ChatTTS容器构建教程
一、模型介绍
ChatTTS 是专门为对话场景设计的文本转语音模型,例如 LLM 助手对话任务。它支持英文和中文两种语言。最大的模型使用了 10 万小时以上的中英文数据进行训练。在 HuggingFace 中开源的版本为 4 万小时训练且未 SFT 的版本。
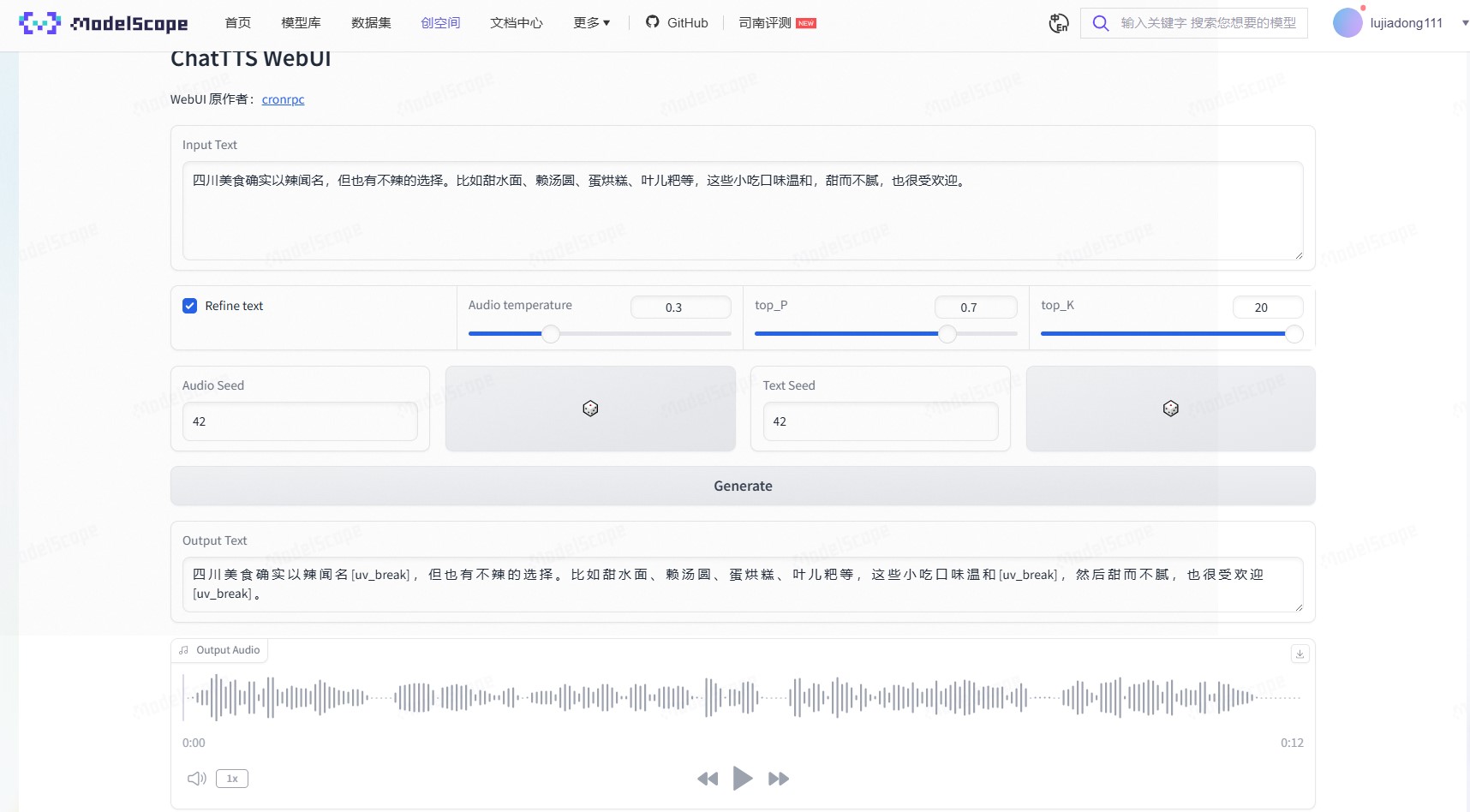
ChatTTS WebUI如下:
二、应用场景
ChatTTS适用于需要高质量语音交互的场景,包括但不限于以下部分:
- 虚拟助手 :在聊天机器人或语言模型中,提供自然的语音回复,增强用户体验。
- 智能客服 :在客户服务系统中,通过语音与用户交流,解决用户问题。
- 教育娱乐 :在教育软件、有声读物、游戏等应用中,提供生动有趣的语音讲解和角色配音。
- 无障碍辅助 :为视障人士提供语音阅读服务,帮助他们更好地获取信息。
三、容器构建过程
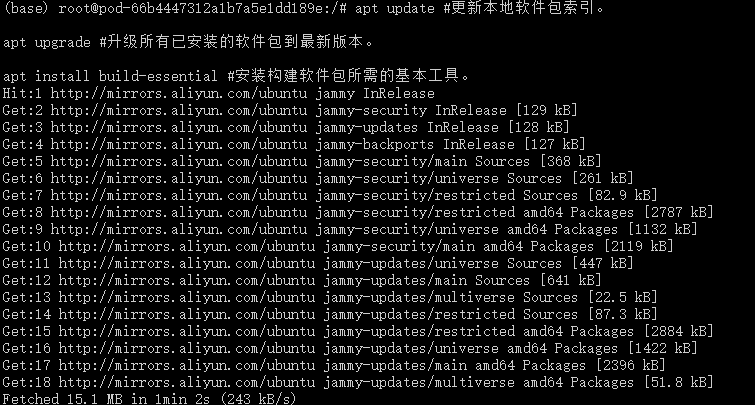
1、安装更新基础环境
apt update
apt upgrade
apt install build-essential
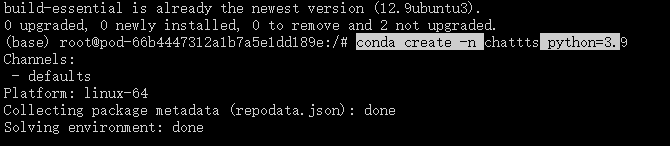
2、创建虚拟环境
conda create -n chattts python=3.9
conda activate chattts
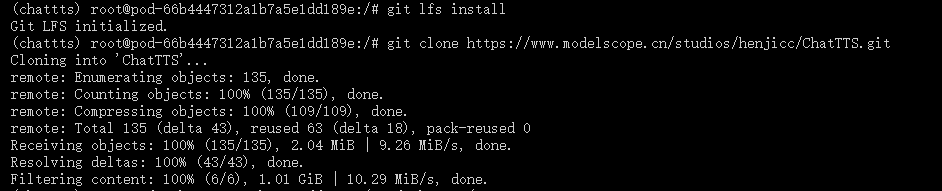
3、克隆项目仓库
apt install git
git lfs install
git clone https://www.modelscope.cn/studios/henjicc/ChatTTS.git
4、安装依赖环境
cd ChatTTS
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install -r requirements.txt

5、指定端口,运行 app.py 文件
export GRADIO_SERVER_NAME=0.0.0.0
export GRADIO_SERVER_PORT=8080
python3 app.py

四、ChatTTS WebUI界面展示
回到容器端,开放端口后获取访问地址,浏览器输入网址,搜索进入WebUI界面,在Input Text下方输入想要转音频的文本,点击Generate,等待一段时间即可得到音频。点击音频下方的播放按钮,就可以对转化结果进行展示。
