Nadaraya-Watson核回归
目录
基本原理
编辑
核函数的选择
带宽的选择
特点
应用
与注意力机制的关系
参考内容

在统计学中,核回归是一种估计随机变量的条件期望的非参数技术。目标是找到一对随机变量 X 和 Y 之间的非线性关系。
在任何非参数回归中,变量 Y 相对于变量 X 的条件期望可以写为:

其中,m是未知函数。
Nadaraya-Watson 核回归是一种非参数回归方法,由Nadaraya和Watson于1964年独立提出。它通过加权平均的方式来估计条件期望,适用于估计变量之间的依赖关系。这种方法特别适合处理数据点稀疏或模型形式未知的情况,能够灵活适应数据的局部特性。Nadaraya-Watson 核回归的核心在于利用核函数来平滑样本点周围的数据,从而对给定点的响应变量的条件期望进行估计(利用核函数来衡量数据点之间的相似度,并根据这种相似度来计算目标点的预测值)。
基本原理
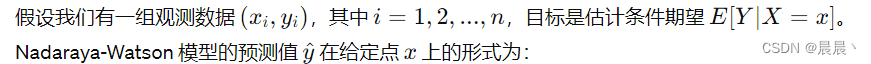
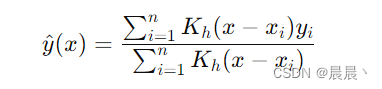

核函数的选择
常见的核函数包括高斯核、Epanechnikov核等。核函数的选择和带宽参数的设定对估计器的性能有重要影响。选择合适的核函数和带宽是核回归中的一个关键问题。
核函数 K(⋅) 是一个非负函数,确保数据点之间的权重是正的。常用的核函数包括高斯核、Epanechnikov核等。选择不同的核函数和带宽 ℎ 可以影响模型的平滑程度和拟合效果。
带宽的选择
带宽 ℎ 的选择对Nadaraya-Watson 核回归的效果有重要影响。带宽过小会导致过拟合,模型对数据的噪声过于敏感;带宽过大则会导致欠拟合,模型不能捕捉到数据的局部特征。因此,选择合适的带宽是这种核回归方法中的关键步骤。常用的带宽选择方法包括交叉验证等。
特点
- 灵活性:Nadaraya-Watson 核回归不需要事先假定数据之间的关系形式,能够适应数据的局部特征。
- 非参数方法:作为一种非参数方法,它不依赖于参数化的模型,适合处理复杂的数据关系。
- 局部加权:通过局部加权平均,它能够在数据密集的区域给予更多的关注,从而更好地捕捉变量之间的依赖关系。
应用
Nadaraya-Watson 核回归在多个领域都有应用,特别是在经济学、生物统计学、机器学习等领域。它适用于探索性数据分析、趋势估计、信号处理等多种情况,特别是在模型形式未知或数据关系复杂时,可以提供一种灵活的估计方法。然而,选择合适的核函数和带宽参数需要根据具体问题和数据集的特点来确定,这对于获取好的回归结果至关重要。
与注意力机制的关系
Nadaraya-Watson核回归与注意力机制之间有着密切的联系。在注意力机制中,模型学习到的权重可以被视为是在给定上下文(如序列中的位置或时间点)对于不同输入的“关注度”。类似地,在Nadaraya-Watson核回归中,核函数确定的权重反映了在估计给定点的条件期望时,周围点的重要性。
这种权重机制的思想在两个领域都是核心的:在Nadaraya-Watson模型中,通过距离来分配权重,近的点比远的点有更高的权重;在注意力机制中,权重通常是通过学习得到的,能够指示模型在处理输入数据时应该“注意”数据的哪些部分。
因此,我们可以把注意力机制视为Nadaraya-Watson核回归在深度学习中的一种推广或变体,其中注意力的权重是通过模型学习得到的,而不是通过传统的核函数预定义的。这种学习到的注意力权重使得模型能够更灵活地适应数据的特点,从而在复杂的任务中取得更好的性能。
参考内容
https://en.wikipedia.org/wiki/Kernel_regression