【Paper Reading】6.RLHF-V 提出用RLHF的1.4k的数据微调显著降低MLLM的虚幻问题
| 分类 | 内容 |
|---|---|
| 论文题目 | RLHF-V: Towards Trustworthy MLLMs via Behavior Alignment from Fine-grained Correctional Human Feedback |
| 作者 | 作者团队:由来自清华大学和新加坡国立大学的研究者组成,包括Tianyu Yu, Yuan Yao, Haoye Zhang, Taiwen He, Yifeng Han, Ganqu Cui, Jinyi Hu, Zhiyuan Liu, Hai-Tao Zheng, Maosong Sun, Tat-Seng Chua。 |
| 发表年份 | CVPR 2024 |
| 摘要 | 文章针对多模态大型语言模型(MLLMs)在生成与图片不符的文本(即幻觉问题)提出了RLHF-V框架。通过从细粒度的人类反馈中学习,显著减少基础MLLM的幻觉率,提高了模型的可信度和实用性。 |
| 引言 | 强调了MLLMs在多模态理解、推理和交互方面的能力,同时指出其存在的幻觉问题,即生成与关联图片不符的文本,这一问题限制了MLLMs在实际应用中的可信度。 |
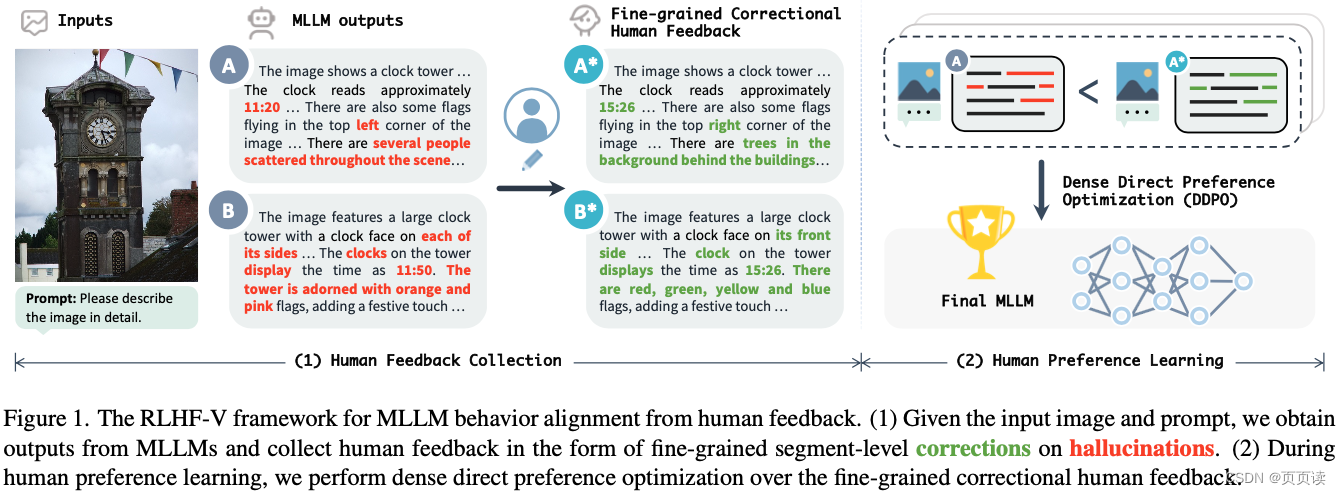
| 主要内容 | RLHF-V框架:论文提出了RLHF-V,一种旨在通过细粒度人类反馈对多模态大型语言模型(MLLMs)行为进行校准的框架,以解决模型产生的幻觉问题,即生成的文本与关联图片不符。这种框架的关键思想是通过人类偏好的形式收集细粒度的反馈,并利用这些反馈来优化模型,从而提高其在处理多模态输入时的可靠性和准确性。 细粒度的人类反馈收集:RLHF-V的一个创新之处在于其收集人类反馈的方式。不同于以往依赖粗粒度或整体排名的反馈,RLHF-V要求人类注释者对模型输出中的具体错误或幻觉部分进行细节级的校正。这种细粒度的反馈不仅提供了更明确的学习信号,而且还避免了因语言多样性或偏见而引起的误导。 密集直接偏好优化(DDPO):为了有效利用收集到的细粒度人类反馈,RLHF-V采用了一种名为密集直接偏好优化(DDPO)的技术。DDPO是一种新的优化策略,专门设计用来处理细粒度的反馈,并能够直接在偏好数据上进行模型训练。通过强化学习方法,DDPO能够精确地调整模型的行为,以减少幻觉产生,增强模型输出的事实依据。 |
| 实验 | 实验设计:为了验证RLHF-V的有效性,作者在五个基准数据集上进行了广泛的实验。这些实验旨在评估RLHF-V在减少幻觉、提高模型可靠性方面的性能。实验包括自动评估和人类评估两部分,分别从模型的准确性、可信度以及与人类偏好的一致性进行评价。 基准数据集:实验涉及的基准数据集包括图像描述、视觉问答和多模态对话等任务,旨在全面评估RLHF-V在多种多模态交互场景下的表现。通过与当前最先进的MLLMs(包括未使用RLHF-V优化的基线模型)进行对比,实验结果展示了RLHF-V在这些任务上的显著改进。 主要结果:实验结果表明,使用RLHF-V框架进行优化的MLLMs在减少幻觉、提高文本与图片一致性方面表现出色。具体而言,与基线模型相比,RLHF-V能够显著降低幻觉率,改善模型输出的可信度和准确性。在人类评估方面,RLHF-V优化后的模型产生的输出更加符合人类的偏好和期望,显示出对复杂多模态输入的更好理解。 效率与性能:除了提升模型性能,RLHF-V还显示出良好的数据和计算效率。即使在有限的标注数据下,RLHF-V也能通过其细粒度的反馈学习机制有效地改进模型行为,证明了其在实际应用中的可行性和效率。 |
| 结论 | RLHF-V通过细粒度的人类反馈校准MLLMs的行为,显著提高了模型的可信度,并在开源MLLMs中取得了最先进的性能。 |
| 阅读心得 | 亮点:
|