Meta:大语言模型可以通过自我批判取得大幅提升!

夕小瑶科技说 原创
作者 | 谢年年
论文的审稿模式想必大家都不会陌生,一篇论文除了分配多个评审,最后还将由PC综合评估各位审稿人的reviews撰写meta-review。
最近,来自Meta的研究团队将这一模式引进到大模型的对齐训练中。模型同时扮演 执行者(actor)、评判者(judge)和元评判者(meta-judge) 三种角色。执行者生成回复,评判者评估生成回复的质量并打分,元评判者则检查评判者的质量,为评判者提供必要的训练反馈。
通过这种方式获得大量回复偏好对,无需人工标注数据,进一步训练对齐模型,显著提高了模型的判断和遵循指令的能力。
论文标题:
META-REWARDING LANGUAGE MODELS: Self-Improving Alignment with LLM-as-a-Meta-Judge
论文链接:
https://arxiv.org/pdf/2407.19594

方法
本文假设没有任何额外的人工监督数据,仅有一个初始的种子LLM。通过迭代自我对弈,模型同时扮演执行者(actor)、评判者(judge)和元评判者(meta-judge)三种角色。执行者生成回复,评判者评估生成的质量并打分,元评判者则比较评判者的质量,为其提供必要的训练反馈。
虽然最终的目标是训练执行者生成更优质的回复,但评判者评判是否准确也很重要。随着评判者能力的提升,执行者也能获得更好的反馈,从而不断进步。本文提出的 “元奖励机制(Meta-Rewarding)”旨在同时增强执行者和评判者的能力。迭代过程下图所示:
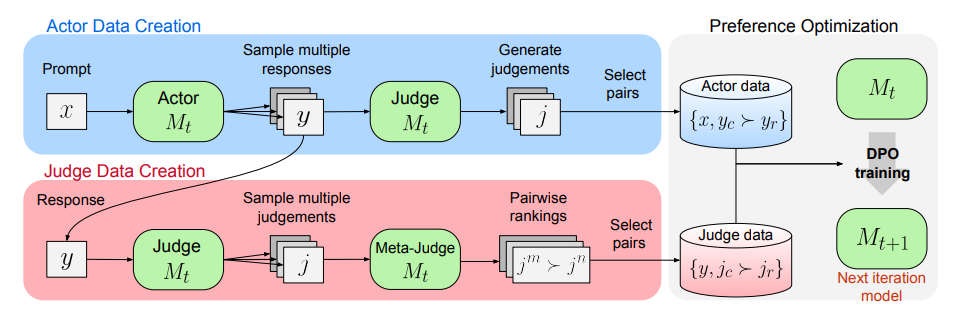
增强执行者和评判者的能力最重要的就是获取大量训练数据。因此每个迭代周期首先由执行者针对每个提示生成多个回复变体,评判者为每个回复打分,为训练执行者构建回复偏好对。
为了训练评判者构建评判偏好对,则选择一个回复,并让元评判者比较评判者针对该回复生成的两个评判变体,以确定哪个更好,这通过LLM作为元评判者的提示来实现,如下图所示:

一旦为执行者和评判者都收集了偏好数据,就通过DPO在数据集上进行偏好优化训练。
接下来详述每个部分数据集构建。
执行者偏好数据集创建
数据集创建过程主要包括三个步骤:
-
从执行者获取样本回复假设有一组给定的提示,对于每个提示,在迭代时,从当前模型中抽样生成个不同的回复。
-
聚合多个评判对于每个回复,使用“LLM作为评判者”的提示从中生成个不同的评判。

该提示指示模型根据固定评分标准对给定提示下的回复进行评价,并输出其推理过程和最终分数(满分5分)。丢弃无效的打分,计算所有有效评判分数的平均值,得到每个回复的最终奖励分数。
-
带长度控制的偏好数据选择
之前的工作简单地选择每个提示下得分最高和最低的回复作为被选回复和被拒绝回复,形成偏好对。然而,这会导致长度爆炸问题,即随着迭代次数增加,回复变得越来越长。
作者引入了一个简单的长度控制机制。通过定义了一个质量层级参数,以控制基于分数的选择和长度考虑之间的权衡。特别地,得分位于顶层范围内的回复被认为具有相似质量。在选择被选回复时,优先选择该顶层范围内最短的回复。这种方法有助于抵消评判者倾向于更长回复的倾向,从而避免训练数据出现偏差。相反,对于被拒绝回复,选择得分在范围内的最长回复。将设置为0将有效禁用长度控制,恢复为纯基于分数的选择。
评判者偏好数据集创建
作者设计了一个元评审,来对比评判者的好坏。整个过程分为三大步骤,旨在精准挑选出高质量的评审对,并有效减少位置偏差等影响因素。
-
响应选择
为了训练出更加敏锐的评审系统,专注于那些评审意见分歧最大的响应。通过计算每个响应在不同评审间评分的方差,筛选出评分方差最大的响应作为训练材料。
-
成对的元评审评估
对于每个选定的响应,有最多N个相应的评审,记作。然后利用LLM作为元评审,通过详细分析两个评审的判断,模型会生成思维链推理并给出胜负判断。
为消除位置偏差,变换评审顺序并引入位置加权评分机制,确保评估的公正性。此外,还引入了针对第一和第二位置的获胜加权评分。定义和分别为在第一和第二位置的总获胜次数,并计算权重为:
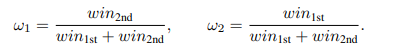
判断()之间单场战斗的结果定义为:

最终,这些评估结果汇总成一个战斗矩阵,反映评审间的相对实力。
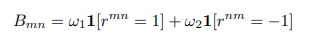
-
Elo评分和成对选择
借鉴Elo评分系统,作者将战斗矩阵转化为每个评审的元奖励。通过解决以下最大似然估计问题确定每个评审的Elo评分 :
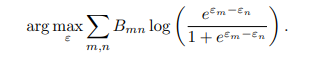
这种方法允许在元评判者评估中考虑位置偏差的分数,提供更准确的奖励信号,提高评审质量。在创建偏好对时,选择Elo评分最高和最低的评审输出作为通过和拒绝的评审输出。
在实践中,元评审可能偏好冗长的评审输出。为纠正这一偏差,作者增设了长度阈值过滤步骤,有效限制了过长输出的影响,实现了评审质量与简洁性的良好平衡。
实验
实验设置
本文使用经过指令微调的 Llama-3-8B-Instruct 作为种子模型。再对种子模型利用[1]提供的评估微调数据集进行监督微调得到初始评判者。
在Meta-Rewarding迭代中,同样以[1]提供的20000个提示作为种子集,每次迭代抽取5000个提示,总共进行四次迭代:
-
Iter 1 通过使用 DPO在SFT模型生成的执行和评审偏好数据对对上训练获得M1。
-
Iter 2 通过在M1生成的执行和评审偏好对上使用 DPO 训练 M1 来获得 M2。
-
Iter 3 通过仅在 M2 生成的执行偏好对上使用 DPO 训练 M2 来获得 M3。
-
Iter 4 通过仅在 M3 生成的执行偏好对上使用 DPO 训练 M3 来获得 M4。
评估与实验分析
由于Meta-Rewarding同时改善模型作为演员和评判者的表现,因此将测量两个方面。
执行者的指令遵循能力
作者采用了三个成熟的GPT4驱动自动评估基准从不同维度评估模型。AlpacaEval 2侧重于日常聊天场景,Arena-Hard则包含复杂与挑战性问题,MT-Bench评估多轮对话能力,覆盖8类问题。
-
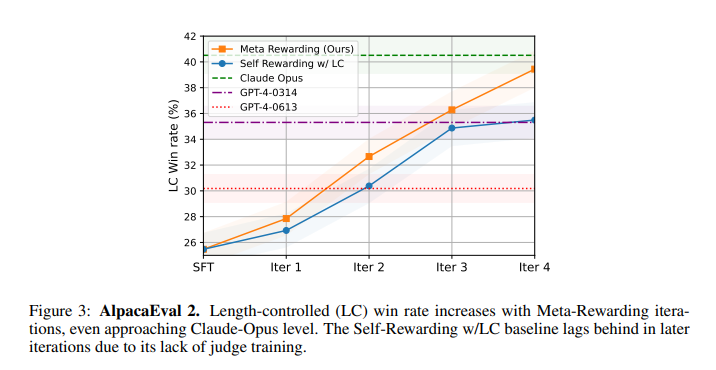
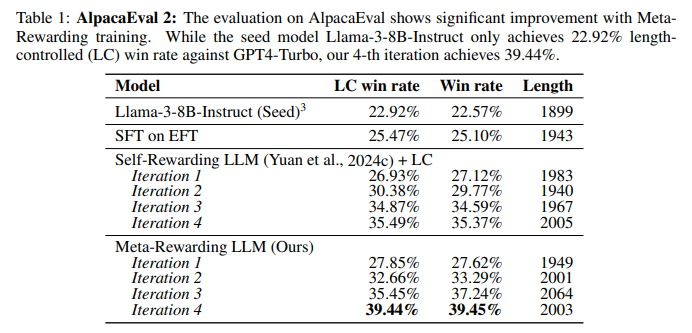
Meta-Rewarding迭代显著提升胜率。如下图所示,在AlpacaEval基准上,胜率从22.9%跃升至39.4%,超越GPT-4,逼近Claude Opus,且模型仅8B参数,未用额外人类数据,成效显著。同时,该方法优于使用强大外部奖励模型的强基线SPPO。
-
元评判者及长度控制机制对提升至关重要,在没有元评判者参与训练评判者的情况下,仅依赖自奖励基线与长度控制(LC)相结合,虽然能够带来一定程度的改进,但这种改进在训练的后期迭代中显得较为有限。如下表所示,随着训练迭代的进行,平均响应长度并未出现明显增长,这有力地证明了所采用的长度控制机制在控制输出长度方面的稳定性和有效性。
-
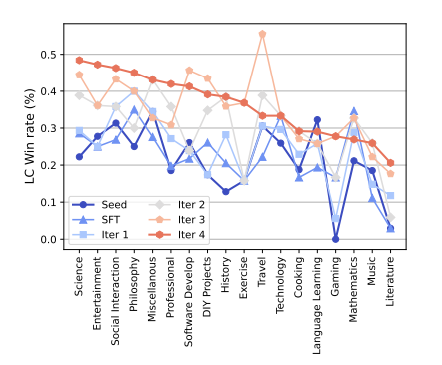
Meta-Rewarding几乎改进了所有指令类别,特别在知识密集型类别如科学、游戏、文学上表现突出(,但在旅行、数学等类别上改进较小。
-
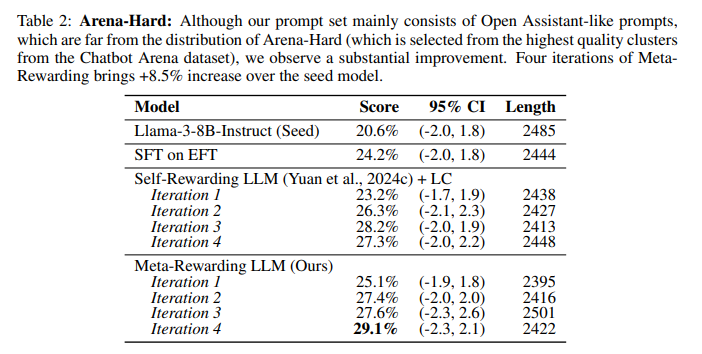
Meta-Rewarding 改进了复杂和困难问题的回答。 在应对复杂问题上,通过Arena-Hard评估,Meta-Rewarding持续提分,较种子模型提升显著(+8.5%)。
-
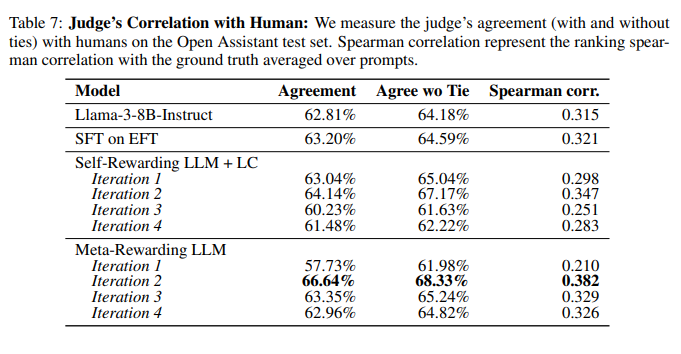
Meta-Rewarding 尽管仅在单轮数据上训练,但并未牺牲多轮能力。 Meta-Rewarding在MT-Bench评估中仍保持了多轮对话能力,最后一轮迭代中首轮得分提升,第二轮得分牺牲微小(<0.1),而以往的方法通常在第二轮得分上牺牲超过 0.2,而第一轮得分没有改善。
评判者的奖励建模能力
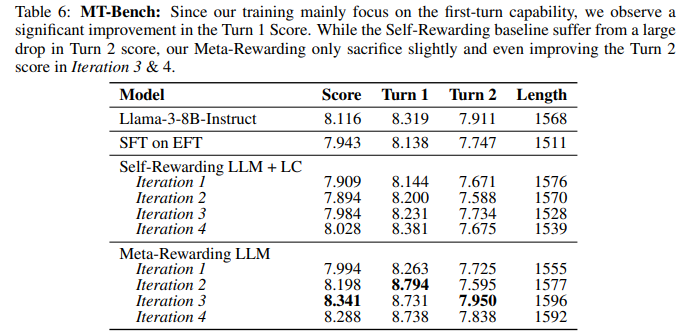
作者比较评判者的能力与人类评判和当前最强的判断模型 gpt-4-1106-preview 之间的相关性。还通过斯皮尔曼相关性分析,量化模型生成排名与Open Assistant数据集中的一致性。
模型经Meta-Rewarding训练后,判断能力显著提升。下表显示,与自奖励基线相比,在两种评估设置中,Meta-Rewarding与GPT-4判断的相关性均大幅增强,尤其是无平局一致性指标提升显著。自选对设置中,迭代2时改进高达+12.34%,而GPT-4选择对设置中也超过+6%。这证明了Meta-Rewarding在提升模型判断能力上的有效性,使其更接近GPT-4的评估水平。
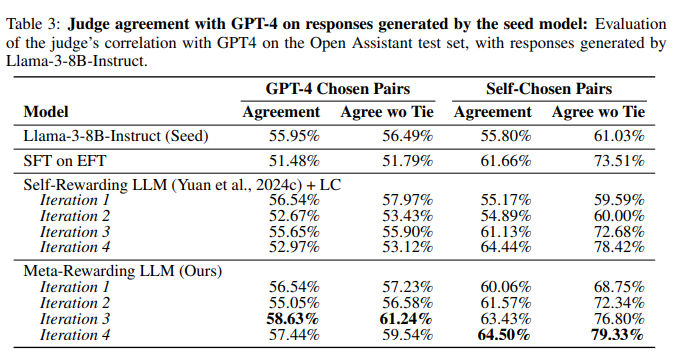
Meta-Rewarding 训练提高了与人类的判断相关性。 通过Open Assistant数据集验证,可以看到本文模型与人类排名的相关性显著增加。然而,随着训练深入,这一改进有所减缓,可能与响应分布变化有关。
结语
本文利用元评判者分配元奖励,优化模型判断偏好,克服自奖励框架的训练限制。同时,引入长度控制技术,解决训练中的长度问题。即使没有额外的人类反馈,该方法也显著改善了 Llama-3-8B-Instruct,并超越了依赖于人类反馈的强基线 Self-Rewarding 和SPPO 。并且该模型的判断能力与人类及强大AI评判者(如GPT-4)高度相关。也许随着科技发展,无需人类反馈的模型超对齐将可能实现。