每日五道java面试题之java基础篇(五)

第一题. final、finally、finalize 的区别?
- final ⽤于修饰变量、⽅法和类:final 修饰的类不可被继承;修饰的⽅法不可被重写;修饰的变量不可变。
- finally 作为异常处理的⼀部分,它只能在 try/catch 语句中,并且附带⼀个语句块表示这段语句最终⼀定
被执⾏(⽆论是否抛出异常),经常被⽤在需要释放资源的情况下, System.exit (0) 可以阻断 finally 执
⾏。 - finalize 是在 java.lang.Object ⾥定义的⽅法,也就是说每⼀个对象都有这么个⽅法,这个⽅法在 gc 启
动,该对象被回收的时候被调⽤。⼀个对象的 finalize ⽅法只会被调⽤⼀次,finalize 被调⽤不⼀定会⽴即回收该对象,所以有可能调⽤finalize 后,该对象⼜不需要被回收了,然后到了真正要被回收的时候,因为前⾯调⽤过⼀次,所以不会再次调⽤ finalize 了,进⽽产⽣问题,因此不推荐使⽤ finalize ⽅法。
第二题. ==和 equals 的区别?
== : 它的作⽤是判断两个对象的地址是不是相等。即,判断两个对象是不是同⼀个对象(基本数据类型 == ⽐较的是值,引⽤数据类型 == ⽐较的是内存地址)。
equals() : 它的作⽤也是判断两个对象是否相等。但是这个“相等”⼀般也分两种情况:
- 默认情况:类没有覆盖 equals() ⽅法。则通过 equals() ⽐较该类的两个对象时,等价于通过“ == ”⽐较这两个对象,还是相当于⽐较内存地址。
- ⾃定义情况:类覆盖了 equals() ⽅法。我们平时覆盖的 equals()⽅法⼀般是⽐较两个对象的内容是否相同,⾃定义了⼀个相等的标准,也就是两个对象的值是否相等。
第三题.hashCode 与 equals?
这个也是⾯试常问——“你重写过 hashcode 和 equals 么,为什么重写 equals 时必须重写 hashCode ⽅法?”
什么是 HashCode?
hashCode() 的作⽤是获取哈希码,也称为散列码;它实际上是返回⼀个 int 整数,定义在 Object 类中, 是⼀个本地⽅法,这个⽅法通常⽤来将对象的内存地址转换为整数之后返回。
public native int hashCode();
哈希码主要在哈希表这类集合映射的时候⽤到,哈希表存储的是键值对(key-value),它的特点是:能根据“键”快速的映射到对应的“值”。这其中就利⽤到了哈希码!
为什么要有 hashCode?
上⾯已经讲了,主要是在哈希表这种结构中⽤的到。
例如 HashMap 怎么把 key 映射到对应的 value 上呢?⽤的就是哈希取余法,也就是拿哈希码和存储元素的数组的⻓度取余,获取 key 对应的 value 所在的下标位置。
为什么重写 quals 时必须重写 hashCode ⽅法?
如果两个对象相等,则 hashcode ⼀定也是相同的。两个对象相等,对两个对象分别调⽤ equals ⽅法都返回
true。反之,两个对象有相同的 hashcode 值,它们也不⼀定是相等的 。因此,equals ⽅法被覆盖过,则hashCode⽅法也必须被覆盖。
hashCode() 的默认⾏为是对堆上的对象产⽣独特值。如果没有重写 hashCode() ,则该 class 的两个对象⽆论如何都不会相等(即使这两个对象指向相同的数据)
为什么两个对象有相同的 hashcode 值,它们也不⼀定是相等的?
因为可能会碰撞, hashCode() 所使⽤的散列算法也许刚好会让多个对象传回相同的散列值。越糟糕的散列算法越容易碰撞,但这也与数据值域分布的特性有关(所谓碰撞也就是指的是不同的对象得到相同的 hashCode )。
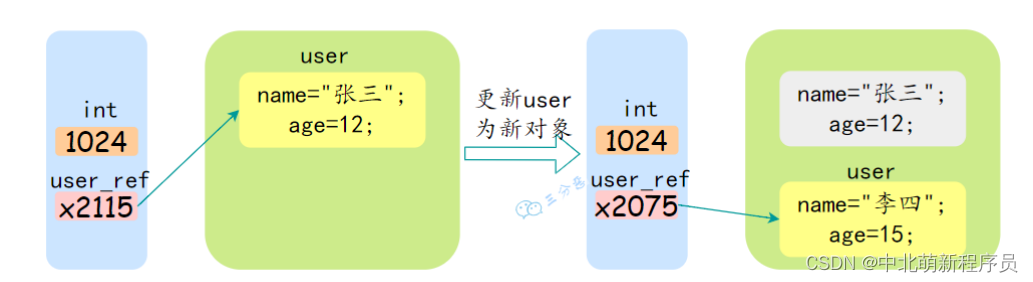
第四题. Java 是值传递,还是引⽤传递?
Java 语⾔是值传递。Java 语⾔的⽅法调⽤只⽀持参数的值传递。当⼀个对象实例作为⼀个参数被传递到⽅法中时,参数的值就是对该对象的引⽤。对象的属性可以在被调⽤过程中被改变,但对对象引⽤的改变是不会影响到调⽤者的。
JVM 的内存分为堆和栈,其中栈中存储了基本数据类型和引⽤数据类型实例的地址,也就是对象地址。
⽽对象所占的空间是在堆中开辟的,所以传递的时候可以理解为把变量存储的对象地址给传递过去,因此引⽤类型也是值传递。
第五题 深拷贝和浅拷贝?
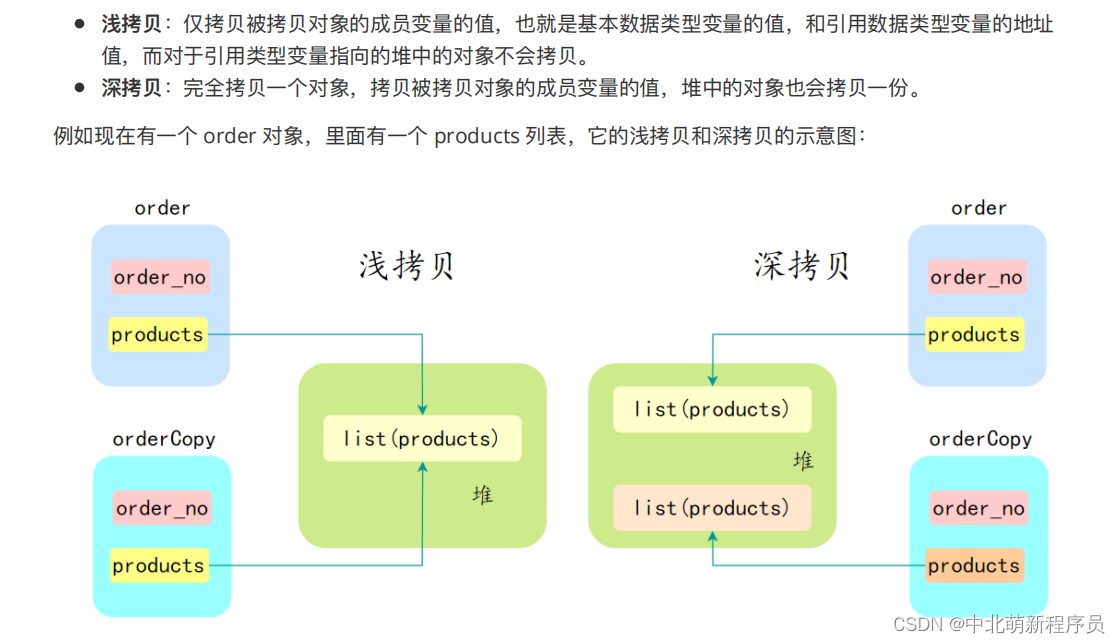
因此深拷⻉是安全的,浅拷⻉的话如果有引⽤类型,那么拷⻉后对象,引⽤类型变量修改,会影响原对象
浅拷⻉如何实现呢?
Object 类提供的 clone()⽅法可以⾮常简单地实现对象的浅拷⻉。
深拷⻉如何实现呢?
- 重写克隆⽅法:重写克隆⽅法,引⽤类型变量单独克隆,这⾥可能会涉及多层递归。
- 序列化:可以先将原对象序列化,再反序列化成拷⻉对象。
如果我的内容对你有帮助,请点赞,评论,收藏。创作不易,大家的支持就是我坚持下去的动力!
