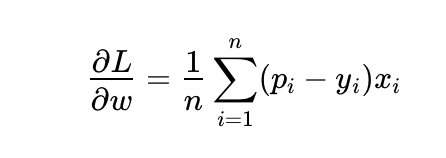Datawhale X 李宏毅苹果书 AI夏令营|机器学习基础之案例学习
机器学习(Machine Learning, ML):机器具有学习的能力,即让机器具备找一个函数的能力
函数不同,机器学习的类别不同:
回归(regression):找到的函数的输出是一个数值或标量(scalar)。例如:机器学习预测某一个时间段内的PM2.5,机器要找到一个函数f,输入是跟PM2.5有关的的指数,输出是明天中午的P M2.5的值。
分类(classification):让机器做选择题,先准备一些选项(类别class),机器要找到的的函数会从设定好的选项里边选择一个当作输出。例如:在邮箱账户里设置垃圾邮件检测规则,这套规则就可以看作输出邮件是否为垃圾邮件的函数
除了回归和分类还有结构化学习(structured learning),机器不仅要做选择题或者输出一个数字,还要产生一个有结构的结果,比如一张图或者一篇文章等。让机器产生有结构的结果的学习过程称为结构化学习。
机器学习的3个过程:
Step1: 写出带有未知参数(parameter)的函数,这个函数称为模型(model)。模型在机器学习中就是一个带有未知参数的函数,特征(feature)是这个函数里边已知的信息,w为权重,b为偏置。
Step2: 定义损失(loss),损失也是一个函数,记为L(b, w) 用于评判模型的参数是否合适。
真实值称为标签(Label)
估测值跟真实值之间的差距
计算二者差的绝对值称为平均绝对误差(Mean Absolute Error, MAE) e=|ŷ-y|
计算二者差的平方称为均方误差(Mean Squared Error, MSE)e=(ŷ-y)2
其中的y和ŷ都是概率分布,这个时候可能会选择计算交叉熵(cross entropy)
Step3: 解一个优化问题,即找到最好的一对(w, b),使损失L的值最小,用(w*, b*),代表最好的一对(w, b)
线性回归:
- 损失函数:均方误差(Mean Squared Error,MSE)
- L关于w的方程:
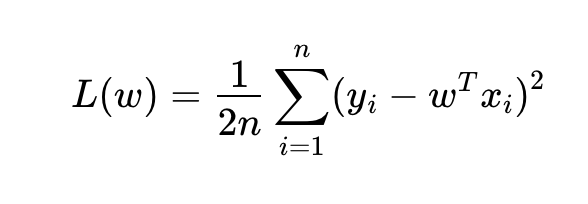
- L关于w的偏导数:
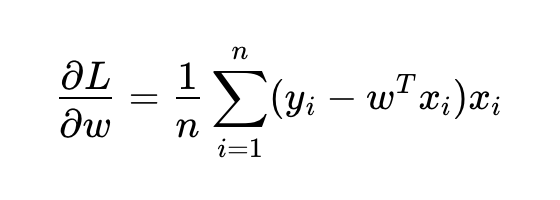
逻辑回归:
- 损失函数:交叉熵损失(Cross-Entropy Loss)
- L关于w的方程:
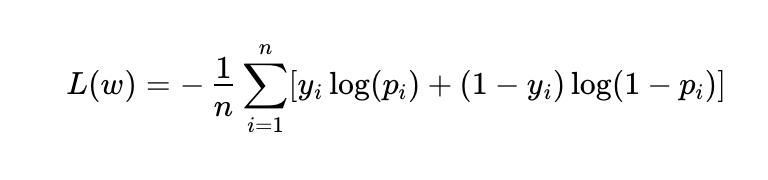
- L关于w的偏导数