【数据结构与算法】:非递归实现快速排序、归并排序

🔥个人主页: Quitecoder
🔥专栏:数据结构与算法

上篇文章我们详细讲解了递归版本的快速排序,本篇我们来探究非递归实现快速排序和归并排序
目录
- 1.非递归实现快速排序
- 1.1 提取单趟排序
- 1.2 用栈实现的具体思路
- 1.3 代码实现
- 2.归并排序
1.非递归实现快速排序
快速排序的非递归实现主要依赖于栈(stack)来模拟递归过程中的函数调用栈。递归版本的快速排序通过递归调用自身来处理子数组,而非递归版本则通过手动管理一个栈来跟踪接下来需要排序的子数组的边界
那么怎样通过栈来实现排序的过程呢?
思路如下:
使用栈实现快速排序是对递归版本的模拟。在递归的快速排序中,函数调用栈隐式地保存了每次递归调用的状态。但是在非递归的实现中,你需要显式地使用一个辅助栈来保存子数组的边界
以下是具体步骤和栈的操作过程:
-
初始化辅助栈:
创建一个空栈。栈用于保存每个待排序子数组的起始索引(begin)和结束索引(end)。 -
开始排序:
将整个数组的起始和结束索引作为一对入栈。这对应于最初的排序问题。 -
迭代处理:
在栈非空时,重复下面的步骤:- 弹出一对索引(即栈顶元素)来指定当前要处理的子数组。
- 选择子数组的一个元素作为枢轴(pivot)进行分区(可以是第一个元素,也可以通过其他方法选择,下面我们还是用三数取中)。
- 进行分区操作,这会将子数组划分为比枢轴小的左侧部分和比枢轴大的右侧部分,同时确定枢轴元素的最终位置。
-
处理子数组:
分区操作完成后,如果枢轴元素左侧的子数组(如果存在)有超过一个元素,则将其起始和结束索引作为一对入栈。同样,如果右侧的子数组(如果存在)也有超过一个元素,也将其索引入栈 -
循环:
继续迭代该过程,直到栈为空,此时所有的子数组都已经被正确排序。
所以主要思路就两个:
- 分区
- 单趟排序
1.1 提取单趟排序
我们上篇文章讲到递归排序的多种方法,这里我们可以取其中的一种提取出单趟排序:
int Getmidi(int* a, int begin, int end)
{
int midi = (begin + end) / 2;
if (a[begin] < a[midi])
{
if (a[midi] < a[end])
return midi;
else if (a[begin] > a[end])
return begin;
else
return end;
}
else
{
if (a[midi] > a[end])
return midi;
else if (a[end] < a[begin])
return end;
else
return begin;
}
}
void QuickSortHole(int* arr, int begin, int end) {
if (begin >= end) {
return;
}
int midi = Getmidi(arr, begin, end);
Swap(&arr[midi], &arr[begin]);
int key = arr[begin];
int left = begin;
int right = end;
while (left < right) {
while (left < right && arr[right] >= key) {
right--;
}
arr[left] = arr[right];
while (left < right && arr[left] <= key) {
left++;
}
arr[right] = arr[left];
}
arr[left] = key;
QuickSortHole(arr, begin, left - 1);
QuickSortHole(arr, left + 1, end);
}
接下来完成单趟排序函数:
int singlePassQuickSort(int* arr, int begin, int end)
{
if (begin >= end) {
return;
}
// 选择枢轴元素
int midi = Getmidi(arr, begin, end);
Swap(&arr[midi], &arr[begin]);
int key = arr[begin]; // 挖第一个坑
int left = begin; // 初始化左指针
int right = end; // 初始化右指针
// 进行分区操作
while (left < right) {
// 从右向左找小于key的元素,放到左边的坑中
while (left < right && arr[right] >= key) {
right--;
}
arr[left] = arr[right];
// 从左向右找大于key的元素,放到右边的坑中
while (left < right && arr[left] <= key) {
left++;
}
arr[right] = arr[left];
}
// 将枢轴元素放入最后的坑中
arr[left] = key;
// 函数可以返回枢轴元素的位置,若需要进一步的迭代过程
return left;
}
1.2 用栈实现的具体思路
以下面这串数组为例:
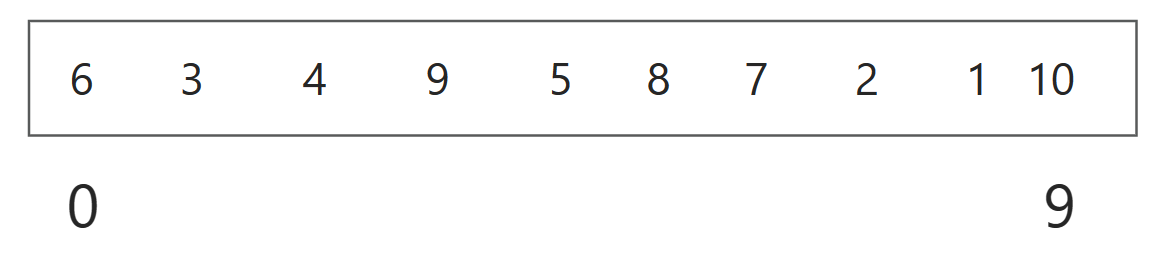
首先建立一个栈,将整个数组的起始和结束索引作为一对入栈
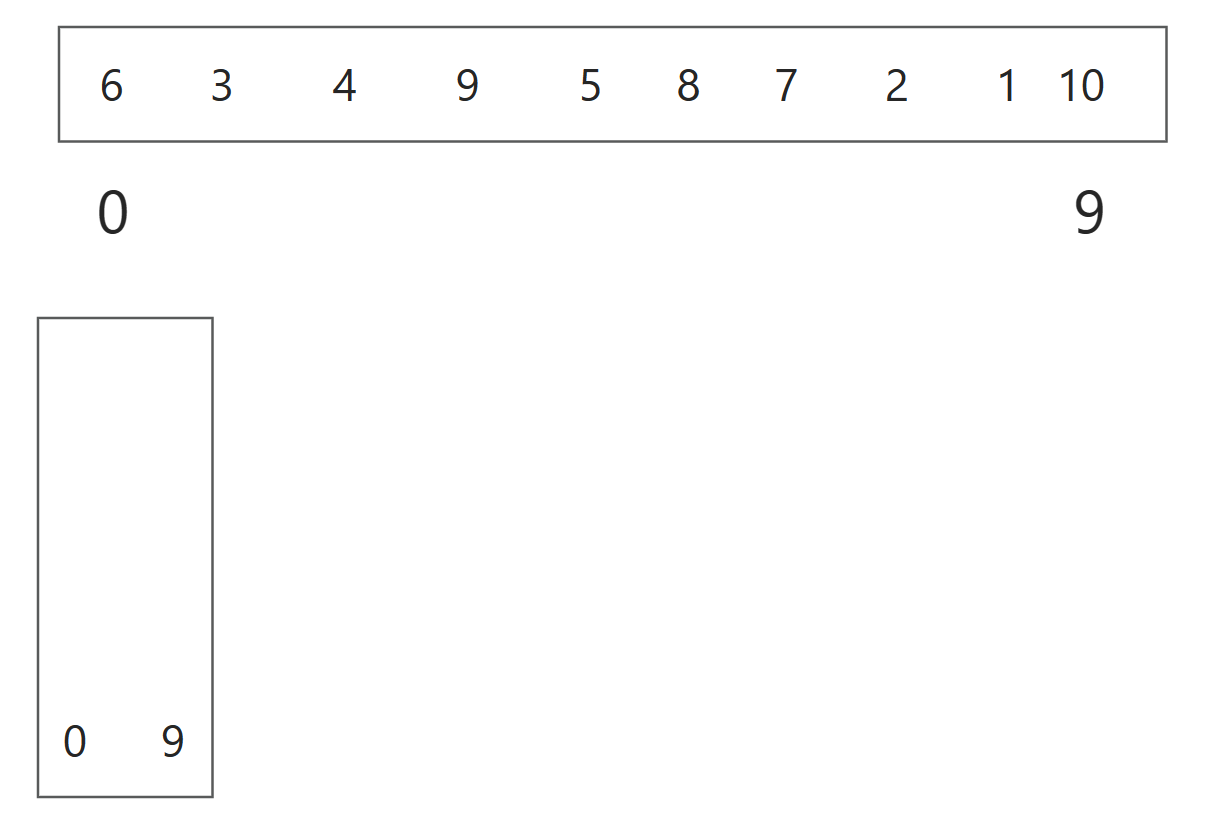
弹出一对索引(即栈顶元素)来指定当前要处理的子数组:这里即弹出0 9索引
找到枢轴6进行一次单趟排序:
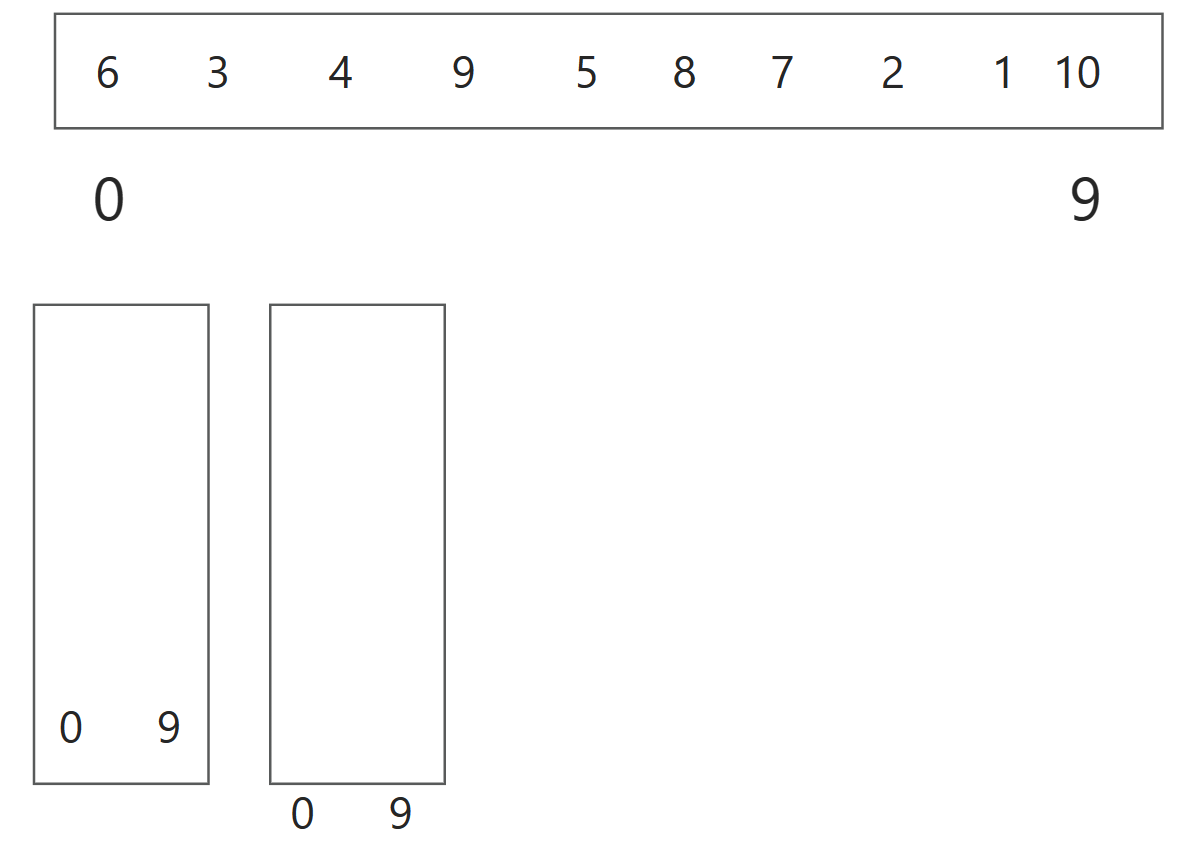
针对这个数组:
6 3 4 9 5 8 7 2 1 10
我们使用“三数取中”法选择枢轴。起始位置的元素为6,结束位置的元素为10,中间位置的元素为5。在这三个元素中,6为中间大小的值,因此选择6作为枢轴。因为枢轴已经在第一个位置,我们可以直接开始单趟排序。
现在,开始单趟排序:
- 枢轴值为
6。 - 从右向左扫描,找到第一个小于
6的数1。 - 从左向右扫描,找到第一个大于
6的数9。 - 交换这两个元素。
- 继续进行上述步骤,直到左右指针相遇。
经过单趟排序后:
6 3 4 1 5 2 7 8 9 10
接下来需要将枢轴6放置到合适的位置。我们知道,最终左指针和右指针会停在第一个大于或等于枢轴值6的位置。在这个例子中,左右指针会停在7上。现在我们将6与左指针指向的位置的数交换:
5 3 4 1 2 6 7 8 9 10
现在枢轴值6处于正确的位置,其左侧所有的元素都小于或等于6,右侧所有的元素都大于或等于6。
分区操作完成后,如果枢轴元素左侧的子数组(如果存在)有超过一个元素,则将其起始和结束索引作为一对入栈。同样,如果右侧的子数组(如果存在)也有超过一个元素,也将其索引入栈
我们接下来完成这个入栈过程:让两个子数组的索引入栈
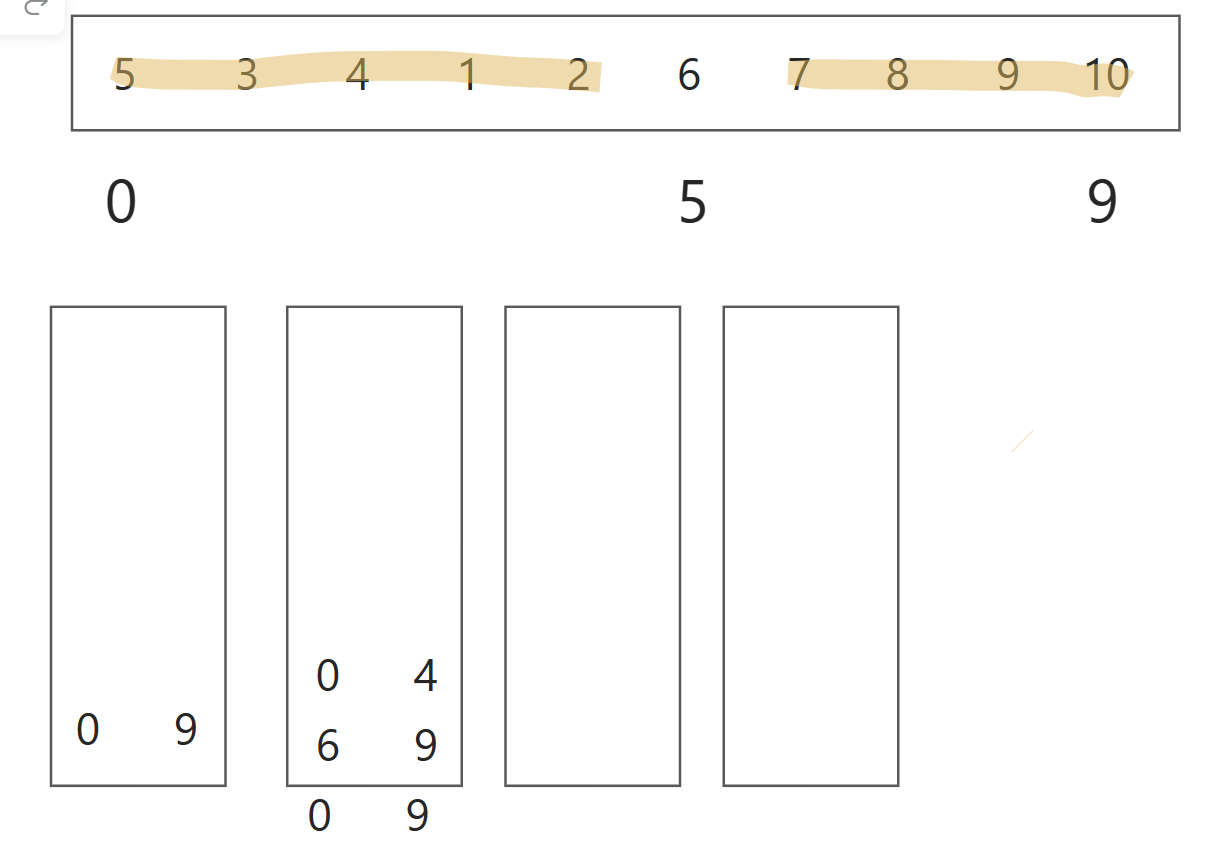
接着取0 4索引进行单趟排序并不断分区,分割的索引继续压栈,继续迭代该过程,直到栈为空,此时所有的子数组都已经被正确排序
1.3 代码实现
这里我们调用之前的栈的代码,基本声明如下:
typedef int STDataType;
typedef struct Stack
{
STDataType* a;
int top;
int capacity;
}ST;
void StackInit(ST* ps);
// 入栈
void StackPush(ST* ps, STDataType x);
// 出栈
void StackPop(ST* ps);
// 获取栈顶元素
STDataType StackTop(ST* ps);
// 获取栈中有效元素个数
int StackSize(ST* ps);
// 检测栈是否为空,如果为空返回非零结果,如果不为空返回0
bool StackEmpty(ST* ps);
// 销毁栈
void StackDestroy(ST* ps);
我们接下来完成排序代码,首先建栈,初始化,并完成第一个压栈过程:
ST s;
StackInit(&s);
StackPush(&s, end);
StackPush(&s, begin);
实现一次单趟排序:
int left = StackTop(&s);
StackPop(&s);
int right = StackTop(&s);
StackPop(&s);
int keyi = singlePassQuickSort(a, left, right);
注意这里我们先压入end,那么我们先出的就是begin,用left首先获取begin,再pop掉获取end
接着判断keyi左右是否还有子数组
if (left < keyi - 1)
{
StackPush(&s, keyi - 1);
StackPush(&s, left);
}
if (keyi + 1<right)
{
StackPush(&s, right);
StackPush(&s, keyi+1);
}
将此过程不断循环即为整个过程,总代码如下:
void Quicksortst(int* a, int begin, int end)
{
ST s;
StackInit(&s);
StackPush(&s, end);
StackPush(&s, begin);
while (!StackEmpty(&s))
{
int left = StackTop(&s);
StackPop(&s);
int right = StackTop(&s);
StackPop(&s);
int keyi = singlePassQuickSort(a, left, right);
if (left < keyi - 1)
{
StackPush(&s, keyi - 1);
StackPush(&s, left);
}
if (keyi + 1<right)
{
StackPush(&s, right);
StackPush(&s, keyi+1);
}
}
StackDestroy(&s);
}
这里思想跟递归其实是差不多的,也是一次取一组进行排序,递归寻找每个区间
2.归并排序
假如我们已经有了两个已经排序好的数组,我们如何让他们并为一个有序的数组呢?
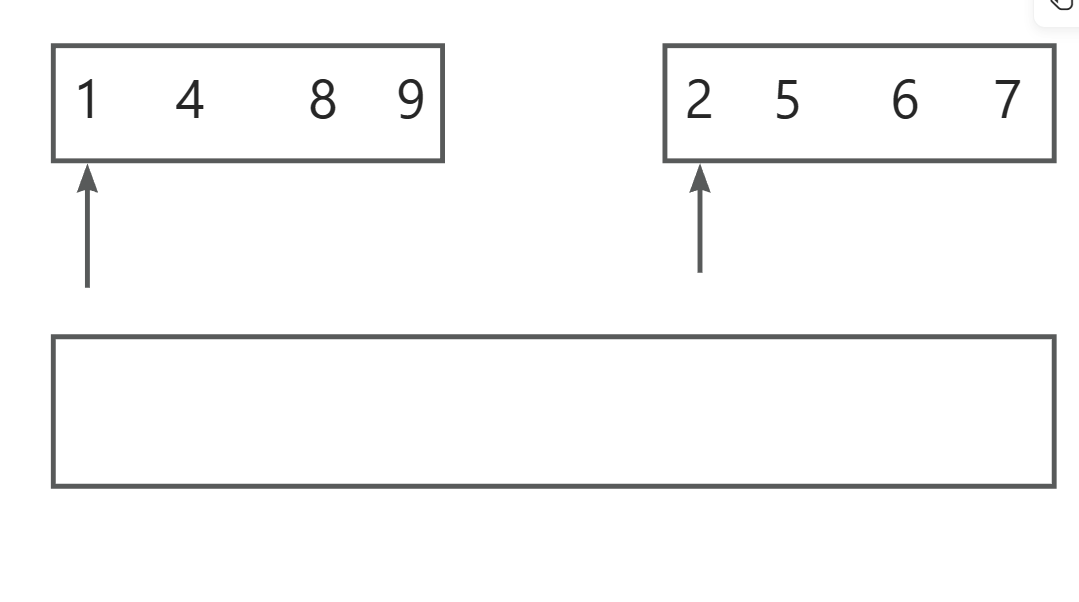
我们的做法就是用两个索引进行比较,然后插入一个新的数组完成排序,这就是归并排序的基础思路
那如果左右不是两个排序好的数组呢?
下面是归并排序的算法步骤:
-
递归分解数组:如果数组的长度大于1,首先将数组分解成两个部分。通常这是通过将数组从中间切分为大致相等的两个子数组
-
递归排序子数组:递归地对这两个子数组进行归并排序,直到每个子数组只包含一个元素或为空,这意味着它自然已经排序好
-
合并排序好的子数组:将两个排序好的子数组合并成一个排序好的数组。这通常通过设置两个指针分别指向两个子数组的开始,比较它们指向的元素,并将较小的元素放入一个新的数组中,然后移动指针。重复此过程,直到所有元素都被合并进新数组
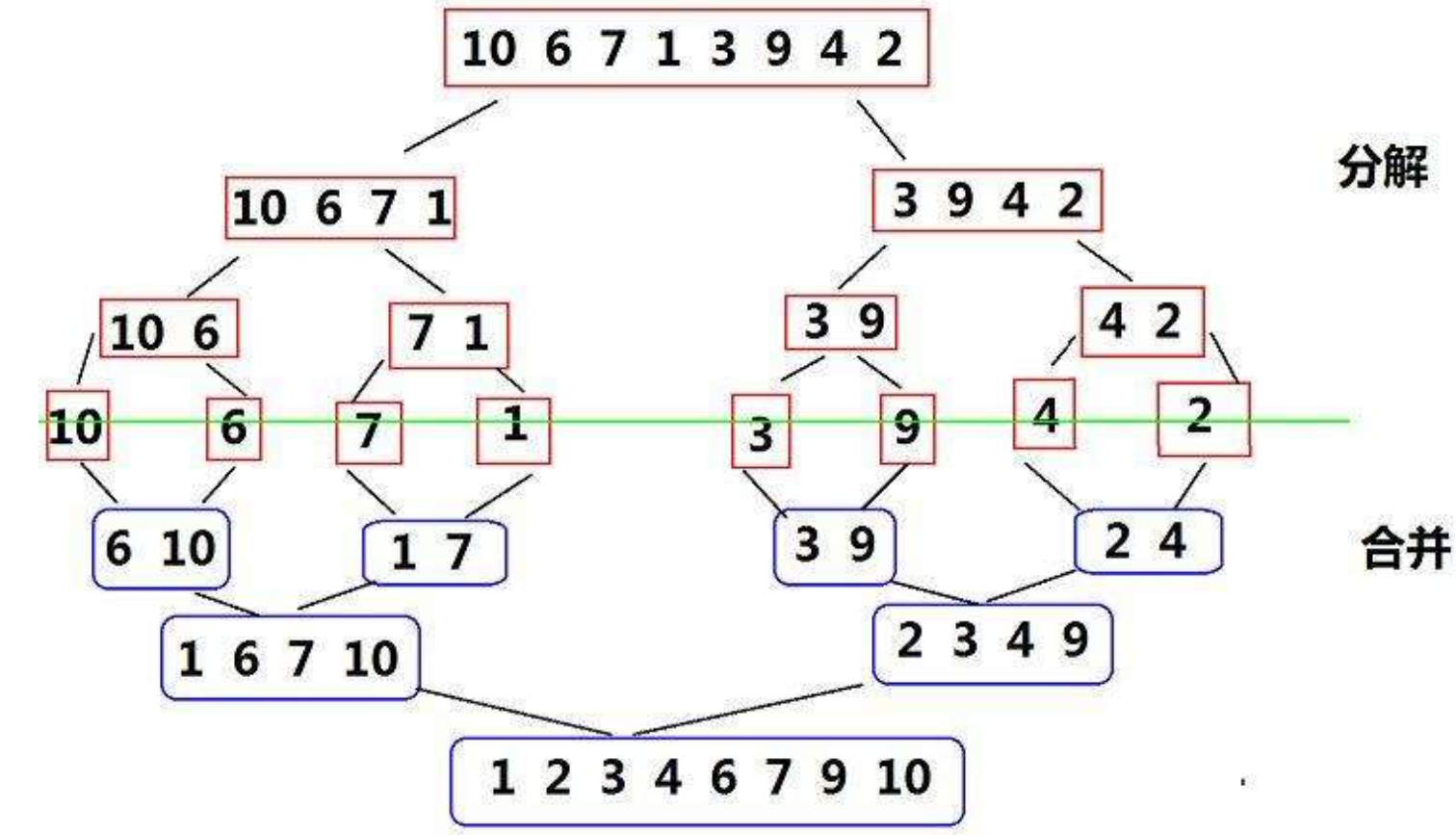
所以我们得需要递归来实现这一过程,首先声明函数并建造新的数组:
void MergeSort(int* a, int n)
{
int* tmp =(int *) malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc fail");
return;
}
free(tmp);
}
由于我们不能每次开辟一遍数组,我们这里就需要一个子函数来完成递归过程:
void _MergrSort(int* a, int begin, int end, int* tmp);
首先,不断递归将数组分解:
int mid = (begin + end) / 2;
if (begin >= end)
{
return;
}
_MergrSort(a, begin, mid, tmp);
_MergrSort(a, mid+1, end, tmp);
接着获取分解的两个数组的各自的首端到尾端的索引:
int begin1 = begin, end1 = mid;
int begin2 = mid + 1, end2 = end;
令要插入到数组tmp的起点为begin处:
int begin1 = begin, end1 = mid;
int begin2 = mid + 1, end2 = end;
int i = begin;
接下来遍历两个数组,无论谁先走完都跳出循环
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[i] = a[begin1];
i++;
begin1++;
}
else
{
tmp[i] = a[begin2];
i++;
begin2++;
}
}
这时会有一方没有遍历完,按照顺序插入到新数组中即可
while (begin1 <= end1)
{
tmp[i] = a[begin1];
begin1++;
i++;
}
while (begin2<= end2)
{
tmp[i] = a[begin2];
begin2++;
i++;
}
插入到新数组后,我们拷贝到原数组中即完成了一次排序
memcpy(a+begin,tmp+begin,sizeof(int )*(end-begin+1));
完整代码如下:
void _MergrSort(int* a, int begin, int end, int* tmp)
{
int mid = (begin + end) / 2;
if (begin >= end)
{
return;
}
_MergrSort(a, begin, mid, tmp);
_MergrSort(a, mid+1, end, tmp);
int begin1 = begin, end1 = mid;
int begin2 = mid + 1, end2 = end;
int i = begin;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[i] = a[begin1];
i++;
begin1++;
}
else
{
tmp[i] = a[begin2];
i++;
begin2++;
}
}
while (begin1 <= end1)
{
tmp[i] = a[begin1];
begin1++;
i++;
}
while (begin2<= end2)
{
tmp[i] = a[begin2];
begin2++;
i++;
}
memcpy(a+begin,tmp+begin,sizeof(int )*(end-begin+1));
}
void MergeSort(int* a, int n)
{
int* tmp =(int *) malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc fail");
return;
}
_MergrSort(a, 0, n - 1, tmp);
free(tmp);
}
- 排序好的左半部分和右半部分接着被合并。为此,使用了两个游标
begin1和begin2,它们分别指向两个子数组的起始位置,然后比较两个子数组当前元素,将较小的元素拷贝到tmp数组中。这个过程继续直到两个子数组都被完全合并 - 在所有元素都被合并到tmp数组之后,使用memcpy将排序好的部分拷贝回原数组a。这个地方注意memcpy的第三个参数,它是
sizeof(int)*(end - begin + 1),表示拷贝的总大小,单位是字节 - begin和end变量在这里表示待排序和合并的数组部分的起止索引
本节内容到此结束!感谢大家阅读!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.kler.cn/a/273127.html 如若内容造成侵权/违法违规/事实不符,请联系邮箱:809451989@qq.com进行投诉反馈,一经查实,立即删除!