GPT-SoVITS语音合成服务器部署,可远程访问(全部代码和详细部署步骤)
GPT-SoVITS 是一个开源项目,它使用大约一分钟的语音数据便可以训练出一个优秀的TTS模型。
项目的核心技术是 Zero-shot TTS 和 Few-shot TTS。
Zero-shot TTS 可以让用户输入5秒钟的语音样本并立即体验转换后的语音,而 Few-shot TTS 则可以通过使用仅一分钟的训练数据进行模型微调,从而提高语音相似度和真实性。
该项目支持多语言推理,包括但不限于英语,日语和中文。此外,项目还提供了一些集成工具,包括声音伴奏分离,自动训练集分割,中文ASR和文本标签,帮助初学者创建训练数据集和 GPT/SoVITS 模型。
具体功能
Zero-shot TTS:用户只需输入5秒钟的语音样本,就可以立即体验文本到语音的转换。
Few-shot TTS:使用只有一分钟的训练数据微调模型,以提高语音的相似度和真实感。
跨语言支持:可以在与训练数据集不同的语言中进行推理,目前支持英语,日语和中文。
WebUI 工具:集成工具包括声音伴奏分离,自动训练集分割,中文ASR和文本标签,帮助初学者创建训练数据集和GPT/SoVITS模型。
conda create -n GPTSoVits python=3.9
conda activate GPTSoVits
bash install.sh
pip install -r requirements.txt
conda install ffmpegLanguage dictionary:
- 'zh': Chinese
- 'ja': Japanese
- 'en': English
模型下载:
1.GPT-SoVITS Models 下载后放入:GPT_SoVITS/pretrained_models
iCloud Drive - Apple iCloud
2.UVR5 Weights 下载后放入:tools/uvr5/uvr5_weights
iCloud Drive - Apple iCloud
服务器部署:
import os, re, logging,argparse,torch,sys
if torch.cuda.is_available():
device = "cuda"
elif torch.backends.mps.is_available():
device = "mps"
else:
device = "cpu"
# 处理参数
parser = argparse.ArgumentParser(description="GPT-SoVITS api")
parser.add_argument("-s", "--sovits_path", type=str, default="GPT_SoVITS/pretrained_models/s2G488k.pth", help="SoVITS模型路径")
parser.add_argument("-g", "--gpt_path", type=str, default="GPT_SoVITS/pretrained_models/s1bert25hz-2kh-longer-epoch=68e-step=50232.ckpt", help="GPT模型路径")
parser.add_argument("-dr", "--default_refer_path", type=str, default="5.wav", help="默认参考音频路径")
parser.add_argument("-dt", "--default_refer_text", type=str, default="为什么御弟哥哥,甘愿守孤灯", help="默认参考音频文本")
parser.add_argument("-dl", "--default_refer_language", type=str, default="zh", help="默认参考音频语种")
parser.add_argument("-d", "--device",type=str, default="cuda", help="cuda / cpu / mps")
parser.add_argument("-a", "--bind_addr", type=str, default='0.0.0.0', help="default: 0.0.0.0")
parser.add_argument("-p", "--port", type=int, default='9880', help="default: 9880")
parser.add_argument("-c", "--cut", type=int, default=5, help="default: 5 按标点符号切分")
parser.add_argument("-fp", "--full_precision", action="store_true", default=False, help="覆盖config.is_half为False, 使用全精度")
parser.add_argument("-hp", "--half_precision", action="store_true", default=False, help="覆盖config.is_half为True, 使用半精度")
parser.add_argument("-hb", "--hubert_path", type=str, default='GPT_SoVITS/pretrained_models/chinese-hubert-base', help="覆盖config.cnhubert_path")
parser.add_argument("-b", "--bert_path", type=str, default='GPT_SoVITS/pretrained_models/chinese-roberta-wwm-ext-large', help="覆盖config.bert_path")
args = parser.parse_args()
default_wav=args.default_refer_path
default_text=args.default_refer_text
default_language=args.default_refer_language
splits = {",", "。", "?", "!", ",", ".", "?", "!", "~", ":", ":", "—", "…", }
root_dir=os.getcwd()
SoVITS_weight_root = "SoVITS_weights"
GPT_weight_root = "GPT_weights"
os.makedirs(SoVITS_weight_root, exist_ok=True)
os.makedirs(GPT_weight_root, exist_ok=True)
host=args.bind_addr
port = args.port
is_half=bool(args.half_precision)
sys.path.append(root_dir)
sys.path.append(os.path.join(root_dir,"GPT_SoVITS"))
gpt_path = args.gpt_path
sovits_path = args.sovits_path
bert_path = args.bert_path
os.environ['PYTORCH_ENABLE_MPS_FALLBACK'] = '1' # 确保直接启动推理UI时也能够设置。
if "_CUDA_VISIBLE_DEVICES" in os.environ:
os.environ["CUDA_VISIBLE_DEVICES"] = os.environ["_CUDA_VISIBLE_DEVICES"]
import LangSegment
import pdb
from fastapi.responses import StreamingResponse, JSONResponse
from fastapi import FastAPI, Request, HTTPException
import signal
from io import BytesIO
import uvicorn
import soundfile as sf
import gradio as gr
from transformers import AutoModelForMaskedLM, AutoTokenizer
import numpy as np
import librosa, torch
from GPT_SoVITS.feature_extractor import cnhubert
from GPT_SoVITS.module.models import SynthesizerTrn
from GPT_SoVITS.AR.models.t2s_lightning_module import Text2SemanticLightningModule
from GPT_SoVITS.text import cleaned_text_to_sequence
from GPT_SoVITS.text.cleaner import clean_text
from time import time as ttime
from GPT_SoVITS.module.mel_processing import spectrogram_torch
from GPT_SoVITS.my_utils import load_audio
cnhubert.cnhubert_base_path = args.hubert_path
logging.getLogger("markdown_it").setLevel(logging.ERROR)
logging.getLogger("urllib3").setLevel(logging.ERROR)
logging.getLogger("httpcore").setLevel(logging.ERROR)
logging.getLogger("httpx").setLevel(logging.ERROR)
logging.getLogger("asyncio").setLevel(logging.ERROR)
logging.getLogger("charset_normalizer").setLevel(logging.ERROR)
logging.getLogger("torchaudio._extension").setLevel(logging.ERROR)
tokenizer = AutoTokenizer.from_pretrained(bert_path)
bert_model = AutoModelForMaskedLM.from_pretrained(bert_path)
if is_half == True:
bert_model = bert_model.half().to(device)
else:
bert_model = bert_model.to(device)
def get_bert_feature(text, word2ph):
with torch.no_grad():
inputs = tokenizer(text, return_tensors="pt")
for i in inputs:
inputs[i] = inputs[i].to(device)
res = bert_model(**inputs, output_hidden_states=True)
res = torch.cat(res["hidden_states"][-3:-2], -1)[0].cpu()[1:-1]
assert len(word2ph) == len(text)
phone_level_feature = []
for i in range(len(word2ph)):
repeat_feature = res[i].repeat(word2ph[i], 1)
phone_level_feature.append(repeat_feature)
phone_level_feature = torch.cat(phone_level_feature, dim=0)
return phone_level_feature.T
class DictToAttrRecursive(dict):
def __init__(self, input_dict):
super().__init__(input_dict)
for key, value in input_dict.items():
if isinstance(value, dict):
value = DictToAttrRecursive(value)
self[key] = value
setattr(self, key, value)
def __getattr__(self, item):
try:
return self[item]
except KeyError:
raise AttributeError(f"Attribute {item} not found")
def __setattr__(self, key, value):
if isinstance(value, dict):
value = DictToAttrRecursive(value)
super(DictToAttrRecursive, self).__setitem__(key, value)
super().__setattr__(key, value)
def __delattr__(self, item):
try:
del self[item]
except KeyError:
raise AttributeError(f"Attribute {item} not found")
ssl_model = cnhubert.get_model()
if is_half == True:
ssl_model = ssl_model.half().to(device)
else:
ssl_model = ssl_model.to(device)
def change_sovits_weights(sovits_path):
global vq_model, hps
dict_s2 = torch.load(sovits_path, map_location="cpu")
hps = dict_s2["config"]
hps = DictToAttrRecursive(hps)
hps.model.semantic_frame_rate = "25hz"
vq_model = SynthesizerTrn(
hps.data.filter_length // 2 + 1,
hps.train.segment_size // hps.data.hop_length,
n_speakers=hps.data.n_speakers,
**hps.model
)
if ("pretrained" not in sovits_path):
del vq_model.enc_q
if is_half == True:
vq_model = vq_model.half().to(device)
else:
vq_model = vq_model.to(device)
vq_model.eval()
print(vq_model.load_state_dict(dict_s2["weight"], strict=False))
with open("./sweight.txt", "w", encoding="utf-8") as f:
f.write(sovits_path)
change_sovits_weights(sovits_path)
def change_gpt_weights(gpt_path):
global hz, max_sec, t2s_model, config
hz = 50
dict_s1 = torch.load(gpt_path, map_location="cpu")
config = dict_s1["config"]
max_sec = config["data"]["max_sec"]
t2s_model = Text2SemanticLightningModule(config, "****", is_train=False)
t2s_model.load_state_dict(dict_s1["weight"])
if is_half == True:
t2s_model = t2s_model.half()
t2s_model = t2s_model.to(device)
t2s_model.eval()
total = sum([param.nelement() for param in t2s_model.parameters()])
print("Number of parameter: %.2fM" % (total / 1e6))
with open("./gweight.txt", "w", encoding="utf-8") as f: f.write(gpt_path)
change_gpt_weights(gpt_path)
def get_spepc(hps, filename):
audio = load_audio(filename, int(hps.data.sampling_rate))
audio = torch.FloatTensor(audio)
audio_norm = audio
audio_norm = audio_norm.unsqueeze(0)
spec = spectrogram_torch(
audio_norm,
hps.data.filter_length,
hps.data.sampling_rate,
hps.data.hop_length,
hps.data.win_length,
center=False,
)
return spec
def splite_en_inf(sentence, language):
pattern = re.compile(r'[a-zA-Z ]+')
textlist = []
langlist = []
pos = 0
for match in pattern.finditer(sentence):
start, end = match.span()
if start > pos:
textlist.append(sentence[pos:start])
langlist.append(language)
textlist.append(sentence[start:end])
langlist.append("en")
pos = end
if pos < len(sentence):
textlist.append(sentence[pos:])
langlist.append(language)
# Merge punctuation into previous word
for i in range(len(textlist)-1, 0, -1):
if re.match(r'^[\W_]+$', textlist[i]):
textlist[i-1] += textlist[i]
del textlist[i]
del langlist[i]
# Merge consecutive words with the same language tag
i = 0
while i < len(langlist) - 1:
if langlist[i] == langlist[i+1]:
textlist[i] += textlist[i+1]
del textlist[i+1]
del langlist[i+1]
else:
i += 1
return textlist, langlist
def clean_text_inf(text, language):
formattext = ""
language = language.replace("all_","")
for tmp in LangSegment.getTexts(text):
if language == "ja":
if tmp["lang"] == language or tmp["lang"] == "zh":
formattext += tmp["text"] + " "
continue
if tmp["lang"] == language:
formattext += tmp["text"] + " "
while " " in formattext:
formattext = formattext.replace(" ", " ")
phones, word2ph, norm_text = clean_text(formattext, language)
phones = cleaned_text_to_sequence(phones)
return phones, word2ph, norm_text
dtype=torch.float16 if is_half == True else torch.float32
def get_bert_inf(phones, word2ph, norm_text, language):
language=language.replace("all_","")
if language == "zh":
bert = get_bert_feature(norm_text, word2ph).to(device)#.to(dtype)
else:
bert = torch.zeros(
(1024, len(phones)),
dtype=torch.float16 if is_half == True else torch.float32,
).to(device)
return bert
def nonen_clean_text_inf(text, language):
if(language!="auto"):
textlist, langlist = splite_en_inf(text, language)
else:
textlist=[]
langlist=[]
for tmp in LangSegment.getTexts(text):
langlist.append(tmp["lang"])
textlist.append(tmp["text"])
phones_list = []
word2ph_list = []
norm_text_list = []
for i in range(len(textlist)):
lang = langlist[i]
phones, word2ph, norm_text = clean_text_inf(textlist[i], lang)
phones_list.append(phones)
if lang == "zh":
word2ph_list.append(word2ph)
norm_text_list.append(norm_text)
print(word2ph_list)
phones = sum(phones_list, [])
word2ph = sum(word2ph_list, [])
norm_text = ' '.join(norm_text_list)
return phones, word2ph, norm_text
def nonen_get_bert_inf(text, language):
if(language!="auto"):
textlist, langlist = splite_en_inf(text, language)
else:
textlist=[]
langlist=[]
for tmp in LangSegment.getTexts(text):
langlist.append(tmp["lang"])
textlist.append(tmp["text"])
print(textlist)
print(langlist)
bert_list = []
for i in range(len(textlist)):
lang = langlist[i]
phones, word2ph, norm_text = clean_text_inf(textlist[i], lang)
bert = get_bert_inf(phones, word2ph, norm_text, lang)
bert_list.append(bert)
bert = torch.cat(bert_list, dim=1)
return bert
def get_first(text):
pattern = "[" + "".join(re.escape(sep) for sep in splits) + "]"
text = re.split(pattern, text)[0].strip()
return text
def get_cleaned_text_final(text,language):
if language in {"en","all_zh","all_ja"}:
phones, word2ph, norm_text = clean_text_inf(text, language)
elif language in {"zh", "ja","auto"}:
phones, word2ph, norm_text = nonen_clean_text_inf(text, language)
return phones, word2ph, norm_text
def get_bert_final(phones, word2ph, text,language,device):
if language == "en":
bert = get_bert_inf(phones, word2ph, text, language)
elif language in {"zh", "ja","auto"}:
bert = nonen_get_bert_inf(text, language)
elif language == "all_zh":
bert = get_bert_feature(text, word2ph).to(device)
else:
bert = torch.zeros((1024, len(phones))).to(device)
return bert
def merge_short_text_in_array(texts, threshold):
if (len(texts)) < 2:
return texts
result = []
text = ""
for ele in texts:
text += ele
if len(text) >= threshold:
result.append(text)
text = ""
if (len(text) > 0):
if len(result) == 0:
result.append(text)
else:
result[len(result) - 1] += text
return result
def get_tts_wav(*,refer_wav_path, prompt_text, prompt_language="zh", text="", text_language="zh", top_k=5, top_p=1, temperature=1, ref_free = False):
text+='.'
print(f'{refer_wav_path=},{prompt_text=},{prompt_language=},{text=},{text_language=}')
if prompt_text is None or len(prompt_text) == 0:
ref_free = True
t0 = ttime()
#prompt_language = dict_language[prompt_language]
#text_language = dict_language[text_language]
if not ref_free:
prompt_text = prompt_text.strip("\n")
if (prompt_text[-1] not in splits): prompt_text += "。" if prompt_language != "en" else "."
print(("实际输入的参考文本:"), prompt_text)
text = text.strip("\n")
for t in splits:
text= text if not re.search(fr'\{t}',text) else re.sub(fr'\{t}+',t,text)
if (text[0] not in splits and len(get_first(text)) < 4): text = "。" + text if text_language != "en" else "." + text
if len(text)<4:
raise Exception('有效文字数太少,至少输入4个字符')
print(("实际输入的目标文本:"), text)
zero_wav = np.zeros(
int(hps.data.sampling_rate * 0.3),
dtype=np.float16 if is_half == True else np.float32,
)
with torch.no_grad():
wav16k, sr = librosa.load(refer_wav_path, sr=16000)
if (wav16k.shape[0] > 160000 or wav16k.shape[0] < 48000):
raise OSError(("参考音频在3~10秒范围外,请更换!"))
wav16k = torch.from_numpy(wav16k)
zero_wav_torch = torch.from_numpy(zero_wav)
if is_half == True:
wav16k = wav16k.half().to(device)
zero_wav_torch = zero_wav_torch.half().to(device)
else:
wav16k = wav16k.to(device)
zero_wav_torch = zero_wav_torch.to(device)
wav16k = torch.cat([wav16k, zero_wav_torch])
ssl_content = ssl_model.model(wav16k.unsqueeze(0))[
"last_hidden_state"
].transpose(
1, 2
) # .float()
codes = vq_model.extract_latent(ssl_content)
prompt_semantic = codes[0, 0]
t1 = ttime()
print(f'{args.cut=}')
if (args.cut == 1):
text = cut1(text)
elif (args.cut == 2):
text = cut2(text)
elif (args.cut == 3):
text = cut3(text)
elif (args.cut == 4):
text = cut4(text)
elif (args.cut == 5):
text = cut5(text)
while "\n\n" in text:
text = text.replace("\n\n", "\n")
print(("实际输入的目标文本(切句后):"), text)
texts = text.split("\n")
texts = merge_short_text_in_array(texts, 5)
audio_opt = []
if not ref_free:
phones1, word2ph1, norm_text1=get_cleaned_text_final(prompt_text, prompt_language)
bert1=get_bert_final(phones1, word2ph1, norm_text1,prompt_language,device).to(dtype)
for text in texts:
# 解决输入目标文本的空行导致报错的问题
if (len(text.strip()) == 0):
continue
if (text[-1] not in splits): text += "。" if text_language != "en" else "."
print(("实际输入的目标文本(每句):"), text)
phones2, word2ph2, norm_text2 = get_cleaned_text_final(text, text_language)
bert2 = get_bert_final(phones2, word2ph2, norm_text2, text_language, device).to(dtype)
if not ref_free:
bert = torch.cat([bert1, bert2], 1)
all_phoneme_ids = torch.LongTensor(phones1+phones2).to(device).unsqueeze(0)
else:
bert = bert2
all_phoneme_ids = torch.LongTensor(phones2).to(device).unsqueeze(0)
bert = bert.to(device).unsqueeze(0)
all_phoneme_len = torch.tensor([all_phoneme_ids.shape[-1]]).to(device)
prompt = prompt_semantic.unsqueeze(0).to(device)
t2 = ttime()
with torch.no_grad():
# pred_semantic = t2s_model.model.infer(
pred_semantic, idx = t2s_model.model.infer_panel(
all_phoneme_ids,
all_phoneme_len,
None if ref_free else prompt,
bert,
# prompt_phone_len=ph_offset,
top_k=top_k,
top_p=top_p,
temperature=temperature,
early_stop_num=hz * max_sec,
)
t3 = ttime()
# print(pred_semantic.shape,idx)
pred_semantic = pred_semantic[:, -idx:].unsqueeze(
0
) # .unsqueeze(0)#mq要多unsqueeze一次
refer = get_spepc(hps, refer_wav_path) # .to(device)
if is_half == True:
refer = refer.half().to(device)
else:
refer = refer.to(device)
# audio = vq_model.decode(pred_semantic, all_phoneme_ids, refer).detach().cpu().numpy()[0, 0]
audio = (
vq_model.decode(
pred_semantic, torch.LongTensor(phones2).to(device).unsqueeze(0), refer
)
.detach()
.cpu()
.numpy()[0, 0]
) ###试试重建不带上prompt部分
max_audio=np.abs(audio).max()#简单防止16bit爆音
if max_audio>1:audio/=max_audio
audio_opt.append(audio)
audio_opt.append(zero_wav)
t4 = ttime()
print("%.3f\t%.3f\t%.3f\t%.3f" % (t1 - t0, t2 - t1, t3 - t2, t4 - t3))
yield hps.data.sampling_rate, (np.concatenate(audio_opt, 0) * 32768).astype(
np.int16
)
def split(todo_text):
todo_text = todo_text.replace("……", "。").replace("——", ",")
if todo_text[-1] not in splits:
todo_text += "。"
i_split_head = i_split_tail = 0
len_text = len(todo_text)
todo_texts = []
while 1:
if i_split_head >= len_text:
break # 结尾一定有标点,所以直接跳出即可,最后一段在上次已加入
if todo_text[i_split_head] in splits:
i_split_head += 1
todo_texts.append(todo_text[i_split_tail:i_split_head])
i_split_tail = i_split_head
else:
i_split_head += 1
return todo_texts
def cut1(inp):
inp = inp.strip("\n")
inps = split(inp)
split_idx = list(range(0, len(inps), 4))
split_idx[-1] = None
if len(split_idx) > 1:
opts = []
for idx in range(len(split_idx) - 1):
opts.append("".join(inps[split_idx[idx]: split_idx[idx + 1]]))
else:
opts = [inp]
return "\n".join(opts)
def cut2(inp):
inp = inp.strip("\n")
inps = split(inp)
if len(inps) < 2:
return inp
opts = []
summ = 0
tmp_str = ""
for i in range(len(inps)):
summ += len(inps[i])
tmp_str += inps[i]
if summ > 50:
summ = 0
opts.append(tmp_str)
tmp_str = ""
if tmp_str != "":
opts.append(tmp_str)
# print(opts)
if len(opts) > 1 and len(opts[-1]) < 50: ##如果最后一个太短了,和前一个合一起
opts[-2] = opts[-2] + opts[-1]
opts = opts[:-1]
return "\n".join(opts)
def cut3(inp):
inp = inp.strip("\n")
return "\n".join(["%s" % item for item in inp.strip("。").split("。")])
def cut4(inp):
inp = inp.strip("\n")
return "\n".join(["%s" % item for item in inp.strip(".").split(".")])
# contributed by https://github.com/AI-Hobbyist/GPT-SoVITS/blob/main/GPT_SoVITS/inference_webui.py
def cut5(inp):
# if not re.search(r'[^\w\s]', inp[-1]):
# inp += '。'
inp = inp.strip("\n")
punds = r'[,.;?!、,。?!;:]'
items = re.split(f'({punds})', inp)
items = ["".join(group) for group in zip(items[::2], items[1::2])]
opt = "\n".join(items)
return opt
def custom_sort_key(s):
# 使用正则表达式提取字符串中的数字部分和非数字部分
parts = re.split('(\d+)', s)
# 将数字部分转换为整数,非数字部分保持不变
parts = [int(part) if part.isdigit() else part for part in parts]
return parts
def change_choices():
SoVITS_names, GPT_names = get_weights_names()
return {"choices": sorted(SoVITS_names, key=custom_sort_key), "__type__": "update"}, {"choices": sorted(GPT_names, key=custom_sort_key), "__type__": "update"}
def get_weights_names():
SoVITS_names = [sovits_path]
for name in os.listdir(SoVITS_weight_root):
if name.endswith(".pth"): SoVITS_names.append("%s/%s" % (SoVITS_weight_root, name))
GPT_names = [gpt_path]
for name in os.listdir(GPT_weight_root):
if name.endswith(".ckpt"): GPT_names.append("%s/%s" % (GPT_weight_root, name))
return SoVITS_names, GPT_names
SoVITS_names, GPT_names = get_weights_names()
app = FastAPI()
def handle(refer_wav_path, prompt_text, prompt_language, text, text_language):
if (
refer_wav_path == "" or refer_wav_path is None
or prompt_text == "" or prompt_text is None
or prompt_language == "" or prompt_language is None
):
refer_wav_path,prompt_text,prompt_language=default_wav,default_text,default_language
if not refer_wav_path or not prompt_text or not prompt_language:
return JSONResponse({"code": 400, "message": "未指定参考音频且接口无预设"}, status_code=400)
with torch.no_grad():
gen = get_tts_wav(
refer_wav_path=refer_wav_path, prompt_text=prompt_text, prompt_language=prompt_language, text=text, text_language=text_language
)
sampling_rate, audio_data = next(gen)
wav = BytesIO()
sf.write(wav, audio_data, sampling_rate, format="wav")
wav.seek(0)
torch.cuda.empty_cache()
if device == "mps":
print('executed torch.mps.empty_cache()')
torch.mps.empty_cache()
return StreamingResponse(wav, media_type="audio/wav")
@app.post("/")
async def tts_endpoint(request: Request):
json_post_raw = await request.json()
return handle(
json_post_raw.get("refer_wav_path"),
json_post_raw.get("prompt_text"),
json_post_raw.get("prompt_language"),
json_post_raw.get("text"),
json_post_raw.get("text_language"),
)
@app.get("/")
async def tts_endpoint(
refer_wav_path: str = None,
prompt_text: str = None,
prompt_language: str = None,
text: str = None,
text_language: str = None,
):
return handle(refer_wav_path, prompt_text, prompt_language, text, text_language)
if __name__ == "__main__":
uvicorn.run(app, host=host, port=port, workers=1)python api2.py
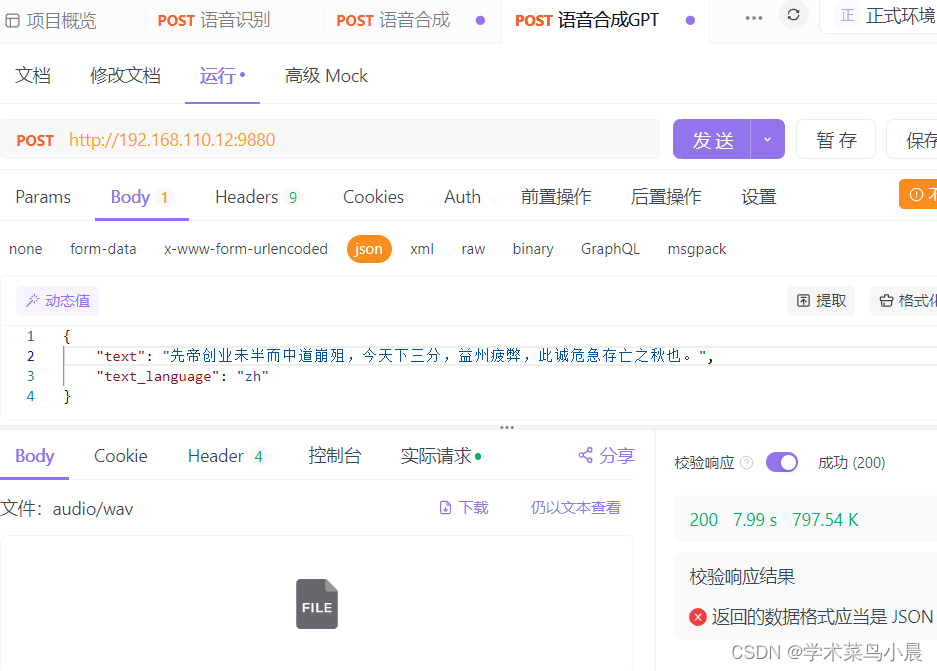
http://192.168.110.12:9880
{
"text": "先帝创业未半而中道崩殂,今天下三分,益州疲弊,此诚危急存亡之秋也。",
"text_language": "zh"
}