VPTTA:为每张医疗图像生成特定的“提示”,解决跨不同设备和条件的医疗图像分割的准确性和适应性
VPTTA:为每张医疗图像生成特定的“提示”,解决跨不同设备和条件的医疗图像分割的准确性和适应性
- 提出背景
- VPTTA 方法
- VPTTA 步骤
提出背景
论文:https://arxiv.org/pdf/2311.18363.pdf
代码:https://github.com/Chen-Ziyang/VPTTA
这篇论文主要是为了解决在不同医疗中心采集的医疗图像在分布上的差异对语义分割模型部署的影响。
分布偏移(即不同数据集之间的统计特性差异)是一个常见问题,特别是在医疗图像处理领域,不同的设备或采集条件往往导致算法性能下降。
为了克服这一挑战,作者提出了一种称为视觉提示测试时适应(VPTTA)的新方法。
举个例子,假设我们有一个在数据集A上训练好的医疗图像分割模型,这个模型能够很好地区分不同的组织类型,比如肿瘤和正常组织。
但当我们尝试将这个模型应用到从另一个医疗中心采集的数据集B时,可能会发现模型的性能大大下降。
这是因为数据集A和B在图像的质量、对比度、亮度等方面存在差异,即存在分布偏移。
传统的解决方法可能是更新或调整模型,让它更好地适应新的数据集B。
然而,这种方法有几个缺点,比如可能导致模型忘记原来在数据集A上的知识(灾难性遗忘),或者需要大量的标注数据集B的图像进行重新训练。
相比之下,VPTTA方法提出不直接修改原始模型,而是为每个测试图像生成一个“视觉提示”,通过这个提示来调整模型对新数据集的适应性。
具体来说,这个方法通过训练少量的参数(即视觉提示),在不改变原始模型权重的情况下,使模型能够更好地处理来自不同分布的图像。
这种方法的优点是可以避免灾难性遗忘,并且因为视觉提示参数很少,所以训练过程迅速且高效。此外,作者还引入了一个记忆库机制和预热机制来进一步提高模型的适应能力。
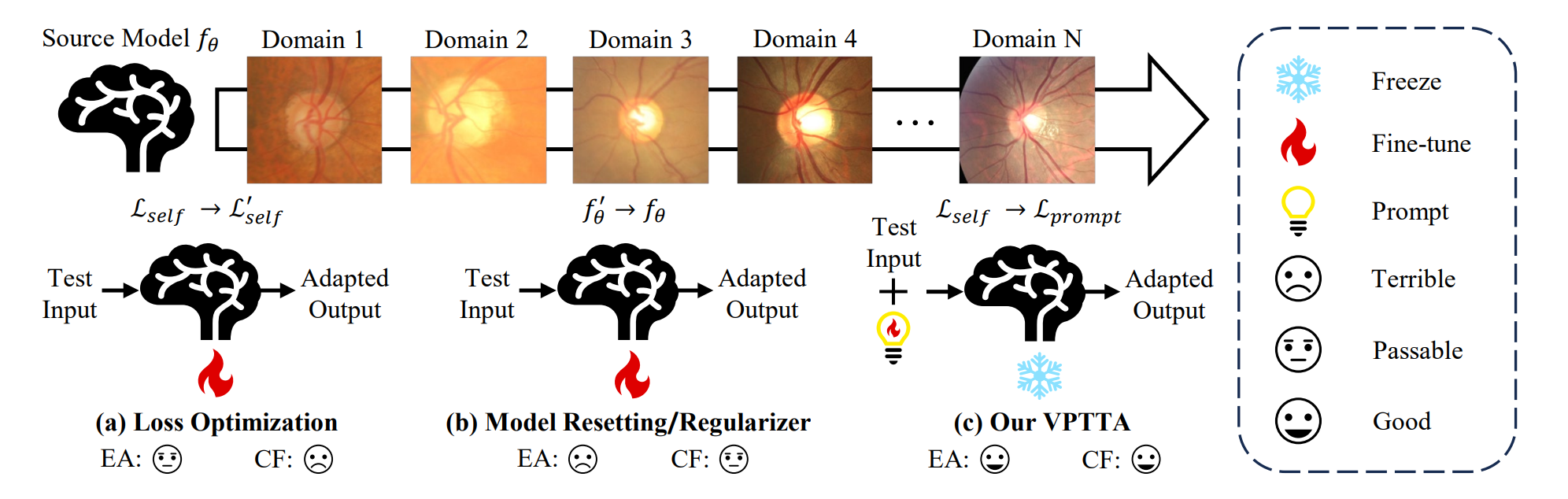
这张图比较了三种不同的方法,它们都试图解决如何让一个用于分析医疗图像的电脑程序(比如分割脑部扫描图)适应不同医院或设备拍摄的图像,即便这些图像在外观上因为设备或拍摄方式不同而有所变化。
-
第一个小图(a)是“损失优化”。
这是一个基础方法,就像每次有新的图像类型时,你就尝试调整电脑程序的一些设置来适应这些新图像。
但是这种方法有个问题,就好比你不断地改变一个食谱来适应每一位顾客的口味,最后可能连最初的食谱是什么都忘了。
-
第二个小图(b)是“模型重置/正则化”。
这是一种改进方法,它尝试通过“重置”电脑程序的某些部分或者通过特殊规则来防止它忘记原来的能力。
这就像在调整食谱的同时,确保一些基本的味道不会改变。
-
第三个小图(c)是这篇文章提出的方法,叫“VPTTA”。
这种方法不去改变原来的程序,而是给它一些提示,帮助它理解新的图像。
这有点像给食谱添加注释,而不是改变食谱本身。
图下方的表情代表了每种方法处理新类型图像时的表现:
- 悲伤的脸表示效果很糟糕,程序没能很好地适应新图像。
- 平静的脸表示效果一般,程序勉强能应对新图像。
- 微笑的脸表示效果很好,程序成功适应了新图像。
最后,这张图说明通过提供提示(VPTTA方法),电脑程序能更好地适应新的医疗图像,而不会忘记它原来的技能。
这种方法是帮助程序处理不同来源的图像更有效的方法。
VPTTA 方法
问题: 在现实世界中部署医疗图像处理的语义分割模型时,不同医疗中心拍摄的图像在外观上会有所不同(这称为分布偏移),这使得原本在一组数据上训练好的模型在新数据上的性能下降。
解法: 作者提出了一种叫做视觉提示测试时适应(VPTTA)的方法,旨在避免更新模型时产生的错误累积和灾难性遗忘。
VPTTA方法包含了三个关键步骤:提示设计、提示初始化、和提示训练。
子解法和对应特征:
-
提示设计:低频提示(子解法1)
- 利用傅立叶变换,将测试图像的低频成分与提示进行结合,形成适应后的图像。
- 之所以使用低频提示,是因为低频成分与图像的风格和纹理紧密相关,更改这些成分可以有效地解决分布偏移问题。
-
提示初始化:记忆库(子解法2)
- 使用一个记忆库,它存储了之前测试图像的低频成分和相应的提示,用于初始化新的提示。
- 之所以采用记忆库初始化,是因为适当的初始值可以显著提升训练的效率和效果。
-
提示训练:统计对齐(子解法3)
- 通过最小化源模型和测试数据特征的批归一化统计数据之间的差异来训练提示。
- 之所以对统计数据进行对齐,是因为统计数据的不匹配是导致分布偏移的主要原因。
-
预热机制(子解法4)
- 在推理阶段开始时,通过模拟源统计数据和目标统计数据之间的中间状态来减轻训练困难。
- 引入预热机制的原因是,它可以帮助模型在有限的迭代次数内更平滑地过渡到适应目标数据集的状态。
VPTTA方法通过三个子解法来实现目标数据集的适应:
- 设计低频提示以调整图像风格
- 使用记忆库来高效初始化提示
- 通过统计对齐来训练提示
- 以及利用预热机制来优化模型在推理阶段初期的适应过程
VPTTA 步骤
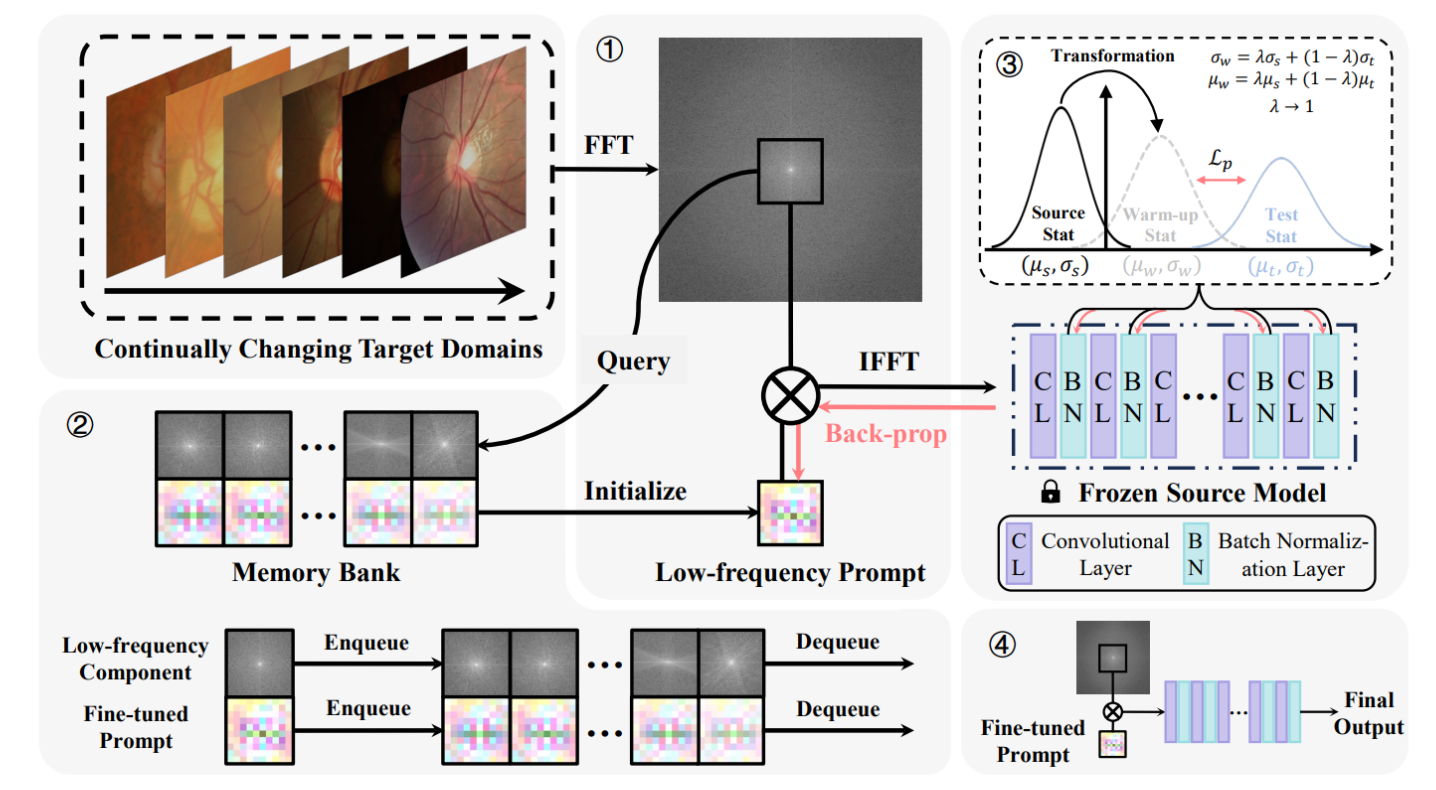
图中的流程描述了如何处理和适应连续变化的目标域的医疗图像。
整个过程分为四个主要步骤:
-
傅里叶变换(FFT)和逆变换(IFFT):
- 对每个测试图像首先应用快速傅里叶变换(FFT)将其转换到频率域。
- 在频率域中,使用图像的低频部分与记忆库中存储的提示进行查询和初始化。
- 然后通过与低频提示相乘,再应用逆傅里叶变换(IFFT),将其转换回空间域以形成调整过的图像。
-
记忆库:
- 记忆库储存了先前图像的低频成分和相应的调整过的提示。
- 当新的图像通过FFT进行查询时,记忆库用来初始化当前图像的提示,使用先进先出(FIFO)的方式进行更新。
-
统计转换和损失计算:
- 对于预训练模型中的每个批次归一化(BN)层,将源统计数据(源域的均值和标准差)转换成温和的启动统计数据。
- 使用绝对距离损失函数 ( L_p ),根据启动统计数据和目标统计数据之间的差异来微调提示。
-
最终输出和反向传播:
- 微调后的提示被用来更新图像,并将结果输入到冻结的源模型中以产生最终的输出。
- 根据损失函数通过反向传播来更新提示。
图中还包括了符号和缩略语的解释,如“Stat”表示统计数据。“C”表示卷积层,“B”表示批次归一化层,“L”表示层,这些是构成预训练模型的不同类型的层。
这张图解释了作者提出的系统是如何在不改变预训练模型参数的情况下,通过为每个测试图像创建和优化一个特定的提示,来适应新的目标域数据。
这个方法有助于减少模型适应新数据时出现的错误累积和灾难性遗忘。

当医疗图像来自不同的医疗中心时,图像的外观可能会有所不同,这使得自动识别系统难以准确地识别图像中的特定部分(比如眼底图像中的视盘和视杯)。
这张图展示了一个方法,该方法通过给每张图像添加一个"提示",帮助自动识别系统更好地理解和处理这些图像,使其能够在新的图像上取得更好的识别效果。
在图中,每一行显示了来自一个特定医疗中心的图像。
"原始图像"是没有修改的图像,而"适应图像"是通过这个新方法处理过的图像。
"提示"是这个方法生成的,用于帮助调整图像以改善识别结果。
为了说明这种方法的效果,图中用Dice分数系数(DSC)来衡量识别的准确性。
DSC值越高,表示识别的准确性越好。图表显示,在应用了提示之后,许多图像的DSC值都有所提高,这意味着识别的准确性得到了改善。
简而言之,这张图展示了一种技术如何帮助医疗图像识别系统更准确地工作,尤其是当它们处理来自不同来源的图像时。