【GPT-SOVITS-05】SOVITS 模块-残差量化解析
说明:该系列文章从本人知乎账号迁入,主要原因是知乎图片附件过于模糊。
知乎专栏地址:
语音生成专栏
系列文章地址:
【GPT-SOVITS-01】源码梳理
【GPT-SOVITS-02】GPT模块解析
【GPT-SOVITS-03】SOVITS 模块-生成模型解析
【GPT-SOVITS-04】SOVITS 模块-鉴别模型解析
【GPT-SOVITS-05】SOVITS 模块-残差量化解析
【GPT-SOVITS-06】特征工程-HuBert原理
1.概述
在 GPT-SOVITS 实现中,残差量化层是一个相对核心的改动。如前文所述,在 AR模块训练时,其semantic特征是基于预训练生成模型中残差量化层的输出。残差量化层的核心代码如下:
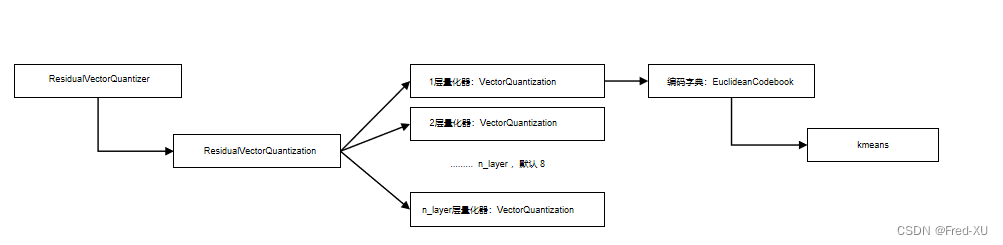
- ResidualVectorQuantizer 是残差量化编码器的封装,在生成模型中构建
- ResidualVectorQuantization 是残差量化编码器的具体实现,其默认包含8个量化编码器
- VectorQuantization。层与层之间用的是输入值和量化值的残差。
- VectorQuantization 是具体某一层的量化编码,将输入数据进行量化编码
- VectorQuantization 在进行量化编码时,其编码字典的实现为
Euclideanbook。其将输入数据做k均值聚类实现一个编码器,将k均值的中心点,作为量化字典。
2、EuclideanCodebook 实现
2.1、原理
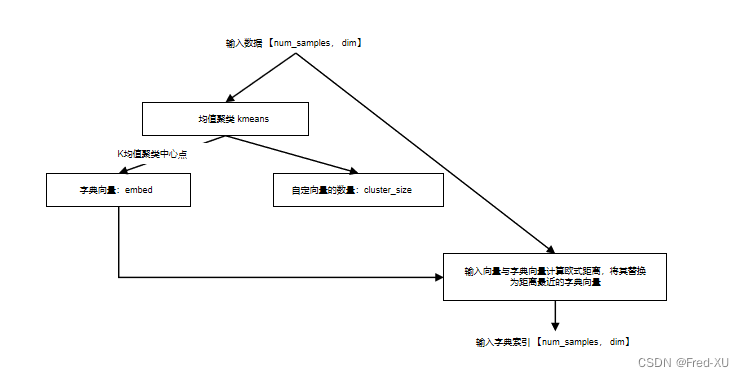
- 输入数据大小为【num_sample,dim】,前者为输入数据数量,后者为每个数据的向量维度 基于k均值聚类,codebook_size
- 参数为聚类K的中心点数量,即字典大小,kmeans_iters为迭代次数
- 完成k均值聚类后,原始数据各值与中心点计算欧式距离,以就近原则选择中心点作为量化的替代值
2.2、调试代码参考
book = EuclideanCodebook(
dim=30,
codebook_size=1024,
kmeans_init=True,
kmeans_iters=50,
decay=0.99,
epsilon=1e-5,
threshold_ema_dead_code=2)
quantize, embed_ind = book.forward(sample_data)
3、ResidualVectorQuantizer 实现
3.1、原理
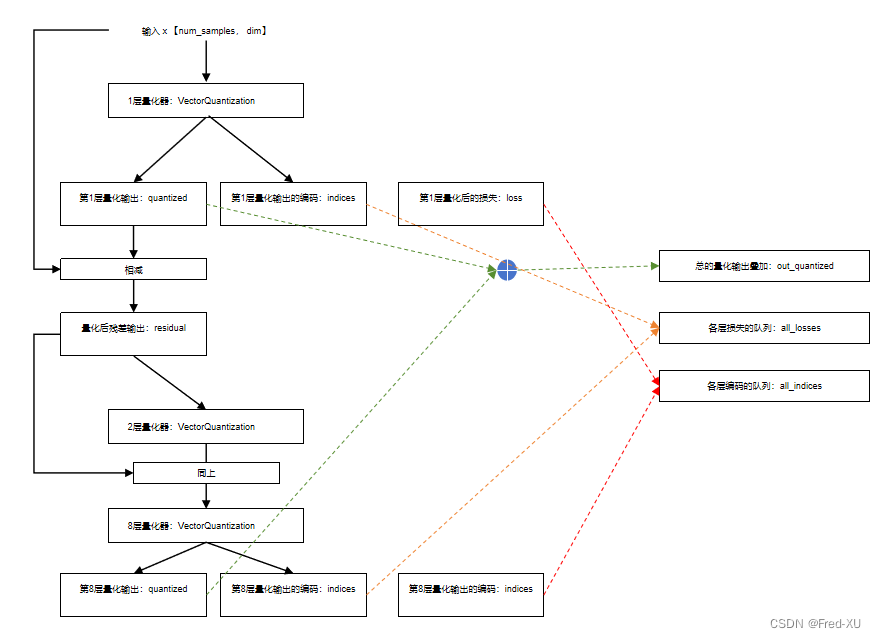
- 残差量化编码器有默认8个独立的量化器构成
- 在每一层的输出时输出三个值
all_losses = []
all_indices = []
out_quantized = []
n_q = n_q or len(self.layers)
for i, layer in enumerate(self.layers[:n_q]):
# quantized: 量化后的特征向量
# indices: 量化后的特征向量所对应的索引
# loss : 量化后的特征向量和原始特征的损失
quantized, indices, loss = layer(residual) # 进入下一层的输入是残差
residual = residual - quantized # 残差
quantized_out = quantized_out + quantized # 基于量化输出的总体累加输出
all_indices.append(indices)
all_losses.append(loss)
if layers and i in layers:
out_quantized.append(quantized)
out_losses, out_indices = map(torch.stack, (all_losses, all_indices))
return quantized_out, out_indices, out_losses, out_quantized
3.2、调试代码参考
rvq = ResidualVectorQuantization(
dim=30,
codebook_size=1024,
num_quantizers=8,
decay=0.99,
kmeans_init=True,
kmeans_iters=50,
threshold_ema_dead_code=2
)
sample_data_1 = torch.rand(1,30, 1000)
rvq.forward(sample_data_1, layers=[0])
codes = rvq.forward(sample_data_1)
indices = rvq.encode(sample_data_1)
print(rvq.decode(indices))