A Closer Look at Spatiotemporal Convolutions for Action Recognition
1、引言
论文链接:https://arxiv.org/abs/1711.11248
在这篇文章中作者更细致地研究了用于行为识别任务中的时空卷积,即在 ResNet[1] 框架下做了大量 2D CNN 到 3D CNN 的实验,证明了 3D CNN 在残差学习框架下的优势,并引入了 2 种新的时空卷积形式 MCx 和 R(2+1)D[2],其中 R(2+1)D 在 Sports-1M 上达到 SOTA,在 Kinetics, UCF101, 和 HMDB51 上接近 SOTA。
2、R3D
R3D[2] 只是把 ResNet 的所有卷积层换成了对应的 3D 卷积,自然所有的 BatchNorm2d 层要改为 BatchNorm3d,分类头前的 AdaptiveAvgPool2d 层要替换为 AdaptiveAvgPool3d。但 R3D 的第一个卷积层的卷积核尺寸为(3,7,7),stride=(1, 2, 2)。即第一个卷积层卷积核时间尺寸与空间尺寸不同,且没有时间 striding。
2、MCx
作者把 ResNet 的卷积分为 5 组,对应于 ResNet 的 5 层。x 代表 x 组及其后面的卷积都是 2D 卷积(3D 卷积核时间尺寸为 1, 且没有时间 striding),x 组前面的卷积都是 3D 卷积。其它部分均与 R3D 相同。
4、R(2+1)D
将 3D 卷积分解为连续的 2D 空间卷积(3D 卷积核时间尺寸为 1, 且没有时间 striding)和 1D 时间卷积(3D 卷积核空间尺寸为 1, 且没有空间 striding)就得到 (2+1)D 卷积,如图 1 所示。
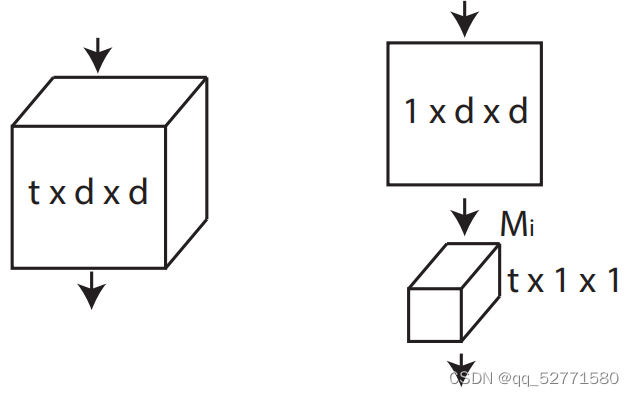
图1 (2+1)D vs 3D 卷积
设 3D 卷积的输入通道数为 in_c,输出通道数为 out_c,kernel_size=(t,d,d)。则对应的 (2+1)D 卷积中,2D 卷积的输入通道数为 in_c,输出通道数为 Mi,kernel_size=(1,d,d);1D 卷积的输入通道数为 Mi,输出通道数为 out_c ,kernel_size=(t,1,1);为了使 (2+1)D 卷积与对应的 3D 卷积参数量相当,应满足
. (1)
(2+1)D 在 2D 卷积核 1D 卷积间依次添加了 BatchNorm3d 和 ReLU,使 (2+1)D 卷积的非线性量是 3D 卷积的两倍,使 (2+1)D 卷积可以拟合更复杂的函数。R3D 和 R(2+1)D 的第一组卷积的 torch 源码如图 2 所示。
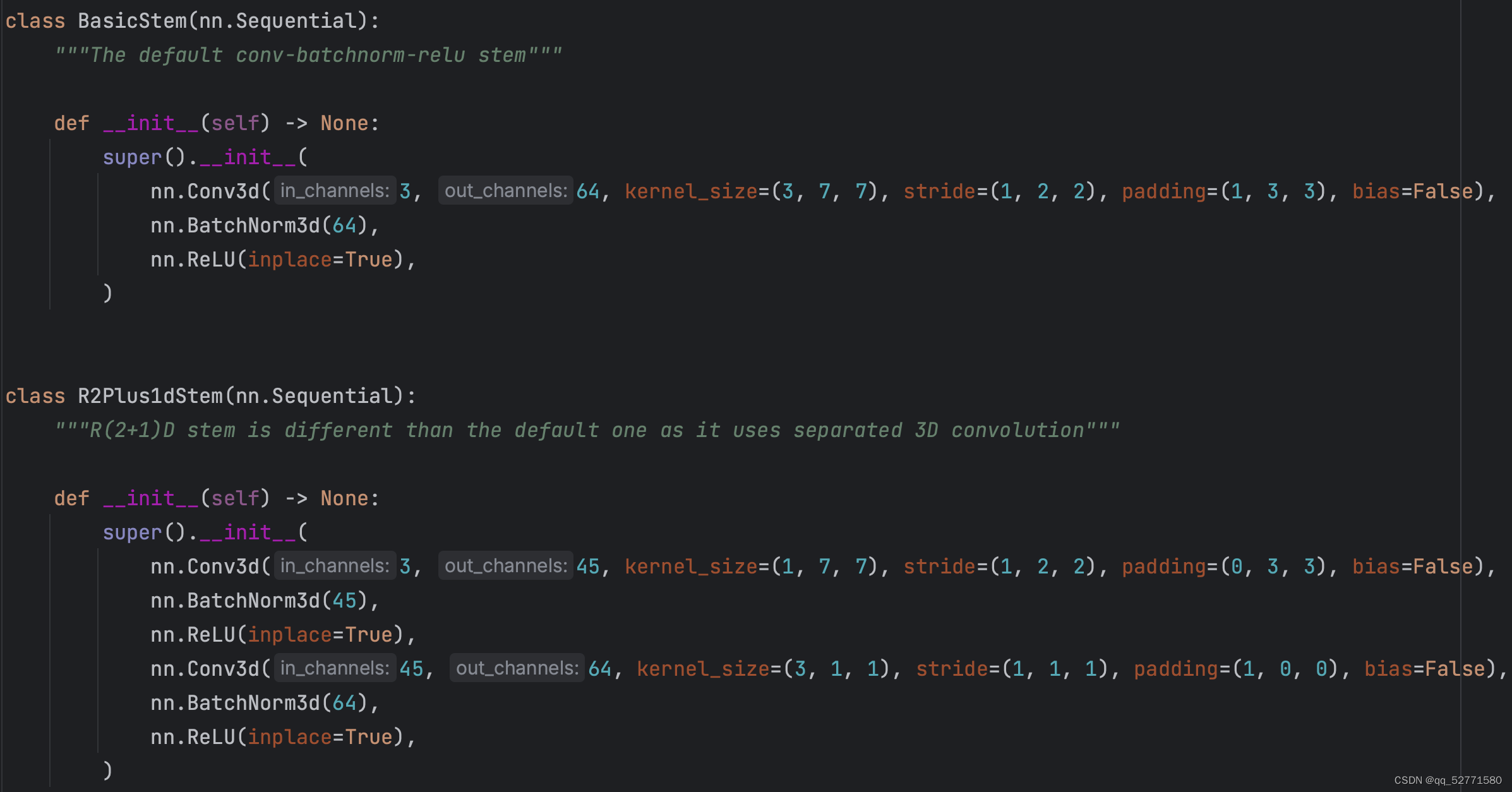 图2 (2+1)D vs 3D 卷积源码示例
图2 (2+1)D vs 3D 卷积源码示例
这里的 Mi=45 不满足式(1)。在 torch 源码中,若均使用 BasicBlock,则只有第 2 组的第一块和 2、3、4、5 组的其它块的第一个 (2+1)D 卷积满足式(1);若均使用 Bottleneck,则只有第一组的第一块满足式(1)。
R3D 将所有的 3D 卷积都替换为对应的 (2+1)D 卷积就得到 R(2+1)D。
4、总结
在论文[2] 中作者主要引入了 2 种新的时空卷积形式 MCx 和 R(2+1)D,其中 MCx 中 MC3 的动作识别 accuracy 最高, MC3 的 accuracy 明显超过了同层数的 R3D,但参数量大约只有其 1/3。R(2+1)D 的参数量和对应的 R3D 差不多,但其 accuracy 明显超过了 MC3。
参考文献
[1] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 770–778, 2016.
[2] Du Tran, Heng Wang, Lorenzo Torresani, Jamie Ray, Yann LeCun, and Manohar Paluri. A closer look at spatiotemporal convolutions for action recognition. In CVPR, pages 6450–6459, 2018.