【Python进阶(十二)】——自然语言处理
🍉CSDN小墨&晓末:https://blog.csdn.net/jd1813346972
个人介绍: 研一|统计学|干货分享
擅长Python、Matlab、R等主流编程软件
累计十余项国家级比赛奖项,参与研究经费10w、40w级横向
文章目录
- 1 自然语言包导入及设置
- 2 数据读入
- 3 分词处理
- 4自定义词汇
- 5 停用词处理
- 6 词性分布分析
- 7 高频词分析
- 8 词频统计
- 9 关键词分析
- 10 生成词云
- 11 保存图片并释放内存
【Python进阶(十二)】——自然语言处理,建议收藏!
该篇文章主要讲解了基本的自然语言处理,包括自然语言的分词、停用词、词性分析、词频统计、词频分析、词云图生成等。
1 自然语言包导入及设置
import pynlpir as pynlpir#下载并导入包 pynlpir
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
from matplotlib.font_manager import FontProperties
font = FontProperties(fname=r'c:\windows\fonts\simhei.ttf', size=15) #设置字体
2 数据读入
运行程序:
text=open('2017.txt', 'r').read().replace('\n','')#逐行读取并将换行符去掉
text[:150] #查看已读入数据:前150个字符
运行结果:

3 分词处理
运行程序:
pynlpir.open()#打开分词器
pynlpir.segment(text,pos_names='parent',pos_english=False)[:20]#进行探索性分词并显示结果的前20项
#pos_tagging:是否带有词性标注,默认为ture
#pos_names='parent':词性名称返回方式为基本,child为详细
#pos_english:词性名称是否用英文表示
#探索性分词存在问题:
#(1)分词问题:某些词切分不准确
#(2)停用词问题:需要排除个别词语
#(3)缺字段“年份”
运行结果:

如果pynlpir.open()报错:raise RuntimeError(“NLPIR function ‘NLPIR_Init’ failed.”) RuntimeError: NLPIR function ‘NLPIR_Init’ failed.
则是证书过期问题,点击链接:https://github.com/NLPIR-team/NLPIR
打包下载,然后把NLPIR.user替换到
D:\Anaconda3\Lib\site-packages\pynlpir\Data(以实际Python安装包site-packages位置为准)目录下的NLPIR.uer文件,重启解释器,发现pynlpir.open()就不报错了
4自定义词汇
运行程序:
pynlpir.nlpir.AddUserWord('央视'.encode('utf8'),'noun')
pynlpir.nlpir.AddUserWord('主持人:'.encode('utf8'),'noun')
pynlpir.nlpir.AddUserWord('观众朋友们'.encode('utf8'),'noun')
pynlpir.nlpir.AddUserWord('春联'.encode('utf8'),'noun')
pynlpir.nlpir.AddUserWord('一号演播大厅'.encode('utf8'),'noun')
pynlpir.nlpir.AddUserWord('综合频道'.encode('utf8'),'noun')
pynlpir.nlpir.AddUserWord('综艺频道'.encode('utf8'),'noun')
pynlpir.nlpir.AddUserWord('中文国际频道'.encode('utf8'),'noun')
pynlpir.nlpir.AddUserWord('军事农业频道'.encode('utf8'),'noun')
pynlpir.nlpir.AddUserWord('少儿频道'.encode('utf8'),'noun')
运行结果:
2
2
2
2
2
2
2
2
2
2
运行程序:
pynlpir.segment(text,pos_names='parent',pos_english=False)[:20]
运行结果:
[('主持人:', '名词'),
('中国', '名词'),
('中央电视台', '复合语'),
('!', '标点符号'),
('主持人:', '名词'),
('中国', '名词'),
('中央电视台', '复合语'),
('!', '标点符号'),
('主持人:', '名词'),
('此刻', '代词'),
('我们', '代词'),
('在', '介词'),
('北京', '名词'),
('中央电视台', '复合语'),
('一号演播大厅', '名词'),
('向', '介词'),
('全球', '名词'),
('现场', '处所词'),
('直播', '动词'),
('《', '标点符号')]
运行程序:
words = []
year=2017
year_words = []
year_words.extend(pynlpir.segment(text,pos_names='parent',pos_english=False))#追加一个分词结果的新列表
for j in range(len(year_words)):
ls_year_words=list(year_words[j])
ls_year_words.append(year)
words.append(ls_year_words)
words[2:13]
运行结果:
[['中央电视台', '复合语', 2017],
['!', '标点符号', 2017],
['主持人:', '名词', 2017],
['中国', '名词', 2017],
['中央电视台', '复合语', 2017],
['!', '标点符号', 2017],
['主持人:', '名词', 2017],
['此刻', '代词', 2017],
['我们', '代词', 2017],
['在', '介词', 2017],
['北京', '名词', 2017]]
运行程序:
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all" ##执行多输出
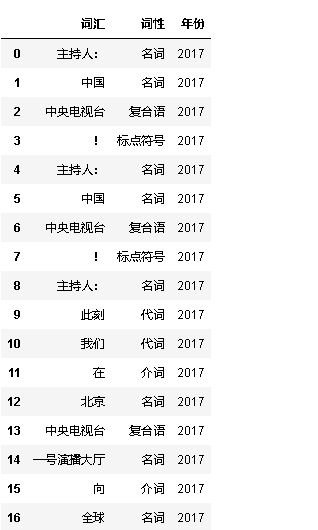
df_words = pd.DataFrame(words,columns=["词汇","词性","年份"])#将words转化为数据框对象
df_words.head(25)
df_words.index.size#显示数据框行数
运行结果:
5 停用词处理
运行程序:
stopwords= open('stopwords.txt').read()#读取停用词
stopwords[:20]
运行结果:
'主持人:\n主持人:\n主持词\n(\n(\n?\n'
运行程序:
for i in range(df_words.shape[0]):#行数
if(df_words.词汇[i] in stopwords):
df_words.drop(i,inplace=True)
else:
pass
df_words.head(15) #过滤停用词
运行结果:

运行程序:
df_words.shape[0] #过滤停用词后行数
运行结果:
3976
6 词性分布分析
运行程序:
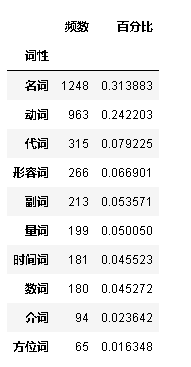
df_WordSpeechDistribution = pd.DataFrame(df_words['词性'].value_counts(ascending=False))#value_counts:基数并按降序排序
df_WordSpeechDistribution.head(10)
df_WordSpeechDistribution.rename(columns={'count':'频数'},inplace=True)#修改列明
df_WordSpeechDistribution.head()
df_WordSpeechDistribution['频数'].sum()#查看行数
运行结果:

运行程序:
df_WordSpeechDistribution['百分比'] = df_WordSpeechDistribution['频数'] / df_WordSpeechDistribution['频数'].sum()#新增一列百分比
df_WordSpeechDistribution.head(10)
运行结果:
运行程序:
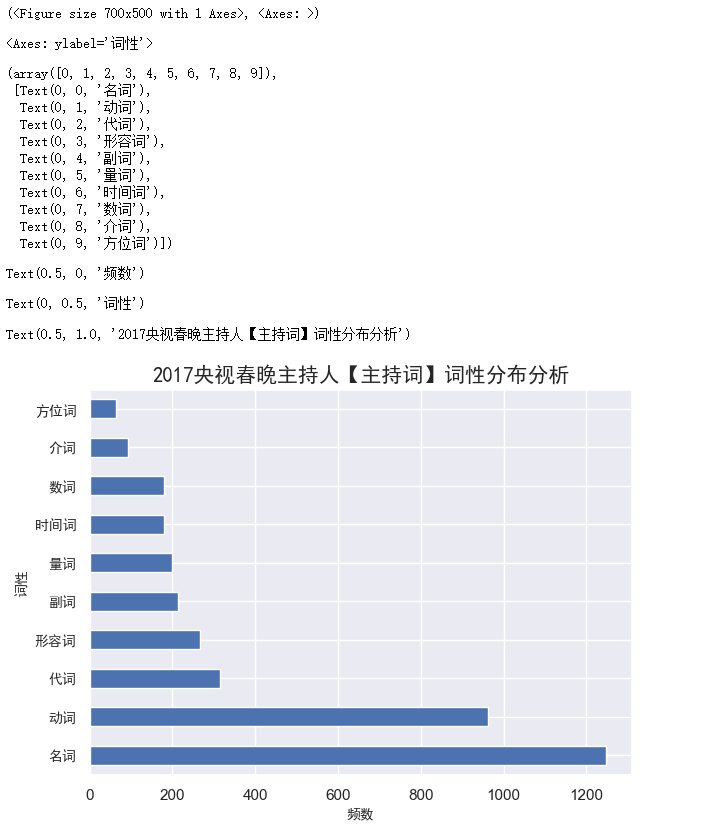
plt.subplots(figsize=(7,5))
df_WordSpeechDistribution.iloc[:10]['频数'].plot(kind='barh')#横向条形图
plt.yticks(fontproperties=font,size=10)
plt.xlabel('频数',fontproperties=font,size=10)
plt.ylabel('词性',fontproperties=font,size=10)
plt.title('2017央视春晚主持人【主持词】词性分布分析',fontproperties=font)
运行结果:
7 高频词分析
运行程序:
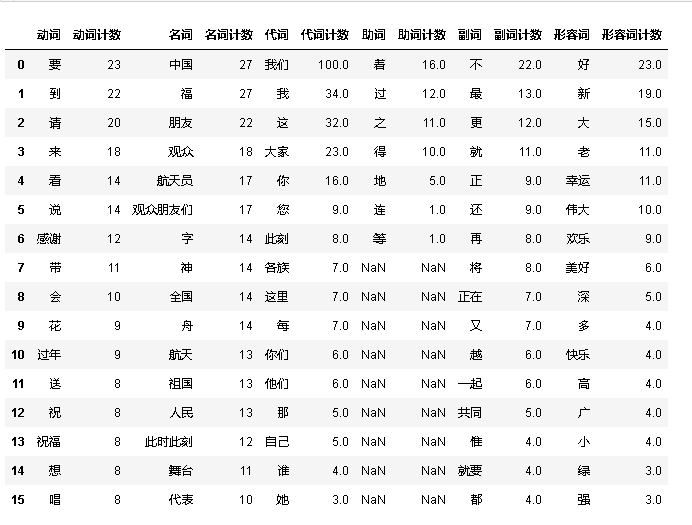
columns_slected=['动词','动词计数','名词','名词计数','代词','代词计数','助词','助词计数','副词','副词计数','形容词','形容词计数']
df_Top6 = pd.DataFrame(columns=columns_slected)
for i in range(0,12,2):
df_Top6[columns_slected[i]] = df_words.loc[df_words['词性']==columns_slected[i]]['词汇'].value_counts().reset_index()['词汇']
df_Top6[columns_slected[i+1]] = df_words.loc[df_words['词性']==columns_slected[i]]['词汇'].value_counts().reset_index()['count']
df_Top6.head(16)
运行结果:
8 词频统计
运行程序:
df_words.head()
df_AnnaulWords=df_words[["年份","词汇"]].pivot(columns="年份", values="词汇")#.pivot:重塑数据
df_AnnaulWords.head()
运行结果:

运行程序:
df_AnnaulWords.fillna(0,inplace=True)#将空值替换成0
df_AnnaulWords.head()
运行结果:

运行程序:
df_AnnualTopWords=pd.DataFrame(columns=[2017])
df_AnnualTopWords[2017]=df_AnnaulWords[2017].value_counts().reset_index()[2017]
df_AnnualTopWords[1:].head(20)#第0行是0,需要排除
运行结果:

9 关键词分析
运行程序:
df_annual_keywords = pd.DataFrame(columns=[2017])
df_annual_keywords[2017]=pynlpir.get_key_words(' '.join(df_AnnualTopWords[2017].astype('str')))#提取关键词并保存到数据框
df_annual_keywords.head(10)
运行结果:

10 生成词云
运行程序:
from wordcloud import WordCloud,ImageColorGenerator
from imageio import imread
font_wc= r'C:\Windows\Fonts\msyhbd.ttc'#需要安装Visual C++ 14.0:http://landinghub.visualstudio.com/visual-cpp-build-tools,选择standalone compiler
myText=' '.join(df_words.词汇)
import imageio
bg_pic = imageio.v2.imread('cac617363047389f.jpg') # 上传背景图片
wc = WordCloud(font_path=font_wc, mask=bg_pic,max_words=500,max_font_size=200,
background_color='white',colormap= 'Reds_r',scale=15.5)
wc.generate(myText)
plt.imshow(wc)
plt.axis('off')
运行结果:

11 保存图片并释放内存
运行程序:
wc.to_file('chun.jpg')#保存图片
pynlpir.close()#释放内存