【数据结构】KMP算法细节详解
KMP算法细节详解
- 前言
- 一、字符串匹配问题
- 1.BF算法
- 2.KMP算法
- 二、next数组
- 三、手写nex思想
- 四、机算next思想
- 五、next数组细节理解
- 六、nextVal数组
- 七、KMP算法代码实现
- 八、nextVal数组代码实现
- 完结
前言
KMP算法是为了字符串匹配问题而被研究出来的,字符串匹配问题就是查看一个字符串A是否是字符串B的子串,如果是字串的话,在B的哪个位置?此算法代码简练,但理解起来非常困难,建议挑出一整块时间来专门学习,本文作者写的非常用心,还不了解KMP的小伙伴一定要静下心来慢慢细品,你一定会有所收获🍊
一、字符串匹配问题
如果遇到这种在一个字符串中寻找另一个字符串的子串这种问题,大多数人第一时间想到的肯定是通过暴力匹配算法来完成,也就是Brute-Force算法简称BF算法,时间复杂度为O(m*n),如果有上千行上万文本呢?,时间成本一定会很高,所以D.E.Knuth,J.H.Morris和V.R.Pratt三位大神提出了KMP算法,KMP(Knuth-Morris-Pratt )算法也由他们三个的名字命名。
1.BF算法

2.KMP算法
肉眼可见的差距

二、next数组
next数组是KMP算法的精髓
KMP之所以会这样高效的查找字符串全都是next数组的功劳,也就是动图中字符串下面的数字,KMP算法会根据生成的next数组来移动,如果比对错误,将子串的首位直接移动到主串对比错误的位置,随后根据next数组提供的下标向左移动x格,图中下标为-1,所以向左移动-1格,就是向右移动一格

三、手写nex思想
注:上面图片的下标是按照nextVal生成的,next数组生成请看下面,nextVal是next的改进版,后面会讲到,我们先理解next数组生成原理
next数组的值计算的是从第n位开始前面字符串的最大公共前后缀的长度,不包括整个字符串本身,比如有这样一个字符串

从第一位向前看,没有字符,没法求,所有人为规定next[0]固定为-1(这里也有部分老师讲解第一位是0,其实思想都一样只不过是下标不一样而已,我们学的是思想不用在意这些),从第二位b向前看,也没有公共前后缀,next[2]为0,从第三位c向前看,也没有,next[3]为0,第四位a向前看,也没有next[4]为0,第五位b向前看,此时,最大公共前后缀为a,长度就是1,next[5]为1,从第六位向前看,最大公共前后缀为ab,长度为2,所以next[6]为2

四、机算next思想
比如一个字符串abcda,此时next数组的最大公共前后缀是1,那如果加个b呢,abcdab,此时最大公共前后缀是2,加个c呢,最大公共前后缀就变成3,经过大量数据观察,发现每次最大公共前后缀最多+1。
如果一个字符串abcdeffabcde,此时最大公共前后缀是3,如果在后面加一个g,这个字符串变成abcdffabcdg,最大公共前后缀直接就变成了0,也就是说每次最大公共前后缀可能直接减少到0。
如果增加一个字符的时候,发现新增加的字符与前缀后面的字母不相同了,就会进行减少,如下图所示,一次次进行查找,当前新的最大相同前后缀是什么,直到查找到位置。

这种方法未免有些麻烦,我们可以利用已有的条件进行优化,如果没有找到,直接找到其对应的next数组的值的字符串的下标,进行比对,如果成功,将找打他的next数组的值进行+1,就是next数组最新一位的值,如果找到最后,会找到字符串下标为0的位置,0位置的next数组值是-1,拿到-1的话数组会报错,这里写代码的时候不要忘记处理。

为什么可以这么做呢?因为前面红框的前缀,等于后面红框的后缀,我们在此基础上向后进行对比一位即可判断出next数组最新一位的值。
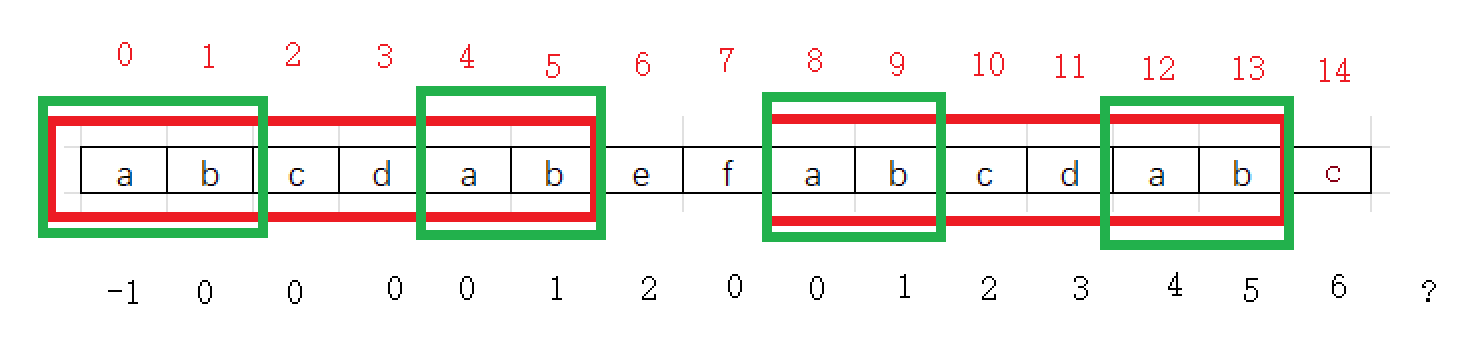
五、next数组细节理解
为什么按照next数组移动就可以保证不跳过匹配成功的字符串呢?
前面说过,如果匹配失败子串的首字符的位置会移动到匹配失败的位置,再向左移动next数组[i]格,匹配失败的那一位的next数组记录着前面字符的最大公共前后缀长度,由于前面的前缀都已经于主串匹配过了,只不过后缀后面的位置对不上,那么我们直接将后缀的起始位置对准匹配失败的位置,也就是向左移动next[i]个长度(也就是向左移动最大公共前后缀的长度),就能保证跳跃过程中没有错过任何可以匹配成功的串。还可以使主串中已经成功配对的后缀于子串的前缀相匹配,再向后匹配。

下图中,①=②=③=④,所以移动回去时保证前面的后缀会与匹配失误的地方对齐

上面展示的是有公共前后缀的情况,那么如果整个字符串都没有公共前后缀会怎么样?
- 将发挥KMP算法的最大作用!
我们只需大胆向后跳,不用再往前跳了
此动画后半部省略掉了,找到最后没有发现相同串

六、nextVal数组
讲完了next数组,接下来讲解nextval数组,nextVal数组是next数组的改进版,因为next数组还有改进的空间,那就是在生成数组的时候对在next数组的基础上,对失配字符的next数组下标进行读取,读取数组下标到字符串的下标位置,然后进行比较,如果不相等,那么不对其进行优化,如果读取失配字符的next数组下标到字符串的下标位置相等,那么将读取失配字符的next数组下标到字符串下标,然后取出这个位置的next数组的值到失配位置的next数组。(这里难理解,多看几次)

这样做的原理是什么呢?
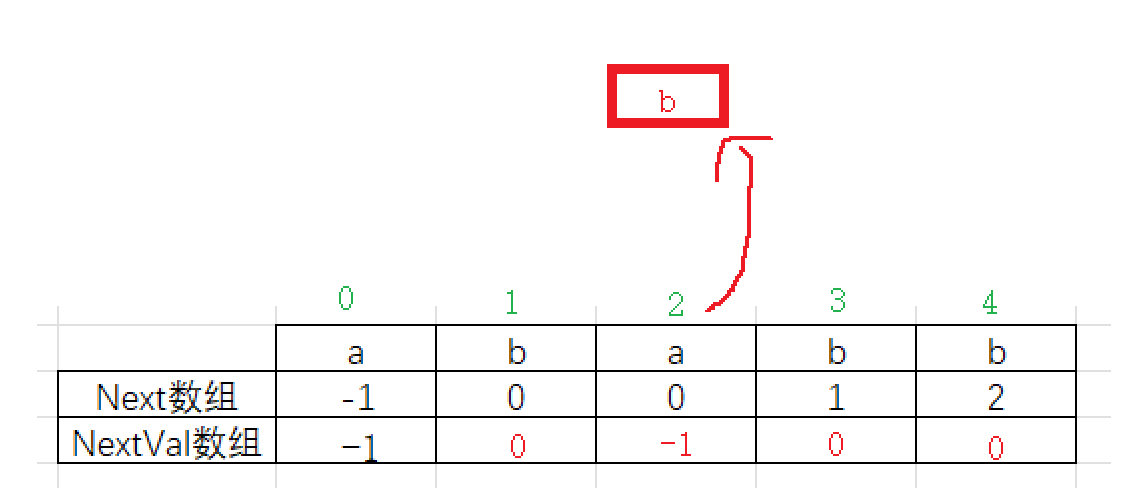
如果此时a在与上面的字符串进行配对,那么a此时与b失配,说明对比的数是非a,按照next数组原理我们将下标为0的位置移动到上面b的位置,可是a已经和b对比过了,将下标为0的a移动过去必然也会失配,所有nextVal要先对失配的位置与next数组的值对应的下标的字符进行比较,相等就会读取其对应位置的next下标到失配位置的next下标。
七、KMP算法代码实现
讲完了原理,这里是代码实现。
- 可以将里面的next替换为nextVal,两者都为独立的数组生成函数。
#define _CRT_SECURE_NO_WARNINGS 1
#include <stdlib.h>
#include <assert.h>
#include <stdio.h>
void getNext(int * next,const char* s,int len)
{
assert(next && s); //判断两个指针是不是空指针
int i = 0, cur = -1; //i是当前位置、cur是当前最大相同前后缀的长度
next[0] = cur;
while (i < len)
{
if (cur==-1||s[i]==s[cur]) //cur为-1的时候也要恢复成0同时i++
{
next[i + 1] = cur+1;
cur++; //cur恢复成0
i++;
}
else
{
cur = next[cur]; //如果失配,直接找到这个位置的next数组的值给到cur
}
}
}
int kmp(const char* p, const char* s)
{
int len = strlen(s);
int* next = (int*)malloc(sizeof(len) * len);
getNext(next, s, len - 1);
assert(next);
int i = 0, j = 0; //定义i为字符串下标,j为next数组下标
while (p[i])
{
if (j==-1||p[i] == s[j]) //如果next数组下标为-1,next数组下标恢复为0,字符串下标+1
{
i++;
j++;
if (s[j] == '\0') //如果字符串下标为‘\0’,查找成功返回i-j也就是字符串匹配成功位置的收个字符的下标
{
free(next);
next = NULL;
return i - j;
}
}
else
{
j = next[j]; //将此位置的next数组下标对准字符串对应位置得下标
}
}
free(next);
next = NULL;
return -1; //如果p[字符串下标]=='\0',跳出循环,证明查找失败,返回-1
}
int main()
{
char p[] = "abcdabecabcfdsafdasdasfdasfasdfasfdasafdsbc";
char s[] = "abecab";
printf("%d", kmp(p, s));
}
八、nextVal数组代码实现
void getNextVal(int *next,const char* s,int len)
{
assert(next);
int i = 0, cur = -1;
next[0] = cur;
while(i < len)
{
if (cur == -1 || s[i] == s[cur]) //为-1注意处理
{
i++;
cur++;
if (s[i] != s[cur]) //比next数组增加一个判断
{
next[i] = cur;
}
else
{
next[i] = next[cur]; //如果相等,把next[cur]的值取过来
}
}
else
{
cur = next[cur];
}
}
}
完结
作者的话
KMP是一块硬骨头,建议各位能挑出一段长时间专门攻克它,不要今天看一点,明天再看一点,这样不会有收获,写代码不代表就已经真正理解了KMP,你最好要能熟练的讲给其他小伙伴KMP到底一种什么样的算法,记录一份详细的笔记,忘记的时候拿出来反复重温,最后如果觉得哪里没有理解,可以评论区留言或者私信作者,我会耐心地给大家来答疑解惑。当然如果有不足的地方还请各位帮忙补充。