【Java EE初阶十】多线程进阶二(CAS等)
1. 关于CAS
CAS: 全称Compare and swap,字面意思:”比较并交换“,且比较交换的是寄存器和内存;
一个 CAS 涉及到以下操作:
下面通过语法来进一步进项说明:
下面有一个内存M,和两个寄存器A,B;
CAS(M,A,B):该条指令意味着如果M和A中的值相同,则将M 和B中的值进行交换,在完成上述操作之后,返回true;如果M和A中的值不相同,则不用发生任何交换,同时返回false;
综上所述,交换的本质就是当寄存器和内存中的值一样时,将其他寄存器中不同与内存中的值赋给内存;
1.1 CAS伪代码
下面写的代码是伪代码,该段代码不能被顺利的编译运行,但是可以用来辅助理解上述所说 CAS 的工作流程.
boolean CAS(address, expectValue, swapValue) {
if (&address == expectedValue) {
&address = swapValue;
return true;
}
return false;
}CAS其实是一个cpu指令(一条cpu指令就能满足上述比较交换的逻辑),说明单个cpu指令是原子的。故此可以使用CAS完成一些操作(给编写线程安全的代码,引入了新的思路并且不涉及线程阻塞),进一步代替“加锁”;
基于CAS实现线程安全的方式,也称为“无锁编程”,其优缺点如下:
优点:保证线程安全,同时避免阻塞;
缺点:
1、代码会更加复杂,不好理解;
2、只能够适合一些特定的场景,不如加锁方式更加普遍;
Cas本质上是cpu提供的指令->又被操作系统封装提供成api->又被jvm封装,也被提供成api->被程序员使用了;
1.2 CAS 有哪些应用
1.2.1 实现原子类
Int++操作不是原子的(load,add,save),其中AtomicInteger,基于CAS的方式对int进行封装了,此时进行int++(基于cas指令来实现的)就是原子的操作了

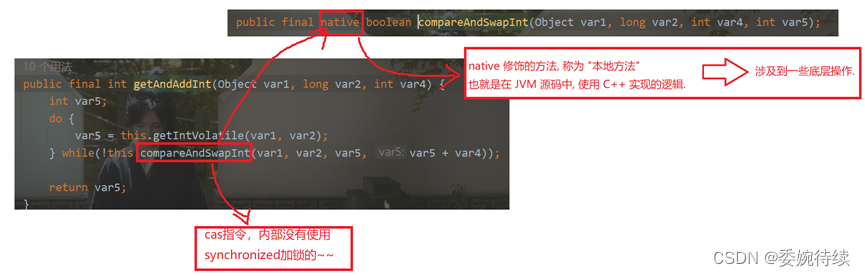
结论:原子类里面是基于cas来实现的;下面是简化的代码:
class AtomicInteger {
private int value;
public int getAndIncrement() {
int oldValue = value;
while ( CAS(value, oldValue, oldValue+1) != true) {
oldValue = value;
}
return oldValue;
}
}
通过在多线程t1和t2的分析中了解cas的简单原理:
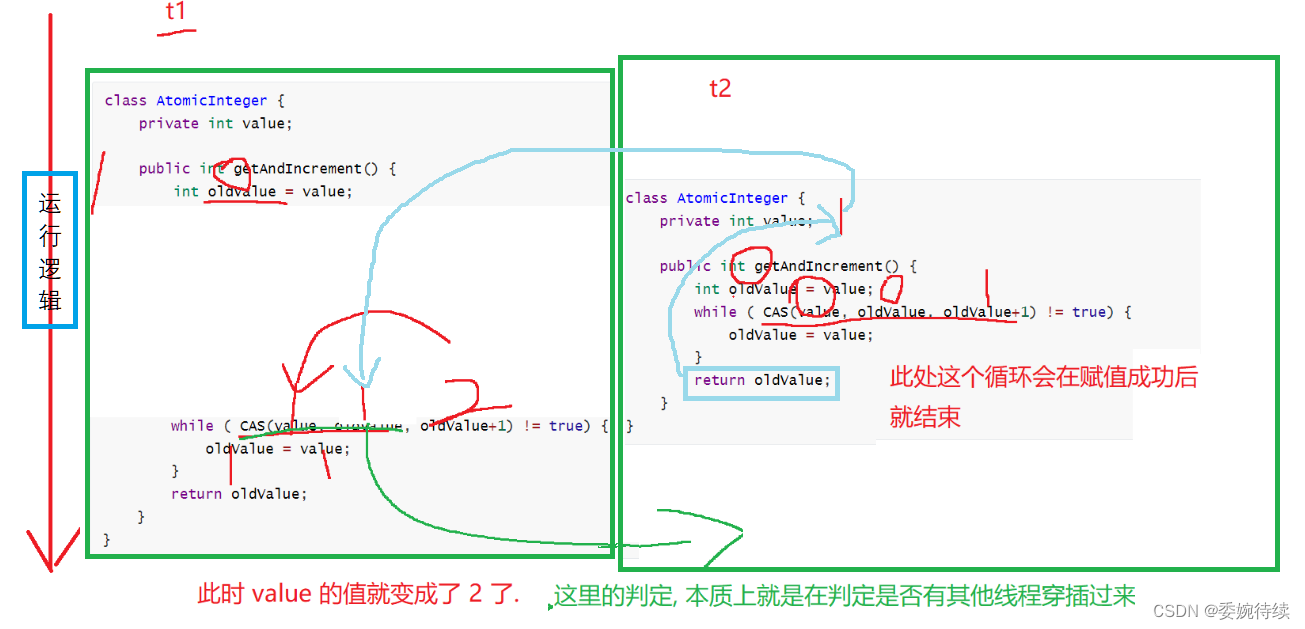
我们所说的“线程不安全”本质上是进行自增的过程中,被其他线程的自增行为穿插执行了;但是CAS是让这里的自增不要被穿插执行,其核心思路类似于加锁,但是加锁是通过阻塞的方式避免穿插,CAS则是通过重试的方式避免被穿插;
1.2.2 实现自旋锁

1.2.2 关于ABA问题
CAS进行操作的关键,是通过值“有没有发生变化”作为“有没有其他线程穿插执行的”判定依据,但是在一些的极端的情况下,我们的值本来是正常情况下的A的成为A->B->A,针对第一个要判断的线程来说,看起来由于值没有变二判定没有其他线程进行穿插执行,但是事实上我们已经存在线程穿插执行的问题了。
如下图所示,虽然使用cas语句进行判定的时候内存中和寄存器中的数值一样,但是我们不能确定内存中的值是始终没有发生变化还是发生变化之后被其他线程又成功改回来了;

2. JUC的相关类
JUC(java.util.concurrent),且Concurrent:并发的意思,这个包里面的内容,主要就是一些多线程相关的组件;
2.1 Callable 接口
该接口也是一种创建线程的方式,适合于想让某个线程执行一个逻辑,并且返回结果的时候;相对而言,runnable不关注结果,代码举例如下:
代码示例: 创建线程计算 1 + 2 + 3 + ... + 1000, 使用 Callable 版本
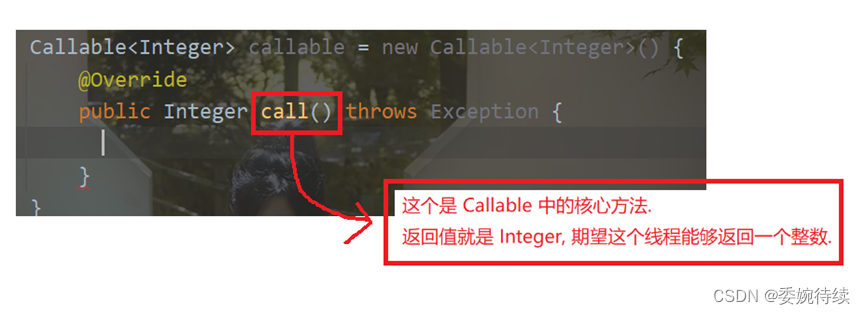
创建一个匿名内部类, 实现 Callable 接口. Callable 带有泛型参数. 泛型参数表示返回值的类型.
重写 Callable 的 call 方法, 完成累加的过程. 直接通过返回值返回计算结果.
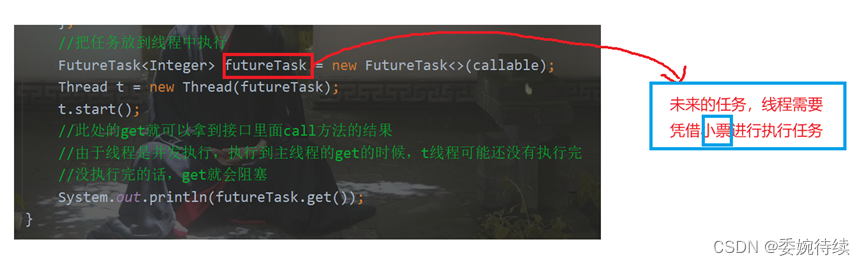
把 callable 实例使用 FutureTask 包装一下.
创建线程, 线程的构造方法传入 FutureTask . 此时新线程就会执行 FutureTask 内部的 Callable 的 call 方法, 完成计算. 计算结果就放到了 FutureTask 对象中.
在主线程中调用 futureTask.get() 能够阻塞等待新线程计算完毕. 并获取到 FutureTask 中的结果.
Callable<Integer> callable = new Callable<Integer>() { @Override public Integer call() throws Exception { int sum = 0; for (int i = 1; i <= 1000; i++) { sum += i; } return sum; } }; FutureTask<Integer> futureTask = new FutureTask<>(callable); Thread t = new Thread(futureTask); t.start(); int result = futureTask.get(); System.out.println(result) }
下面图解主要是关于futuretask的讲解:
理解 Callable:
Callable 和 Runnable 相对, 都是描述一个 "任务". Callable 描述的是带有返回值的任务, Runnable 描述的是不带返回值的任务. Callable 通常需要搭配 FutureTask 来使用. FutureTask 用来保存 Callable 的返回结果. 因为 Callable 往往是在另一个线程中执行的, 啥时候执行完并不确定. FutureTask 就可以负责这个等待结果出来的工作
2.2 ReentrantLock
可重入互斥锁. 和 synchronized 定位类似, 都是用来实现互斥效果, 保证线程安全. ReentrantLock 也是可重入锁. "Reentrant" 这个单词的原意就是 "可重入";
ReentrantLock 的用法:
lock(): 加锁, 如果获取不到锁就死等.
trylock(超时时间): 加锁, 如果获取不到锁, 等待一定的时间之后就放弃加锁.
unlock(): 解锁
ReentrantLock lock = new ReentrantLock();
-----------------------------------------
lock.lock();
try {
// working
} finally {
lock.unlock()
} ReentrantLock相对于synchronized的优势:
1、ReentrantLock,在加锁的时候,有两种方式lock(加锁失败就会阻塞等待) 和trylock(加锁失败就会放弃);
2、ReentrantLock还通过了公平锁的实现(默认情况下是非公平锁)
3、ReentrantLock提供了更强大的等待通知机制,主要是搭配了condition类,实现等待通知的;
总的来说,我们在加锁的时候,首选synchronized(会有优化锁的策略),因为ReentrantLock使用起来更加复杂,尤其是容易忘记解锁;
2.3 信号量 Semaphore
Semaphore 信号量, 本质上就是一个计数器. 用来表示 "可用资源的个数".每次申请一个可用资源,就需要让计数器-1(p操作);每次释放一个可用资源,就需要让计数器+1(v操作),操作系统,提供了信号量实现,同时操作系统也提供了api;jvm封装了这样的api,就可以在java代码中使用了;
理解信号量:
可以把信号量想象成是停车场的展示牌: 当前有车位 100 个. 表示有 100 个可用资源. 当有车开进去的时候, 就相当于申请一个可用资源, 可用车位就 -1 (这个称为信号量的 P 操作) 当有车开出来的时候, 就相当于释放一个可用资源, 可用车位就 +1 (这个称为信号量的 V 操作) 如果计数器的值已经为 0 了, 还尝试申请资源, 就会阻塞等待, 直到有其他线程释放资源.
Semaphore 的 PV 操作中的加减计数器操作都是原子的, 可以在多线程环境下直接使用.
关于semaphore的代码如下:
Semaphore semaphore = new Semaphore(4);
Runnable runnable = new Runnable() {
@Override
public void run() {
try {
System.out.println("申请资源");
semaphore.acquire();
System.out.println("我获取到资源了");
Thread.sleep(1000);
System.out.println("我释放资源了");
semaphore.release();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
for (int i = 0; i < 20; i++) {
Thread t = new Thread(runnable);
t.start();
}2.4 CountDownLatch
同时等待 N 个任务执行结束.主要适用于,多个线程来完成一系列任务的时候,用来衡量任务的进度是否完成。
比如需要把一个很大的任务,拆分成多个小任务,让这些小任务并发的去执行。就可以使用CountDownLatch来判定说当前的这些任务是否都完全全部完成了;
Eg:下载一个文件,就可以使用多线程下载;相比之下,有一些专业的下载工具(往往和资源服务器之间只有一个连接,服务器往往会对于连接传输的速度有一定的限制),就可成倍的提升下载速度(IDM),多线程下载(每个线程都建立一个连接,此时就需要把整个大任务进行分割)
CountDownLatch 主要有两个方法:
- await,该方法调用的时候就会阻塞,就会等待其他线程完成任务,当所有的线程都完全的完成了任务之后,此时这个await才会返回,才会继续往下走;
- CountDown,告诉CountDownLatch,我当前的一个子任务已经完成了
结果如下:

3 线程安全的集合类
3.1 多线程环境使用 ArrayList:
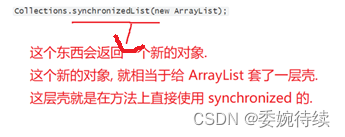
3.1.1 Collections.synchronizedList(new ArrayList);
synchronizedList 是标准库提供的一个基于 synchronized 进行线程同步的 List. synchronizedList 的关键操作上都带有 synchronized
3.1.2 使用 CopyOnWriteArrayList
写时拷贝;
比如,两个线程使用同一个arraylist,可能会读,也可能会修改;
如果要是两个线程读,则可以直接进行读操作即可;
如果某个线程需要进行修改,就把arraylist临时复制出一个副本,进行修改的线程就修改这个副本,与此同时,另外一个线程任然可以从原来的数据文件上读取数据,一旦这边修改的临时文件修改完毕,就会使用修改好的这份数据文件来代替原来的数据文件。
该方法的局限性:
- 当前操作的ArrayList不能太大(拷贝成本,不能太高)
- 更适用于一个线程去修改,而不能是多个线程去同时修改(多个线程读,一个线程修改)
这种场景特别适用于服务器的配置更新~~,可以通过配置文件来描述配置的详细内容(本身就不会很大),配置的内容会被读取到内存中,再有其他的线程读取这里的内容,但是修改这个配置内容,往往只能有一个线程来修改;
应用场景:使用某个命令让服务器重新加载配置,就可以使用写时拷贝的方式;
3.2 多线程环境使用哈希表
3.2.1 Hashtable
HashMap 本身不是线程安全的. 在多线程环境下使用哈希表可以使用: ConcurrentHashMap
Hashtable保证线程安全,主要是给关键方法加上synchronized(类似于给this加锁),同时只有两个线程在操作同一个Hashtable就会出现锁冲突
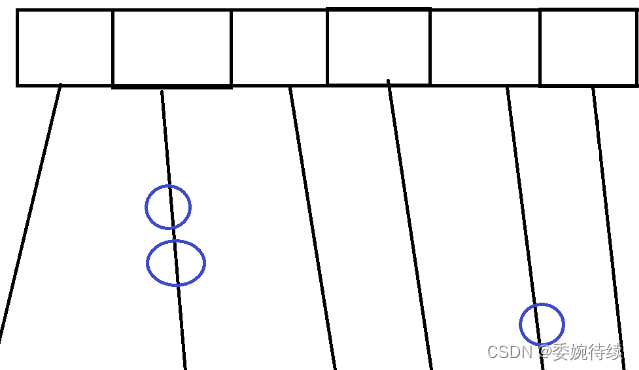
如上图所示,当两个不同的key映射到同一个数组下标上,就会出现hash冲突,使用链表来解决hash冲突;
按照上述这样的方式来操作 ,并且在不考虑触发扩容的前提下,操作不同的链表的时候就是线程安全的,相比之下,如果两个线程操作的是同一个链表,才会比较容易发生线程安全的问题;故此连个线程,操作的是不同的链表,就根本不用加锁,只要在操作同一个链表的时候才需要进行加锁;
3.2.2 ConcurrentHashMap
ConcurrentHashMap相比于 Hashtable 做出了一系列的改进和优化,简单如下所示:
1、 ConcurrentHashMap最核心的改进,就是把一个全局的大锁,改进成了每个链表独立的一把小锁,这样就大幅度的降低了锁冲突的概率(一个hash表有很多这样的链表,两个线程恰好同时访问一个链表的概率比较少)--->就是把每一个链表的头结点作为锁对象,synchronized可以使用任何对象作为锁对象
2、充分利用了cas的特性,把一些不必要加锁的环节给省略了,比如需要使用变量记录hash表中的元素个数,就可以使用原子操作(cas)修改元素个数;
3、 ConcurrentHashMap,还有一个激进的操作,针对读操作没有进行加锁,读和读之间,读和写之间,都不会有锁竞争;写和写之间是需要进行加锁的
q:是否会存在“读到一个修改了一半的数值呢”这种情况?
a:ConcurrentHashMap 在底层编码的过程中,比较谨慎的处理了一些细节,修改数值的时候就会避免使用++,--这种非原子的操作,使用=进行修改的时候,本身就是原子的,读的时候,要么读到的就是之前所写的旧的数值,要么读到的就是重写修改后的数值,不会出现一个修改到一半的数值;
4、ConcurrentHashMap针对扩容操作进行了单独的优化
本身Hashtable和HashMap在扩容的时候,都是需要把所有单独的元素都拷贝一遍的(如果元素较多的话,就会比较耗时)即1000个用户访问,且只有一个人在访问的时候触发扩容遇到卡顿,所以就需要化整为零的进行复制,一旦需要扩容,我们旧分为很多次进行搬运复制,每次只用复制一小部分防治这一个单次访问遇到卡顿;
当然,ConcurrentHashMap基本的使用方法和普通的HasMap完全一样
ps:本篇的内容到这里就结束啦,如果对你有所帮助的话,就请一键三连哦哦!!!