Apache SeaTunnel Zeta 引擎源码解析(一)Server端的初始化
引入
本系列文章是基于 Apache SeaTunnel 2.3.6版本,围绕Zeta引擎给大家介绍其任务是如何从提交到运行的全流程,希望通过这篇文档,对刚刚上手SeaTunnel的朋友提供一些帮助。

我们整体的文章将会分成三篇,从以下方向给大家介绍:
- SeaTunnel Server端的初始化
- Client端的任务提交流程
- Server端的接收到任务的执行流程
由于涉及源码解析,涉及篇幅较大,所以分成系列文章来记录下一个任务的整体流程。
参考
- [ST-Engine][Design] The Design of LogicalPlan to PhysicalPlan:https://github.com/apache/seatunnel/issues/2269
作者介绍
大家好,我是刘乃杰,一名大数据开发工程师,参与Apache SeaTunnel的开发也有一年多的时间了,不仅给SeaTunnel提交了一些PR,而且添加的一些功能也非常有意思,欢迎大家来找我交流,其中包括支持Avro格式文件,SQL Transform中支持嵌套结构查询,给节点添加Tag达到资源隔离等。
近期推送SeaTunnel在公司内部的落地,需要跟同事,老板介绍SeaTunnel的技术架构,也需要详细的运行流程,帮助同事更好的上手开发,维护。
但是发现目前好像没有这样的一篇文章,能从整体来分析一个任务的执行流程,从而帮助开发者更加容易的定位问题,添加功能。
所以花了一些时间来写了这篇文章,希望抛砖引玉让其他的大佬们也多多写一些源码解析的文章出来。
集群拓扑
首先请大家先从整体了解下SeaTunnel的Zeta引擎架构, SeaTunnel是基于hazelcast来实现的分布式集群通信。
在2.3.6版本之后, 集群中的节点可以被分配为Master或Worker节点,从而将调度与执行分开,避免Master节点的负载过高从而出现问题。
并且2.3.6版本还添加了一个功能,可以对每个节点添加tag属性,当提交任务时可以通过tag来选择任务将要运行的节点, 从而达到资源隔离的目的。
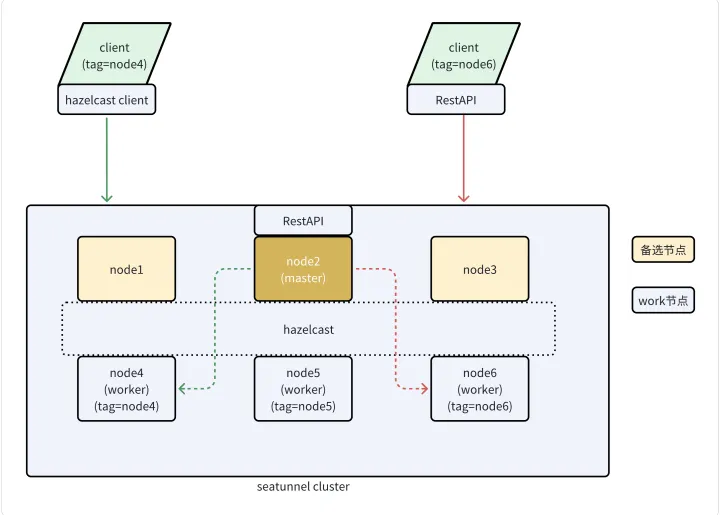
集群的服务端分为Master或Worker节点, Master节点负责接收请求、逻辑计划生成、分配任务等(与之前的版本相比,会多了几个Backup节点,但是对于集群稳定性来说是一个挺大的提升)。
而Worker节点则只负责执行任务, 也就是数据的读取和写入。
提交任务时可以创建Hazelcast的客户端连接集群来进行通信,或者使用Restapi来进行通信。
服务端启动
当我们对集群的整体架构有个大致的了解后,再来具体了解下具体的流程。
首先看下Server端的启动过程。
Server端的启动命令为:
sh bin/seatunnel-cluster.sh -d -r <node role type>查看这个脚本的内容后就会发现, 这个脚本最终的执行命令为:
java -cp seatunnel-starter.jar org.apache.seatunnel.core.starter.seatunnel.SeaTunnelServer <other_java_jvm_config_and_args>我们查看这个starter.seatunnel.SeaTunnelServer的代码
public class SeaTunnelServer {
public static void main(String[] args) throws CommandException {
ServerCommandArgs serverCommandArgs =
CommandLineUtils.parse(
args,
new ServerCommandArgs(),
EngineType.SEATUNNEL.getStarterShellName(),
true);
SeaTunnel.run(serverCommandArgs.buildCommand());
}
}这个代码是使用了JCommander来解析用户传递的参数并构建并运行Command, serverCommandArgs.buildCommand返回的类为:
public class ServerExecuteCommand implements Command<ServerCommandArgs> {
private final ServerCommandArgs serverCommandArgs;
public ServerExecuteCommand(ServerCommandArgs serverCommandArgs) {
this.serverCommandArgs = serverCommandArgs;
}
@Override
public void execute() {
SeaTunnelConfig seaTunnelConfig = ConfigProvider.locateAndGetSeaTunnelConfig();
String clusterRole = this.serverCommandArgs.getClusterRole();
if (StringUtils.isNotBlank(clusterRole)) {
if (EngineConfig.ClusterRole.MASTER.toString().equalsIgnoreCase(clusterRole)) {
seaTunnelConfig.getEngineConfig().setClusterRole(EngineConfig.ClusterRole.MASTER);
} else if (EngineConfig.ClusterRole.WORKER.toString().equalsIgnoreCase(clusterRole)) {
seaTunnelConfig.getEngineConfig().setClusterRole(EngineConfig.ClusterRole.WORKER);
// in hazelcast lite node will not store IMap data.
seaTunnelConfig.getHazelcastConfig().setLiteMember(true);
} else {
throw new SeaTunnelEngineException("Not supported cluster role: " + clusterRole);
}
} else {
seaTunnelConfig
.getEngineConfig()
.setClusterRole(EngineConfig.ClusterRole.MASTER_AND_WORKER);
}
HazelcastInstanceFactory.newHazelcastInstance(
seaTunnelConfig.getHazelcastConfig(),
Thread.currentThread().getName(),
new SeaTunnelNodeContext(seaTunnelConfig));
}
}在这里会根据配置的角色类型来修改配置信息。
当是Worker节点时,将Hazelcast节点的类型设置为lite member,在Hazelcast中lite member是不进行数据存储的
然后会创建了一个hazelcast实例, 并且传递了SeaTunnelNodeContext实例以及读取并修改的配置信息
public class SeaTunnelNodeContext extends DefaultNodeContext {
private final SeaTunnelConfig seaTunnelConfig;
public SeaTunnelNodeContext(@NonNull SeaTunnelConfig seaTunnelConfig) {
this.seaTunnelConfig = seaTunnelConfig;
}
@Override
public NodeExtension createNodeExtension(@NonNull Node node) {
return new org.apache.seatunnel.engine.server.NodeExtension(node, seaTunnelConfig);
}
@Override
public Joiner createJoiner(Node node) {
JoinConfig join =
getActiveMemberNetworkConfig(seaTunnelConfig.getHazelcastConfig()).getJoin();
join.verify();
if (node.shouldUseMulticastJoiner(join) && node.multicastService != null) {
super.createJoiner(node);
} else if (join.getTcpIpConfig().isEnabled()) {
log.info("Using LiteNodeDropOutTcpIpJoiner TCP/IP discovery");
return new LiteNodeDropOutTcpIpJoiner(node);
} else if (node.getProperties().getBoolean(DISCOVERY_SPI_ENABLED)
|| isAnyAliasedConfigEnabled(join)
|| join.isAutoDetectionEnabled()) {
super.createJoiner(node);
}
return null;
}
private static boolean isAnyAliasedConfigEnabled(JoinConfig join) {
return !AliasedDiscoveryConfigUtils.createDiscoveryStrategyConfigs(join).isEmpty();
}
private boolean usePublicAddress(JoinConfig join, Node node) {
return node.getProperties().getBoolean(DISCOVERY_SPI_PUBLIC_IP_ENABLED)
|| allUsePublicAddress(
AliasedDiscoveryConfigUtils.aliasedDiscoveryConfigsFrom(join));
}
}在SeaTunnelNodeContext中覆盖了createNodeExtension方法, 将使用engine.server.NodeExtension类,
这个类的代码为:
public class NodeExtension extends DefaultNodeExtension {
private final NodeExtensionCommon extCommon;
public NodeExtension(@NonNull Node node, @NonNull SeaTunnelConfig seaTunnelConfig) {
super(node);
extCommon = new NodeExtensionCommon(node, new SeaTunnelServer(seaTunnelConfig));
}
@Override
public void beforeStart() {
// TODO Get Config from Node here
super.beforeStart();
}
@Override
public void afterStart() {
super.afterStart();
extCommon.afterStart();
}
@Override
public void beforeClusterStateChange(
ClusterState currState, ClusterState requestedState, boolean isTransient) {
super.beforeClusterStateChange(currState, requestedState, isTransient);
extCommon.beforeClusterStateChange(requestedState);
}
@Override
public void onClusterStateChange(ClusterState newState, boolean isTransient) {
super.onClusterStateChange(newState, isTransient);
extCommon.onClusterStateChange(newState);
}
@Override
public Map<String, Object> createExtensionServices() {
return extCommon.createExtensionServices();
}
@Override
public TextCommandService createTextCommandService() {
return new TextCommandServiceImpl(node) {
{
register(HTTP_GET, new Log4j2HttpGetCommandProcessor(this));
register(HTTP_POST, new Log4j2HttpPostCommandProcessor(this));
register(HTTP_GET, new RestHttpGetCommandProcessor(this));
register(HTTP_POST, new RestHttpPostCommandProcessor(this));
}
};
}
@Override
public void printNodeInfo() {
extCommon.printNodeInfo(systemLogger);
}
}在这个代码中, 我们可以看到在构造方法中, 初始化了SeaTunnelServer这个类, 而这个类与最开始的类是同名的,
是在不同的包下, 这个类的完整类名为: org.apache.seatunnel.engine.server.SeaTunnelServer
我们看下这个类的代码:
public class SeaTunnelServer
implements ManagedService, MembershipAwareService, LiveOperationsTracker {
private static final ILogger LOGGER = Logger.getLogger(SeaTunnelServer.class);
public static final String SERVICE_NAME = "st:impl:seaTunnelServer";
private NodeEngineImpl nodeEngine;
private final LiveOperationRegistry liveOperationRegistry;
private volatile SlotService slotService;
private TaskExecutionService taskExecutionService;
private ClassLoaderService classLoaderService;
private CoordinatorService coordinatorService;
private ScheduledExecutorService monitorService;
@Getter private SeaTunnelHealthMonitor seaTunnelHealthMonitor;
private final SeaTunnelConfig seaTunnelConfig;
private volatile boolean isRunning = true;
public SeaTunnelServer(@NonNull SeaTunnelConfig seaTunnelConfig) {
this.liveOperationRegistry = new LiveOperationRegistry();
this.seaTunnelConfig = seaTunnelConfig;
LOGGER.info("SeaTunnel server start...");
}
@Override
public void init(NodeEngine engine, Properties hzProperties) {
...
if (EngineConfig.ClusterRole.MASTER_AND_WORKER.ordinal()
== seaTunnelConfig.getEngineConfig().getClusterRole().ordinal()) {
startWorker();
startMaster();
} else if (EngineConfig.ClusterRole.WORKER.ordinal()
== seaTunnelConfig.getEngineConfig().getClusterRole().ordinal()) {
startWorker();
} else {
startMaster();
}
...
}
....
}这个类是SeaTunnel Server端的核心代码, 在这个类中会根据节点的角色来启动相关的组件。
稍微总结下seatunnel的流程:
SeaTunnel是借助于Hazelcast的基础能力,来实现集群端的组网, 并调用启动核心的代码。
对于这一块有想深入了解的朋友可以去看下Hazelcast的相关内容,这里仅仅列出了调用路径。
按照顺序所加载调用的类为
- starter.SeaTunnelServer
- ServerExecutreCommand
- SeaTunnelNodeContext
- NodeExtension
- server.SeaTunnelServer
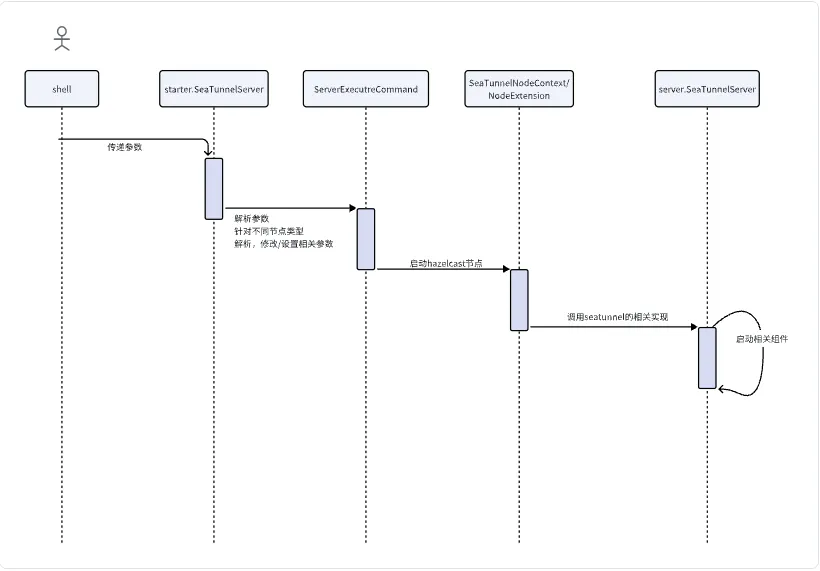
接下来再来详细看下Master节点以及Worker节点中所创建的组件
Worker节点
private void startWorker() {
taskExecutionService =
new TaskExecutionService(
classLoaderService, nodeEngine, nodeEngine.getProperties());
nodeEngine.getMetricsRegistry().registerDynamicMetricsProvider(taskExecutionService);
taskExecutionService.start();
getSlotService();
}
public SlotService getSlotService() {
if (slotService == null) {
synchronized (this) {
if (slotService == null) {
SlotService service =
new DefaultSlotService(
nodeEngine,
taskExecutionService,
seaTunnelConfig.getEngineConfig().getSlotServiceConfig());
service.init();
slotService = service;
}
}
}
return slotService;
}我们可以看到在startWorker方法中, 会初始化两个组件, taskExectutionService和slotService 这两个组件, 都与任务执行相关。
SlotService
先来看下SlotService的初始化
@Override
public void init() {
initStatus = true;
slotServiceSequence = UUID.randomUUID().toString();
contexts = new ConcurrentHashMap<>();
assignedSlots = new ConcurrentHashMap<>();
unassignedSlots = new ConcurrentHashMap<>();
unassignedResource = new AtomicReference<>(new ResourceProfile());
assignedResource = new AtomicReference<>(new ResourceProfile());
scheduledExecutorService =
Executors.newSingleThreadScheduledExecutor(
r ->
new Thread(
r,
String.format(
"hz.%s.seaTunnel.slotService.thread",
nodeEngine.getHazelcastInstance().getName())));
if (!config.isDynamicSlot()) {
initFixedSlots();
}
unassignedResource.set(getNodeResource());
scheduledExecutorService.scheduleAtFixedRate(
() -> {
try {
LOGGER.fine(
"start send heartbeat to resource manager, this address: "
+ nodeEngine.getClusterService().getThisAddress());
sendToMaster(new WorkerHeartbeatOperation(getWorkerProfile())).join();
} catch (Exception e) {
LOGGER.warning(
"failed send heartbeat to resource manager, will retry later. this address: "
+ nodeEngine.getClusterService().getThisAddress());
}
},
0,
DEFAULT_HEARTBEAT_TIMEOUT,
TimeUnit.MILLISECONDS);
}在SeaTunnel中会有一个动态Slot的概念,如果设置为true, 则每个节点就没有Slot的这样一个概念,可以提交任意数量的任务到此节点上,如果设置为固定数量的Slot, 那么该节点仅能接受这些Slot数量的Task运行。
在初始化时,会根据是否为动态Slot来进行数量的初始化。
private void initFixedSlots() {
long maxMemory = Runtime.getRuntime().maxMemory();
for (int i = 0; i < config.getSlotNum(); i++) {
unassignedSlots.put(
i,
new SlotProfile(
nodeEngine.getThisAddress(),
i,
new ResourceProfile(
CPU.of(0), Memory.of(maxMemory / config.getSlotNum())),
slotServiceSequence));
}
}同时也可以看到初始化时会启动一个线程,定时向Master节点发送心跳,心跳信息中则包含了当前节点的信息, 包括已经分配的、未分配的Slot数量等属性,Worker节点通过心跳将信息定时更新给Master。
@Override
public synchronized WorkerProfile getWorkerProfile() {
WorkerProfile workerProfile = new WorkerProfile(nodeEngine.getThisAddress());
workerProfile.setProfile(getNodeResource());
workerProfile.setAssignedSlots(assignedSlots.values().toArray(new SlotProfile[0]));
workerProfile.setUnassignedSlots(unassignedSlots.values().toArray(new SlotProfile[0]));
workerProfile.setUnassignedResource(unassignedResource.get());
workerProfile.setAttributes(nodeEngine.getLocalMember().getAttributes());
workerProfile.setDynamicSlot(config.isDynamicSlot());
return workerProfile;
}
private ResourceProfile getNodeResource() {
return new ResourceProfile(CPU.of(0), Memory.of(Runtime.getRuntime().maxMemory()));
}TaskExecutionService
这个组件与任务提交相关, 这里先简单看下,与任务提交的相关代码在后续再深入查看。
在Worker节点初始化时, 会新建一个TaskExecutionService对象,并调用其start方法
private final ExecutorService executorService =
newCachedThreadPool(new BlockingTaskThreadFactory());
public TaskExecutionService(
ClassLoaderService classLoaderService,
NodeEngineImpl nodeEngine,
HazelcastProperties properties) {
// 加载配置信息
seaTunnelConfig = ConfigProvider.locateAndGetSeaTunnelConfig();
this.hzInstanceName = nodeEngine.getHazelcastInstance().getName();
this.nodeEngine = nodeEngine;
this.classLoaderService = classLoaderService;
this.logger = nodeEngine.getLoggingService().getLogger(TaskExecutionService.class);
// 指标相关
MetricsRegistry registry = nodeEngine.getMetricsRegistry();
MetricDescriptor descriptor =
registry.newMetricDescriptor()
.withTag(MetricTags.SERVICE, this.getClass().getSimpleName());
registry.registerStaticMetrics(descriptor, this);
// 定时任务更新指标到IMAP中
scheduledExecutorService = Executors.newSingleThreadScheduledExecutor();
scheduledExecutorService.scheduleAtFixedRate(
this::updateMetricsContextInImap,
0,
seaTunnelConfig.getEngineConfig().getJobMetricsBackupInterval(),
TimeUnit.SECONDS);
serverConnectorPackageClient =
new ServerConnectorPackageClient(nodeEngine, seaTunnelConfig);
eventBuffer = new ArrayBlockingQueue<>(2048);
// 事件转发服务
eventForwardService =
Executors.newSingleThreadExecutor(
new ThreadFactoryBuilder().setNameFormat("event-forwarder-%d").build());
eventForwardService.submit(
() -> {
List<Event> events = new ArrayList<>();
RetryUtils.RetryMaterial retryMaterial =
new RetryUtils.RetryMaterial(2, true, e -> true);
while (!Thread.currentThread().isInterrupted()) {
try {
events.clear();
Event first = eventBuffer.take();
events.add(first);
eventBuffer.drainTo(events, 500);
JobEventReportOperation operation = new JobEventReportOperation(events);
RetryUtils.retryWithException(
() ->
NodeEngineUtil.sendOperationToMasterNode(
nodeEngine, operation)
.join(),
retryMaterial);
logger.fine("Event forward success, events " + events.size());
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
logger.info("Event forward thread interrupted");
} catch (Throwable t) {
logger.warning(
"Event forward failed, discard events " + events.size(), t);
}
}
});
}
public void start() {
runBusWorkSupplier.runNewBusWork(false);
}在这个类中,有一个成员变量,创建了一个线程池。
在构造方法中创建了一个定时任务来更新IMAP里面的任务状态。创建了一个任务来将Event信息发送给Master节点,由Master节点将这些Event发送给外部服务。
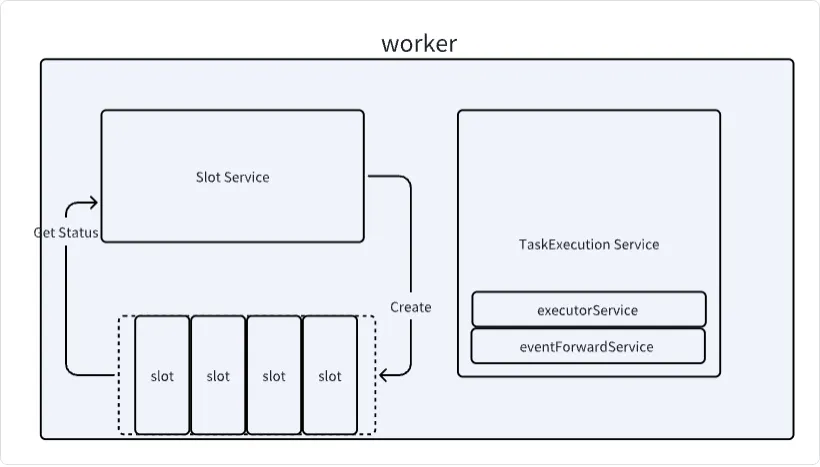
Master节点
private void startMaster() {
coordinatorService =
new CoordinatorService(nodeEngine, this, seaTunnelConfig.getEngineConfig());
monitorService = Executors.newSingleThreadScheduledExecutor();
monitorService.scheduleAtFixedRate(
this::printExecutionInfo,
0,
seaTunnelConfig.getEngineConfig().getPrintExecutionInfoInterval(),
TimeUnit.SECONDS);
}我们可以看到在Master节点中,启动了两个组件:协调器组件和监控组件。
监控组件的任务比较简单, 就是周期性的打印集群信息。
CoordinatorService
public CoordinatorService(
@NonNull NodeEngineImpl nodeEngine,
@NonNull SeaTunnelServer seaTunnelServer,
EngineConfig engineConfig) {
this.nodeEngine = nodeEngine;
this.logger = nodeEngine.getLogger(getClass());
this.executorService =
Executors.newCachedThreadPool(
new ThreadFactoryBuilder()
.setNameFormat("seatunnel-coordinator-service-%d")
.build());
this.seaTunnelServer = seaTunnelServer;
this.engineConfig = engineConfig;
masterActiveListener = Executors.newSingleThreadScheduledExecutor();
masterActiveListener.scheduleAtFixedRate(
this::checkNewActiveMaster, 0, 100, TimeUnit.MILLISECONDS);
}
private void checkNewActiveMaster() {
try {
if (!isActive && this.seaTunnelServer.isMasterNode()) {
logger.info(
"This node become a new active master node, begin init coordinator service");
if (this.executorService.isShutdown()) {
this.executorService =
Executors.newCachedThreadPool(
new ThreadFactoryBuilder()
.setNameFormat("seatunnel-coordinator-service-%d")
.build());
}
initCoordinatorService();
isActive = true;
} else if (isActive && !this.seaTunnelServer.isMasterNode()) {
isActive = false;
logger.info(
"This node become leave active master node, begin clear coordinator service");
clearCoordinatorService();
}
} catch (Exception e) {
isActive = false;
logger.severe(ExceptionUtils.getMessage(e));
throw new SeaTunnelEngineException("check new active master error, stop loop", e);
}
}在初始化时, 会启动一个线程来定时检查当前阶段是否为Master节点, 当节点当前不是Master节点但在集群中成为Master节点时, 会调用initCoordinatorService()来进行状态的初始化, 并将状态修改为True。
当节点自身标记为Master节点,但在集群中已不再是Master节点时,进行状态清理。
private void initCoordinatorService() {
// 从hazelcast中获取分布式IMAP
runningJobInfoIMap =
nodeEngine.getHazelcastInstance().getMap(Constant.IMAP_RUNNING_JOB_INFO);
runningJobStateIMap =
nodeEngine.getHazelcastInstance().getMap(Constant.IMAP_RUNNING_JOB_STATE);
runningJobStateTimestampsIMap =
nodeEngine.getHazelcastInstance().getMap(Constant.IMAP_STATE_TIMESTAMPS);
ownedSlotProfilesIMap =
nodeEngine.getHazelcastInstance().getMap(Constant.IMAP_OWNED_SLOT_PROFILES);
metricsImap = nodeEngine.getHazelcastInstance().getMap(Constant.IMAP_RUNNING_JOB_METRICS);
// 初始化JobHistoryService
jobHistoryService =
new JobHistoryService(
runningJobStateIMap,
logger,
runningJobMasterMap,
nodeEngine.getHazelcastInstance().getMap(Constant.IMAP_FINISHED_JOB_STATE),
nodeEngine
.getHazelcastInstance()
.getMap(Constant.IMAP_FINISHED_JOB_METRICS),
nodeEngine
.getHazelcastInstance()
.getMap(Constant.IMAP_FINISHED_JOB_VERTEX_INFO),
engineConfig.getHistoryJobExpireMinutes());
// 初始化EventProcess, 用于发送事件到其他服务
eventProcessor =
createJobEventProcessor(
engineConfig.getEventReportHttpApi(),
engineConfig.getEventReportHttpHeaders(),
nodeEngine);
// If the user has configured the connector package service, create it on the master node.
ConnectorJarStorageConfig connectorJarStorageConfig =
engineConfig.getConnectorJarStorageConfig();
if (connectorJarStorageConfig.getEnable()) {
connectorPackageService = new ConnectorPackageService(seaTunnelServer);
}
// 集群恢复后, 尝试恢复之前的历史任务
restoreAllJobFromMasterNodeSwitchFuture =
new PassiveCompletableFuture(
CompletableFuture.runAsync(
this::restoreAllRunningJobFromMasterNodeSwitch, executorService));
}在Coordinatorservice中,会拉取分布式MAP,这个数据结构是Hazelcast的一个数据结构,可以认为是在集群中数据一致的一个MAP。
在SeaTunnel中, 使用这个结构来存储任务信息、Slot信息等。
在这里还会创建EventProcessor, 这个类是用来将事件通知到其他服务,比如任务失败,可以发送信息到配置的接口中,实现事件推送。
最后,由于节点启动,可能是集群异常重启,或者节点切换,这时需要恢复历史运行的任务,那么就会从刚刚获取到的IMAP中获取到之前正在跑的任务列表,然后尝试进行恢复。
这里的IMAP信息可以开启持久化将信息存储到HDFS等文件系统中, 这样可以在系统完全重启后仍然能够读取到之前的任务状态并进行恢复。
在CoordinatorService中运行的组件有:
- executorService (所有可能被选举为master的节点)
- jobHistoryService (master节点)
- eventProcessor (master节点)
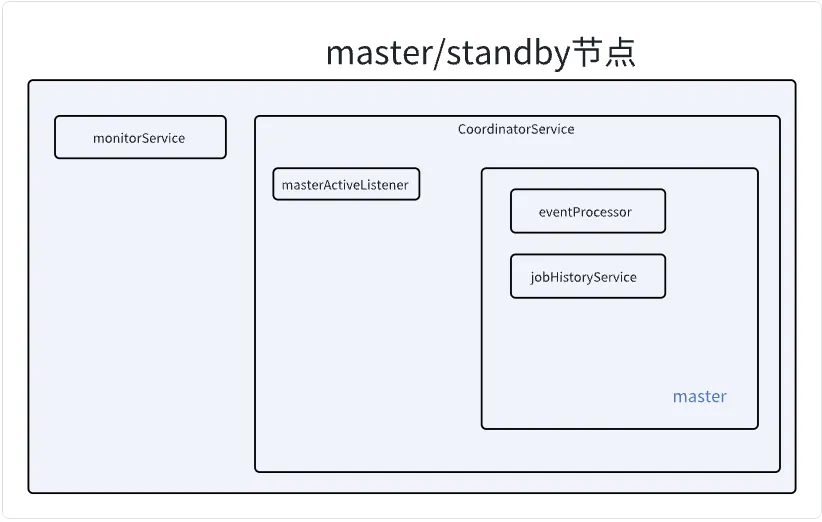
Master节点与备选节点上会:
- 定时检查自己是否为Master节点, 如果是则进行相应的状态转化
Master节点上会:
- 定时打印集群的状态信息。
- 启动转发服务, 将要推送的事件转发到外边服务
在Worker节点上, 启动后会:
- 定时将状态信息上报到Master节点
- 将任务信息更新到IMAP里面。
- 将在Worker产生的要推送给外部服务的事件转发到Master节点上。
至此, 服务端所有服务组件都已启动完成,本文完!
本文由 白鲸开源科技 提供发布支持!