第四章 保护模式入门
保护模式概述
为什么要有保护模式
在实模式下,用户可以访问底层,用户程序乃至操作系统的数据都可以被随意地删改。存在数据安全的问题。
访问内存过小且麻烦,内存不够用,资源也不够用。
在保护模式下,物理内存地址不能直接被程序访问,程序内部的地址(虚拟地址)需要被转化为物理地址后再去访问。

实模式不是32位CPU,变成了16位
32位CPU具有保护模式和实模式两种运行模式,可以兼容实模式下的程序。兼容实模式,是指能够正确处理好实模式下的程序,并不是说在实模式下运行时就完全变成了纯16位的CPU。
最开始,CPU的运行模式是16位的实模式,之后出现32位时也出现了新的模式保护模式,这两个模式主要是为了区分16位和32位的运行模式。兼容就是说在32位下也能运行之前16位的实模式,当它在16位的实模式中,依然具备处理32位操作数的能力。现在的实模式就是指32位的CPU运行在16位模式下的状态。
初见保护模式
保护模式之寄存器扩展
CPU发展到32位后,地址总线和数据总线也发展到32位,其寻址空间更达到了2的32次方,4GB。
寻址方式不变,依然是“段基址:段内偏移地址”。
为了能让一个寄存器访问4GB空间,需要寄存器宽度提升到32位。
寄存器要做到向下兼容,除了能访问到4GB也要做到能访问1MB。

偏移地址和实模式下一样,为了更加安全,添加了“约束条件”,也就是对内存段的描述信息,使用全局描述符表来表示,由GDTR寄存器指向它。
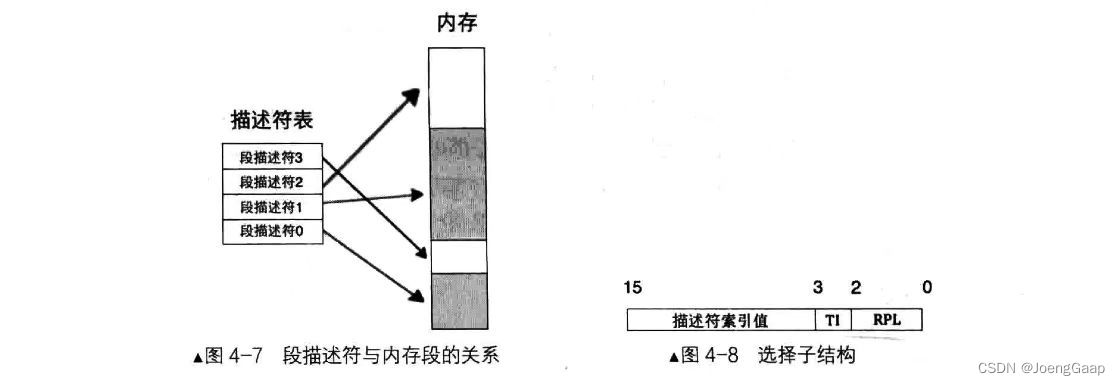
段寄存器里的保存内容叫“选择子”,selector,该选择子起始就是个数,用这个数索引全局描述符表中的段描述符,把全局描述符表当成数组,选择子就像数组下标一样。

为了提高获取段信息的效率,对段寄存器率先应用了缓存技术,将段信息用一个寄存器来缓存,这就是段描述符缓冲寄存器(Descriptor Cache Registers)。以后每次访问相同的段时,就直接读取该段寄存器对应的段描述符缓冲寄存器。这样做主要时为了避免重复计算。
在实模式下也可以。在实模式下时,段基址左移4位后的结果就被放入段描述符缓冲寄存器中,以后每次引用这一个段时,就直接走段描述缓冲寄存器,直到该段寄存器被重新赋值。
CPU有三种模式:实模式、虚拟8086模式、保护模式。

保护模式之寻址扩展
实模式下的寻址方式:

在实模式下的寄存器有固有的使命,只能用规定的寄存器,对于寻址的偏移量,只能是1个字以内的立即数,即不能超过16位。
在保护模式下,基址寄存器和编址寄存器是所有32位的通用寄存器,变址寄存器也是一样,还可以对变址寄存器乘以一个比例因子{1,2,4,8},偏移量变成了32位。


保护模式之运行模式反转
虽然现在的CPU兼容实模式和保护模式,但是需要告诉CPU运行模式生成几位机器码。


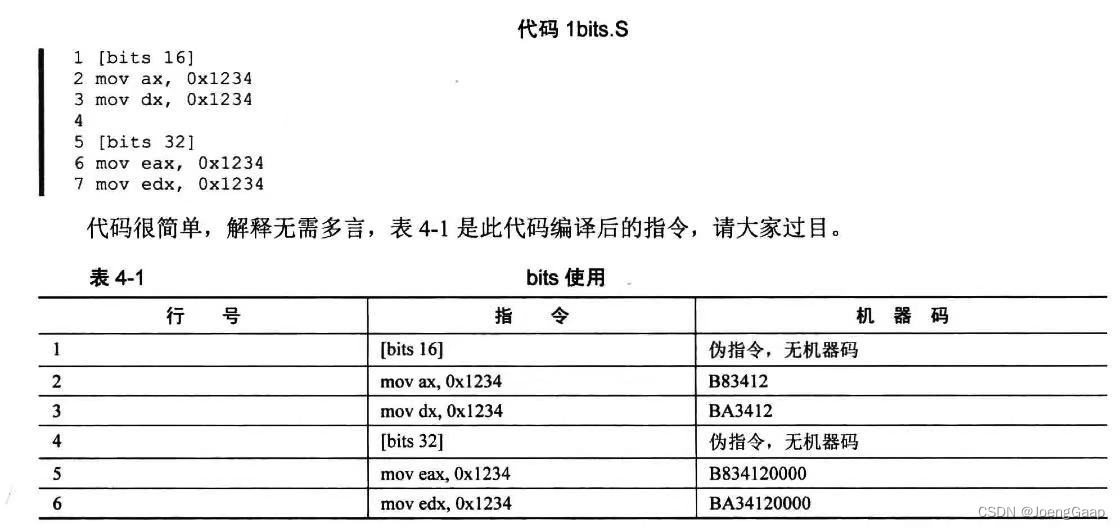
反转前缀:
如果要用另一模式下的操作数大小,需要在指令前添加指令前缀0x66,将当前模式临时改变成另一模式。不管当前模式是什么,总是转变成相反的运行模式。
注意,变的只是操作数大小,且这个转换只是临时的,只在当前指令有效。
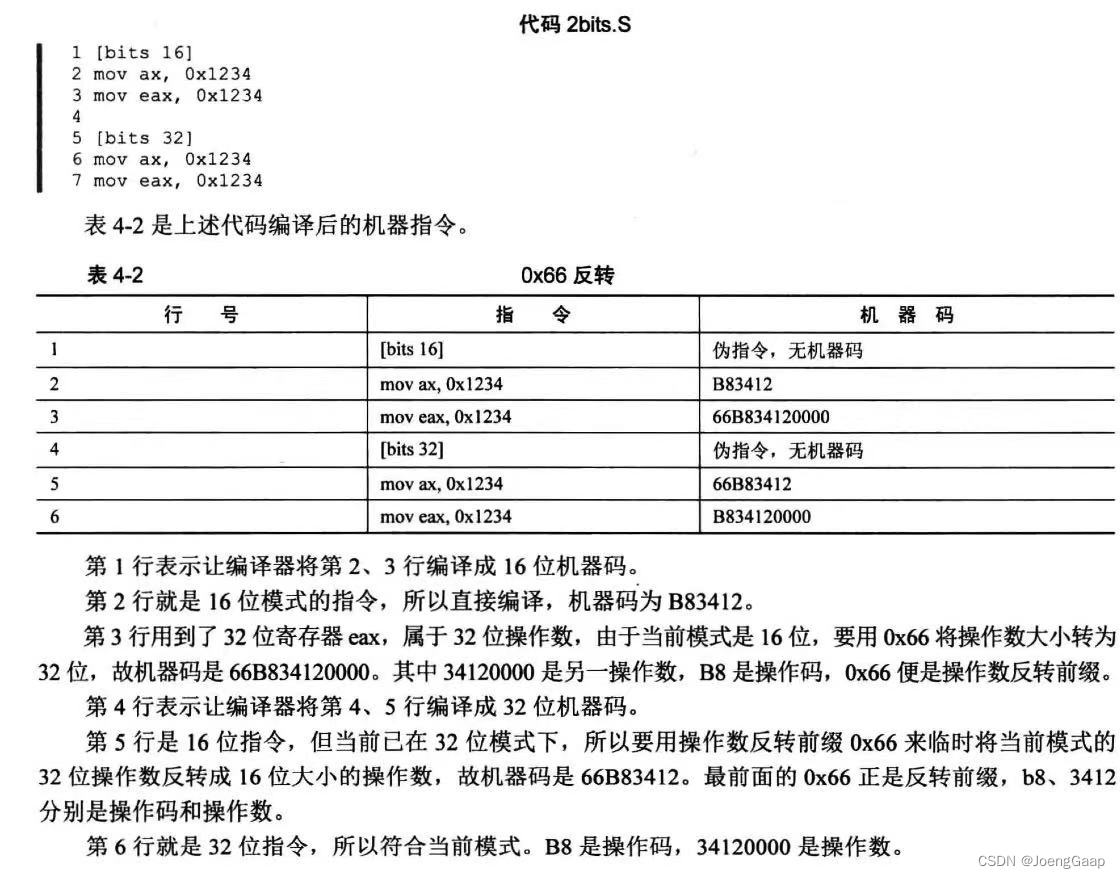
**寻找方式反转前缀0x67:**使用对方模式下的寻址方式。

bit伪指令用于指定运行模式,操作数大小反转前缀0x66和寻址方式反转前缀0x67,用于临时将当前运行模式下的操作数大小和寻址方式转变成另一种模式下的操作数大小及寻址方式。
保护模式之指令扩展
在16位的实模式下,CPU操作数是16位。在32位的保护模式下,操作数扩展到了32位,于是涉及到操作数变化的指令也要跟着扩展,既要兼容16的操作数,也要支持32位的操作数。同样的指令,在实模式和保护模式下都可以同时处理16位和32位的数据。

全局描述符表
全局描述符表(GDT)是保护模式下内存段的登记表,这是不同于实模式的显著特征之一。
段描述符
段描述符是8字节大小,共64位。
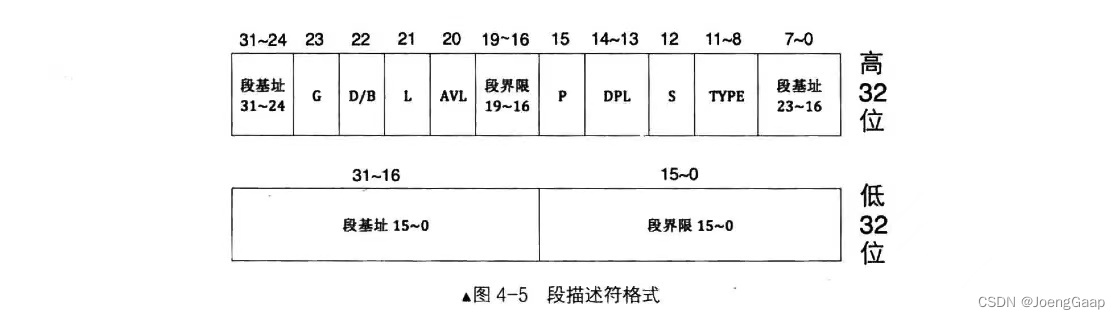


保护模式下地址总线宽度是32位,段基址需要用32位地址来表示。
段界限表示段边界的扩展最值,及最大扩展到多少或最小扩展到多少。扩展方向只有上下两种。对于数据段和代码段,段的扩展方向是向上,即地址越来越高,此时的段界限用来表示段内偏移的最大值。对于栈段,段的扩展方向向下,即地址越来越低,此时的段界限用来表示段内偏移的最小值。
段界限用20个位来表示。段的大小要么是2的20次方等于1MB,要么是2的32次方等于4GB(4KB2^20)。
实际的段界限边界值=(描述符中段界限+1)(段界限的粒度大小:4KB或1)-1。
如果G位为0,表示段界限粒度大小为1字节,如果G为1,表示段界限粒度大小为4KB字节。
内存访问需要用到“段基址:段内偏移地址”,段界限其实是用来限制段内偏移地址的,段内偏移地址必须位于段的范围之内,否则CPU会抛出异常。
全局描述符表GDT、局部描述符表LDT及选择子
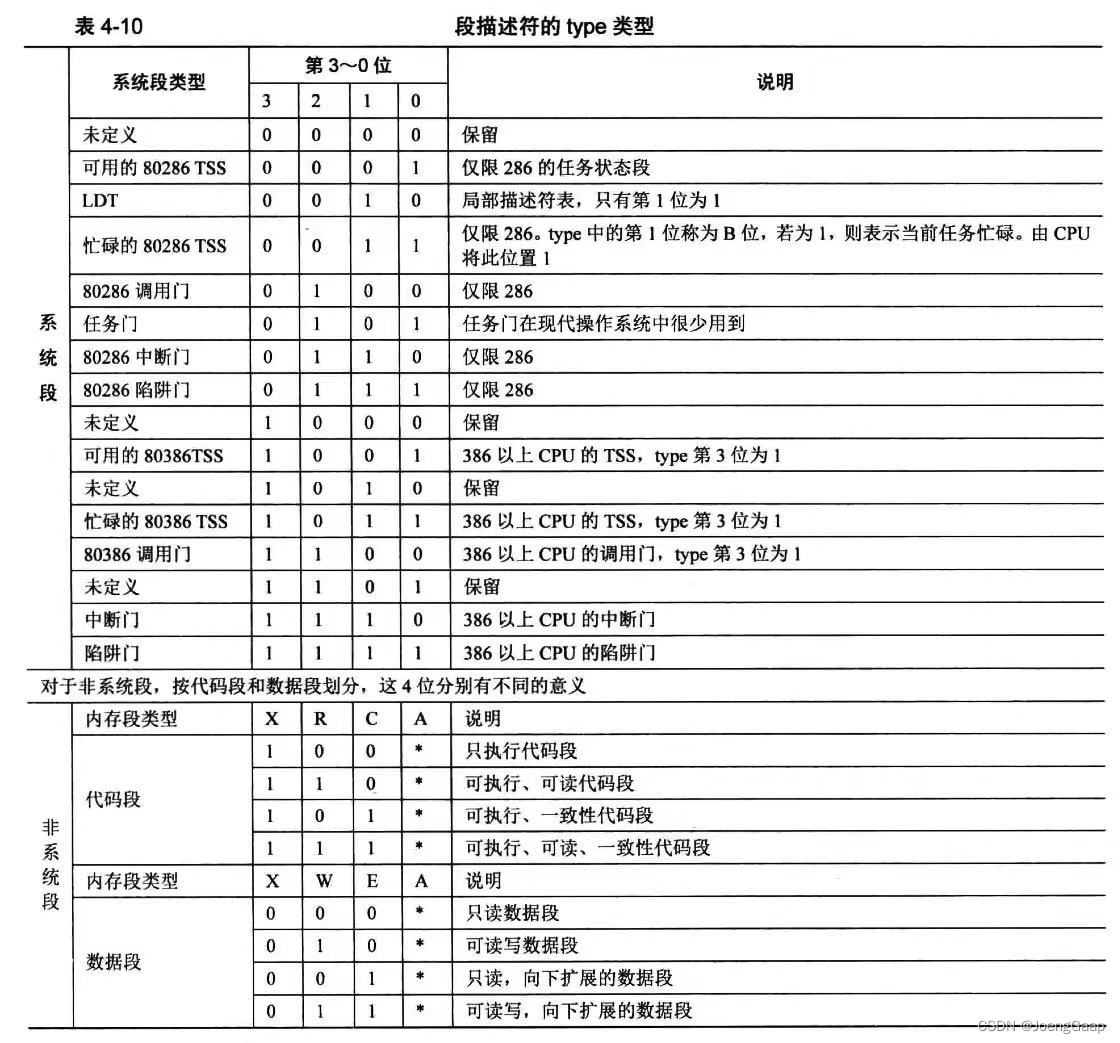
一个段描述符只用来定义一个内存段。代码段、数据段和栈段等多个内存段的段描述符都放在全局描述符表中。
全局描述符表相当于是描述符表的数组,数组中的每个元素都是8字节的描述符。多个程序都可以在里面定义自己的段描述符,是公用的。
全局描述符表位于内存中,需要用专门的寄存器GDTR指向它。GDTR是48位寄存器。
使用lgdt指令对GDTR初始化。lgdt的指令格式是:lgdt48位内存数据。

选择子:
选择子的作用主要是确定段描述符,确定描述符的目的,一是为了特权级、界限等安全考虑,最主要的还是要确定段的基地址。
保护模式下的段寄存器中已经是选择子,不再是直接的段基址。段基址在段描述符中,用给出的选择子索引到描述符后,CPU自动从段描述符中取出段基址,再加上段内偏移地址,便凑成了“段基址:段内偏移地址”。
选择子的索引值部分是13位,即2的13次方是8192,故最多可以索引8192个段,这和GDT中最多定义8192个描述符是吻合的。
局部描述符表LDT是CPU厂商为在硬件一级原生支持多任务而创建的表。
打开A20地址线
地址回绕:
实模式下的地址线是20位,最大寻址空间是1MB(2^20),即0x00000~0xFFFFF。
实模式下内存访问采用的是“段基址:段内偏移地址”的形式,段基址要乘以16后再加上段内偏移地址。实模式下寄存器都是16位,如果段基址和段内偏移地址都为16位的最大值,即0xFFFF:0xFFFF,最大地址是0xFFFF0+0xFFFF,即0x10FFEF。
所以可能会超过内存空间。对于超过1MB的部分自动回绕到0地址,继续从0地址开始映射。相当于把地址对1MB求模。超过1MB多余出来的内存被称为高端内存区HMA。
对于只有20位地址线的CPU,不需要任何额外操作便能自动实现地址回绕。
对于80286后续的CPU,通过A20 GATE来控制A20地址线。CPU发展到80286后虽然地址总线发展到了24位,但为了兼容,实模式下只使用20条地址线。当超出1MB时,当访问0x10000~0x10FFEF,系统会访问这块内存而不是回绕到0。

打开A20GATE:
in al, 0x92
or al, 0000_0010B
out 0x92, al
保护模式的开关,CR0寄存器的PE位
CR0寄存器第0位,即PE位,此位用于启用保护模式。

进入保护模式
进入保护模式(实现)
处理器微架构简介
流水线
指令执行单元EU是执行指令的唯一部件,一次只能执行一个指令,单核CPU的情况下,只有一个指令处于执行中。CPU中的各部分也是同时只能做一件事,不过在并行工作,各司其职。
CPU的指令执行过程分为取指令、译码、执行三个步骤。每个步骤都是独立执行的,CPU可以一边执行指令,一边取指令,一边译码。
CPU是按照程序中指令顺序来填充流水线的,当前指令和下一条指令在空间上是挨着的。如果当前执行的指令是jmp,会清空流水线。
执行周期越短,CPU所执行的数量越多,效率越高,但流水线级数肯定越多。将每一步操作再继续划分成粒度更细的微操作可以提升效率。

乱序执行
指在CPU中运行的指令并不按照代码中的顺序执行,而是按照一定的策略打乱顺序执行。
当一个“大”操作被分解成多个“微”操作时,它们之间通常独立无关联,所以非常适合乱序执行。
乱序执行的好处就是后面的操作可以放到前面来做,利于装载到流水线上提高效率。
缓存
用一些存取速度较快的存储设备作为数据缓冲区,避免频繁访问速度较慢的低速存储设备。
待执行的指令和相关数据存储在低速的内存中,让CPU这种高速设备等待慢速的内存,实在是太浪费CPU资源了。对于缓存,可以根据程序的局部性原理采取缓存策略。局部性原理是:程序90%的时间都运行在程序中10%的代码上。
CPU将当前用到的指令和当前位置附近的数据都加载到缓存中,大大提高CPU效率,下次直接从缓存中拿数据,不用再区内存中取了。

分支预测
CPU中的指令是在流水线上执行的。分支预测,是当处理器遇到一个分支指令时,是该把分支左边的指令放到流水线上,还是把分支右边的指令放到流水线上。比如if,switch这些。如果分支预测错了,只要将流水线清空就好了。


使用远跳转指令清空流水线,更新段描述符缓冲寄存器
段描述符在变成保护模式前是实模式下的值,进入保护模式后需要更新。

流水线中指令译码错误。在实模式下是16位指令格式,到了保护模式需要变成32指令格式。
所以,既要改变代码段描述符缓冲寄存器的值,又要清空流水线。

保护模式之内存段的保护
保护模式的保护主要体现在段描述符的属性字段中。
向段寄存器加载选择子时的保护
根据选择子的值验证段描述符是否超越界限。
检查段寄存器的用途和段类型是否匹配。
检查段是否存在。
代码段和数据段的保护
对于代码段和数据段来说,CPU每访问一个地址,都要确认该地址不能超过其所在内存段的范围。