【系统架构师】-第19章-大数据架构设计理论与实践
四个特点:
大规模(Volume)、高速度(Velocity)和多样化(Variety),价值(Value)。
五个问题:
异构性(Heterogeneity)、规模(Scale)、时间性(Timeliness)、复杂性(Complexity)和隐私性(Privacy)
五个挑战:
1. 数据获取问题。
2.数据结构问题。
3.数据集成问题。
4.数据分析、组织、抽取和建模等功能性挑战。
5. 如何呈现数据分析的结果,并与非技术的领域专家进行交互。
1、架构的演进
1)异步缓冲

2)读写分离

3)hadoop M/R批处理

2、大数据面临的挑战
数据复杂:结构化、半结构化数据
数据量大:
数据挖掘:
3、大数据处理架构特征:
1、鲁棒性和容错性:机器是不可靠的,允许机器宕机
2、低延迟读取和更新能力
3、横向扩展(Scalable):服务器主机扩展,而不是增强机器性能
4、通用性:多领域支持
5、延展性:需求变动
6、即席查询能力
7、最少维护能力
8、可调试性
4、Lambda架构
1、批处理层
存储数据集(HDFS)、M/R处理离线数据、直接生成 batch view
要求数据原始的、不可变、永远真实
2、加速层(流处理)
增量的数据流、生成 real-time view。有新数据后,更新r-t view。
采用Spark或Storm,结果缓存在MemSQL或Redis中
如果批处理层重新计算生成,则清空real-time view数据。最终一致性
3、服务层
整合batch View 与 real-time View数据集,形成结果集
采用 HBase或Cassandra
响应用户的查询请求,提供主数据集的计算结果的低延迟访问
4、查询视图
面向用户,由Hive创建可查询视图

5、优缺点
1.优点
(1)容错性好。 Lambda架构为大数据系统提供了更友好的容错能力,一旦发生错误,我们
可以修复算法或从头开始重新计算视图。
(2)查询灵活度高。批处理层允许针对任何数据进行临时查询。
(3)易伸缩。所有的批处理层、加速层和服务层都很容易扩展。因为它们都是完全分布式
的系统,我们可以通过增加新机器来轻松地扩大规模。
(4)易扩展。添加视图是容易的,只是给主数据集添加几个新的函数。
2.缺点
(1)全场景覆盖带来的编码开销。
(2)针对具体场景重新离线训练一遍益处不大。
(3)重新部署和迁移成本很高。
6、横向比对
1、事件溯源(Event Sourcing)
(1)整个系统以事件为驱动,所有业务都由事件驱动来完成。
(2)事件是核心,系统的数据以事件为基础,事件要保存在某种存储上。
(3)业务数据只是一些由事件产生的视图,不一定要保存到数据库中。
2、CQRS(查询修改分离)
5、Kappa架构
简化了Lambda架构,移除了批处理层,以消息队列Kafka 作为数据存储及流通道
当需要进行离线分析或者再次计算的时候,则将数据湖的数据再次经
过消息队列重播一次则可

优缺点:
1、部署维护简单
2、数据存储、回溯困难
kappa+架构
将不同来源的数据通过Kafka导入到Hadoop 中,通过HDFS来存储中间
数据,再通过 spark对数据进行分析处理,最后交由上层业务进行查询

6、Lambda与Kappa架构比对

7、补充实际案例架构
案例一
hive查询视图
MemSQL 内存数据库
HBase 整合view
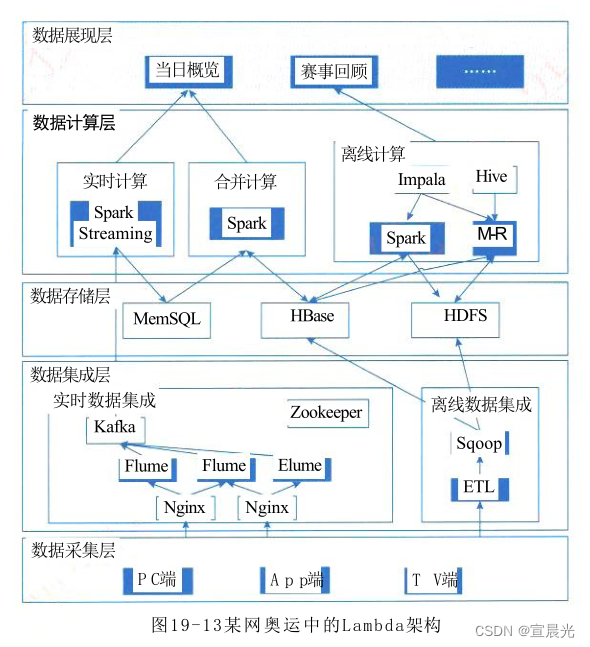
案例二
kafka 向HDFS存储数据,并实时推送数据给Spark 流处理
在批处理层,把转化数据表和曝光数据表导入到Hive中,用Hive Sql做好join, 将两张表聚合而成的结果表导出到MySQL, 提供给服务层
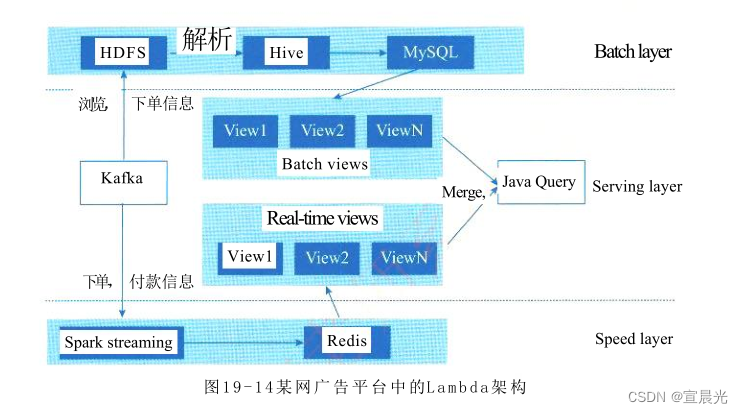
案例三
实时日志分析平台基于Kappa架构,使用统一的数据处理引擎Flink可实时处理全部数据,
并将其存储到Elastic-Search与OpenTSDB中。实时处理过程如下:
(1)日志采集,即在各应用系统部署采集组件Filebeat, 实时采集日志数据并输出到 Kafka
缓存。
(2)日志清洗与解析,即基于大数据计算集群的Flink计算框架,实时读取Kafka中的日
志数据进行清洗和解析,提取日志关键内容并转换成指标,以及对指标进行二次加工形成衍生
指标。
(3)日志存储,即将解析后的日志数据分类存储于 Elastic-Search 日志库中,各类基于日志
的指标存储于OpenTSDB指标库中,供前端组件搜索与查询。
(4)日志监控,即通过单独的告警消息队列来保持监控消息的有序管理与实时推送。
(5)日志应用,即在充分考虑日志搜索专业需求的基础上,平台支持搜索栏常用语句保存,
选择日志变量自动形成搜索表达式,以及快速按时间排序过滤、查看日志上下文等功能
