mysql查询条件包含IS NULL、IS NOT NULL、!=、like %* 、like %*%,不能使用索引查询,只能使用全表扫描,是真的吗???
不知道是啥原因也不知道啥时候, 江湖上流传着这么一个说法 mysql查询条件包含IS NULL、IS NOT NULL、!=、like %* 、like %*%,不能使用索引查询,只能使用全表扫描。
刚入行时我也是这么认为的,还奉为真理!
但是时间工作中你会发现还是走索引啊!下面我们来一一探究其中的奥秘。
一、首先验证一下是会走索引的
创建一个表,结构如下:
create table user_info(
id int PRIMARY key auto_increment,
name varchar(16) default '',
age tinyint default 0,
address varchar(32) default '',
PRIMARY KEY (`id`),
KEY `name` (`name`),
KEY `address_2` (`address`,`name`)
);
ALTER TABLE user_info ADD INDEX (NAME);
ALTER TABLE user_info ADD INDEX (address);数据1
INSERT INTO user_info(NAME,age,address)
VALUES (9,9,'shenzhen9');
BEGIN
DECLARE i INT DEFAULT 1000;
WHILE i < 9000 DO
INSERT INTO user_info (`NAME`, `age`, `address`)
VALUES
(NULL, i , SUBSTRING(MD5(RAND()),1,10) ) ;
SET i = i+ 1 ;
END WHILE ;
① EXPLAIN SELECT * FROM user_info WHERE `name` IS NOT NULL
② EXPLAIN SELECT * FROM user_info WHERE `name` !='9'
③ EXPLAIN SELECT * FROM user_info WHERE `name` is null数据2
INSERT INTO user_info(NAME,age,address)
VALUES (null,9,'shenzhen9');
BEGIN
DECLARE i INT DEFAULT 1000;
WHILE i < 9000 DO
INSERT INTO user_info (`NAME`, `age`, `address`)
VALUES
(REPLACE(UUID(),'-',''), i , SUBSTRING(MD5(RAND()),1,10) ) ;
SET i = i+ 1 ;
END WHILE ;
④ EXPLAIN SELECT * FROM user_info WHERE `name` IS NOT NULL
⑤ EXPLAIN SELECT * FROM user_info WHERE `name` !='9'
⑥ EXPLAIN SELECT * FROM user_info WHERE `name` is null执行数据1 会发现sql①②走索引,③不走索引
执行数据2 会发现sql⑥走索引,④⑤不走索引


二、B+树数据排列规则
1、聚簇索引索引:
①页面中的记录是按照主键值进行排序的;
②B+树每一层节点(页面)都是按照页中记录的主键值大小进行排序的;
③B+树叶子节点对应的页面中存储的是完整的用户记录(就是一条记录中包含我们定义的所有列值,还包含一些InnoDB自己添加的一些隐藏列);
2、二级索引:
①页面中的记录是按照给定的索引列的值进行排序的。
②B+树每一层节点(页面)都是按照页中记录的给定的索引列的值进行排序的。
③B+树叶子节点对应的页面中存储的只是索引列的值 + 主键值。
二级索引值能为空。那对于索引列值为NULL的二级索引记录,在B+树的哪个位置呢?
在B+树的最左边。如下图
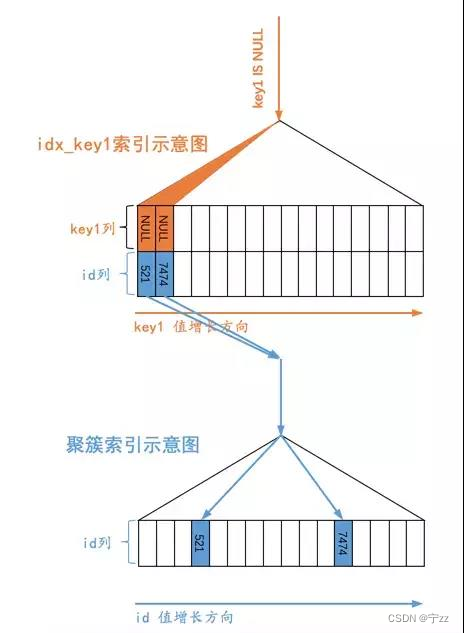
至于为什么,InnoDB是这样的规定:SQL中的NULL值是列中最小的值
什么时候索引又不生效了呢?
对比数据1和数据2两个数据中null值的数量不一样,当null值占多数时is not null 和!=走索引 ,is null不走索引了,数据2刚好相反。
估计大家都能看出什么来了。带索引字段使用null做判断是否走索引与数据量有关,归纳起来就是成本问题(关于mysql索引扫描成本计算详细分析建议大家可以去看一下掘金小册《mysql是怎样运行的:从根上理解mysql》)。
索引(二级索引)扫描成本:
1、读取索引记录成本
2、反查主键索引查找完整数据成本即回表
如果查询读取的二级索引越多那么需要回表查询的次数就会越多,达到一定的比例就会变成全部查询了,也就是上面null 查询时索引有时不生效的原因。
综上MySQL中决定使不使用某个索引执行查询的依据是成本大小。而不是在WHERE子句中用了IS NULL、IS NOT NULL、!=这些条件
三、如何让like‘%字符串%’,‘字符串%’时走索引
通常情况下我们使用like %*%、%*的确不会走索引 但是并不代表就一定不能走索引,我们对上面表中name和age建立复合索引
explain select name from user_info where name like '%a%';SIMPLE user_info index idx_n_a 53 6 16.67 Using where; Using indexexplain select name,age from user_info where name like '%a%';SIMPLE user_info index idx_n_a 53 6 16.67 Using where; Using index以下两个例子是查询了不在复合索引中的列进而造成全表扫描
explain select name,age,address from user_info where name like '%a%';
SIMPLE user_info ALL 6 16.67 Using whereexplain select * from user_info where name like '%a%';
SIMPLE user_info ALL 6 16.67 Using where所以like走不走索引并不是绝对的,要看使用条件!
原文链接:https://blog.csdn.net/weixin_29454029/article/details/113127748