问题排查利器 - 分布式 trace
在分布式系统开发中,系统间的调用往往会横跨多个应用之间的接口。负责的调用链路也导致了,当线上环境出现问题时,例如请求失败、延迟增加或错误发生,我们无法第一时间确定是哪个环节出了问题,这给故障排查和修复带来了挑战。这时候分布式跟踪就变得至关重要。
1、什么是分布式 trace
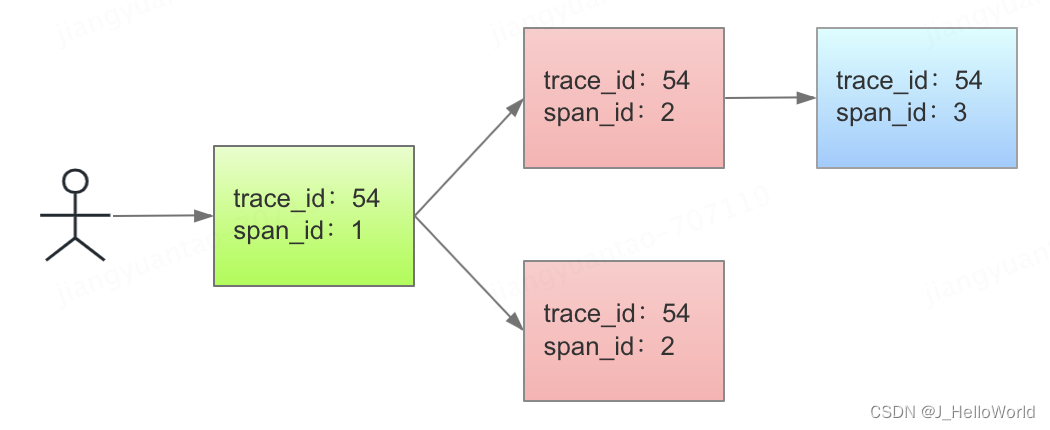
分布式跟踪的目标是收集和分析整个分布式系统中的请求路径和性能数据,以便开发人员可以更好地理解系统中的瓶颈和问题。它通过在应用程序的不同组件之间传递唯一的标识符(通常称为跟踪 ID)来实现这一点,以便跟踪一个请求在系统中的流动。上图中的 span_id 可以理解为应用标记ID,而 trace_id 是请求标记ID,贯穿整个请求且保持不变的。
当一个请求进入分布式系统时,它被赋予一个唯一的跟踪 ID。该跟踪 ID被传递到系统的不同组件中,每个组件在处理请求时都会记录自己的操作并将跟踪 ID 进一步传递给下一个组件。这样,整个请求路径就可以被跟踪和记录下来。
2、分布式 trace 与 日志配合
分布式 trace 告诉了我们服务的执行链路,而日志则提供了具体的上下文内容,我们将分布式跟踪数据和日志数据进行关联和展示,可以提供更全面、准确和统一的信息,帮助我们更好地理解系统行为、定位问题,并建立监控和警报系统。这样可以快速解决故障,优化性能,提高系统的可靠性和可用性。
那怎么将 traceId 标记到我们的每一个请求中呢? 最简单的方式就是给每个请求的所有方法都增加一段写入 traceId 的代码,但是这种对代码的侵入性太大了,我们实现业务逻辑的同时还需要考虑是否记录了 traceId ,所以这里我们通过代码增强的手段来实现 traceId 的传递。
a、使用代理增强管理 trace-id
原理是在每个请求处理线程中通过ThreadLocal存储和获取Trace ID,确保Trace ID的唯一性和正确性。
@Aspect
@Component
public class TraceAspect {
public static final String TRACE_ID = "trace-id";
@Around("execution(* com.fighting.enhance.test.*.*(..))")
public Object traceMethodExecution(ProceedingJoinPoint joinPoint) throws Throwable {
// 不存在则增加 traceId
String traceId = MDC.get(TRACE_ID);
if (StringUtils.isBlank(traceId)) {
MDC.put(TRACE_ID, UUID.randomUUID().toString());
}
// 执行被增强的方法
Object result = joinPoint.proceed();
// 删除本次请求 traceId
MDC.remove(TRACE_ID);
return result;
}
}b、配置logback-spring.xml
打开logback-spring.xml配置文件,并在其中添加一个自定义的PatternLayout模式,用于包含Trace ID。在该模式中,使用%X{trace-id}来引用Trace ID。
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<conversionRule conversionWord="clr" converterClass="org.springframework.boot.logging.logback.ColorConverter"/>
<conversionRule conversionWord="wex" converterClass="org.springframework.boot.logging.logback.WhitespaceThrowableProxyConverter"/>
<property name="CONSOLE_LOG_PATTERN" value="%clr(%d{yyyy-MM-dd HH:mm:ss.SSS}){faint} %clr(%5p) %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %clr(%-40.40logger{39}){cyan} %clr(:){faint} -%X{trace-id} %X{notifyTrackId} %m%n%wex"/>
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}</pattern>
<charset>utf8</charset>
</encoder>
</appender>
<!--异步输出-->
<appender name="async_console_log" class="ch.qos.logback.classic.AsyncAppender">
<includeCallerData>true</includeCallerData>
<!-- 不丢失日志.默认的,如果队列的80%已满,则会丢弃TRACT、DEBUG、INFO级别的日志 -->
<!--<discardingThreshold>0</discardingThreshold>-->
<!-- 更改默认的队列的深度,该值会影响性能.默认值为256 -->
<queueSize>500</queueSize>
<!-- 应用停止或重新部署时,等待appender刷新队列的时间,超过该时间,队列里的日志事件被丢弃,默认1秒 -->
<maxFlushTime>3000</maxFlushTime>
<!-- 添加附加的appender,最多只能添加一个 -->
<appender-ref ref="CONSOLE"/>
</appender>
<root level="INFO">
<appender-ref ref="async_console_log"/>
</root>
</configuration>
c、 测试代码
@Slf4j
@Component
public class TestLogTrace {
public void test(){
log.info("com.fighting.enhance.test.TestLogTrace.test");
log.info("com.fighting.enhance.test.TestLogTrace.test1");
log.info("com.fighting.enhance.test.TestLogTrace.test2");
}
}
@Slf4j
@SpringBootTest
@RunWith(SpringRunner.class)
class ApplicationTests {
@Resource
private TestLogTrace testLogTrace;
@Test
void contextLoads() {
testLogTrace.test();
log.info("testLogTrace.test after");
}
}测试的日志输出中即可看到 traceId
2024-02-05 18:55:09.013 INFO 10900 --- [ main] com.fighting.enhance.test.TestLogTrace : -a981f71b-3bd8-42e2-9683-b4f8a81c629f com.fighting.enhance.test.TestLogTrace.test
2024-02-05 18:55:09.013 INFO 10900 --- [ main] com.fighting.enhance.test.TestLogTrace : -a981f71b-3bd8-42e2-9683-b4f8a81c629f com.fighting.enhance.test.TestLogTrace.test1
2024-02-05 18:55:09.014 INFO 10900 --- [ main] com.fighting.enhance.test.TestLogTrace : -a981f71b-3bd8-42e2-9683-b4f8a81c629f com.fighting.enhance.test.TestLogTrace.test2
2024-02-05 18:55:09.014 INFO 10900 --- [ main] com.fighting.ApplicationTests : - testLogTrace.test after
3、logback配置文件 [%X{traceId}] 的取值逻辑
通过logback的MDC(Mapped Diagnostic Context)机制来获取Trace ID的值,MDC是logback框架提供的一种机制,用于在日志输出中存储和访问线程特定的上下文信息。它使用ThreadLocal实现,并允许你在应用程序中的不同组件之间共享和传递上下文信息。
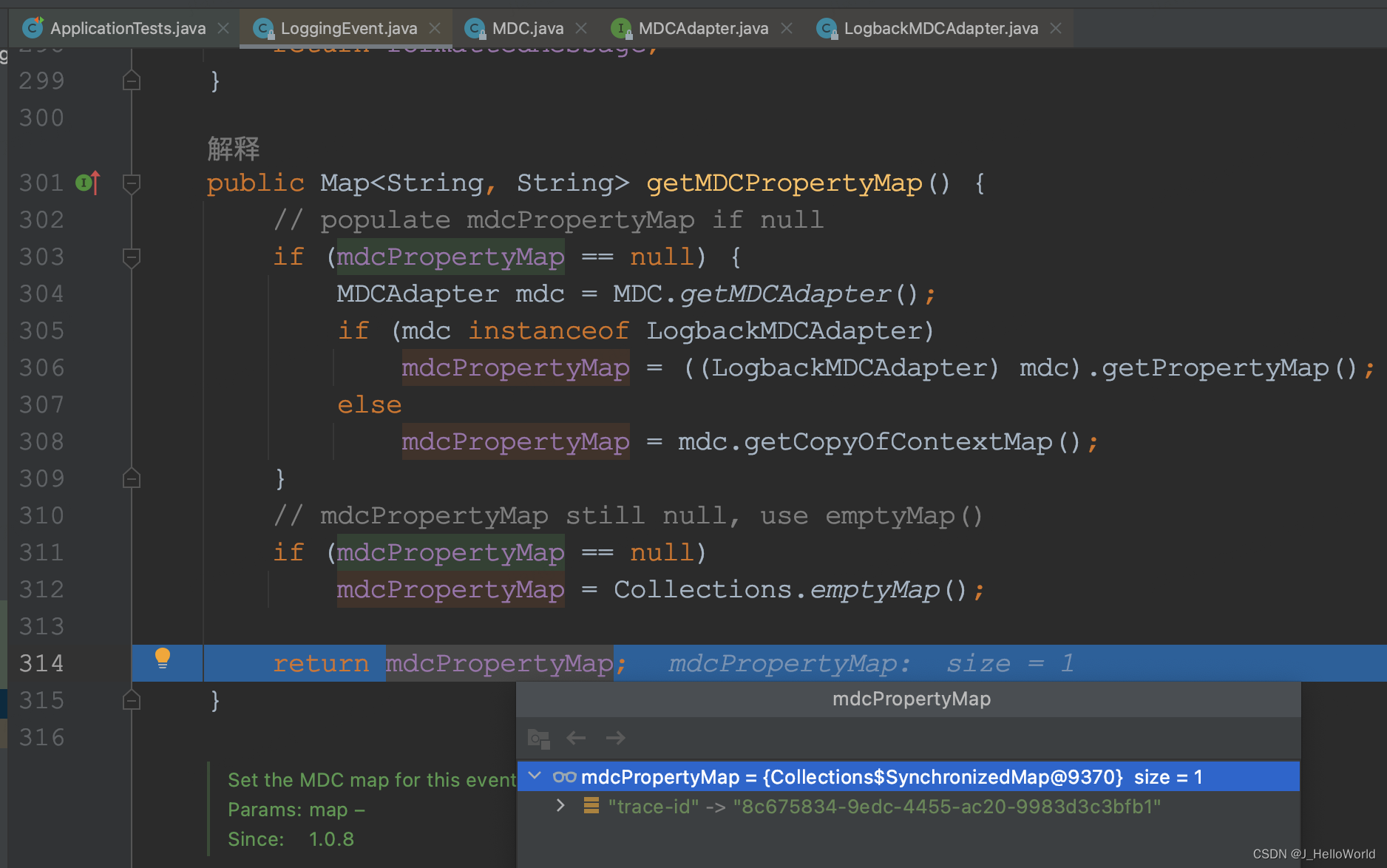
debug 看下获取 trace-id 的源码,其中 getPropertyMap 中的 copyOnThreadLocal 是通过将 MDC 的内容复制到当前线程的ThreadLocal中,以便在多线程环境中能够正确地访问和使用MDC设置的数据。
4、总结
不仅在日志记录上可以使用,分布式 trace 与 监控可视化配合使用,还可以帮助我们更清晰的知道我们的服务端实在那一个环节出了问题,服务出现异常的比例等等
另外在高并发场景下全量日志的打印十分消耗性能,我们也可以利用 trace-id 来实现日志采样打印,采样简单实现,可以通过计算 trace-id %10==0 ,只将满足条件的内容进行日志打印,当然也可以直接通过降级的手段,只打印 error 级别的日志。