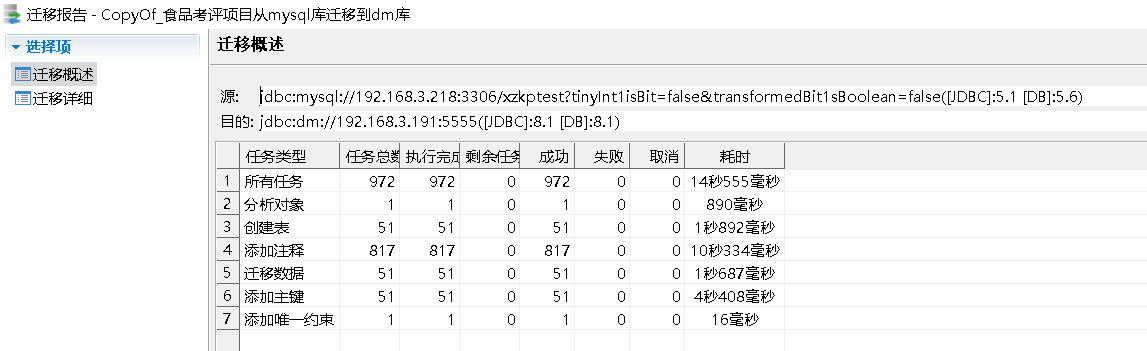
MySQL5.6迁移到DM8
注意: MySQL 5.7 与 MySQL 8.0 的语法有所区别,本文档是将MySQL5.6迁移到DM8。
迁移前准备
源库
数据库信息
统计源端业务库要迁移的数据量、字符编码、归档保留等信息。
| 内容 | 说明 | 备注 |
| 数据库架构 | 单机 | |
| 节点数 | 1 | |
| 数据库版本 | MySQL 5.6.45 | select version(); |
| 待迁移库 | xzkptest | |
| IP 地址/端口 | 192.168.3.218/3306 | |
| 服务器运维用户名(密码) | root:xxxxx | |
| 数据库用户名(密码) | root:xxxxx | |
| 字符集编码 | UTF-8 | show variables like '%character%'; |
| 大小写敏感 | 不敏感 | 默认是不区分大小写 SHOW VARIABLES LIKE 'lower_case_%'; |
| 是否以字节为单位 | 否 | varchar类型是以字符为单位进行存储 |
| 归档保留策略 | / |
迁移对象统计
迁移前统计出需要迁移的库中的对象,提前了解迁移数据量、迁移数据对象、迁移数据类型为考虑迁移时长、停机窗口提供依据,统计库中的对象方法如下:
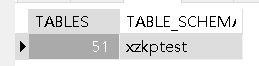
统计指定库中表的数目
SELECT COUNT(*) TABLES, TABLE_SCHEMA FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = 'xzkptest' GROUP BY TABLE_SCHEMA;
参数说明:
TABLE_SCHEMA:数据库名称输出如下:
统计指定库中视图的数目
SELECT TABLE_SCHEMA,COUNT(*) VIEWS FROM INFORMATION_SCHEMA.VIEWS WHERE TABLE_SCHEMA = 'xzkptest' GROUP BY TABLE_SCHEMA;
参数说明:
TABLE_SCHEMA:数据库名称输出为空
统计指定库中所有的存储过程
SELECT `NAME` FROM MYSQL.PROC WHERE DB = 'xzkptest' AND `TYPE` = 'FUNCTION';
参数说明:
DB:数据库名称输出为空
统计指定库中所有的函数
SELECT `NAME` FROM MYSQL.PROC WHERE DB = 'xzkptest' AND `TYPE` = 'FUNCTION';
参数说明:
DB:数据库名称输出为空
统计指定库中所有的触发器
SELECT TRIGGER_SCHEMA ,TRIGGER_NAME FROM MYSQL.TRIGGERS WHERE TRIGGER_SCHEMA= 'xzkptest';
参数说明:
TRIGGER_SCHEMA:数据库名称输出为空
将指定库中所有表数据量记录到辅助表
SELECT TRIGGER_SCHEMA ,TRIGGER_NAME FROM INFORMATION_SCHEMA.TRIGGERS WHERE TRIGGER_SCHEMA= 'xzkptest';
参数说明:
TABLE_SCHEMA:数据库名称输出为空
目标库
DM 目的端信息
| 调研项 | 调研命令 |
| 服务器品牌/型号 | dmidecode |
| 服务器操作系统 | cat /etc/os-release |
| 内存容量 | cat /proc/meminfo |
| CPU 型号/核数 | cat /proc/cpuinfo |
| 端口策略 | 是否与目的端网络、端口互通 |
| 安全策略 | 是否有软件、硬件相关安全限制(比如堡垒机、网闸、文件摆渡) |
| 是否具备可视化界面 | 可视化提供的方式(直连、Xmanager、VNC、BMC 等) |
| 其他 | / |
初始化参数设置
在安装好达梦数据库后还需要初始实例用于对数据的管理,在初始实例时初始化参数尤为重要。
| 数据库参数 | 参数值 |
| DB_NAME(数据库名) | xzspkp |
| INSTANCE_NAME(实例名) | xzspkp |
| PORT_NUM(端口) | 5555 |
| 管理员、审计员、安全员密码(安全版本特有) | 不推荐使用默认密码 |
| EXTENT_SIZE(簇大小) | 16 |
| PAGE_SIZE(页大小) | 32 需要特别注意,如果设置过小迁移过程中会提示长度不够的报错 |
| LOG_SIZE (日志大小) | 2048M |
| CHARSET(字符集) | UTF-8(一般是 UTF8,根据实际要求设置) |
| CASE_SENSITIVE(大小写敏感) | 不敏感(一般是不敏感,根据实际要求设置) |
| BLANK_PAD_MODE(尾部空格填充) | 否 |
其中页大小(page_size)、簇大小(extent_size)、大小写敏感(case_sensitive)、字符集(charset)、结尾空格填充(BLANK_PAD_MODE)一旦确定无法修改,需谨慎设置。
(1)CASE_SENSITIVE 大小写是否敏感设置。CASE_SENSITIVE=1 大小写敏感,包含 2 层意思:
① 表中数据:区分大小写。
② 对象名:对象名区分大小写。
注意
通过管理工具建表时,创建对象时不对对象名加双引号,工具会自动将其转为大写。
MYSQL 建表默认的字符编码是 UTF8_GENERAL_CI,所以建议在 MYSQL 迁移到 DM 时,在达梦端设置成大小写不敏感 CASE_SENSITIVE=0。如果 MYSQL 系统中使用的字符编码是 UTF8_GENERAL_CS,那么建议达梦端设置成大小写敏感 CASE_SENSITIVE=1。MYSQL 设置大小写敏感的细粒度可到字段级别,达梦是实例级别的,一旦设置,后续不可修改,最终还需根据实际情况进行权衡后再设置。
(2) MYSQL 中字符集编码含义:
① UTF8_GENERA_CI:不区分大小写,CI 为 CASE INSENSITIVE 的缩写,即大小写不敏感。
② UTF8_GENERAL_CS:区分大小写,CS 为 CASE SENSITIVE 的缩写,即大小写敏感。
更多初始化参数的详细说明可参考达梦数据库安装目录下 doc 目录中的《 DM8_dminit 使用手册》或在数据库运行目录 bin 目录下执行以下命令查看部分初始化参数说明。
./dminit help兼容性参数设置
| 参数 | 备注 | |
| COMPATIBLE_MODE | 是否兼容其他数据库模式。0:不兼容,1:兼容 SQL92 标准 2:兼容 ORACLE 3:兼容 MS SQL SERVER 4:兼容 MYSQL 5:兼容 DM6 6:兼容 TERADATA。 | SELECT * FROM v$parameter WHERE name like '%COMPATIBLE_MODE%'; 默认值0,0:none, 1:SQL92, 2:Oracle, 3:MS SQL Server, 4:MySQL, 5:DM6, 6:Teradata, 7:PG |
| ORDER_BY_NULLS_FLAG | 控制排序时 NULL 值返回的位置,取值 0、 1、2。 0 表示 NULL 值始终在最前面返回; 1 表示 ASC 升序排序时 NULL 值在最后返回, DESC 降序排序时 NULL 值在最前面返回, 在参数等于 1 的情况下, NULL 值的返回与 ORACLE 保持一致; 2 表示 ASC 升序排序时 NULL 值在最前面返回, DESC 降序排序时 NULL 值在最后返回,在参数等于 2 的情况下, NULL 值的返回与 MYSQL 保持一致。 | 2(兼容 MYSQL)。 |
| MY_STRICT_TABLES | 是否开启 STRICT 模式(严格模式),仅在 COMPATIBLE_MODE=4 时有效。0:不开启,数据超长时自动截断;字符类型转换数值类型(包括 INT、SMALLINT、TINYINT、BIGINT、DEC、FLOAT、DOUBLE)失败时,转换为 0;1:开启,数据超长或计算错误时报错。 | 建议值:1。 |
| BLANK_PAD_MODE(尾部空格填充) | 否 |
创建实例
--df -h查看磁盘,在剩余空间大的目录下创建实例数据目录
mkdir -p /data/dmdb/xzspkp5555
chown -R dmdba:dinstall /data/dmdb/xzspkp5555
--图形化创建实例
/data/dmdbms/tool
./dbca.sh
--更改兼容模式为mysql
vi /opt/dmdb/xzspkp5555/xzspkp/dm.ini
COMPATIBLE_MODE = 4 #Server compatible mode, 0:none, 1:SQL92, 2:Oracle, 3:MS SQL Server, 4:MySQL, 5:DM6, 6:Teradata, 7:PG
--重启库
systemctl restart DmServicexzspkp.service
--创建表空间dbtest,数据文件为DBTEST.DBF。
create tablespace "xzspkp" datafile '/opt/dmdb/xzspkp5555/xzspkp/xzspkp.DBF' size 2048 ;
--更改密码策略
sp_set_para_value(1,'PWD_POLICY',0);
--创建用户指定默认表空间 授予常规权限
create user "xzspkp" identified by "xzspkp" default tablespace "xzspkp" default index tablespace "xzspkp";
grant "PUBLIC","RESOURCE","SOI","SVI","VTI" to "xzspkp";迁移过程
创建迁移
- 打开 DMDTS 迁移工具点击左上方的 3 色小图标新建迁移工程。
- 打开刚刚创建的工程,右键点击“迁移”,选择“新建迁移”,并自定义迁移名称。
- 新建迁移完成后点击下一步。
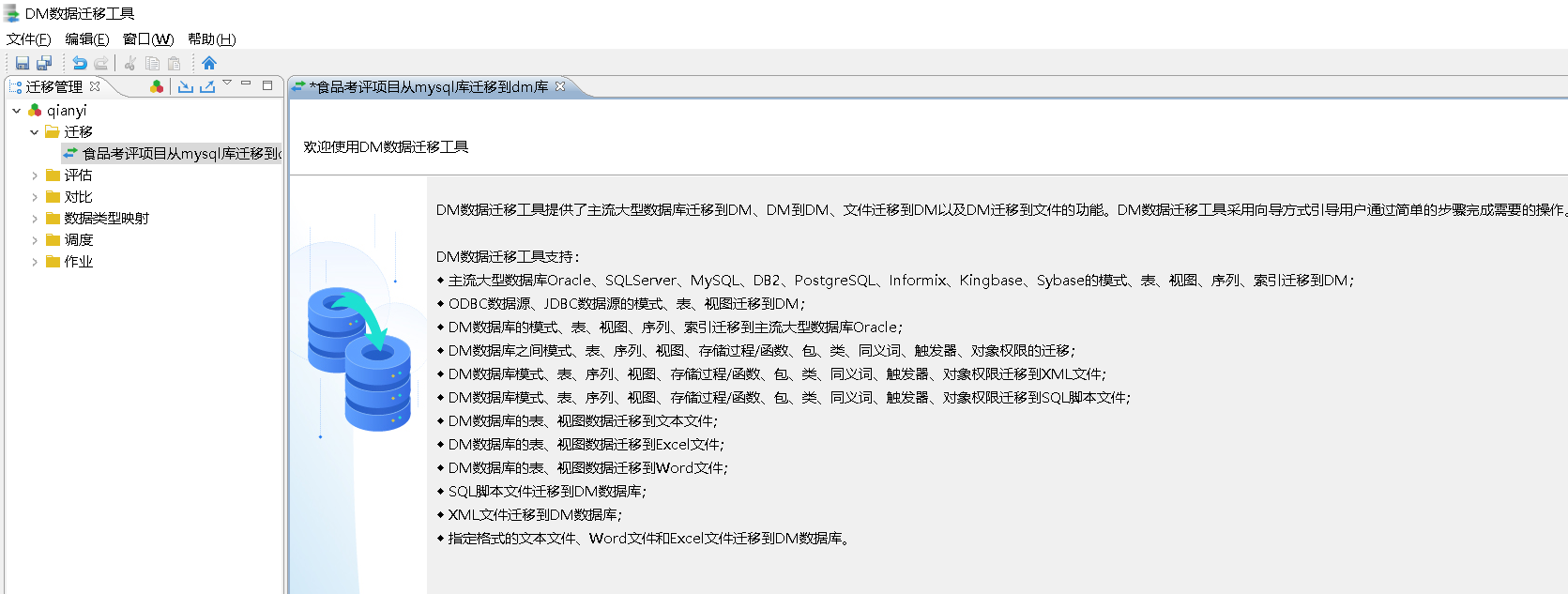
- 在“其它数据库迁移到达梦”选项中选择迁移方式为 “MySQL ==> DM”。
连接数据库
连接源端 MySQL 数据库
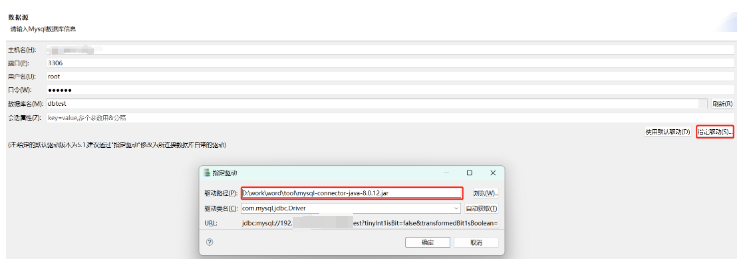
输入源端 MySQL 数据库相关登录信息,在“数据库名”选项中选择需要迁移的数据库。

在创建连接 MySQL 数据库时建议通过指定驱动的方式来连接数据库,避免因为驱动版本不适配等问题导致迁移失败。驱动可以在 MySQL 官网获取与 MySQL 迁移版本相对应的驱动。
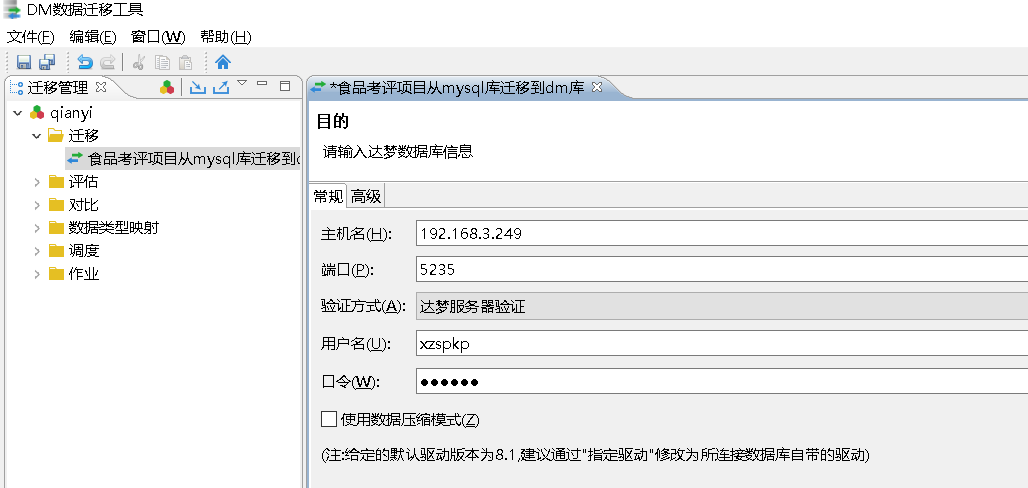
连接目的端 DM 数据库
输入目的端 DM 数据库相关登录信息,选择与源端对应的迁移用户连接数据库。
配置迁移对象及策略
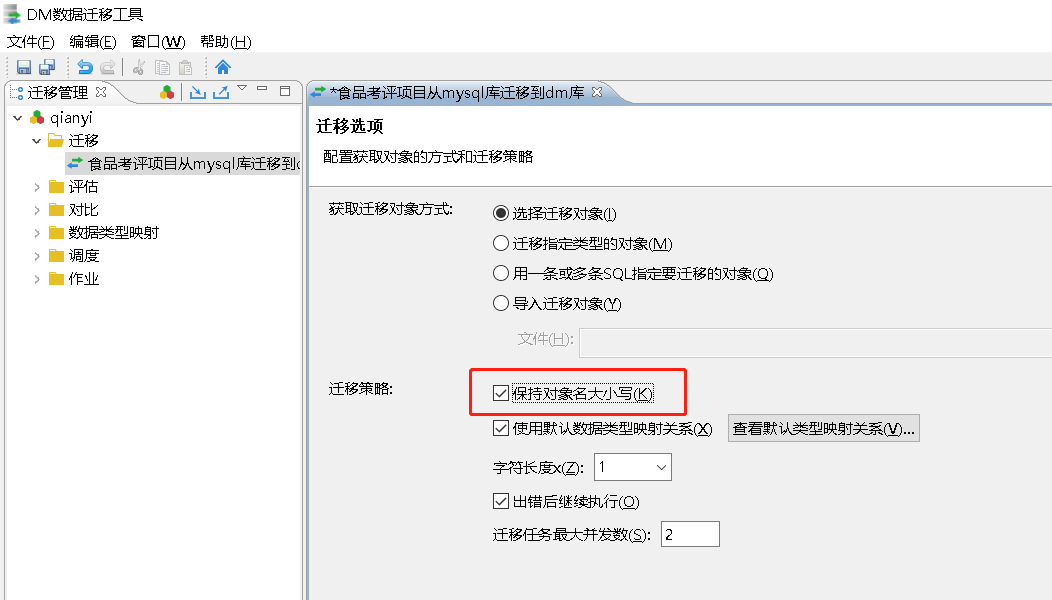
对象名大小写
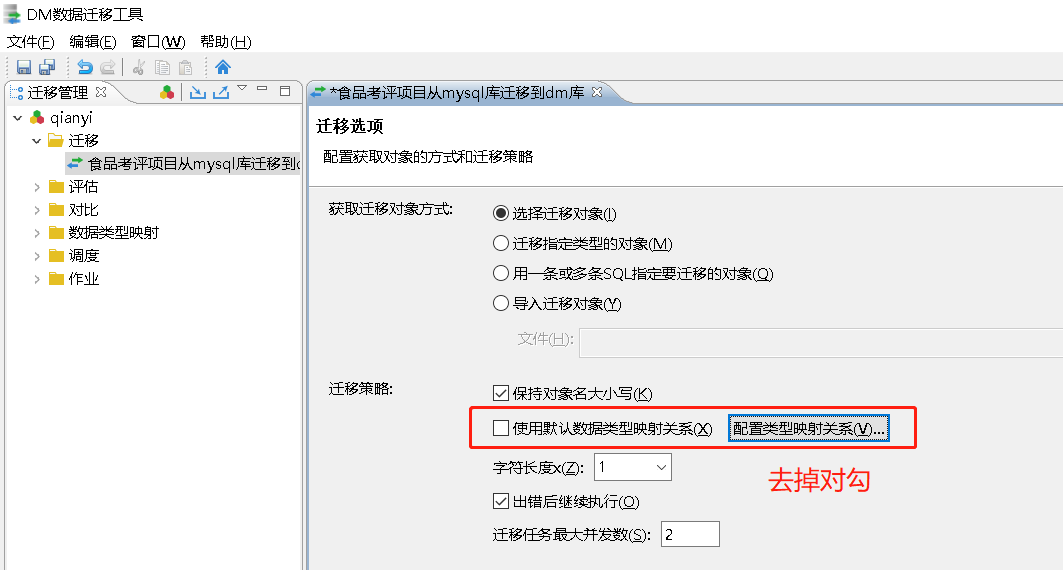
迁移对象方式及迁移策略中勾选“保持对象名大小写”。
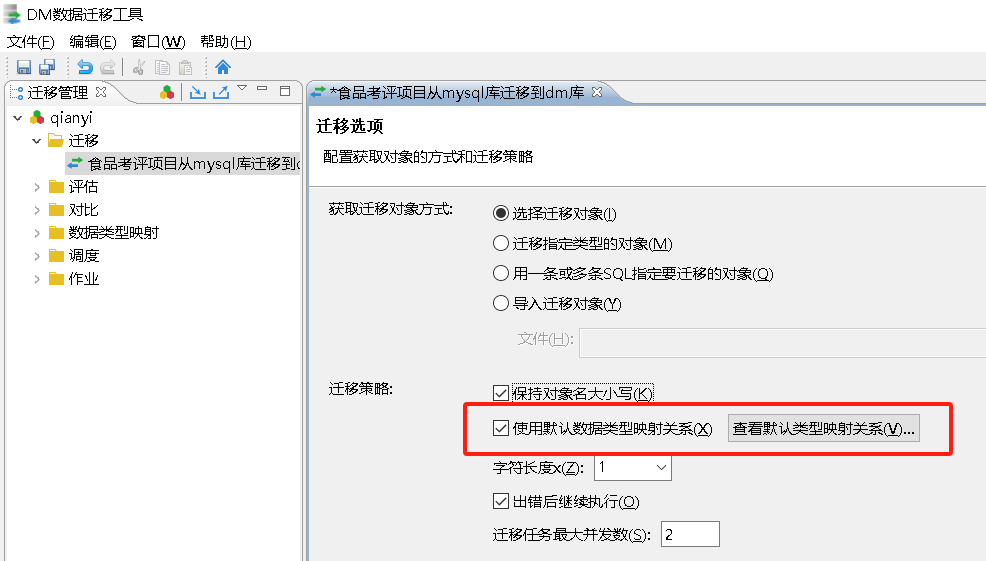
数据类型映射
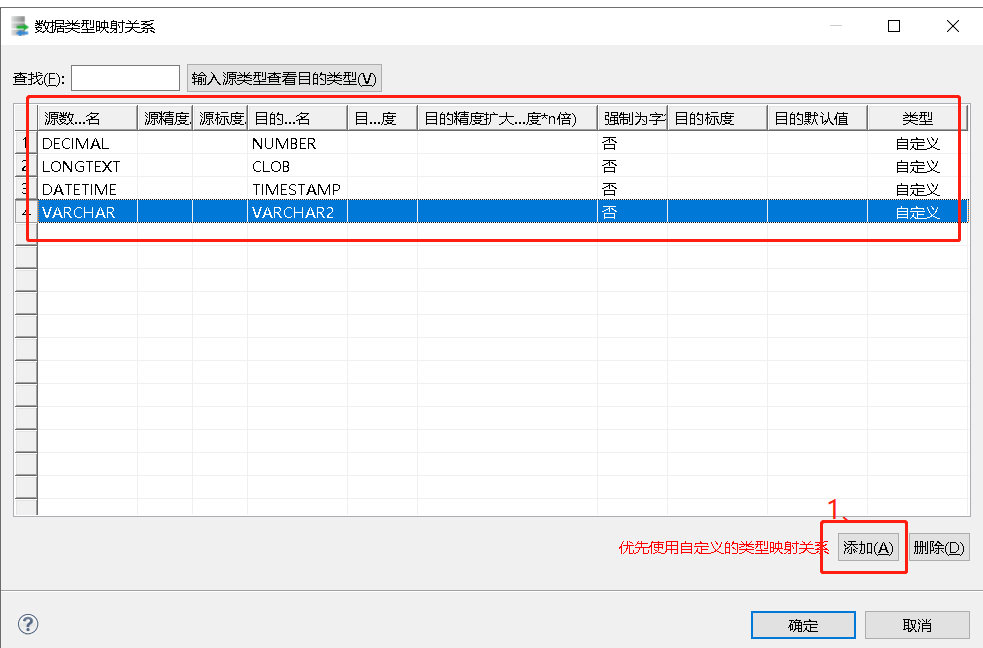
本文档采用场景2:自定义数据类型映射,因为开发要求如下:
根据开发反馈, 迁移过程中必须对部分类型MySQL转换达梦DM的对应关系做出映射的:
MySQL类型 达梦DM类型
decimal numeric
longtext CLOB
datetime TIMESTAMP
varchar varchar2
场景1:默认数据类型映射
当勾选了“使用默认数据类型映射关系”后在迁移时 DTS 会将源端 MySQL 数据库中相应的数据类型采用默认的映射关系映射到目的端 DM 数据库中。如果在这里勾选了“使用默认数据类型映射关系”,后面又自定义了数据类型映射关系,DTS 会优先选择使用自定义的数据映射关系。
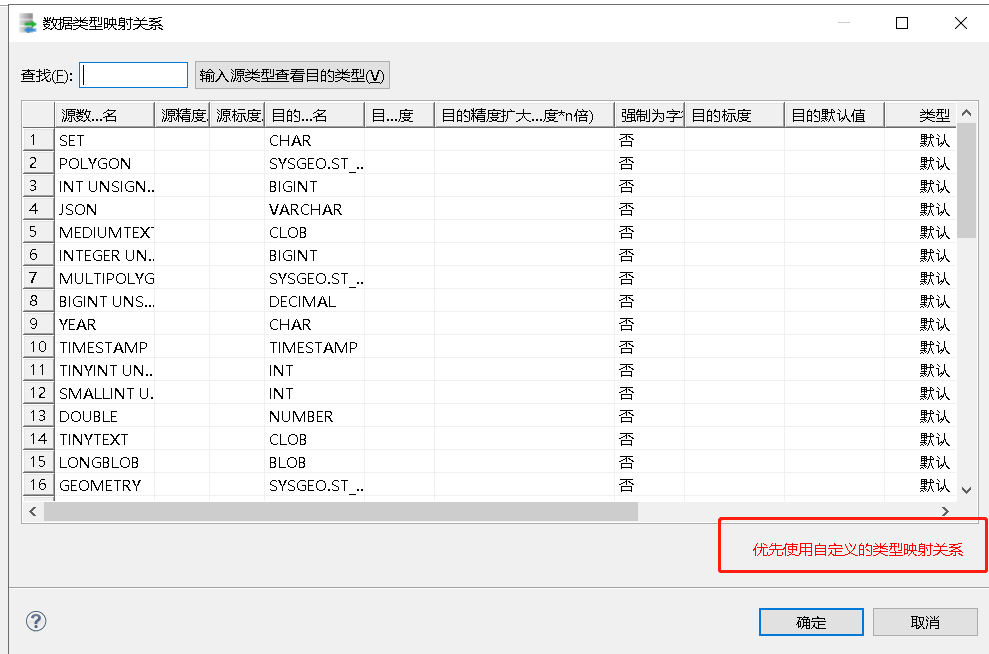
在“迁移策略”中点击“查看数据类型映射关系”可以查看源端 MySQL 到目的端 DM 的数据类型映射关系,包括“源数据类型名”、“源精度”、“源标度”、“目的数据类型名”、“目的精度”等等。
场景2:自定义数据类型映射
勾选源端待迁移的数据库
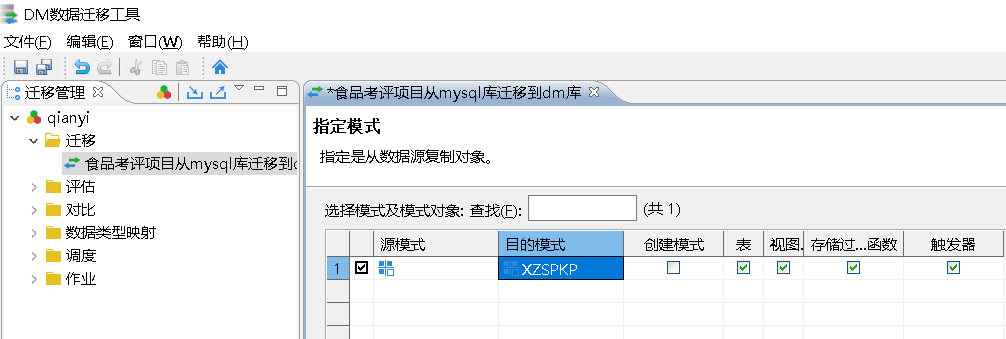
这里需要勾选源端待迁移的数据库,由于 MySQL 端没有模式所以这里模式显示空,并不影响迁移。在 MySQL 数据库连接阶段指定了连接的数据库,所以这里只显示了一条信息。
在指定模式阶段,用户可以通过“源模式”选择源端要迁移的库,通过“目的模式”来指定源端要迁移到 DM 的模式,通过是否勾选“创建模式”、“表”、“视图”、“存储过程/函数”、“触发器”来指定目的端 DM 是否要迁入源端 MySQL 中的这些对象。由于在 DM 数据库准备阶段已经提前将 XZSPKP 模式创建好了,所以这里就不勾选“创建模式”。
勾选源端数据库中需要迁移的对象。
这里可以看到源端待迁移库中所有的对象,用户可以自定义选择 MySQL 需要迁移的具体对象。
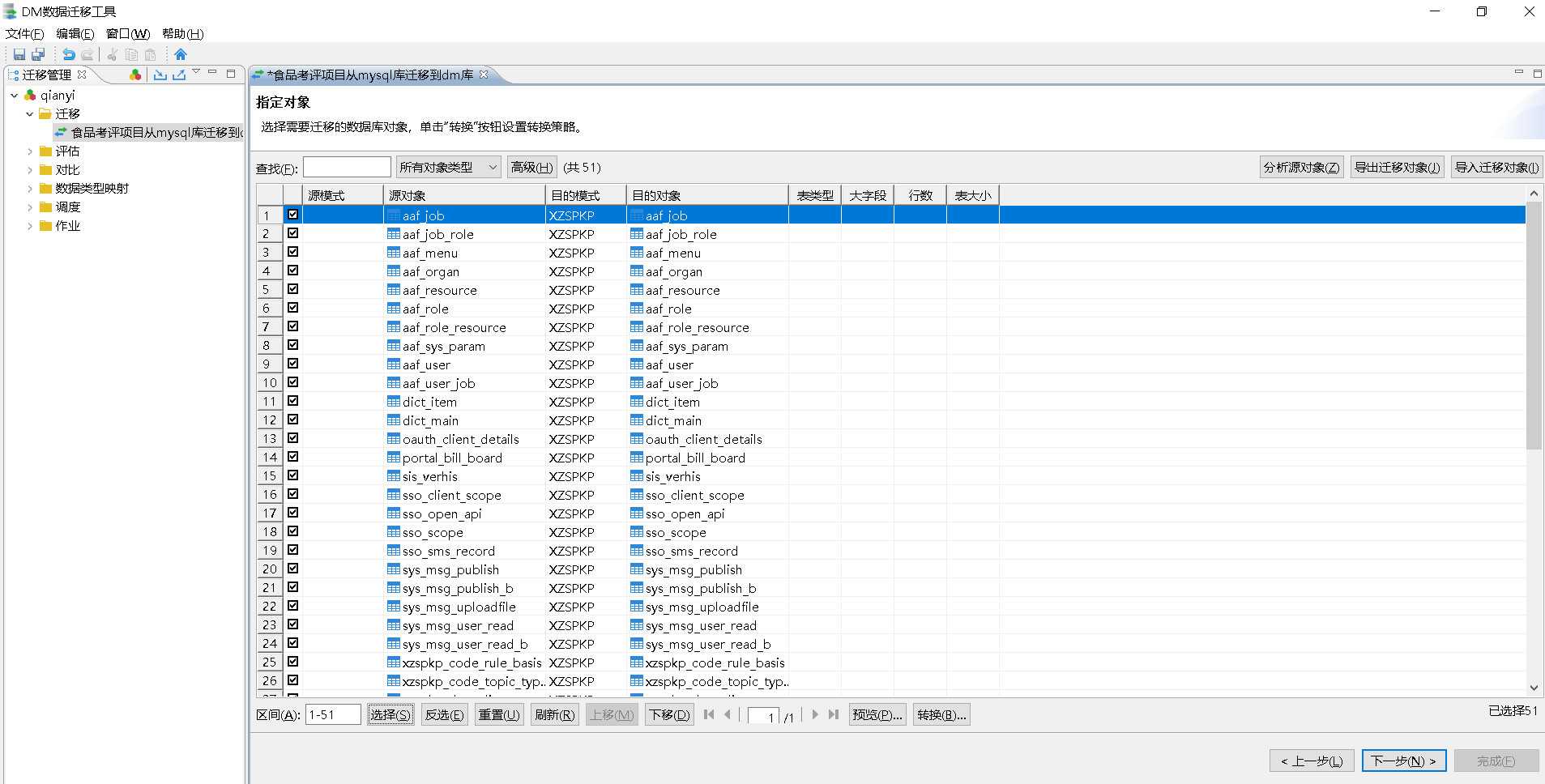
注意
在 SQL 评估阶段不兼容的对象不需要勾选,待其它对象迁移完成后,再手动修改和导入这些不兼容的对象。
用户可以通过点击右上方的“分析源对象”统计选中的源端待迁移对象。用户可以通过该功能对源端迁移对象进行统计分析,包括“源对象统计”、“源表统计”、“源表详细”。
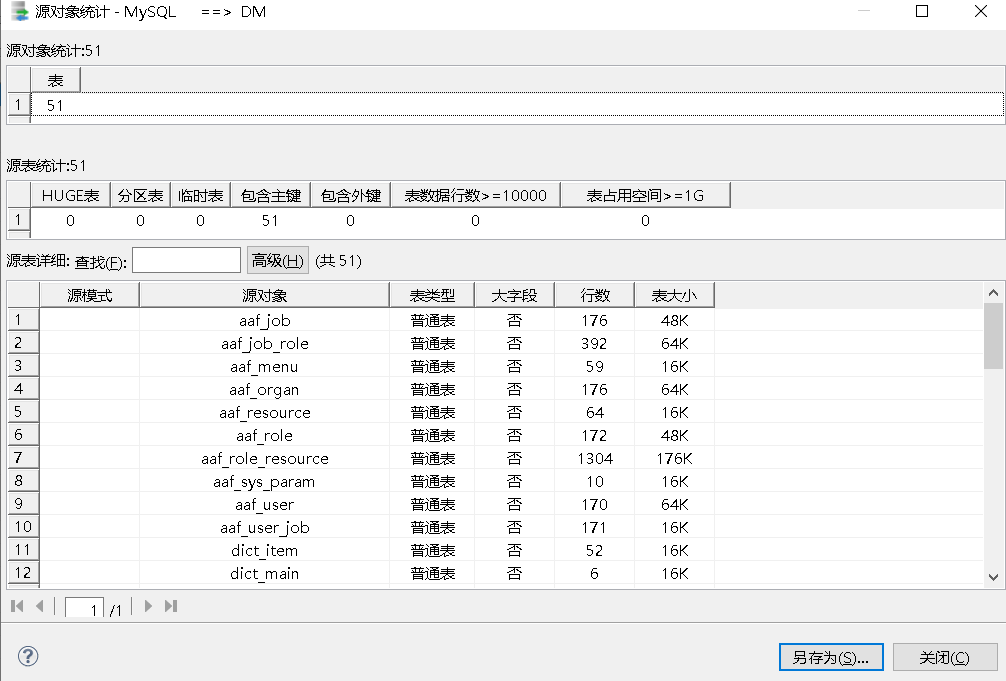
自定义对象迁移策略
待迁移具体对象勾选完毕后可以通过点击转换进行自定义对象迁移策略。
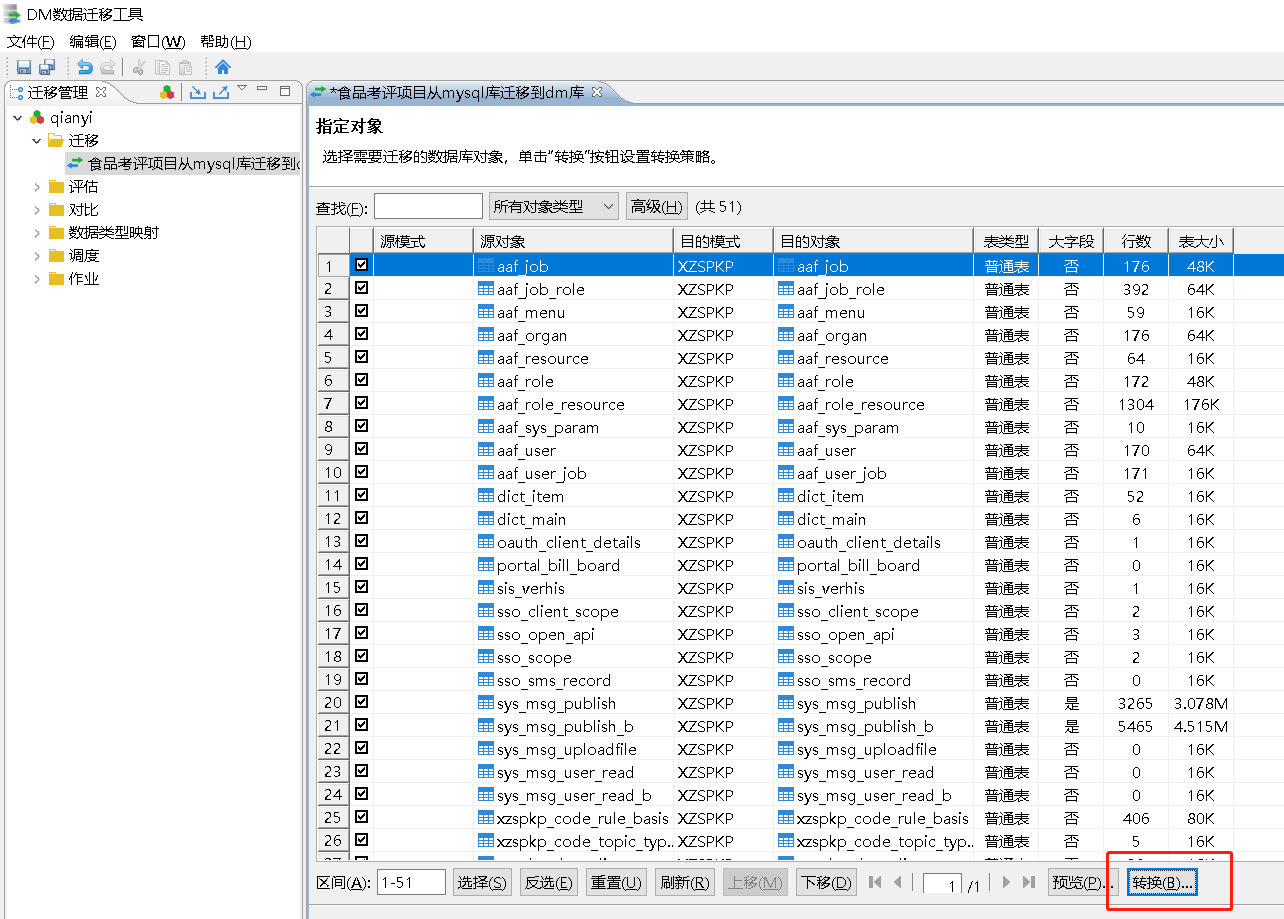
- 自定义对象迁移策略。点击转换后可以设置表的映射关系,包括迁移策略和列映射选项。
(1)迁移策略
在迁移策略中可根据需要设置表及数据迁移的策略。在左侧选项中可以选择“表定义”、“主键”、“约束”、“索引”等的迁移策略;在右侧选项中可以配置与迁移数据相关的策略。
完成映射关系的配置后,需要勾选“应用当前选择项到其他同类对象”,选择该选项后,将弹出对话框,选择其他同类对象,将此策略应用到相同对象上。如果不勾选“应用当前选择项到其他同类对象”,那么配置的迁移策略只会对当前选中的表生效。
本文档不涉及。
开始迁移
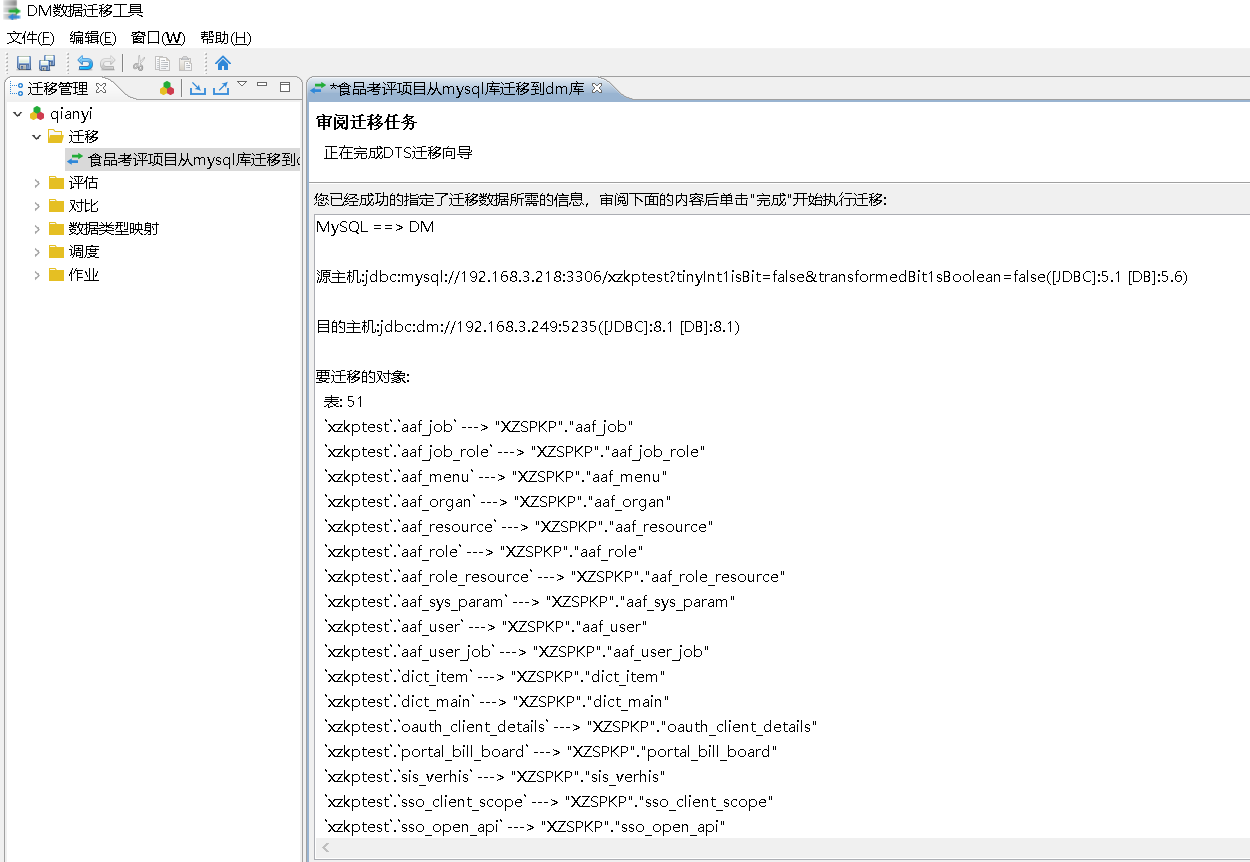
检查迁移任务
检查迁移任务,确认迁移对象是否正确。检查确认后点击“完成”即可开始迁移。
查看迁移进度
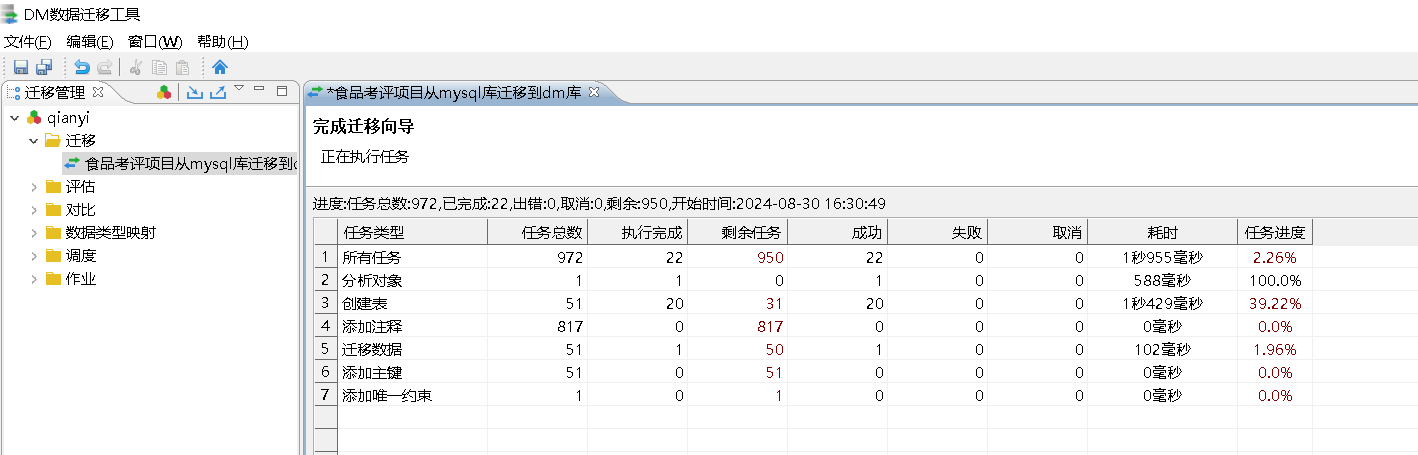
迁移完成