sparksession对象简介
什么是sparksession对象
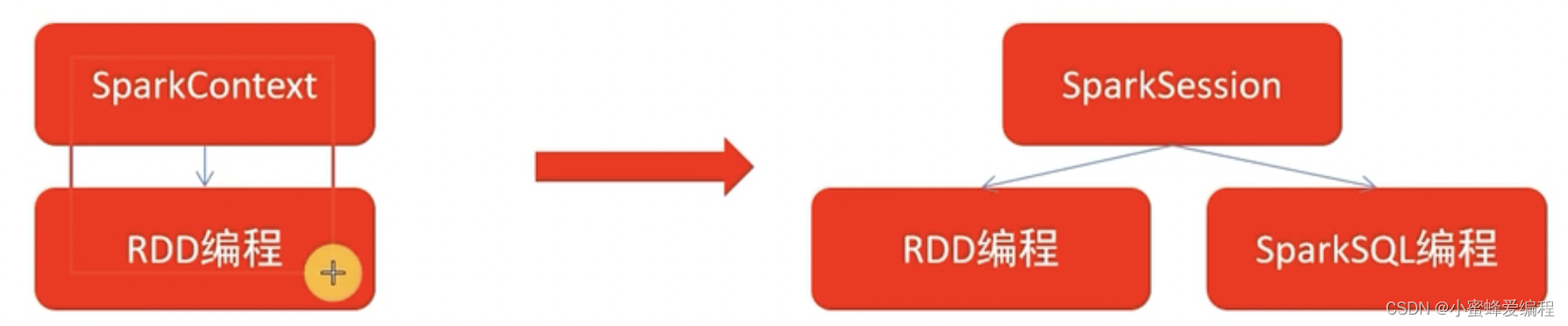
spark2.0之后,sparksession对象是spark编码的统一入口对象,通常我们在rdd编程时,需要SparkContext对象作为RDD编程入口,但sparksession对象既可以作为RDD编程对象入口,在sparkcore编程中可以通过它来获取sparkcontext对象进行rdd编程,也可以直接作为sparksql编程入口对象
sparksession对象构建案例
# coding:utf8
# sparksql中入口对象是SparkSession对象
from pyspark.sql import SparkSession
if __name__ == '__main__':
# 构建sparksession对象,构建器模式
spark = SparkSession.builder.\
appName("mysparkTest").\
master("local[*]").\
config("spark.sql.shuffle.partitions", "4").\
getOrCreate()
# appName设置程序名称
# local: 表示 Spark 将在本地模式下运行,即不会连接到任何集群管理器(如 YARN、Mesos 或 Kubernetes)。这通常用于开发和测试目的。
# [*]: 这是一个特殊的语法,它告诉 Spark 使用所有可用的处理器核心来执行。星号 (*) 是一个占位符,它会被替换为当前机器上的处理器核心数。
# config设置一些常用属性,不想设置可以不用写
# getOrCreate创建sparksession对象
# 通过SparkSession来获取SparkContext对象
sc = spark.SparkContext
# 读取csv格式文件,返回DataFrame格式的数据
df = spark.read.csv("my_csv_file.csv", sep=',', header = False)
# 给df加上表头,并赋值给新的df2
df2 = df.toDF("id", "name", "age")
# 打印df2表结构
df2.printSchema()
# 展示df2
df2.show()
# 创建临时视图,用于sql操作
df2.createTempView("score")
# SQL风格操作
spark.sql("SELECT * FROM score where age=11 limit 5").show()
# DSL风格
df2.where("age=11").limit(5).show()