深度学习系列69:tts技术原理
tts为text-to-speech,asr为Automatic Speech Recognition,即speech-to-text。
1. 常用基础模型
下面介绍的deep voice是端到端生成语音的模型,后面两个是生成Mel谱,然后再使用vocoder生成语音的模型。
1.1 Deep voice
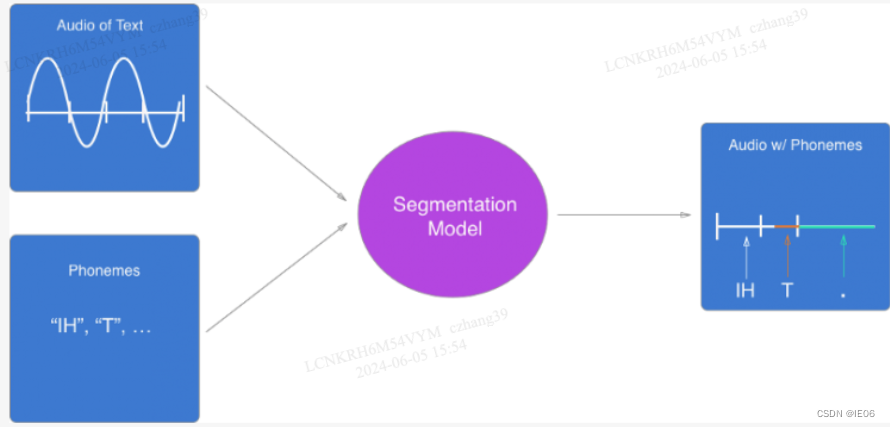
目前端到端的是主流,其整体流程如下图:

步骤1:语素转音素

用的比较多的是语素(phoneme)和字母(grapheme)。这里介绍语素为token的步骤:
· White Room - [ W,AY1, T, ., R, UW1, M,. ]
· Crossroads - [ K,R, AO1, S, R, OW2, D, Z, . ]
上述例子源自于CMU的音素字典,其中,音素旁边的1,2等数字表示应该发重音的位置,句号表示音间停顿。在大多数情况下,通过查询标准音素字典(比如CMU的音素字典),可以得到与输入文本一一对应的标签。
如果出现音素字典没有覆盖的词,Deep Voice使用神经网络来实现这个功能。准确来讲,它沿用过了Yao和Zweig在微软进行的Sequence to Sequence(Seq2Seq)的学习方法来进行文本对应的音素预测。
步骤2:预测每个音素的持续时间和基频
[IH1, T, ., W, AA1, Z, ., ER1, L, IY0, ., S, P, R, IH1, NG, .] -> [IH1 (140hz, 0.5s), T (142hz, 0.1s), . (Not voiced, 0.2s), W (140hz, 0.3s),…]
分割模型将每个音素发声的场景进行匹配,从而获取其对应的音频分割片段和其在音频中的发声位置。
对独立单个的音素而言,给定语音对应某个音素的概率在语音的发声正中最大;而对成对的音素而言,概率最大值出现在两个音素交界点上,因此分割模型的预测结果是因素对。
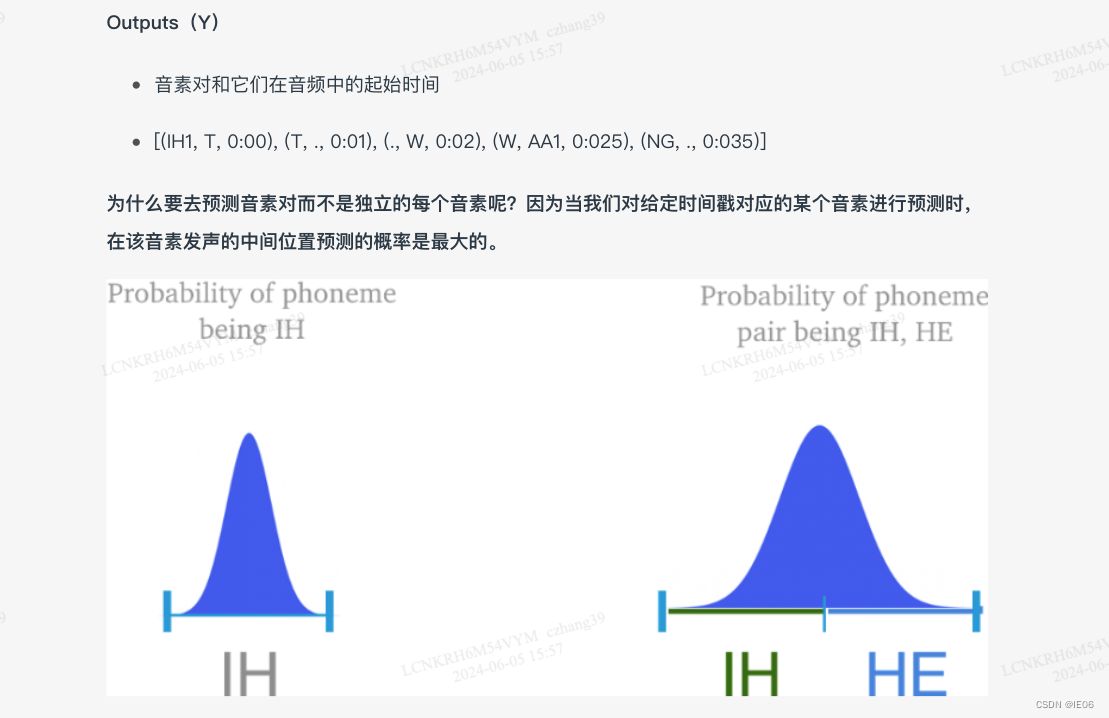
步骤3:将音素,持续时间和基频结合从而输出文本对应的语音
[IH1 (140hz, 0.5s), T (142hz, 0.1s), . (Not voiced, 0.2s), W (140hz, 0.3s),…] -> 音频
原始音频通常保存为16Bit规格 ,对每个时刻输出的可能值 ,softmax层将需要输出65536个值。先将 [-32768, 32767] 的范围线性压缩成 [-1, 1],然后再通过一个名为 μ-law 的算法,然后再将其拉回 [0, 255] 范围中。
1.2 Tacotron
Tacotron用的是一个典型的 Seq2Seq + Attention 的模型架构。它输出还会有个后处理(Post-processing)才会产生声音频谱(spectrogram),紧接着使用decoder生成声音。

步骤1:encoder生成向量
Encoder 的目的就是输入进一些字母和标点符号,输出一堆向量,类似于转为phoneme向量,告诉Decoder和注意力模块这些字母应该怎么发音。

对于 Encoder,我们也可以加上文法的信息。文法会将一句话切割成各类成分,比如主语宾语名词等,这将对一个句子的语气、停顿等起到作用。
步骤2:Tacotron Attention
attention模块的目的就是让机器能自动学习到每一个字母所代表的 embedding 在 decoder 那里会产生多长的声音讯号。而单调对应就意味着当我们将注意力可视化(x轴表示文字embedding,也就是编码器的输出,y轴表示音频,也就是decoder的输出),生成的可视化图案应该是呈对角线分布的。
步骤3. Tacotron Decoder
这里采用的Decoder其实就是Seq2Seq里面的Decoder,产生的vector就是Mel-spectrogram。在Decoder之后,Tacotron还有一个Post Processing(后处理模块),其第一代就是一个CBHG,第二代是一堆卷积层。它会把解码器输出的全部向量当作输入,然后再输出另外一排向量。
第一代的 Tacotron 用的是一个基于规则的 Vocoder,第二代就用上了 Wavenet。
1.3 Fast speech
Fast speech同样有 Encoder 转 character 为 embeddings,不同的是在编码器和解码器之间单独训练了 Duration 模块,可以预测每个 character 要念多长。这个 Duration 模块会输入一个单词嵌入,输出每个字符要说的长度。比如输出是2,它就要把当前的字符嵌入复制两次。

FastSpeech 使用了 Duration 模块的好处是,它不会像 Tacotron 或 基于 Transformer 的 TTS 那样,有一些发音上的瑕疵,比如结巴,跳过词汇没念,念错词汇的情况。直觉上看,FastSpeech 在 Duration 上做了一个更大的限制,来避开这些错误。
2. 常见Vocoder模型
Vocoder:当涉及语音合成时,vocoder是一个重要的组成部分,它负责将数字化的语音信号转换回可听的声音。Vocoder是“Voice Coder”的缩写,它是一种处理语音信号的算法或设备,用于分析和合成声音。它接收数字信号(通常是通过语音识别等手段得到的),并对其进行处理,使之变成人耳能够理解的声音信号。
首先我们大概讲一下 Vocoder 是干什么的。之前说过,一般在模型中操作的都是声谱 spectrogram,而 Vocoder 就是将 spectrogram 转为我们可以听的声音信号的。但是spectrogram只包含了振幅信息,不包含相位信息,无法直接还原为声音。

Griffin-Lim算法是一种启发式方法,用于估计音频信号的相位信息,从而实现从幅度谱(amplitude)重建时域波形(waveform)。这个算法特别适用于声音合成或音频重建的场景。这个算法的基本思想是:通过对幅度谱的估计和随机初始化重建频谱的相位,然后反转这些估计的频谱,再次应用STFT来获得新的时域波形。然后重复这个过程,迭代多次,希望最终获得合理的相位估计。不过它生成的语音听起来还是不太自然。
为什么 Vocoder 要单独拿来研究,而不是接在 TTS、VC 等模型后面直接做 End2End 训练呢?因为 Vocoder 是将频谱图转为波形的方式,只要生成的是频谱图,就可以使用 Vocoder,这使得其泛用性很高,而其他模型的生成目标就变成了生成频谱图,这会降低整个任务难度,使得它们能够更加专注于声音信号的处理。
下面是一些常见的vocoder


2.1 waveNet:PixelCNN自回归
其本质上就是一个自回归模型(autoregressive model),主要构成成分就是因果卷积网络(Causal Convolution Network)。我们首先看下wavenet的结构:
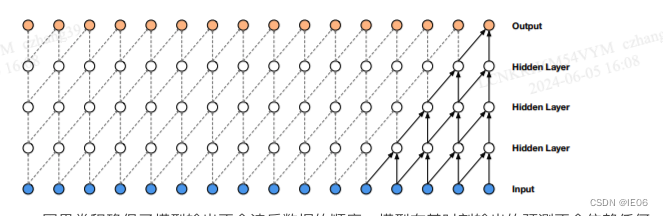
Causal Convolution(因果卷积):是卷积神经网络中的一种卷积操作,它具有一种“因果性”约束,即输出中的每个元素只能依赖于输入序列中其之前的元素。这种约束在处理时间序列数据时非常有用,因为它确保模型不会“未来”依赖于当前时间步之后的信息。
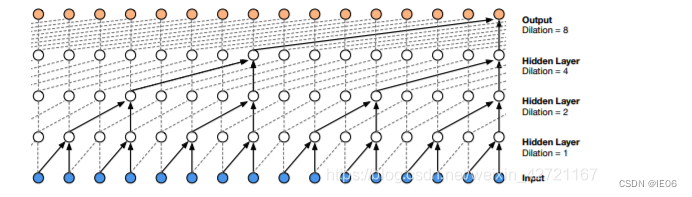
因果卷积存在的一个问题是它需要很多层,或者很大的卷积核来增大其感受野。例如,在上图2中,感受野只有5个单位 。(感受野 = 层数 + 卷积核长度 - 1)。因此WaveNet使用扩大卷积使感受野增大几个数量级,同时不会显著增加计算成本。
为了更方便快捷地计算,需要先对数据实施一个µ-law压扩变换,然后取到256个量化值。µ-law压扩变换算法如下:
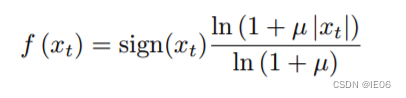
这种编码方式能够在保留音频信号主要特征的同时,通过压缩和量化来减小数据量。
对于PixelCNN,在生成过程(推理过程)是序列处理的,此时需要逐个pixel进行预测,速度很慢,下面的FFTNet则将速度提高到logN级别。
2.2 FFTNet:1*1核的自回归
FFTNet 和 WaveNet 一样也是自回归模型。不一样的是,它将其中的深度 CNN 改成比较简单的计算方式,输入的数据首先会被切成两段,分别为 xl 和 xr,通过不同的 CNN 再加起来得到 z,然后通过一个 ReLU,一个1×1 CNN,一个ReLU,得到新的 x,然后再进行和上面一样的操作。因为相加的操作,每通过一层,输入的数据大小就会减半,最后大小变成1的时候,这就是最终的输出。

2.3 waveglow:基于flow函数

从数学的角度来解释就是下面这样:

这里的z就是平均值为0,标准差为1的高斯分布。


2.4 HiFi-GAN:利用GAN优化
HiFi-GAN包括一个生成器和两个判别器,生成器的架构如下图所示,由多个MRF堆叠而成。MRF是用于上采样的反卷积运算模块。

因为语音信号是由不同周期的正弦信号构成,对周期信号进行建模对于生成实际的语音信号而言,十分重要。**因此,文章提出针对一个有多个鉴别器构成的大鉴别器,每一个小鉴别器固定获取某一周期的原始波形。**这个模型是模型合成真实声音的基础。
使用了两个判别器,一个是multi-period discriminator (MPD),用来识别语音中不同周期的信号,另一个是MelGAN中的multi-scale discriminator,用来应对超长数据。
MPD是由若干子鉴别器构成的,每一个子鉴别器只接受音频的等间距样本,这个间隔是由周期给出的。**子鉴别器主要是通过查看输入音频的不同部分,来获取彼此不同的隐式结构。**我们将周期设置为[2,3,5,7,11]来尽量减少重叠。如图二b中展示的一样,我们将一维的长度为T的原始音频数据转换为2维的数据,宽为p pp,长为T / p T/pT/p,然后对其使用二维卷积处理。MPD中每一个卷积层,我们将卷积核宽度设置为1,来单独处理某一個周期的样本。每一个子鉴别器是一个跨步卷积层,激活函数为 ReLU。然后,对MPD进行权重归一化,通过将输入数据转换成二维数据,而不是直接对周期信号进行采样,MPD的梯度可以传递到输入音频的所有时间步长。

MPD是检测不同周期的采样点,按照一定的空间间隔进行采样,本来就是离散的。MSD是对光滑的波形图进行整体卷积采样,是连续,是为了弥补MPD的离散的缺点。它是一个多尺度鉴定器,来实现对于音频序列的连续感知,由三个子鉴定器混合而成,每一个子鉴定器都是针对不同的输入尺度,分别是原始音频、2倍平均池化音频、4倍平均池化音频。
MB-iSTFT-HIFIGAN加上了诸多轻量化手段,概括来说就是用类似诸如短时FFT等工具代替卷积计算。
2.5 vocos:进行了相位预测
Vocos 是一款设计巧妙的快速神经声码器,它能够从声学特征中合成音频波形。利用生成对抗网络(GAN)的目标训练,Vocos 实现了仅通过一次前向传播即可生成音频波形的能力。与众不同的是,Vocos 不直接在时间域内建模音频样本,而是生成频谱系数,借助逆傅里叶变换快速重构音频。
与HiFigan比,显著的区别在于,vocos不仅对幅度谱进行预测,还要对相位进行预测,即图中希腊字母
ϕ
\phi
ϕ。主体结构中,采用ConvNeXt block(mobilenet方式),有一定的加速作用。也因为没有转置卷积,也不存在必须要用dilated卷积增加感受野的问题。这也是作者不采用dilated的原因。
