Optuna发布 4.0 重大更新:多目标TPESampler自动化超参数优化速度提升显著
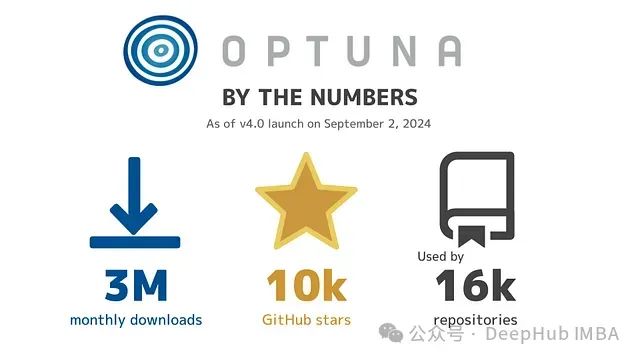
Optuna这个备受欢迎的超参数优化框架在近期发布了其第四个主要版本。自2018年首次亮相以来,Optuna不断发展,现已成为机器学习领域的重要工具。其用户社区持续壮大,目前已达到以下里程碑:
- 10,000+ GitHub星标
- 每月300万+ 下载量
- 16,000+ 代码库使用
- 5,000+ 论文引用
- 18,000+ Kaggle的code使用
Optuna 4.0的开发重点包括:
- 用户间功能共享: 引入OptunaHub平台,便于共享新的采样器和可视化算法。
- 优化生成式AI和多样化计算环境:- 正式支持Artifact Store,用于管理生成的图像和训练模型。- 稳定支持NFS的JournalStorage,实现分布式优化。
- 核心功能增强:- 多目标TPESampler的显著加速- 新Terminator算法的引入
主要新特性
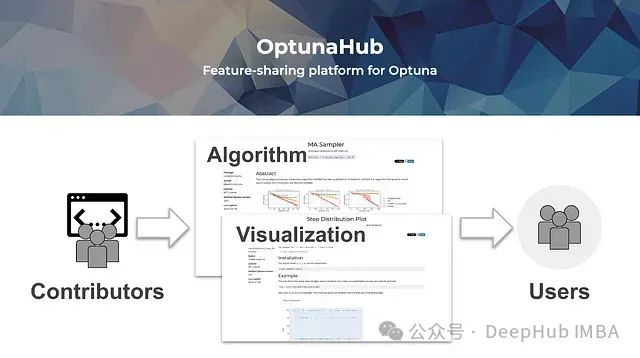
OptunaHub: 功能共享平台
OptunaHub (hub.optuna.org) 作为Optuna的官方功能共享平台正式发布。它提供了大量优化和可视化算法,使开发者能够轻松注册和分享他们的方法。这个平台的推出预计将加速功能开发,为用户提供更多样化的第三方功能。
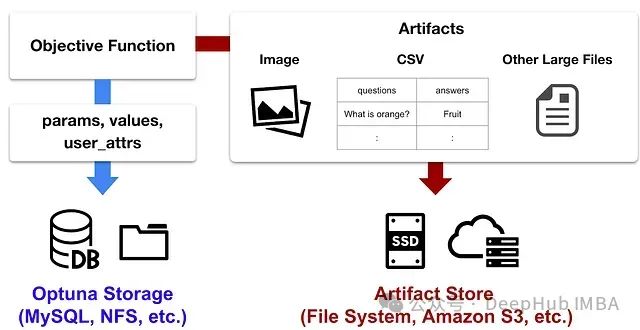
Artifact Store: 增强实验管理
Artifact Store是一个专门用于管理优化过程中生成文件的功能。它可以有效处理:
- 生成式AI输出的文本、图像和音频文件
- 深度学习模型的大型快照文件
这些文件可以通过Optuna Dashboard进行查看。Optuna 4.0稳定了文件上传API,并新增了artifact下载API。同时Dashboard新增了对JSONL和CSV文件的支持。
JournalStorage: 支持NFS分布式优化
JournalStorage是一种基于操作日志的新型存储方式,它简化了自定义存储后端的实现。其中,
JournalFileBackend
支持多种文件系统,包括NFS,可以实现跨节点的分布式优化。这对于难以设置传统数据库服务器的环境尤其有用。
使用示例:
importoptuna
fromoptuna.storagesimportJournalStorage
fromoptuna.storages.journalimportJournalFileBackend
defobjective(trial: optuna.Trial) ->float:
...
storage=JournalStorage(JournalFileBackend("./journal.log"))
study=optuna.create_study(storage=storage)
study.optimize(objective)
新Terminator算法
为解决超参数过拟合问题,Optuna引入了新的Terminator算法。它可以在超参数过拟合之前终止优化过程,或者帮助用户可视化过拟合开始的时间点。新版本引入了预期最小模型遗憾(EMMR)算法,以支持更广泛的用例。
约束优化增强
Optuna 4.0增强了约束优化功能,特别是:
study.best_trial和study.best_trials现在保证满足约束条件- 核心算法(如TPESampler和NSGAIISampler)对约束优化的支持得到改进
多目标TPESampler的加速
多目标优化在机器学习中扮演着越来越重要的角色。例如,在翻译任务中,我们可能需要同时优化翻译质量(如BLEU分数)和响应速度。这种情况下,多目标优化比单目标优化更为复杂,通常需要更多的试验来探索不同目标之间的权衡。
TPESampler(Tree-structured Pareto Estimation Sampler)是Optuna中一个强大的采样器,它在多目标优化中展现出了优秀的性能。与默认的NSGAIISampler相比,TPESampler具有以下优势:
- 更高的样本效率,特别是在1000-10000次试验的范围内
- 能够处理动态搜索空间
- 支持用户定义的类别距离
在之前版本的TPESampler在处理大量试验时存在性能瓶颈,限制了其在大规模多目标优化中的应用。
性能提升
Optuna 4.0对多目标TPESampler进行了显著优化:
- 三目标优化场景下,200次试验的速度提高了约300倍
- 能够高效处理数千次试验的多目标优化
这一改进主要通过优化以下算法实现:
- WFG(加权超体积增益)计算
- 非支配排序
- HSSP(超体积子集选择问题)
TPESampler的工作原理
TPESampler基于树形Pareto估计(TPE)算法。在多目标优化中,它的工作流程如下:
- 将观察到的试验分为非支配解和支配解两组
- 为每个参数构建两个概率分布:一个基于非支配解,另一个基于支配解
- 使用这些分布来指导下一个试验点的选择,倾向于选择可能产生非支配解的参数值
这种方法允许算法在探索(寻找新的有希望的区域)和利用(优化已知的好区域)之间取得平衡。
使用TPESampler进行多目标优化示例
以下是使用TPESampler进行多目标优化的简单示例:
importoptuna
defobjective(trial):
x=trial.suggest_float("x", -5, 5)
y=trial.suggest_float("y", -5, 5)
objective_1=x**2+y**2
objective_2= (x-2)**2+ (y-2)**2
returnobjective_1, objective_2
sampler=optuna.samplers.TPESampler()
study=optuna.create_study(sampler=sampler, directions=["minimize", "minimize"])
study.optimize(objective, n_trials=100)
在这个例子中,定义了一个具有两个目标的优化问题。TPESampler被用作采样器,study被设置为最小化两个目标。
基准测试结果
测试环境:
- Ubuntu 20.04
- Intel Core i7-1255U CPU
- Python 3.9.13
- NumPy 2.0.0
测试结果如图所示:
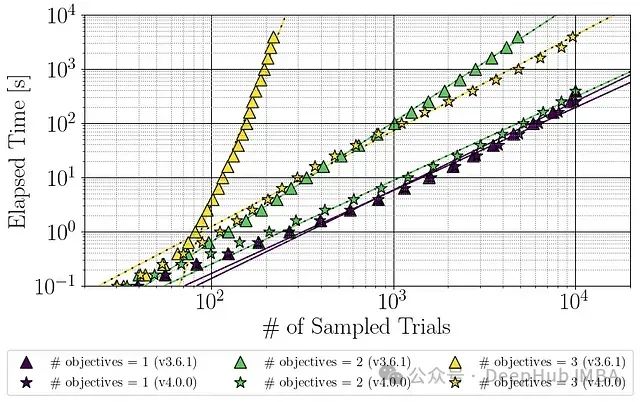

可以看到:
- Optuna 4.0中双目标优化性能接近单目标优化
- 三目标优化在200次试验时,运行时间从约1,000秒减少到约3秒
- 新版本在3-5个目标的情况下仍保持高效
TPESampler vs. NSGAIISampler
虽然NSGAIISampler是Optuna中默认的多目标优化采样器,但TPESampler在某些情况下可能更为有效:
- 大规模优化:在1000-10000次试验的范围内,TPESampler通常表现更好
- 复杂搜索空间:对于具有条件参数或动态搜索空间的问题,TPESampler更为灵活
- 高维参数空间:TPESampler在处理高维参数空间时通常更有效
选择合适的采样器还应该基于具体问题和计算资源。可以尝试两种采样器,比较它们在特定问题上的性能。
结论与展望
Optuna 4.0通过引入新功能和优化现有算法,大幅提升了其在复杂优化任务和多样化计算环境中的适用性。特别是多目标TPESampler的性能提升,为处理更复杂的优化问题铺平了道路。
TPESampler的显著加速使得Optuna能够更有效地处理大规模多目标优化问题。这一改进对于需要同时优化多个目标的复杂机器学习任务(如大型语言模型的训练)具有重要意义。
在官方的发布中Optuna团队还提到后面的工作:
- 扩展问题设置的适用范围
- 通过OptunaHub支持更多创新算法
- 进一步优化性能和用户体验
- 改进TPESampler和其他采样器在更广泛场景下的性能
研发团队鼓励用户尝试新版本的多目标TPESampler,Optuna有望在未来版本中提供更强大、更灵活的超参数优化解决方案。
https://avoid.overfit.cn/post/8d9596779bcc44a79f2a53a2a8d02e24