使用ES检索PDF等文档的全栈方案之前端demo(end)
写在前面
通过之前的系列文章,整个ES搜索文件的流程与大的问题已经统统扫除了,既然是全栈流程,是不能缺少前端查询页面的,前端需简单实现一个用户输入查询关键词句,发起搜索,页面以表格形式展示查询的结果,额外可以提供文件的预览或下载操作。
系列可阅读:
1. 实现ES检索pdf等文件内容的插件
2. 基于GitBucket的Hook构建ES检索PDF等文档全栈方案
3. Java实现读取转码写入ES
4. ES文件搜索的细节优化与实现
5. ES解析word内容为空的问题和直接使用Tika解析文档的方案
实现前端demo
前端框架使用vue快速创建,并基于axois进行后端接口的交互,前提是后端的ES数据查询接口要提前创建好并启动。
具体的操作步骤,从安装vue客户端开始到启动服务,如下:
npm install -g @vue/cli
ln -s /opt/local/npm/node-v16.19.1-linux-x64/bin/vue /usr/bin/vue
vue -V
# 创建模板项目~HelloWorld
vue create lauf
cd lauf && ll
# 安装依赖
npm install
npm install axios -g
# 启动服务
npm run serve
项目结构如上!我们主要修改vim HelloWorld.vue,如果需要调用后端服务请求数据,需在依赖中添加axios库并安装,否则会编译失败。
npm查询依赖有哪些版本:
npm view axios versions
页面效果
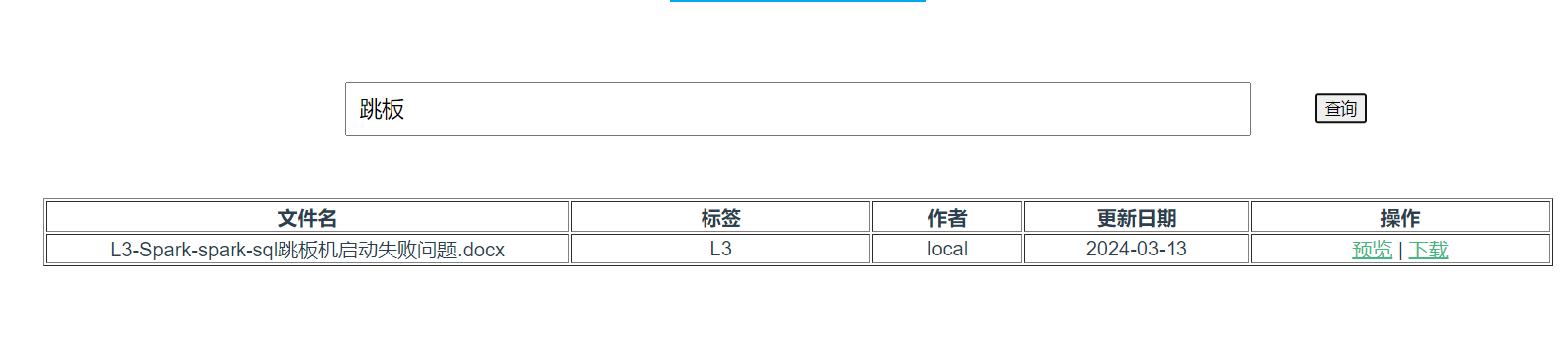
页面可输入关键词点击查询,下方以表格形式返回搜索到的结果,包含标题等信息,以及预览和下载等操作。
ES索引结构与查询语句
#这个是索引的最终mapping结构,设置了多个分片
PUT /docwrite2
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 2
},
"mappings": {
"properties": {
"id": {
"type": "keyword"
},
"title": {
"type": "text",
"analyzer": "ik_max_word"
},
"fileType": {
"type": "keyword"
},
"active": {
"type": "boolean"
},
"upTime": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
},
"content": {
"type": "text",
"analyzer": "ik_smart"
}
}
}
}
# 这个是一个输入关键词进行查询的DSL语句
GET /docwrite2/_search
{
"query": {
"multi_match": {
"query": "跳板机",
"fields": [
"content",
"title"
],
"analyzer": "ik_smart"
}
},
"_source": {
"excludes": ["content"]
}
}
索引结构简介
这是一个在Elasticsearch中创建索引(名为"docwrite2")的RESTful API请求,使用PUT方法。该索引具有特定的设置和映射(数据结构定义)。
-
Settings:
"number_of_shards": 3:表示索引将被分成3个分片,这是Elasticsearch水平扩展的基础,可以提高搜索和存储性能。"number_of_replicas": 2:每个主分片会有2个副本分片,用于提供高可用性和容错性,当某个节点失效时,可以从副本分片继续提供服务。
-
Mappings:
"id":类型为"keyword",这意味着它将被当作不可分割的整体进行索引,常用于精确匹配查询。"title":类型为"text",并指定了分析器(analyzer)为"ik_max_word",这通常是一个中文分词器,会对文本内容进行最大粒度的分词处理,便于全文检索。"fileType":同样为"keyword"类型,用于存储文件类型等不需要分词的属性信息。"active":类型为"boolean",用于存储布尔值类型的字段。"upTime":类型为"date",并指定了日期格式为"yyyy-MM-dd HH:mm:ss",用于存储日期时间类型的数据。"content":类型为"text",并指定了分析器为"ik_smart",这也是一个中文分词器,但相比"ik_max_word",它倾向于更智能的最少切分策略,更适合用于较短的文本片段或标题等内容。
查询语句解释
这个Elasticsearch查询语句是用来在名为“docwrite2”的索引中搜索包含关键词“跳板机”的文档,并且在返回结果中排除了“content”字段的内容。以下是详细的解析:
-
GET /docwrite2/_search: 这是一个针对“docwrite2”索引执行搜索操作的HTTP GET请求。_search端点用于执行搜索查询并返回相关结果。 -
请求体中的查询部分:
-
"query": { ... }:这部分定义了搜索的查询条件。 -
"multi_match": { ... }:这是一种复合查询类型,允许在一个或多个指定字段上执行全文本搜索。在这个例子中:"query": "跳板机":表示要查找的关键词是“跳板机”。"fields": ["content", "title"]:指定要在哪些字段上执行搜索,这里包括“content”和“title”两个字段。"analyzer": "ik_smart":指定使用名为“ik_smart”的分析器来分析查询字符串以及索引中的相应字段内容。由于之前在映射中为"text"类型的字段指定了中文分词器,此处选用“ik_smart”分析器来进行智能分词匹配。
-
-
返回结果控制部分:
"_source": { "excludes": ["content"] }:这一节控制了返回结果中原始文档_source字段的包含或排除规则。在这个案例中,要求在返回的每个匹配文档中排除“content”字段的内容,这意味着即使文档匹配,也不会显示“content”字段的值。
整个查询语句的作用是从索引“docwrite2”的“content”和“title”字段中查找包含词语“跳板机”的文档,并在返回结果时,不显示每个匹配文档的“content”字段内容。