【大数据分析与挖掘算法】matlab实现——改进的Apriori关联规则算法
实验二 :改进的Apriori关联规则算法
一、实验目的
改进Apriori关联规则算法,实现对大型数据库系统扫描时关联规则的快速提取,提高产生效率,降低时间复杂度。
二、实验任务
根据某超市的五条客户购物清单记录,使用改进的Apriori关联规则算法进行计算,实例如下:

三、实验过程

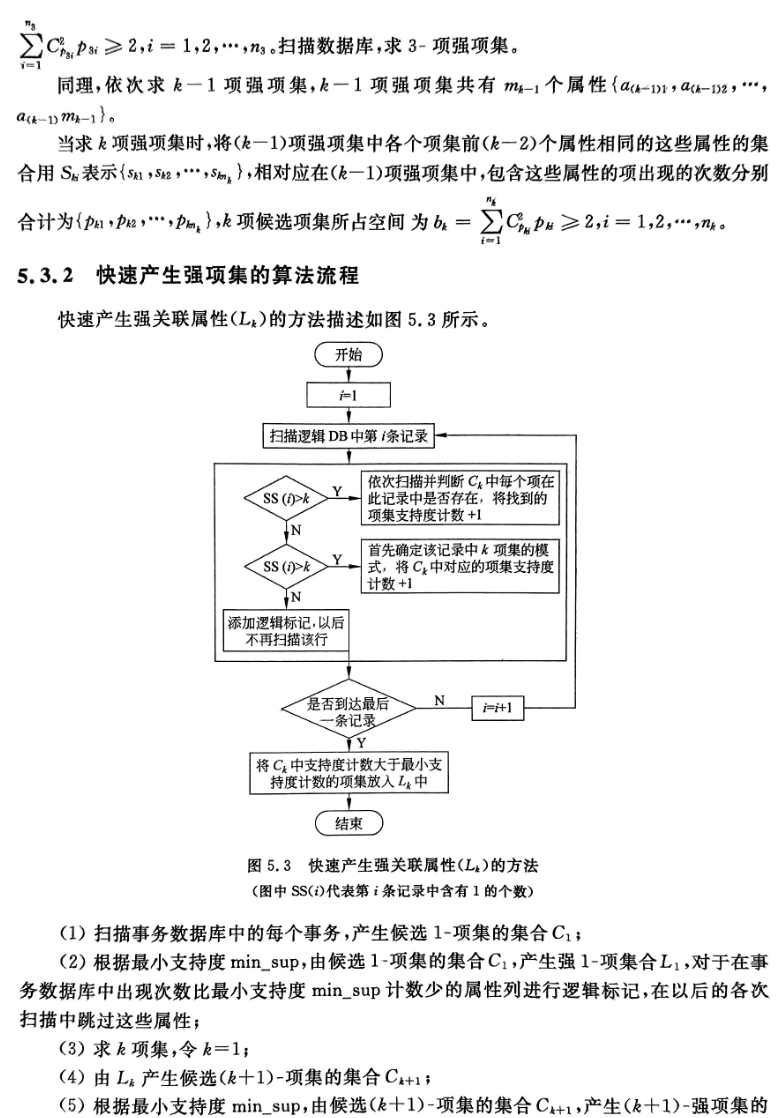


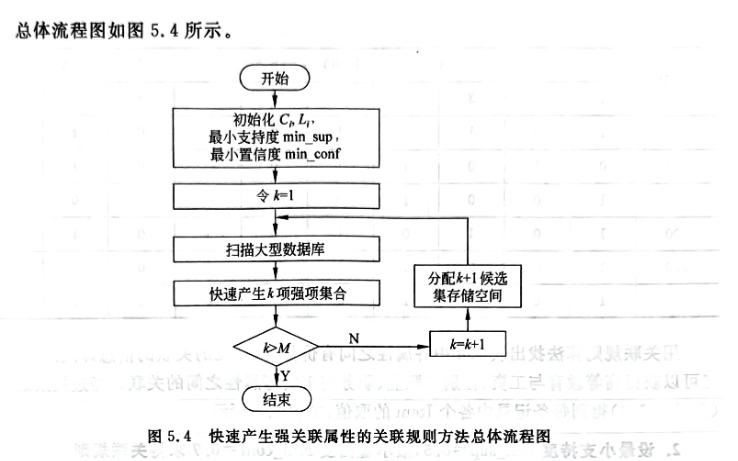
四、实验结果
实现平台:Matlab 2022A
实验代码:
function apriori_improved(goods, min_sup, min_conf)
% 初始化和参数设定
clear; clc; close all;
if nargin < 1
goods = {'C,J,B,O,S'; 'J,S'; 'C,M,S'; 'C,W,S'; 'C,B,M'};
min_sup = 0.4;
min_conf = 0.6;
end
% 计算事务数量
num_transactions = numel(goods);
% 获取所有唯一项
all_items = [];
for i = 1:num_transactions
items = strsplit(goods{i}, ',');
all_items = [all_items, items];
end
all_items = unique(all_items);
% 初始化支持度数据结构
support_data = struct();
% 计算1-项集支持度并生成强1-项集L1
L1 = [];
for i = 1:numel(all_items)
item = all_items{i};
support = calculate_support(item, goods);
if support >= min_sup
support_data.(item) = support;
L1 = [L1; {item, support}];
end
end
% 将不满足最小支持度的属性逻辑标记
candidate_items = fieldnames(support_data);
% 初始化频繁项集列表
frequent_itemsets = L1;
% 初始化候选集
Ck = L1(:, 1);
k = 1;
while true
% 生成k+1项候选集
Ck_plus_1 = generate_candidates(Ck, k);
% 计算k+1项集的支持度
Ck_plus_1_support = [];
for i = 1:numel(Ck_plus_1)
itemset = Ck_plus_1{i};
support = calculate_support(itemset, goods);
if support >= min_sup
Ck_plus_1_support = [Ck_plus_1_support; {itemset, support}];
end
end
% 更新频繁项集列表
if isempty(Ck_plus_1_support)
break;
end
frequent_itemsets = [frequent_itemsets; Ck_plus_1_support];
Ck = Ck_plus_1_support(:, 1);
k = k + 1;
end
% 计算关联规则的置信度和提升度
all_rules = generate_rules(frequent_itemsets, min_conf, goods);
% 输出最终频繁项集和关联规则
disp('Frequent Itemsets:');
disp(frequent_itemsets);
disp('Association Rules:');
disp(all_rules);
end
function support = calculate_support(itemset, transactions)
count = 0;
for j = 1:numel(transactions)
str_chars = strsplit(transactions{j}, ',');
substr_chars = strsplit(itemset, ',');
if all(ismember(substr_chars, str_chars))
count = count + 1;
end
end
support = count / numel(transactions);
end
function Ck_plus_1 = generate_candidates(Ck, k)
Ck_plus_1 = {};
for i = 1:numel(Ck)
for j = i+1:numel(Ck)
itemset1 = strsplit(Ck{i}, ',');
itemset2 = strsplit(Ck{j}, ',');
if all(strcmp(itemset1(1:k-1), itemset2(1:k-1)))
new_itemset = unique([itemset1, itemset2]);
new_itemset = strjoin(sort(new_itemset), ',');
if ~ismember(new_itemset, Ck_plus_1)
Ck_plus_1{end+1} = new_itemset;
end
end
end
end
end
function all_rules = generate_rules(frequent_itemsets, min_conf, transactions)
all_rules = {};
for i = 1:size(frequent_itemsets, 1)
itemset = frequent_itemsets{i, 1};
subsets = generate_subsets(itemset);
for j = 1:size(subsets, 1)
antecedent = subsets{j};
consequent = setdiff(strsplit(itemset, ','), strsplit(antecedent, ','));
if ~isempty(consequent)
confidence = calculate_support(itemset, transactions) / calculate_support(antecedent, transactions);
if confidence >= min_conf
all_rules{end+1, 1} = [antecedent, ' => ', strjoin(consequent, ',')];
all_rules{end, 2} = confidence;
end
end
end
end
end
function subsets = generate_subsets(itemset)
items = strsplit(itemset, ',');
n = numel(items);
subsets = {};
for i = 1:2^n-2
subset = items(logical(bitget(i, n:-1:1)));
subsets{end+1} = strjoin(subset, ',');
end
end
实验结果:

五、总结
1.对改进的Apriori关联规则算法的理解
算法改进的方式有很多,书上给出的这个示例主要是考虑到空间的充分利用,将直接扫描k项集改成k项集通过k-1项集来合成,从而方便快速地产生强项集,在产生过程中也要注意逻辑标记以跳过某些属性减少扫描次数,从而降低整体的时间复杂性。