Python爬虫——请求库安装
目录
- 1.打开Anaconda Prompt 创建环境
- 2.安装resuests
- 3.验证是否安装成功
- 4.安装Selenium
- 5.安装ChromeDriver
- 5.1获取chrom的版本
- 5.1.1点击浏览器右上三个点
- 5.1.2点击设置
- 5.1.3下拉菜单,点击最后关于Chrome,获得其版本
- 5.2 打开网址 [chromedriver](https://googlechromelabs.github.io/chrome-for-testing/)
- 5.3解压下载的压缩包,将可执行文件移动到chrome浏览器安装位置
- 5.4配置环境变量
- 5.4.1准备工作
- 5.4.2*名字起个chromedriver,变量值复制前面chrome的路径即可,然后点击确定即可*
- 5.5将chromedriver.exe放在anaconda安装路径下的Scripts的目录下如下:
- 5.6验证chromedriver是否安装成功
- 6.安装PhantomJS
- 6.1去官网选择相应的版本下载
- 6.2配置环境变量
- 6.3测试是否配置成功
- 7.安装aiohttp
- 7.1安装
- 7.2验证
我创建了一个社区,欢迎大家一起学习交流。社区名称:Spider学习交流
注:该系列教程已经默认用户安装了Pycharm和Anaconda,未安装的可以参考我之前的博客有将如何安装。同时默认用户掌握了Python基础语法。
爬虫可以简单分为几步:1.抓取页,2.分析页面,3.存储数据
在抓取页面的过程中 ,我们需要模拟浏览器向服务器发出请求,所以需要用到一些 Python 库来实现HTTP 请求操作,因此我们先介绍怎么安装这些请求库。
1.打开Anaconda Prompt 创建环境
打开Anaconda Prompt (anaconda),新建一个虚拟环境。不太会的可以先参考我这篇博客Pycharm+Anaconda+yolov5-5.0部署(手把手教+解决一些运行过程中的问题+最全部署yolov5,和Windows配置深度学习环境:安装Pytorch(自动安装cudn和cudnn+图文+快速+很简单)几分钟搞定这两篇博文,里面说的很清楚,大家只需要看前面部分即可。
#1.创建虚拟环境(spider是自己起的名字,大家随机即可)
conda create -n spider python
#2.激活虚拟环境spider
conda activate spider
#3.输入python测试py环境
python
#4.退出
exit()
1.创建虚拟环境显示
2.激活虚拟环境显示
3.测试py环境显示+退出
2.安装resuests
安装的方法很多,我在这就拿最简单的演示。
#1.输入代码
conda install requests
#2.如何输入y等待即可

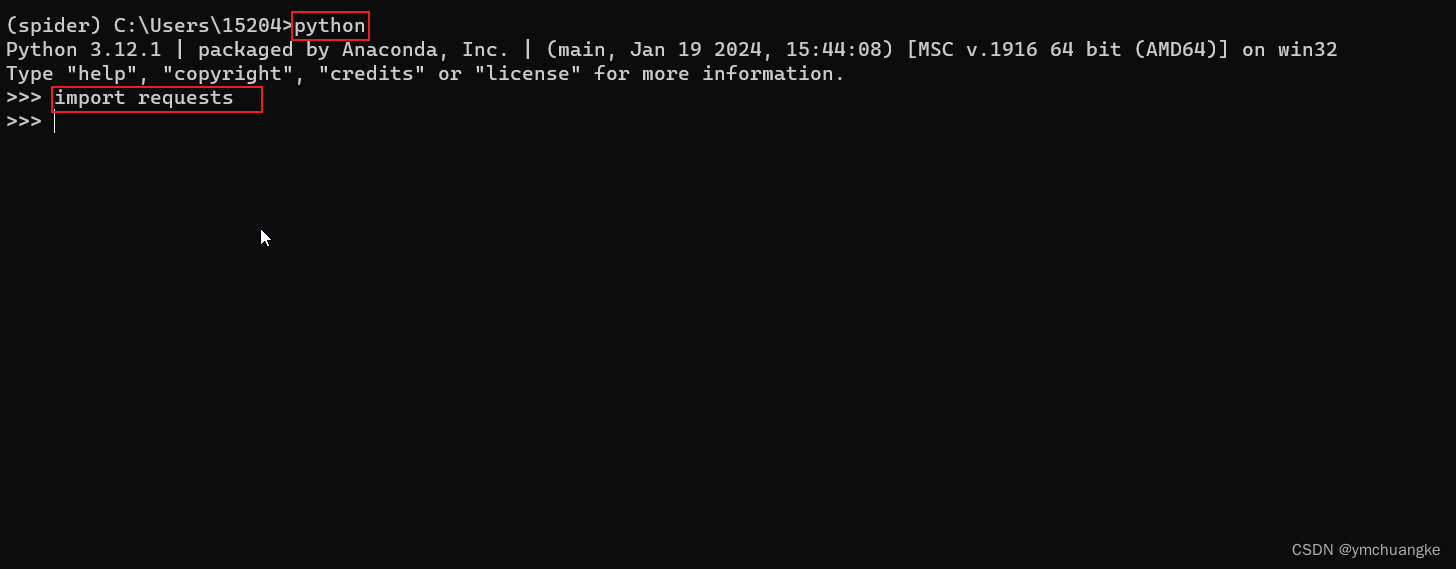
3.验证是否安装成功
#1.输入代码
python
#2.输入
import requests
# 若没有报错证明安装成功,结果如下显示
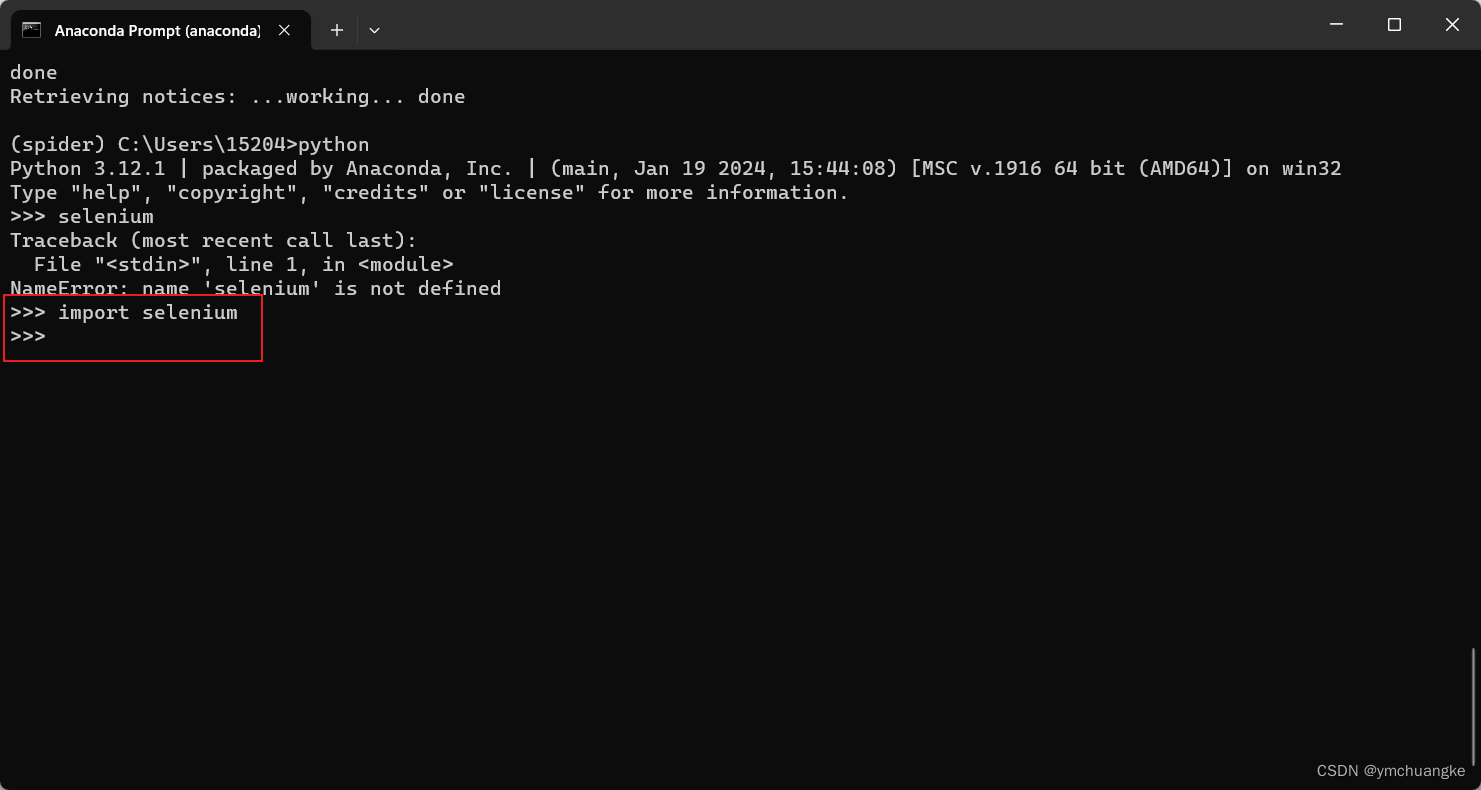
4.安装Selenium
Selenium 是一个自动化测试工具,利用它我们可以驱动浏览器执行特定的动作,如点击、下拉等操作。
#和requests一样的安装方法
conda install selenium
#安装完成以后同样的验证方法,结果如下:
5.安装ChromeDriver
想必大家都有Chrome浏览器吧(嘿嘿嘿)。
没安装的可以自己安装方法很多,在此不再赘述!
接下来介绍如何安装ChromeDriver,因为只有安装这个,才能驱动Chrome浏览器进行相应的操作,其他浏览器同理。
#1.先打开自己的Chrome浏览器查看查看版本
#2.点击 hrome 菜单“帮助”→“关于 Google Chrome”,即可查看 Chrome 的版本号
5.1获取chrom的版本
5.1.1点击浏览器右上三个点
如下图:
5.1.2点击设置
5.1.3下拉菜单,点击最后关于Chrome,获得其版本
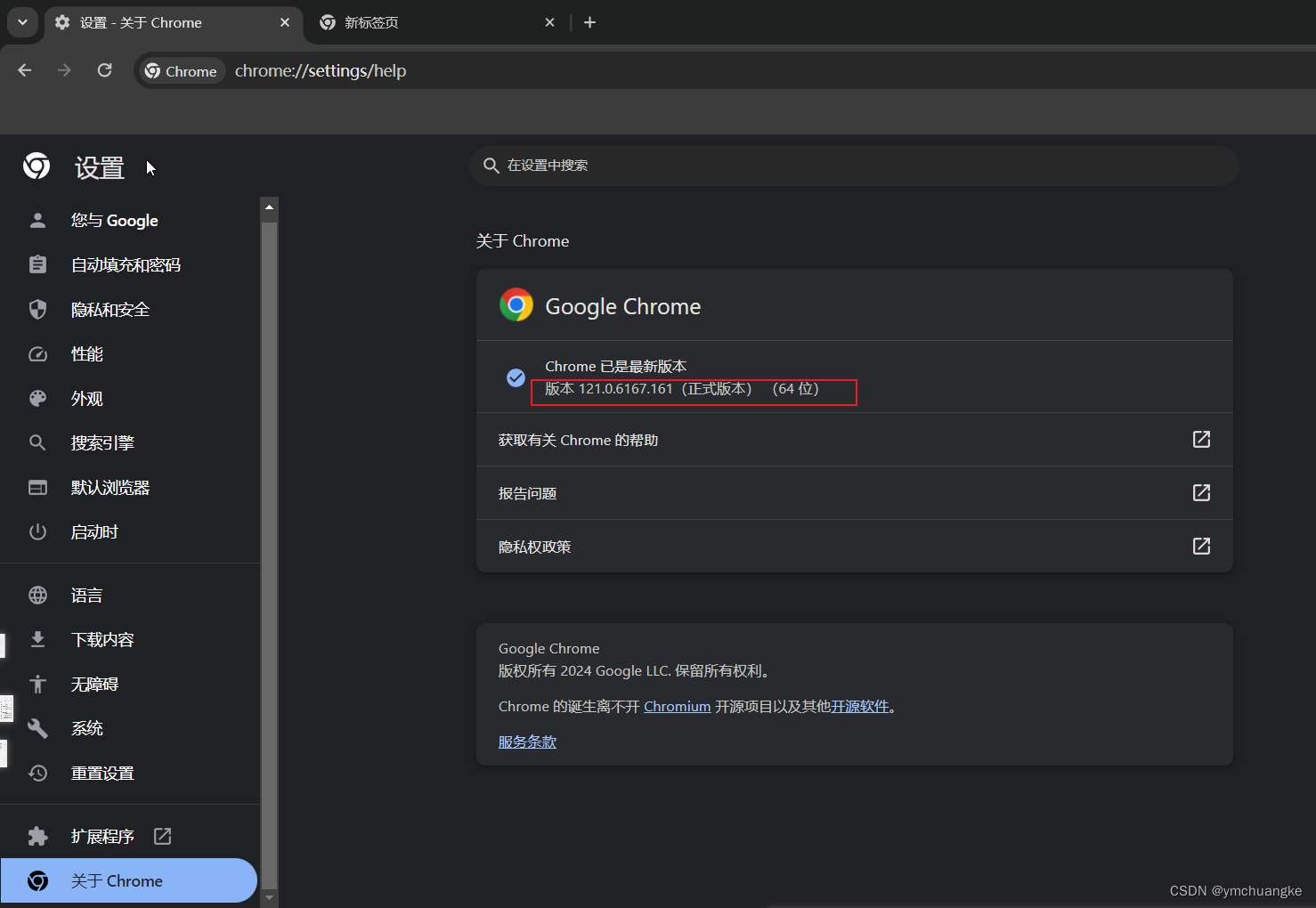
版本是121.0
5.2 打开网址 chromedriver
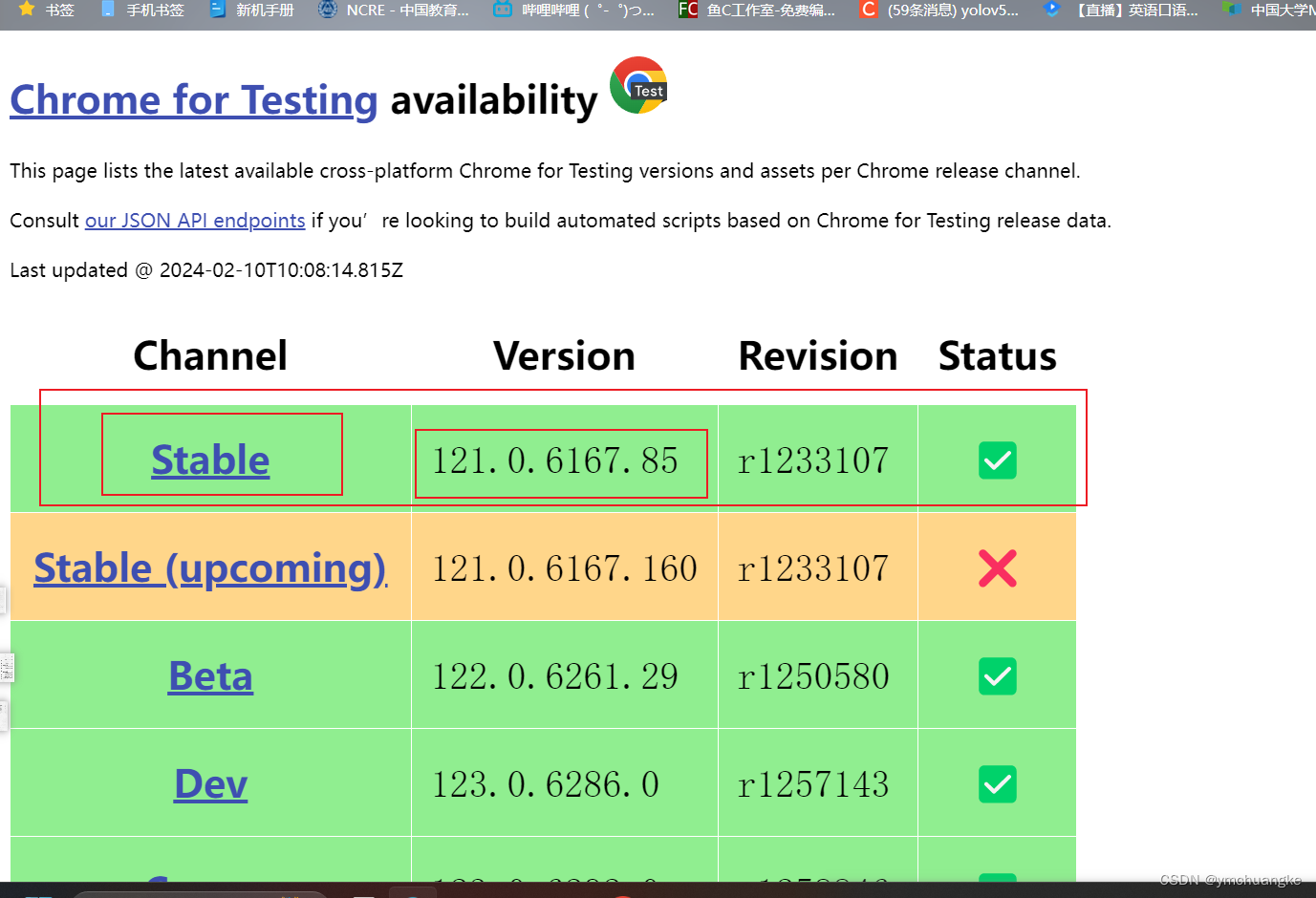
由于未更新到最高版本,选择第一个即可,点击stable。
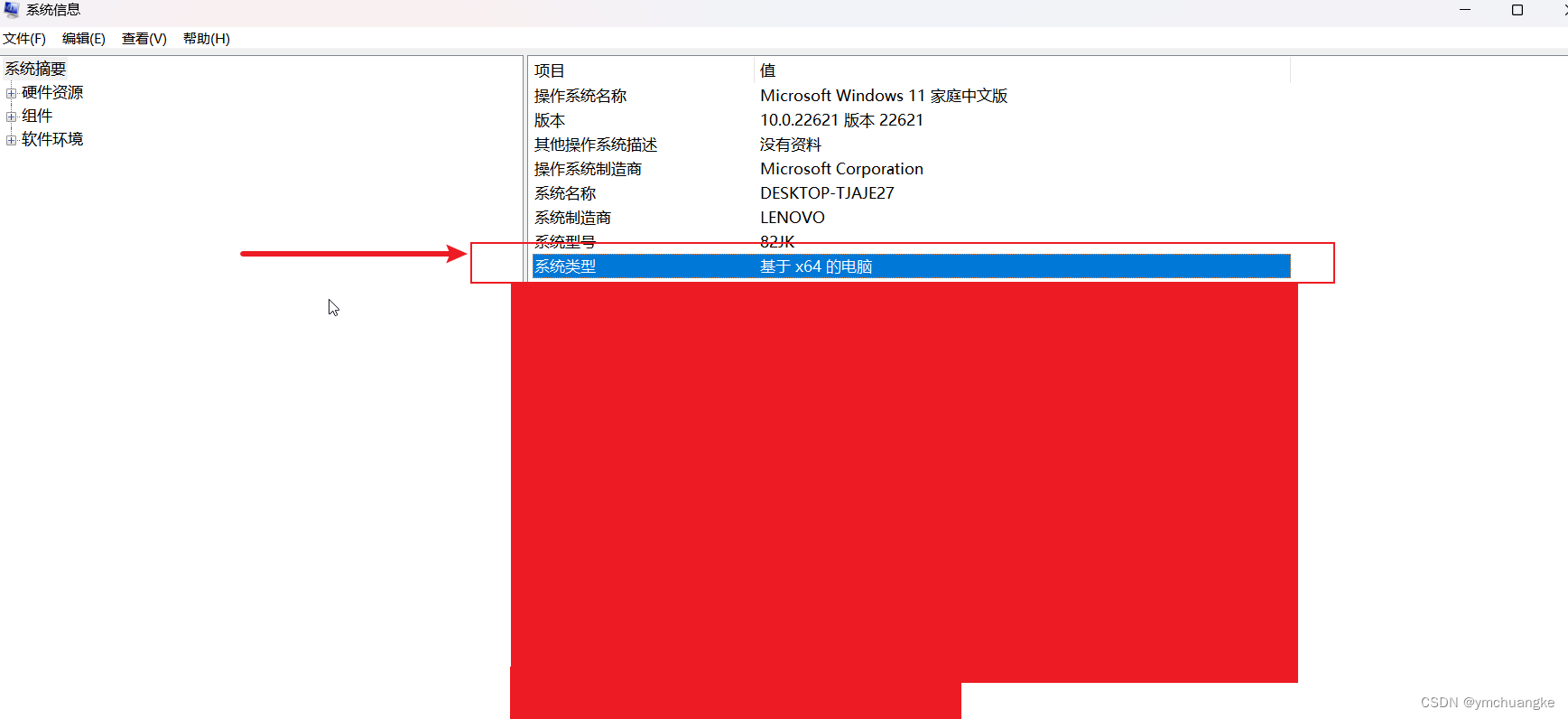
查看自己的电脑版本
win+R,输入msinfo32,查看自己电脑架构,如何下载相应的文件即可。
点击相应的版本下载
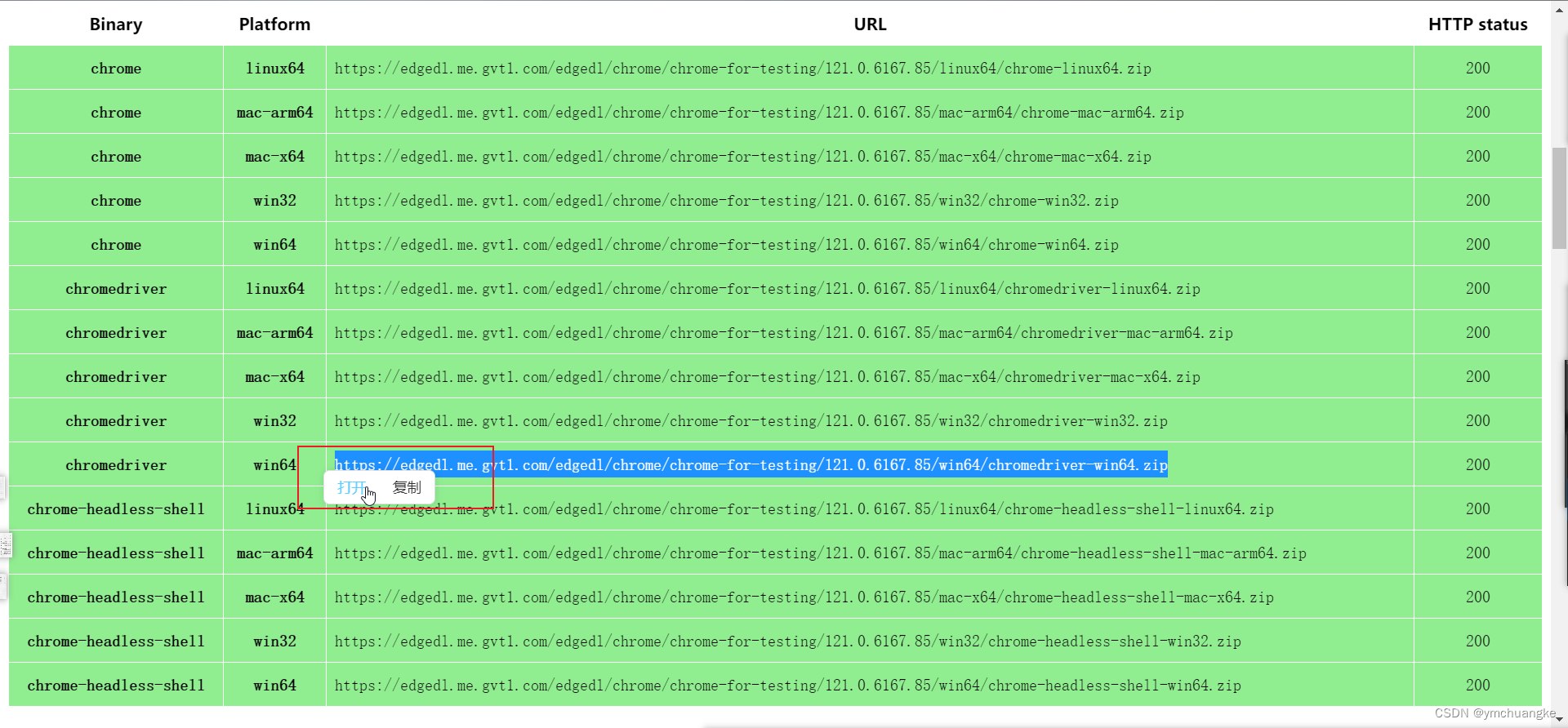
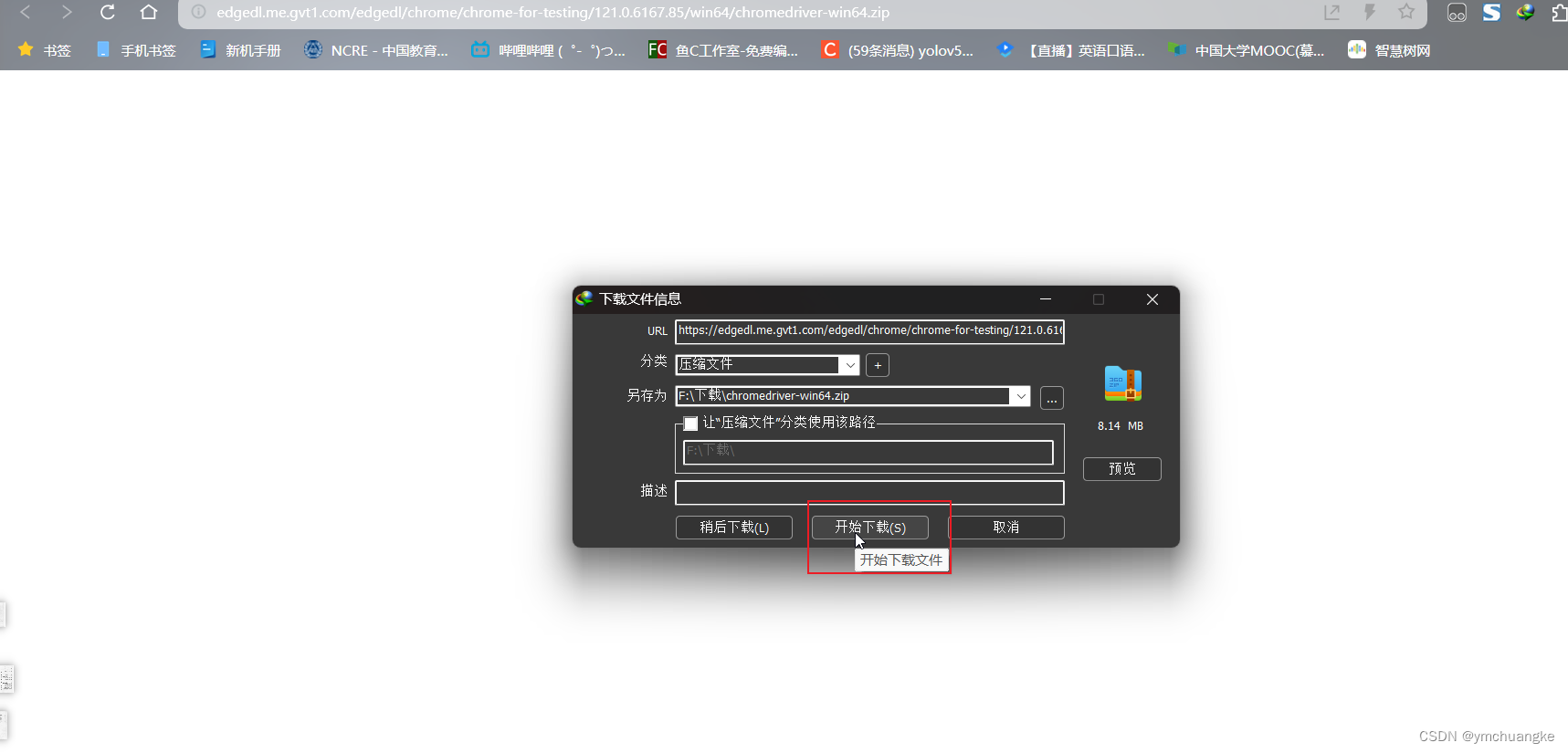
5.3解压下载的压缩包,将可执行文件移动到chrome浏览器安装位置
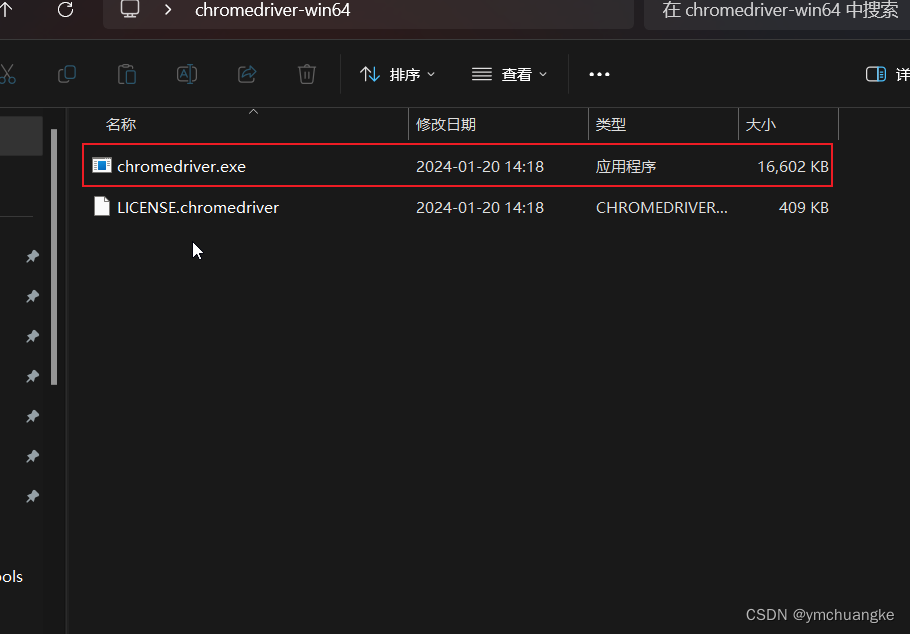
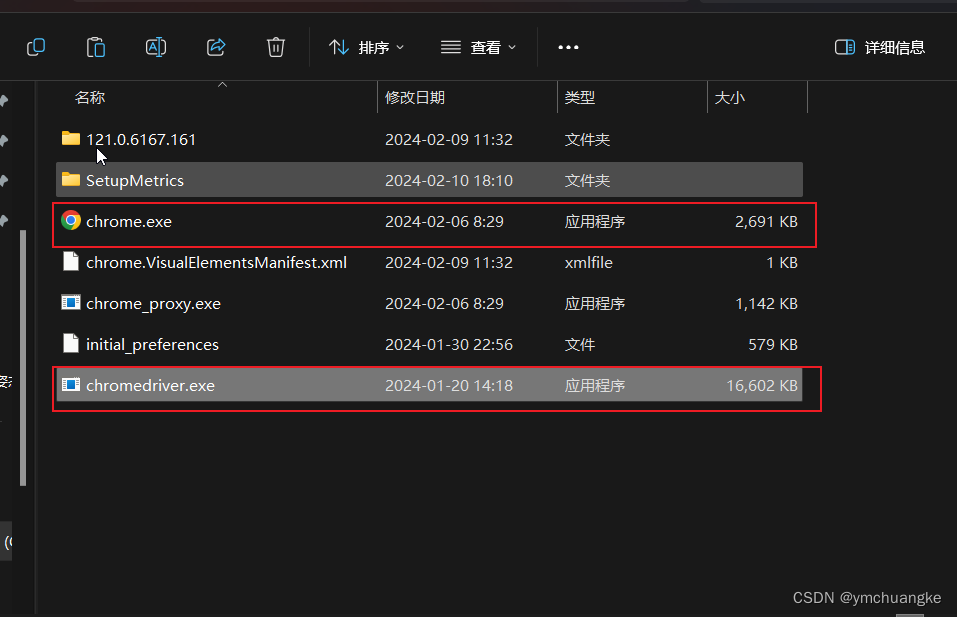
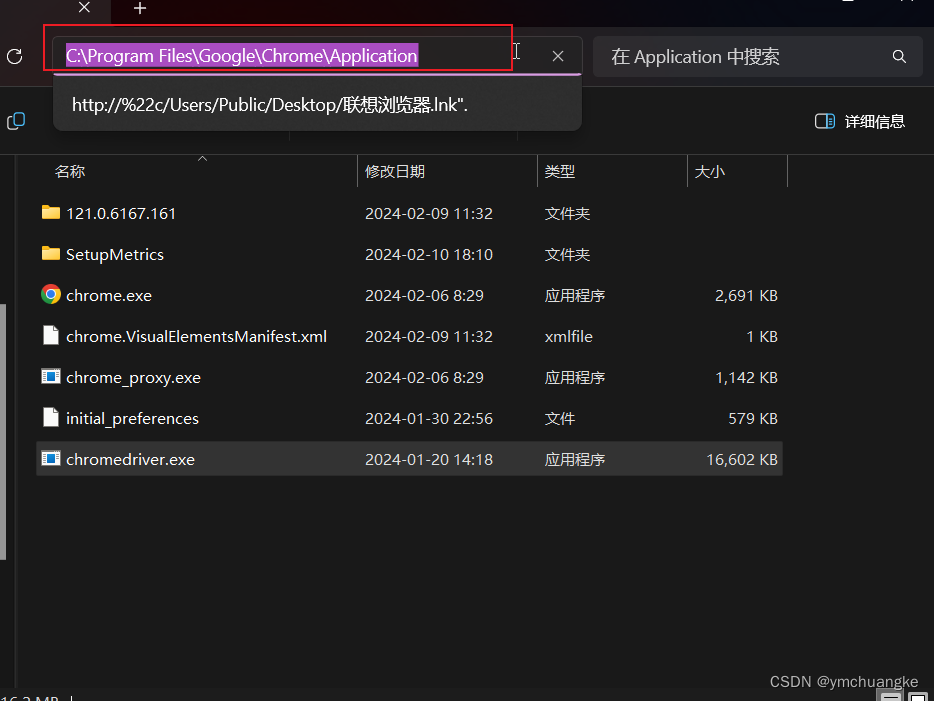
chrome安装位置,可以通过点击chrome ,如何右键选择打开文件位置即可找到。
5.4配置环境变量
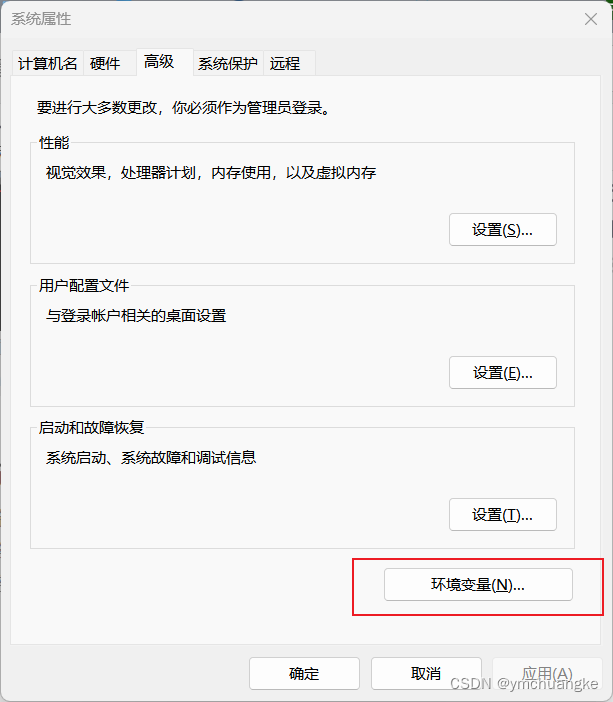
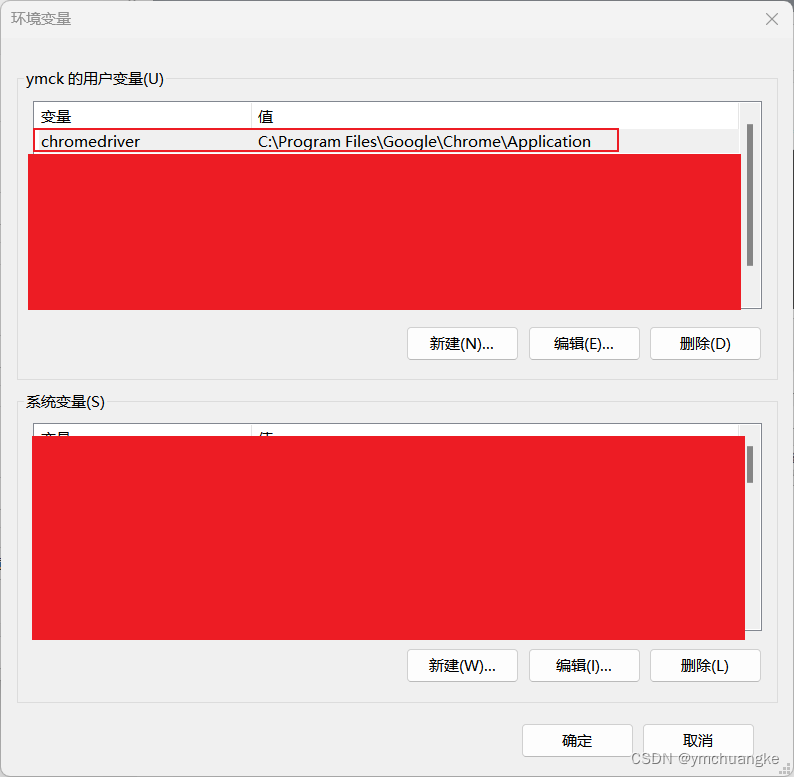
按下win键→搜索框输入:高级系统设置+回车→环境变量→用户变量→Path→编辑→新建,将上面的浏览器安装目录进行复制粘贴,然后不要忘记后续全部点击确定
5.4.1准备工作
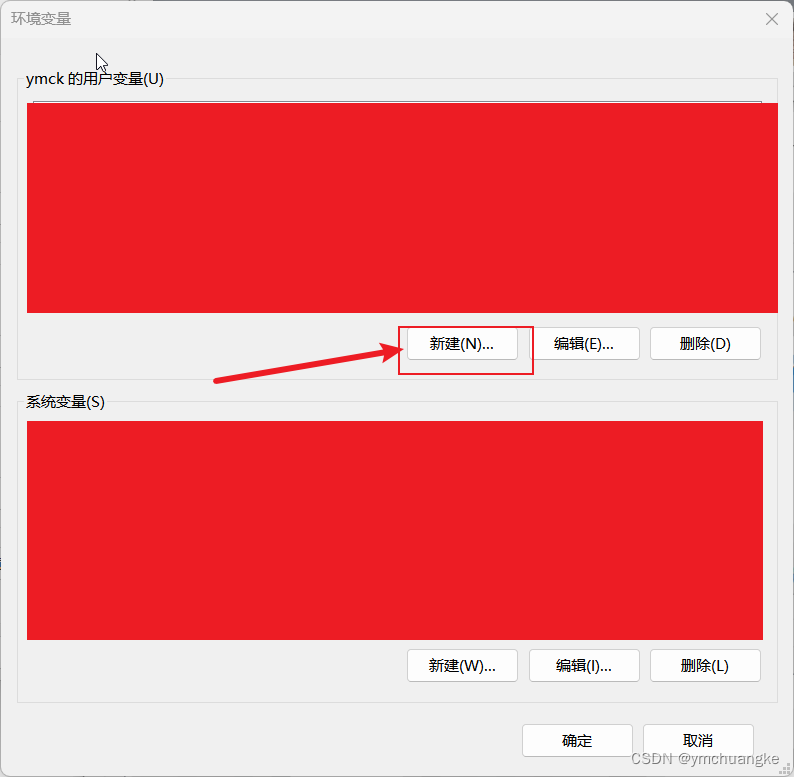
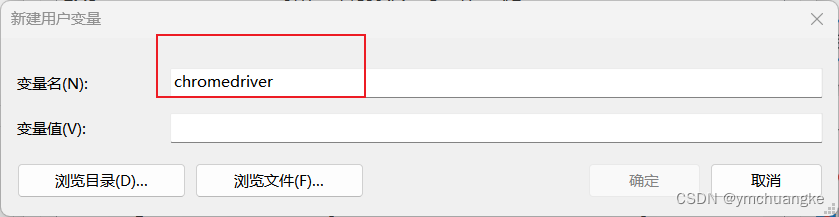
5.4.2名字起个chromedriver,变量值复制前面chrome的路径即可,然后点击确定即可

然后一路确定即可!
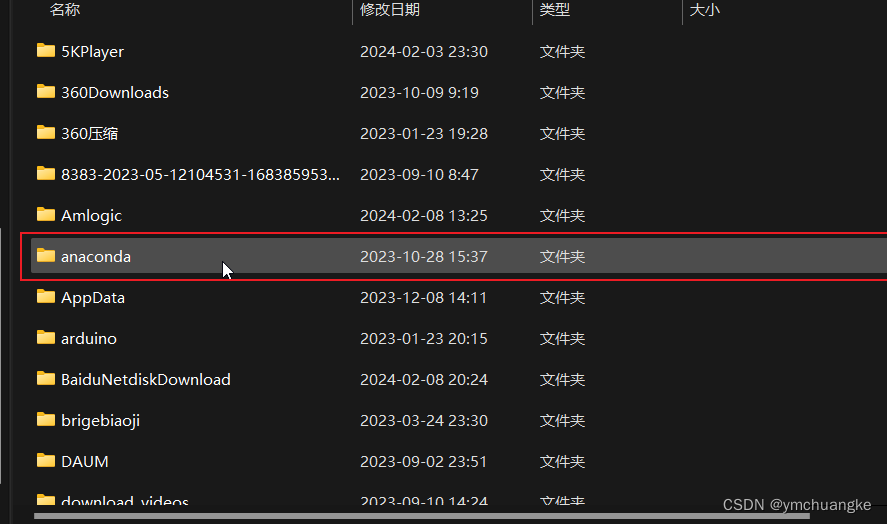
5.5将chromedriver.exe放在anaconda安装路径下的Scripts的目录下如下:
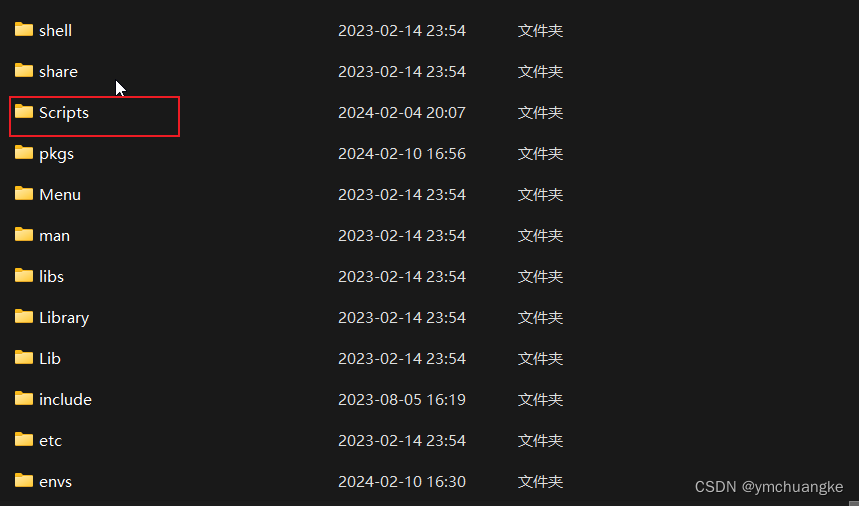
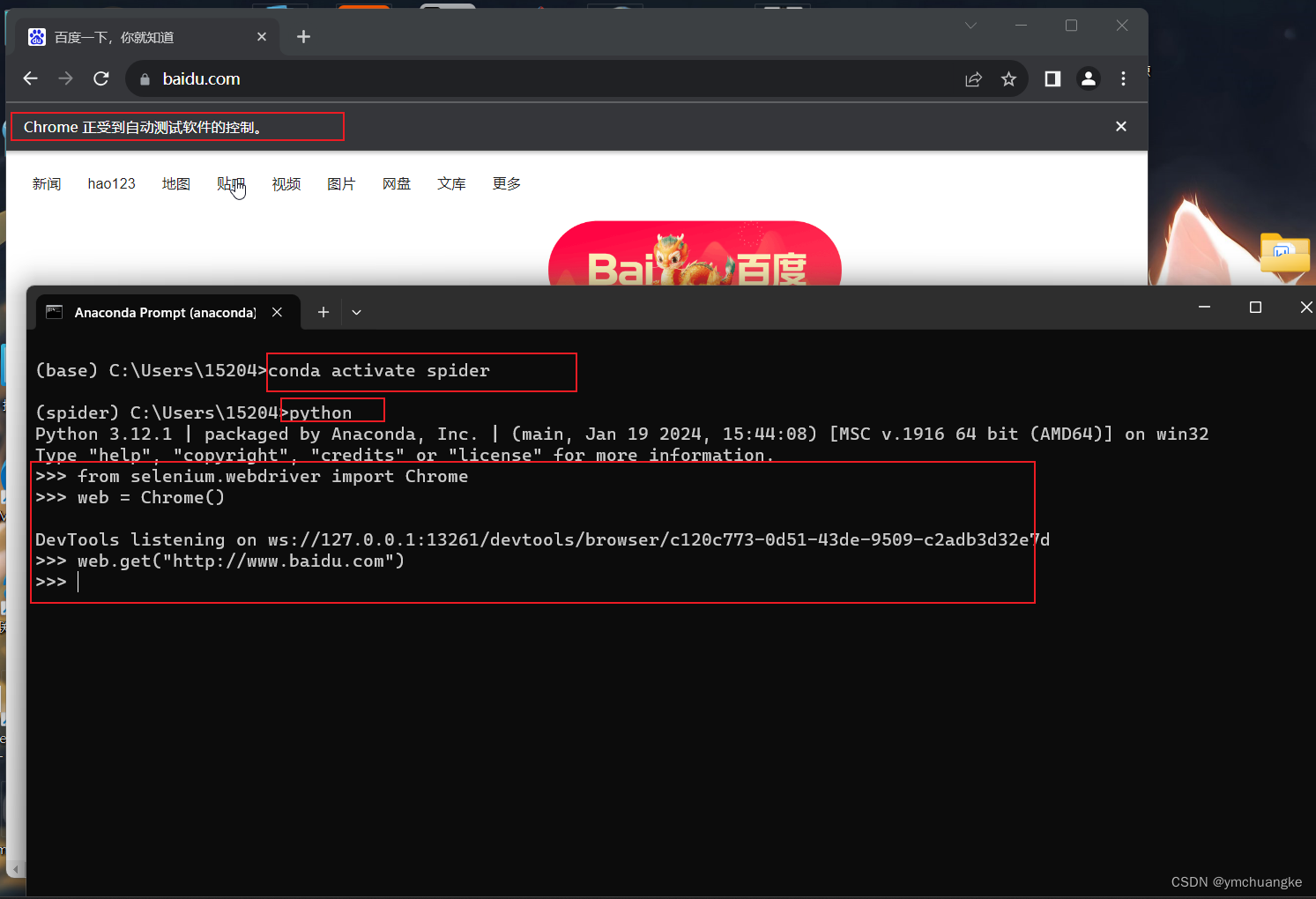
5.6验证chromedriver是否安装成功
#输入如下代码:
python
from selenium.webdriver import Chrome
web = Chrome()
web.get("http://www.baidu.com")
出现下述结果,则说明配置成功!!
拓展:对于其它浏览器的驱动,同样的方法,自己配置即可。
6.安装PhantomJS
PhantomJS 是一个无界面 、可脚本编程的 WebKit 浏览器引擎,它支持多 Web 标准 DOM操作、 ss 选择器、 JSON Canvas 以及 SVG。
Selenium 支持 PhantomJS ,这样在运行的时候就不会再弹出浏览器了,而且 PhantomJS 的运行效率也很高,同时支持各种参数配置,使用很方便。
6.1去官网选择相应的版本下载
- 官方网站
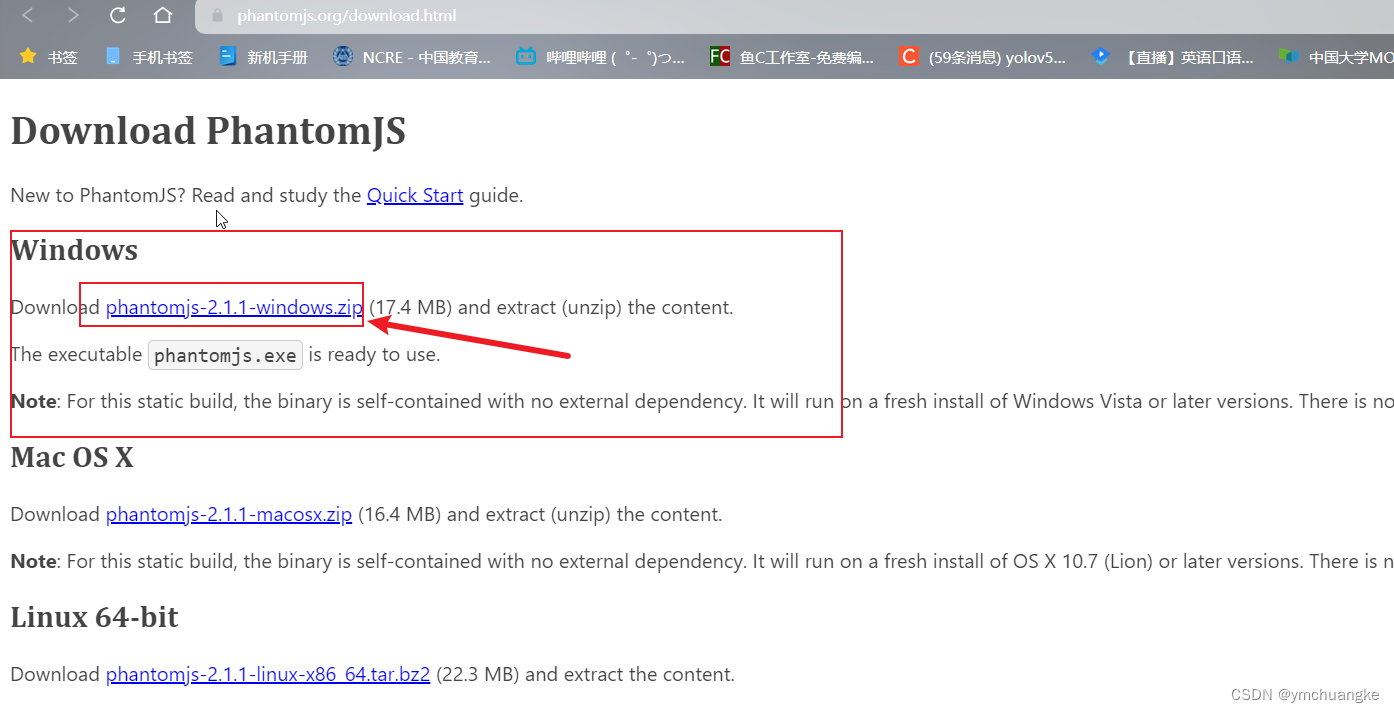
2.解压下载的zip文件,将bin文件夹的路径添加到环境变量
如下:
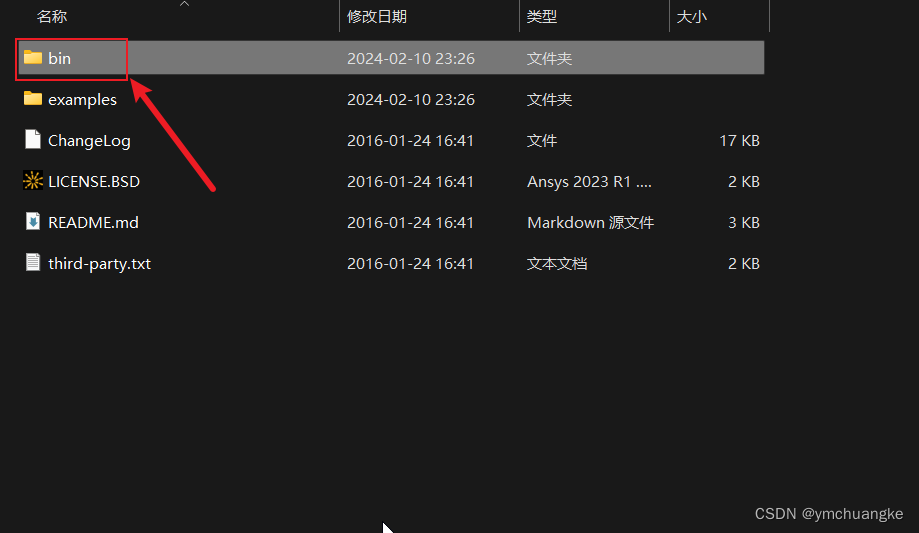
复制下面路径
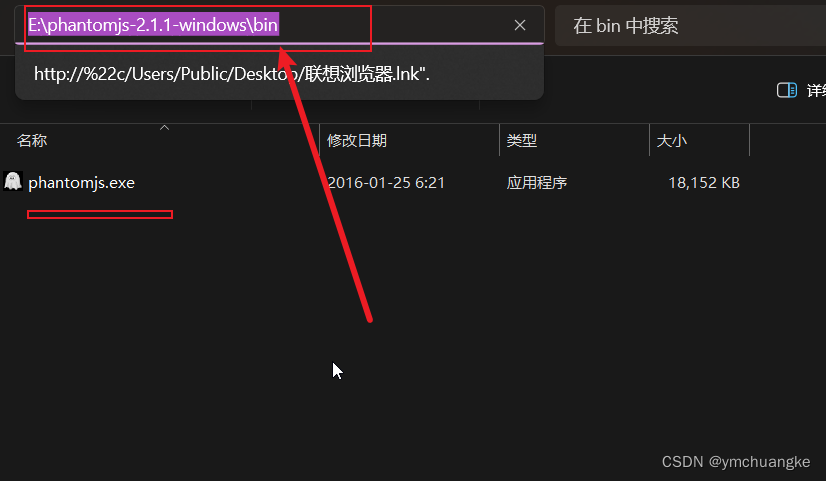
6.2配置环境变量
方法和前面一样
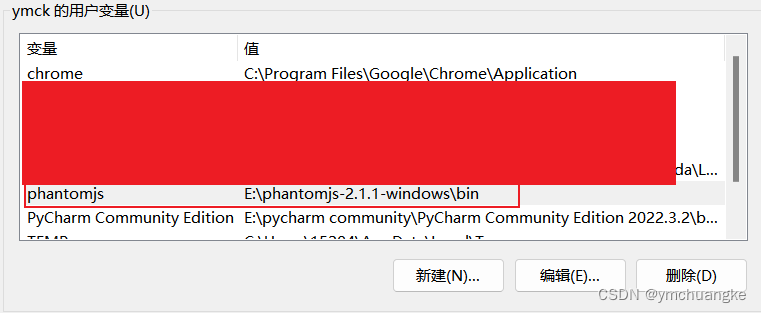
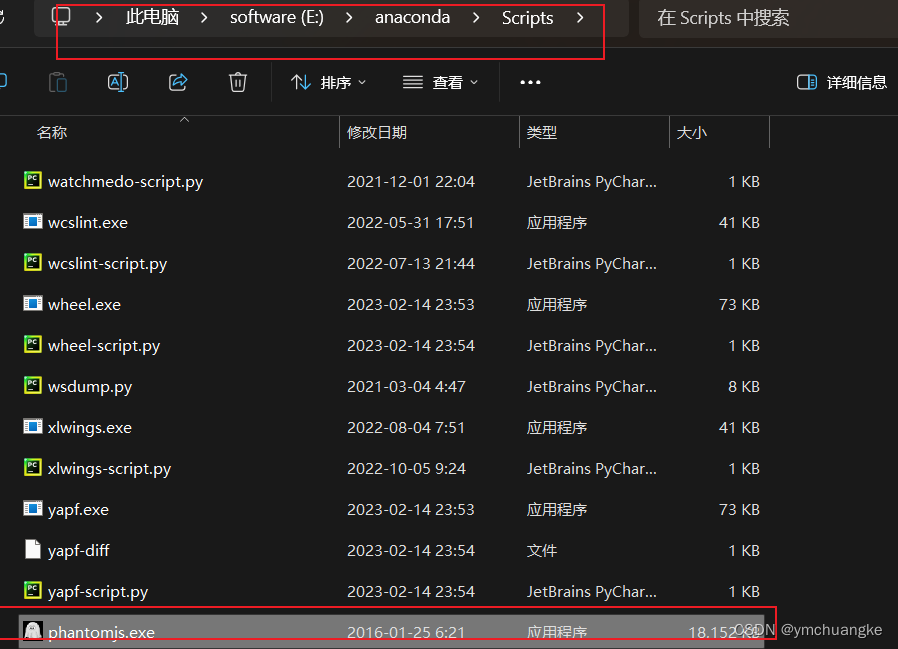
6.3测试是否配置成功
#第一种情况
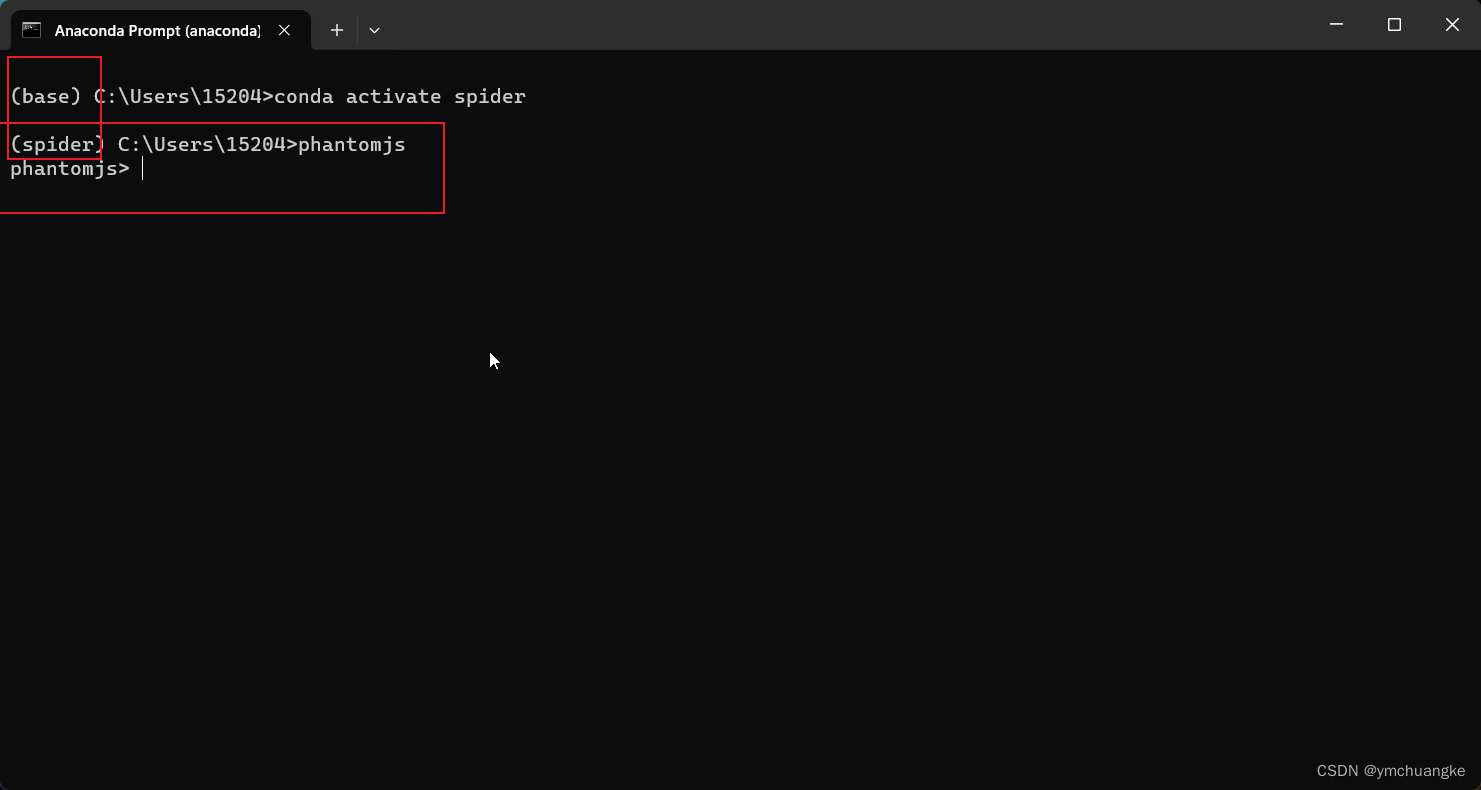
#1.打开anaconda prompt激活环境
conda activate spider
#2.输入phantomjs
phantomjs
#若出现下述界面则正确
#或者下面代码
#第二种情况
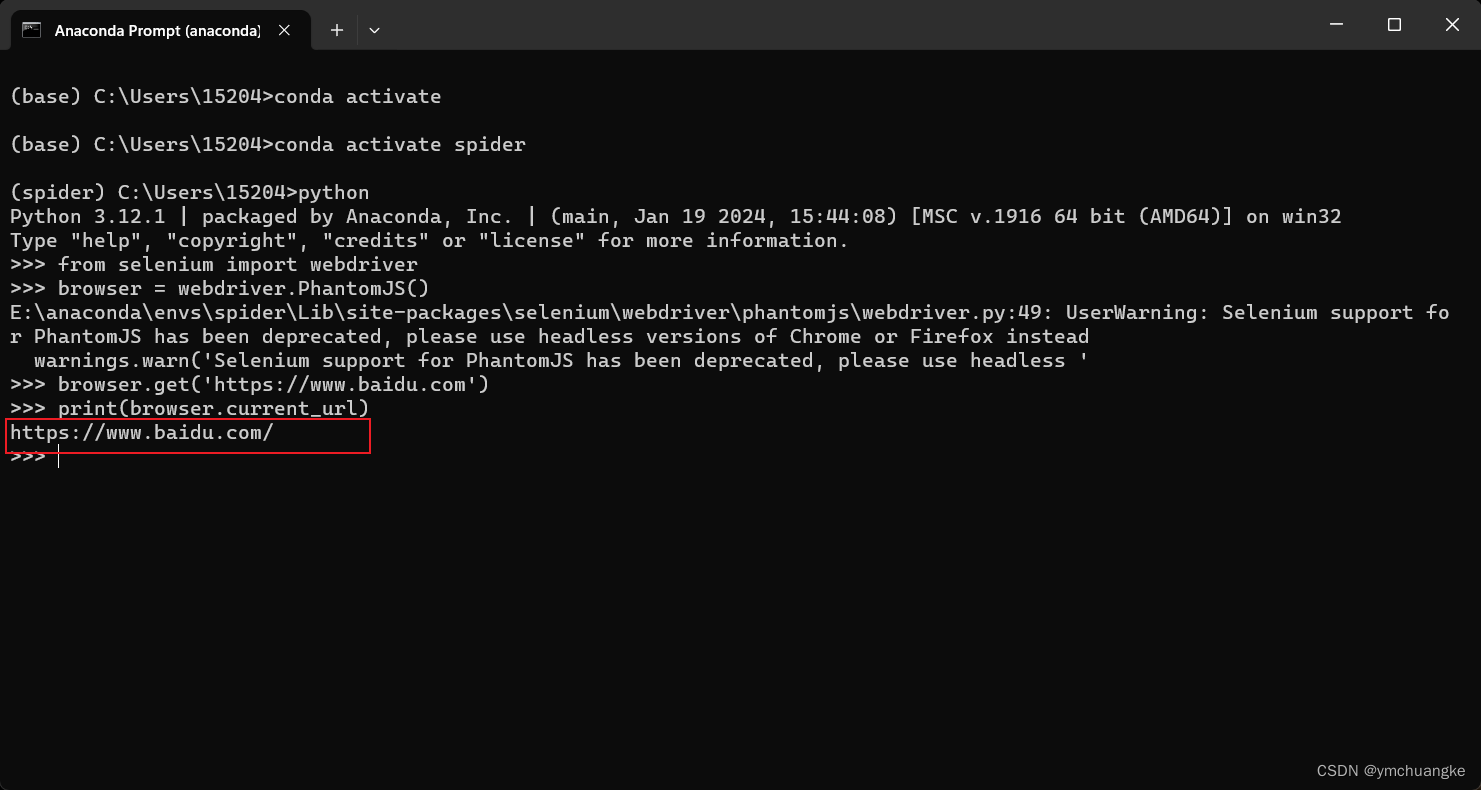
python
from selenium import webdriver
browser = webdriver.PhantomJS()
browser.get('https://www.baidu.com')
print(browser.current_url)
第一种情况:
第二种情况:
7.安装aiohttp
7.1安装
requests 库是一个阻塞式 HTTP 请求库,当我们发出一个请求后,程序会一直等待服器响应,直到得到响应后,程序才会进行下一步处理 其实,这个过程比较长,如果程序可以在这个等待过程中做一些其他的事情,如进行请求的调度 响应的处理等,那么效率可以大幅度提高。
aiohttp 就是这样一个提供异步 We 服务的库,使用异步请求库进行数据抓取时, 会大大提高效率。
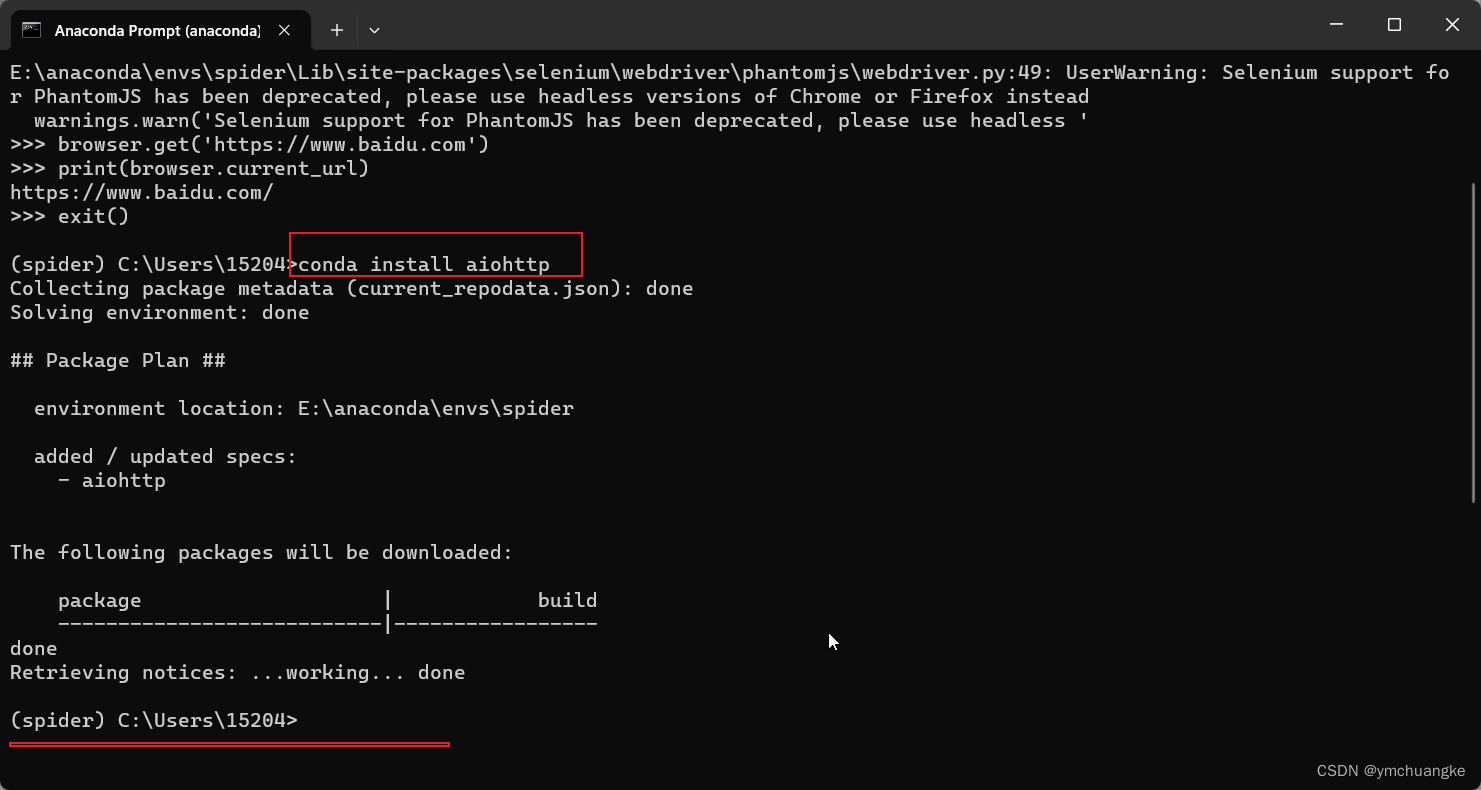
#1.激活conda虚拟环境
conda activate spider
#2.安装aiohttp
conda install aiohttp
7.2验证
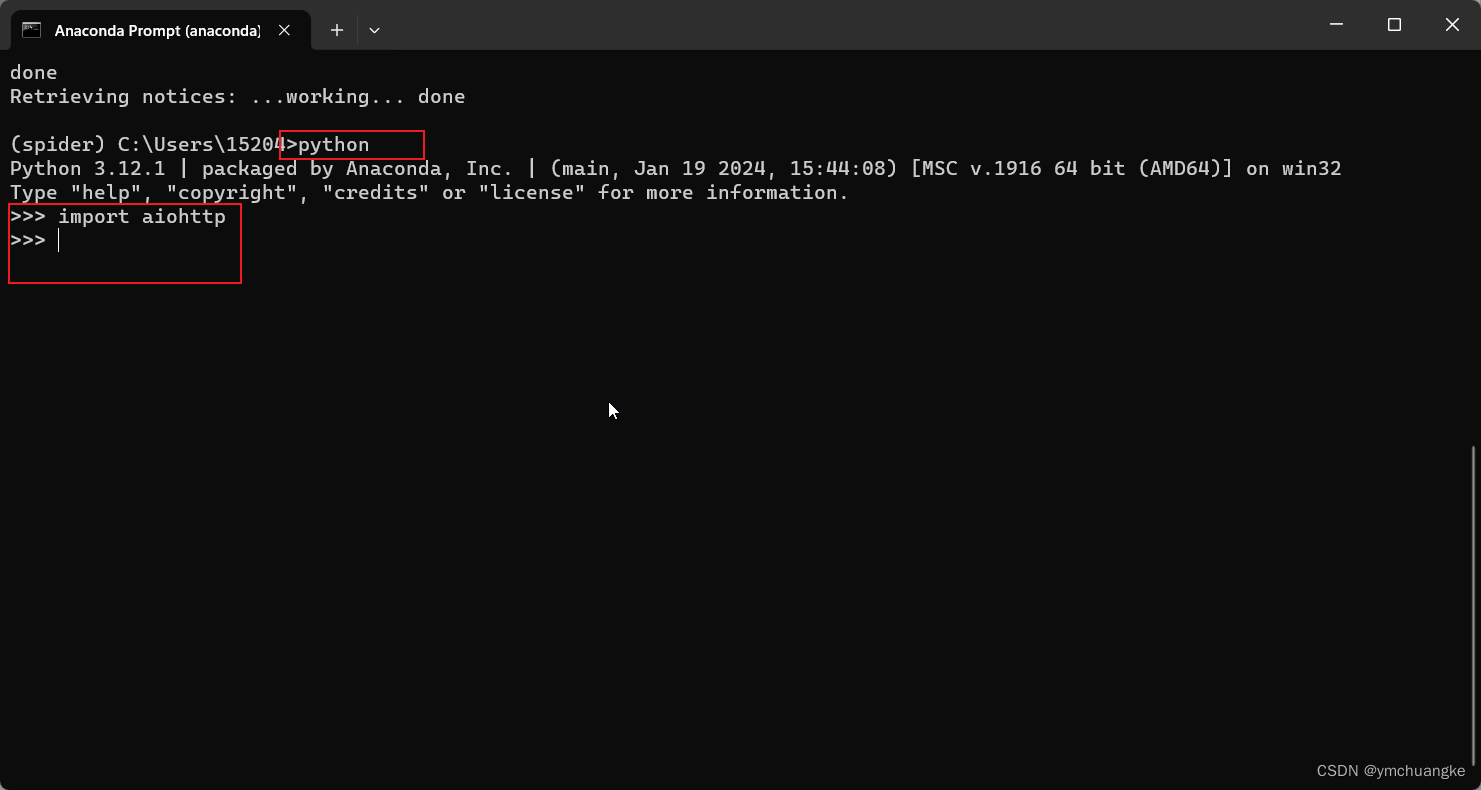
python
import aiohttp
#如果没有错误报出,则证明库已经安装好了
#结果如下:
接下来会写解析库的安装。