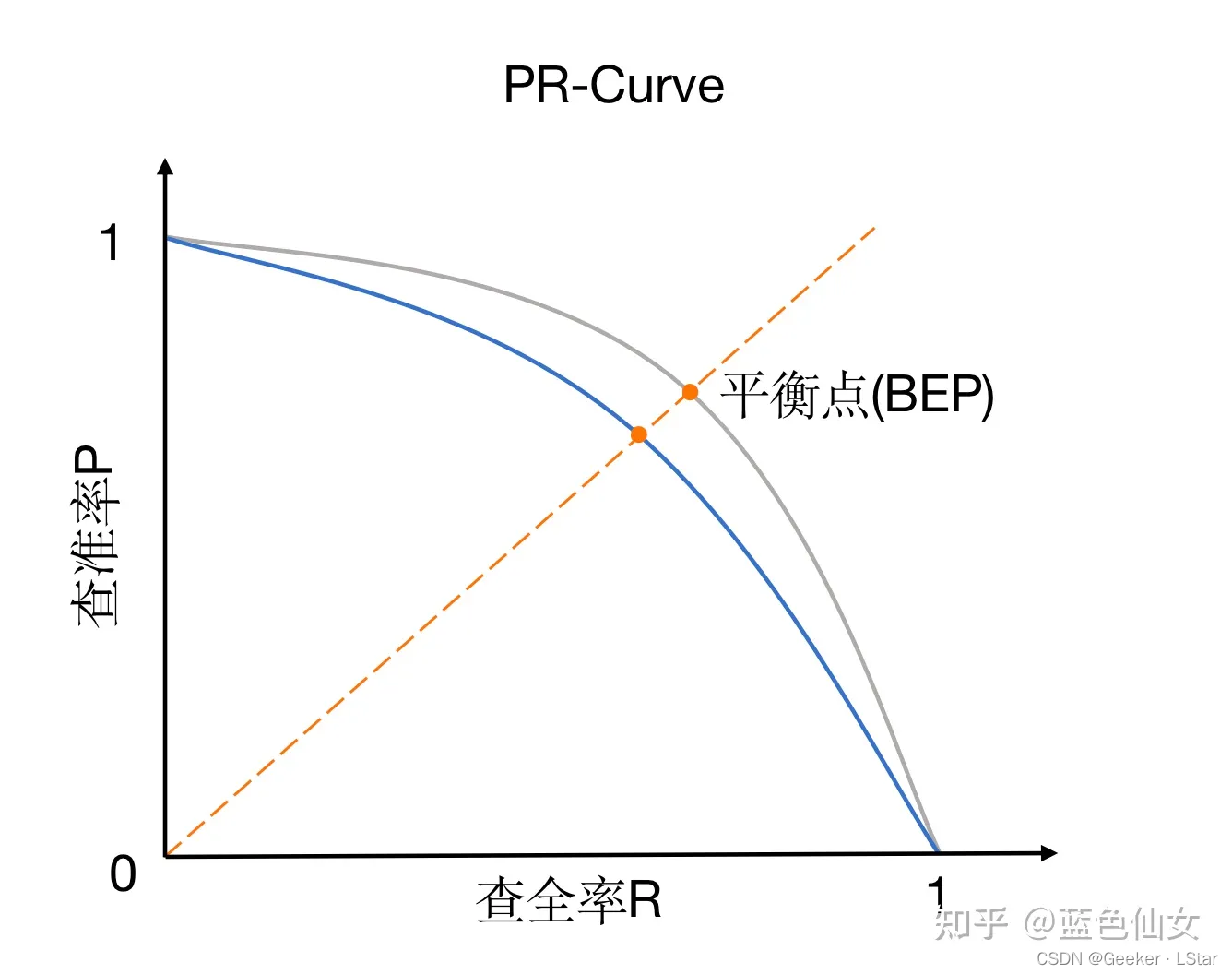
在模型评价中,PR 曲线也是一个可参考的指标。PR 曲线的画法和 ROC 曲线没有区别,这里不再写啦~
综上,分类算法中,常用的模型评价指标有准确率、召回率、精确率、F1 值、ROC 曲线、AUC 值和 PR 曲线等。
嗯,又是将近一万字!
这篇文章讲了很多分类算法中常用的模型评价指标,希望对你有所帮助!⭐
欢迎三连!!一起加油!
——Geeker_LStar